-
C++:哈希表和哈希桶

"总是担心明天,又怎能把我好今天?"
(一) 哈希
①哈希概念
我们要查找关键key值,在不管是 顺序结构/平衡树 中,都需要进行遍历比较。
顺序结构的时间复杂度为O(N) 平衡树的时间复杂度为高度次O(logN);
哈希的本质,就是基于完成快速查找,提出的。
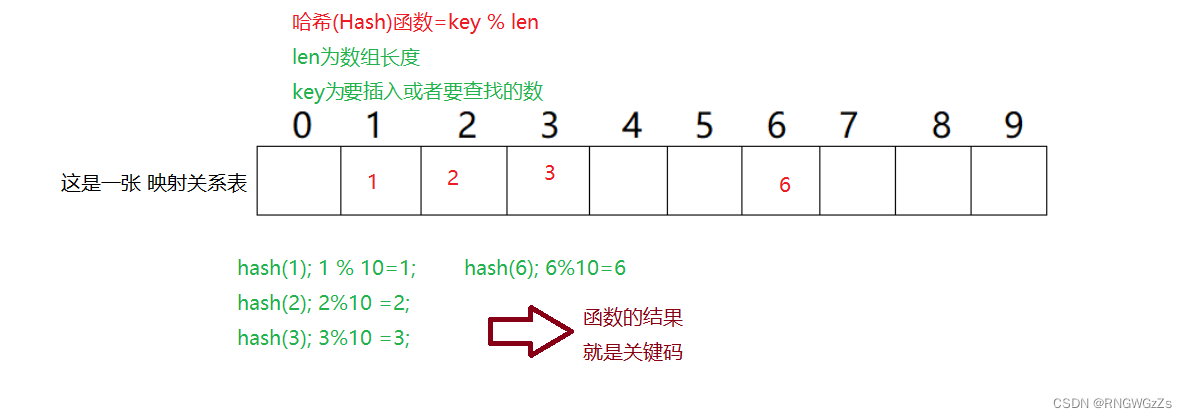
结构1(散列表):
它是一种,让查找数通过某种函数(Func),让元素的存储位置与关键码(Func与查找数)
-----建立映射关系.
1.插入元素;
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放.
2.搜索元素;
计算元素关键码,用关键码去找元素的存储位置,进行比较.
②哈希冲突(碰撞);
我们看上面的列表+函数。如果key为22时,
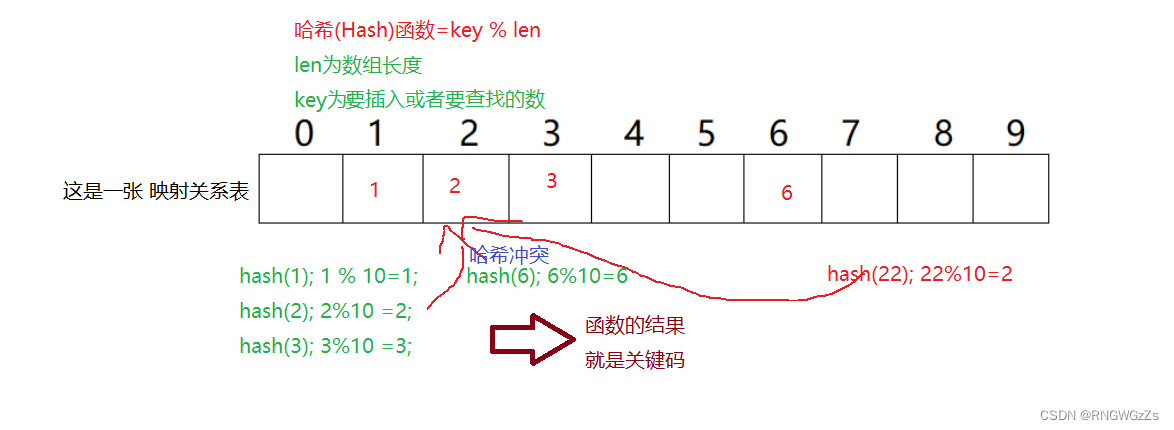
因此,所谓的哈希冲突,就是指。
不同key值 通过同样的哈希函数, 算出的关键码所映射出的位置(地址)一样~
为什么会出现哈希冲突?
其原因就在于哈希函数设计的不够合理;
哈希函数设计原则:
1.定义域内必须包含所需的存储码(关键码).如果散列表允许有m个地址,其值域必须在0~m-1
2.哈希函数算出来的地址,需要均匀空间.
3.设计简单
常见的哈希函数有两种;
1.直接定制法
Hash(Key)= A*Key + B
2.除留余数法
Hash(key) = key% p(p<=m)
(二)哈希闭散列:
解决哈希冲突的两个方法: 闭散列 + 开散列
(1)什么是闭散列?
也叫开放定址法.
当发生哈希冲突时,如果哈希表未被装满,就把key存放到冲突位置中的 “下一个” 空位置中
找寻方法;
1.线性探测: 从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止
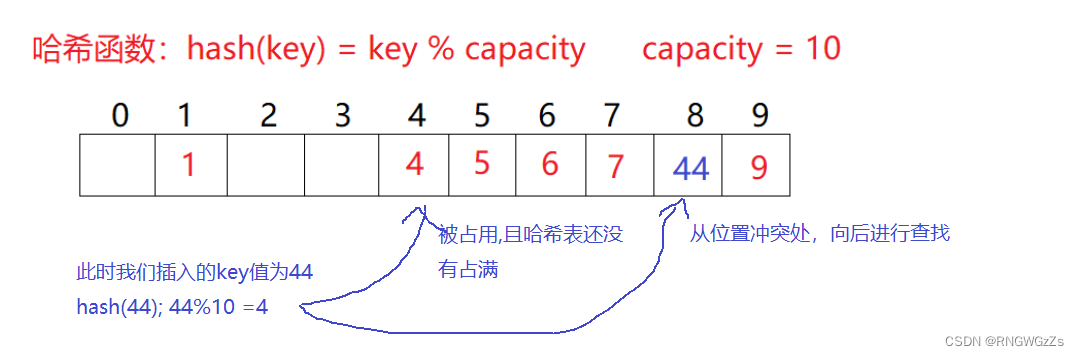
2.二次探测;在线性探测的基础上,走二次方的存放地址。
本质上,是牺牲别人的存储位置。且线性探测会造成连续的冲突,发生踩踏效应.
负载因子;存储数据的个数/空间大小.
负载因子大 冲突的概念更高
负载因子小 冲突的概念小。
因此,在表中进行数据的插入时,一定要随时进行增容,来减小哈希冲突!
(2)闭散列实现;
①哈希结构
- //这种结构设计的优势在于 ,可以不用真正意义上删除数据
- //只需要改变数据的 状态 然后 进行覆盖
- enum State
- {
- EXIST, //存在
- EMPTY, //空
- DELTE //删除
- };
- //哈希表 映射位置的值
- template<class K,class V>
- struct HashData
- {
- pair
- State _state=EMPTY;
- };
- //Hash 表
- template<class K,class V>
- class HashTable
- {
- typedef HashData
- public:
- private:
- //可以看出 哈希表 就是一种线性结构
- /*HashData* _table;
- size_t _size;
- size_t capacity;*/
- //可直接用vector代替
- vector
_table; - size_t _n=0; //有效数据数
- };
②查找
- HashData* find(const K& key)
- {
- if (_table.size() == 0)
- return nullptr;
- //查找
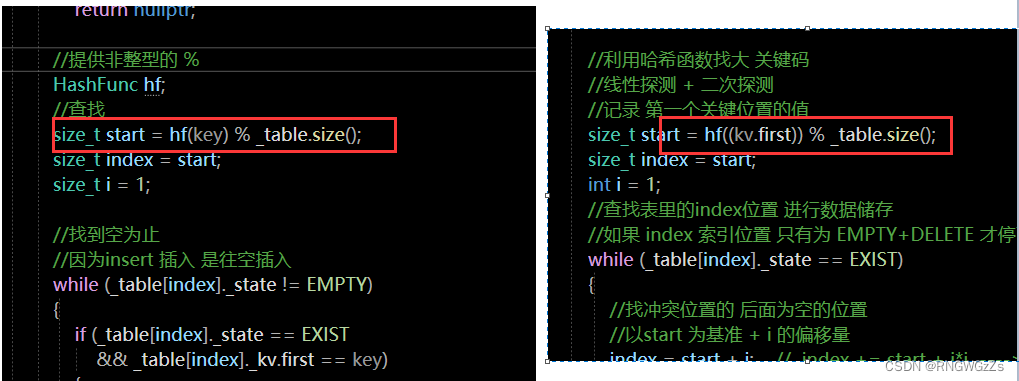
- size_t start = key % _table.size();
- size_t index = start;
- int i = 1;
- //找到空为止
- //因为insert 插入 是往空插入
- while (_table[index]._state != EMPTY)
- {
- if (_table[index].state == EXIST
- && _table[index]._kv == key)
- {
- return _table[index];
- }
- index = start + i;
- index %= _table.size();
- index+=i;
- }
- return nullptr;
- }
查找的逻辑较为简单,还是注意的是,循环的条件是 判断到index处为空 为止。
③插入;
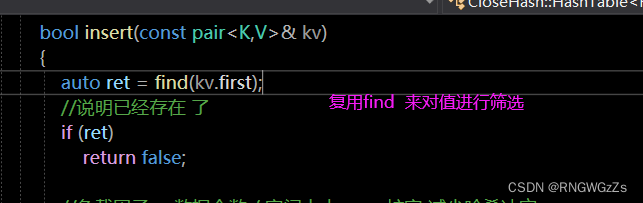

- bool insert(const pair
- {
- HashData* ret = find(kv.first);
- //说明已经存在 了
- if (ret)
- return false;
- //负载因子 = 数据个数 / 空间大小 --->扩容 减少哈希冲突
- if (_table.size() == _n) //这样子设计 也可以避免在 未插入数据前 _n 为空 size为0 的情况
- {
- //扩容10 空间
- _table.resize(10);
- }
- //当负载因子 出现 问题
- else if ((double)_n / (double)_table.size() > 0.7)
- {
- //需要扩容
- //构造一个 新对象
- HashTable
- //开好空间
- newtable._table.resize(2 * _table.size());
- //从_table中读取数值
- for (auto& e : _table)
- {
- if (e._state == EXIST)
- {
- //复用insert
- newtable.insert(e._kv);
- }
- }
- //再进行交换
- _table.swap(newtable._table);
- }
- //利用哈希函数找大 关键码
- //线性探测 + 二次探测
- //记录 第一个关键位置的值
- size_t start = (kv.first) % _table.size();
- size_t index = start;
- int i = 1;
- //查找表里的index位置 进行数据储存
- //如果 index 索引位置 只有为 EMPTY+DELETE 才停下
- while (_table[index]._state == EXIST)
- {
- //找冲突位置的 后面为空的位置
- //以start 为基准 + i 的偏移量
- index = start + i; // index += start + i*i ---->就可以实现二次探测
- //不让index 超出 _table.size()的范围;
- index %=_table.size();
- i++;
- }
- //存入数据
- _table[index]._kv = kv;
- _table[index]._state = EXIST;
- _n++;
- return true;
- }
④删除;
- bool Erase(const K& key)
- {
- HashData* ret = find(key); //找这个数在不在
- if (ret == nullptr)
- return false;
- else
- {
- //找到ret 并把状态置位DELETE
- ret->_state = DELTE;
- --_n;
- }
- }
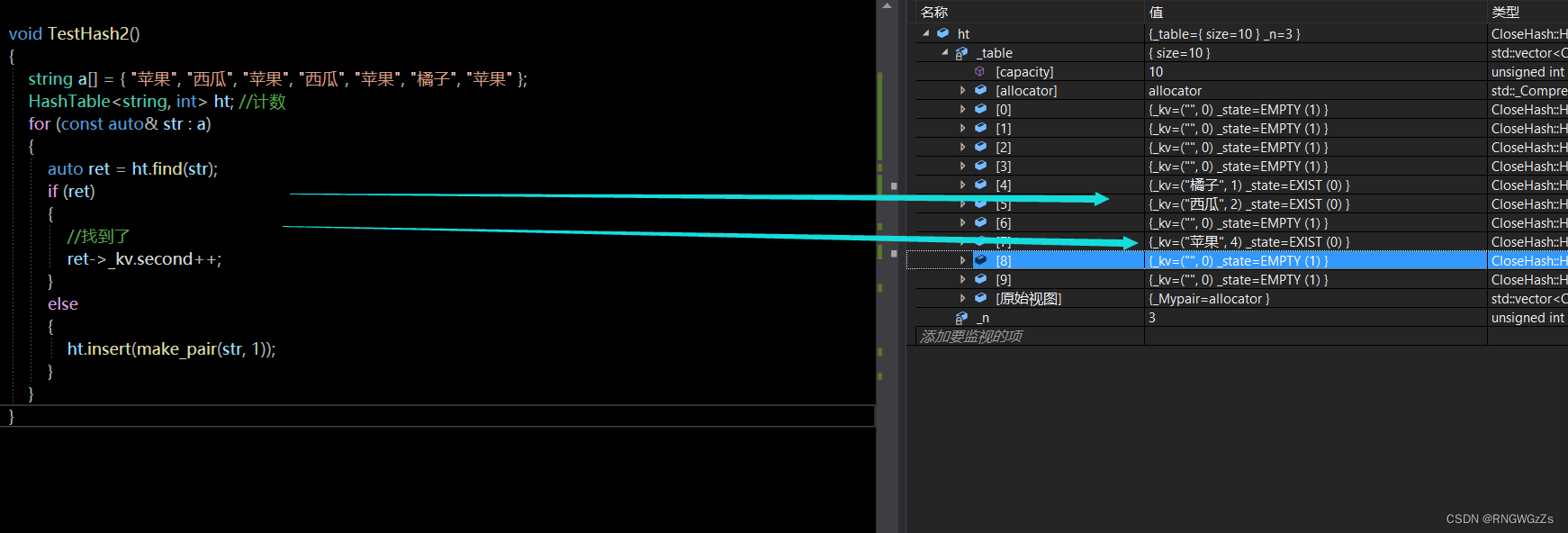
⑤测试;
我们先来插入些数据;
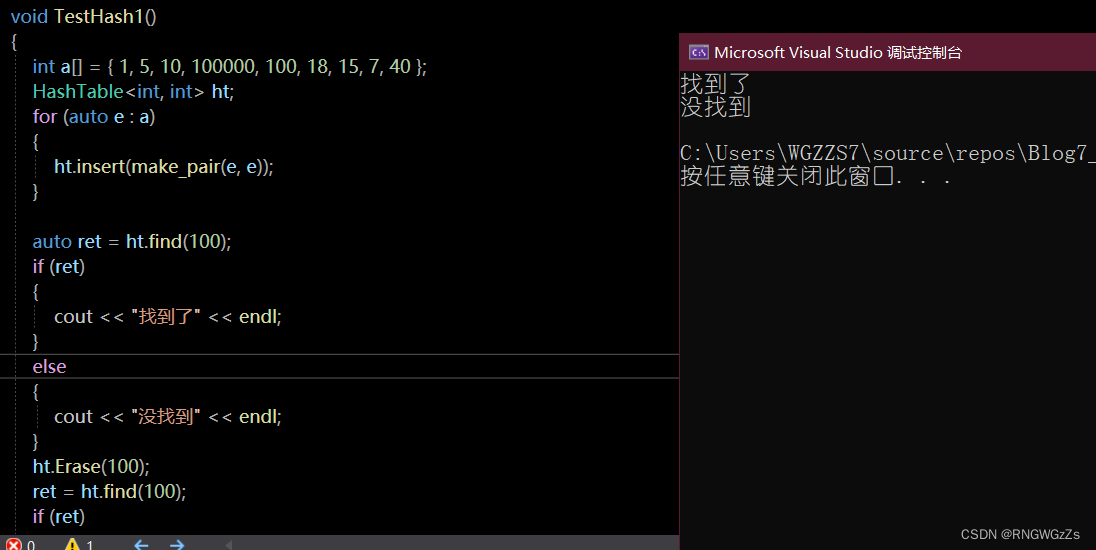
测试样例 很正常。
但此时我们换成字符串就出问题了。
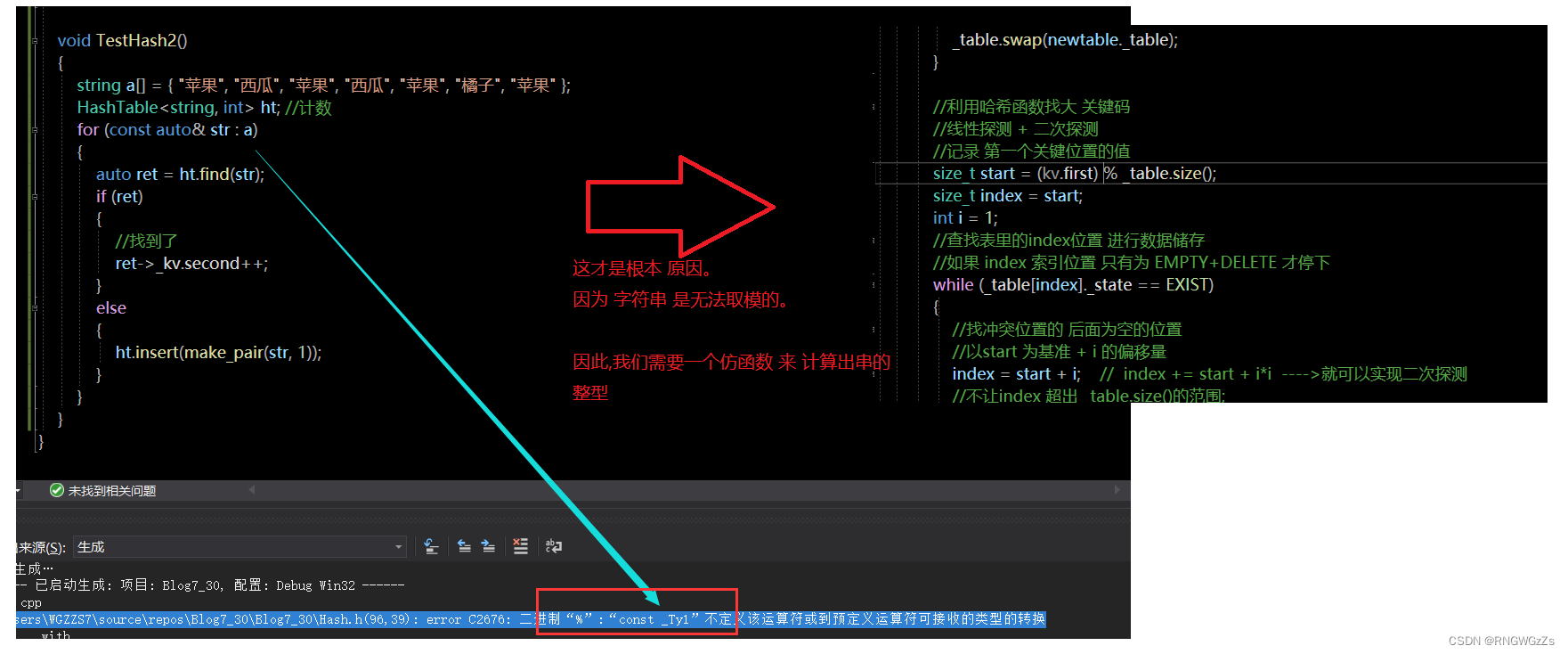
根本原因在于;字符串无法取模。
哈希函数 仅仅只能针对整型处理。
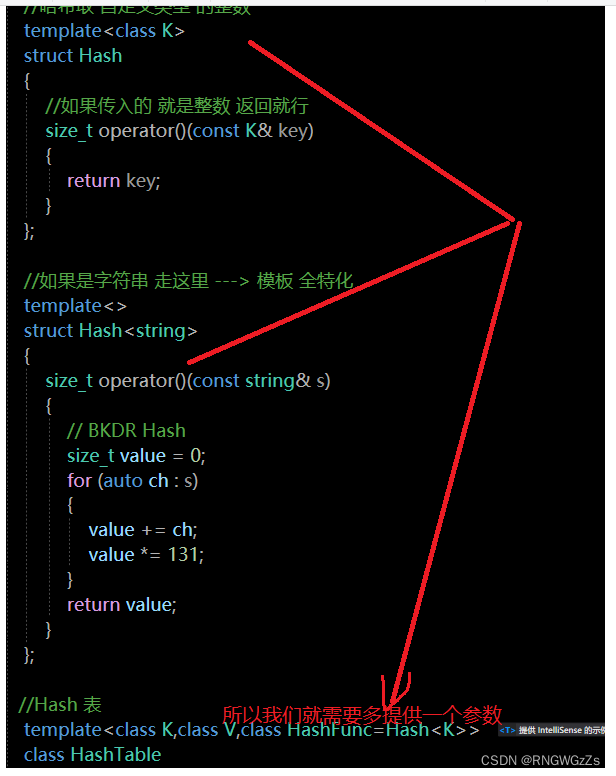
字符串哈希算法
 https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html 这里有 一些前人 经过实验得出的 字符串转整型
https://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html 这里有 一些前人 经过实验得出的 字符串转整型
我们就用一种方法即可;
完成统计;
闭散列的讲解就到这里。因为还有一种更优的设计。我们会把重心放在 开散列上。
(2)什么是开散列?
开散列; 又称链表地址法
每个关键码地址下, 会链接多个节点。形似 挂桶一样。所以也叫哈希桶。
各链表的头节点,会存放在关键码地址中。

①结构;- //本质上 哈希数据 就是单链表
- template<class K,class V>
- struct HashData
- {
- HashData
- pair
- HashData(const pair
- :_kv(kv),
- _next(nullptr)
- {}
- };
- template<class K,class V,class HashFunc=Hash
> - class HashBuckets
- {
- typedef HashData
- public:
- private:
- //存 节点地址
- vector
- size_t _n=0;
- };
②查找;
- Node* find(const K& key)
- {
- HashFunc hf;
- if (_table.size() == 0)
- return nullptr;
- else
- {
- //找相对位置
- size_t index = hf(key) % _table.size();
- Node* cur = _table[index];
- //cur 走到nullptr 为止
- while (cur)
- {
- //找到就返回
- if (hf(cur->_kv.first) == key)
- {
- return cur;
- }
- else
- {
- //没找到就走
- cur = cur->_next;
- }
- }
- }
- return nullptr;
- }
④插入;
插入需要注意的是,增容部分 不是拷贝节点。而是让节点链接到新表上去!
- bool insert(const pair
- {
- Node* ret = find(kv.first);
- if (ret)
- return false;
- HashFunc hf;
- //哈希桶同样也需要 扩容
- //当负载因子 为 1 到时候扩容
- if (_n == _table.size())
- {
- vector
- // NTable._table.resize(_table.size() * 2);
- NTable.resize(GetNextPrime(_table.size()));
- // 这里不是拷贝赋值 而是让旧表里的指针
- //链接进新表
- for (int i = 0; i < _table.size() ; i++)
- {
- if (_table[i])
- {
- //旧表节点
- Node* cur = _table[i];
- while (cur)
- {
- //记录 cur 的下一个 因为 头插 会改变cur->next
- Node* next = cur->_next;
- //重新计算映射位置
- size_t index = hf(kv.first) % NTable.size();
- //头插
- cur->_next = NTable[index];
- NTable[index] = cur;
- cur = next;
- }
- _table[i] = nullptr;
- }
- }
- _table.swap(NTable);
- }
- //插入 哪个位置
- size_t index = hf(kv.first) % _table.size();
- //去构建 一个节点nenode 以备插入
- Node* newnode = new Node(kv);
- //插入选择头插 因为效率高
- newnode->_next = _table[index];
- _table[index] = newnode;
- ++_n;
- return true;
- }
⑤删除;
- bool Erase(const K& key)
- {
- //删除节点 的区别 就在头删 + 其它删除删
- size_t index = hf(key) % _table.size();
- Node* prev = nullptr;
- Node* cur = _table[index];
- while (cur)
- {
- if (cur->_kv.first == key)
- {
- if (cur == _table[index])
- {
- _table[index] = cur->_next;
- }
- else
- {
- prev->_next = cur->_next;
- }
- delete cur;
- --_n;
- return true;
- }
- else
- {
- prev = cur;
- cur = cur->_next;
- }
- }
- return false;
- }
有一个观点;
除留余数法,最好模一个素数
这个仅供参考。因为没什么理论依据。

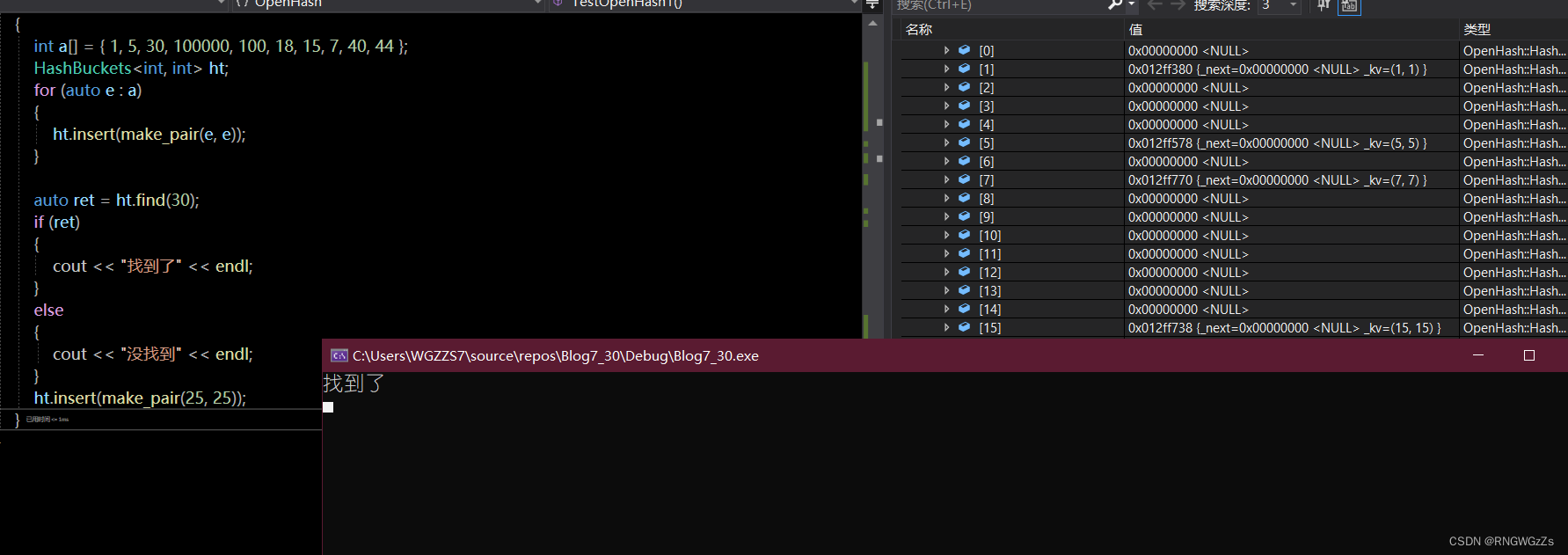
⑤测试;
(三) 哈希三散列的反思;
在实际应用中,使用开散列(哈希桶)的场景远远多余闭散列(哈希表).、
(1)内存空间的使用
对于开散列而言;
为了避免哈希冲突,提高查找效率。会开辟多余空闲空间。
而表项所占的空间也比指针大。 因此链接地址法反而更节省空间。
因为哈希的目的; 节省空间!
当然也有极端情况;当所有节点链接在同一块区域。
哈希桶的负载因子很低,但事实上却构成冲突。
哈希的闭散列 、开散列也就结束了。
感谢你的阅读。
祝你好运~

-
相关阅读:
Ubuntu 下载安装包到本地
云原生平台,让边缘应用玩出花!
论文总结-交通预测(未完成)
Java基础(十九):集合框架
直播课堂系统03-model类及实体
论文阅读_解释大模型_语言模型表示空间和时间
fastdfs常用命令
企业数仓DQC数据质量管理实践篇
Matlab:使用plot函数绘制数据曲线
(持续更新中!)详解【计算机类&面试真题】军队文职考试 ——第一期(真题+解析)| TCP、UDP的区别;程序局部性;ICMP协议及主要功能;重定位所需的计算机硬件
- 原文地址:https://blog.csdn.net/RNGWGzZs/article/details/126067252
