-
橘子学Flink03之Flink的流处理与批处理
一、Flink 处理模型:
flink的处理方式主要有两种是流处理与批处理。Flink 专注于无限流处理,有限流处理是无限流处理的一种特殊情况。可以通过调节阈值来设置多少数据处理一次,这是批处理的一种,我们也可以设置时间阈值。这种攒一批再处理的方式可能会有延迟,kafka应该也有这个思路。
1、流处理
无限流处理:
- 输入的数据没有尽头,像水流一样源源不断
- 数据处理从当前或者过去的某一个时间 点开始,持续不停地进行
有限流处理:
- 从某一个时间点开始处理数据,然后在另一个时间点结束
- 输入数据可能本身是有限的(即输入数据集并不会随着时间增长),也可能出于分析的目的被人为地设定为有限集(即只分析某一个时间段内的事件)
Flink封装了DataStream API进行流处理,封装了DataSet API进行批处理。
同时,Flink也是一个批流一体的处理引擎,提供了Table API / SQL统一了批处理和流处理
2、流处理引擎的技术选型
市面上的流处理引擎不止Flink一种,其他的比如Storm、SparkStreaming、Trident等,实际应用时如何进行选型,给大家一些建议参考
- 流数据要进行状态管理,选择使用Trident、Spark Streaming或者Flink
- 消息投递需要保证At-least-once(至少一次)或者Exactly-once(仅一次)不能选择Storm
- 对于小型独立项目,有低延迟要求,可以选择使用Storm,更简单
- 如果项目已经引入了大框架Spark,实时处理需求可以满足的话,建议直接使用Spark中的Spark Streaming
- 消息投递要满足Exactly-once(仅一次),数据量大、有高吞吐、低延迟要求,要进行状态管理或窗口统计,建议使用Flink
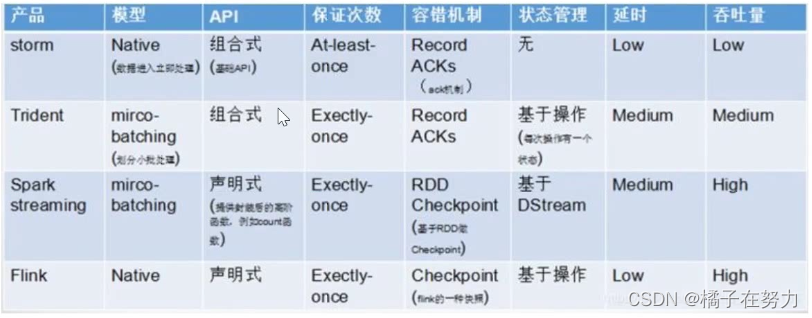
flink是拿到数据就处理,所以延迟很低,spark是在一个时间内压缩处理时长,但是不是真的延迟低。后面看spark的时候再说。
3、Flink 应用场景
Flink主要应用于流式数据分析场景
-
实时ETL
集成流计算现有的诸多数据通道和SQL灵活的加工能力,对流式数据进行实时清晰、归并和结构化处理;同时,对离线数仓进行有效的补充和优化,并为数据实时传输提供可计算通道。
-
实时报表
实时化采集、加工流式数据存储;实时监控和展现业务、客户各类指标,让数据化运营实时化。
-
监控预警
对系统和用户行为进行实时监测和分析,以便及时发现危险行为。
-
在线系统
实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在各类内容投放、智能推送领域有大量的应用。
二、总结
我们看到flink有一个很大的特点就是实时性,所以可以基于实时性做一些很多实时数据的处理和监测。
-
相关阅读:
如何在Zoom中集成自己的app?一个简单的例子
263 丑数
[笔记] 深度学习的部分专业名词
【第二篇】商城系统-工欲善其事必先利其器-环境准备
有了 C 语言的基础,怎么学 Java ?
Dubbo详解,用心看这一篇文章就够了【重点】
可视化学习:CSS transform与仿射变换
串口控制小车电机转动+蓝牙长按控制
力扣刷题-链表理论基础
腾讯云发布三款云原生新品 持续加码云原生布局
- 原文地址:https://blog.csdn.net/liuwenqiang1314/article/details/126069347