-
【MindSpore】用coco2017训练Model_zoo上的 yolov4,迭代了两千多batch_size之后报错,大佬们帮忙看看。
问题描述:
运行环境:Atlas 800 9000 CANN20.2
batch_size: 4,8,16,32(四种分别尝试过,都在一个epoch训练了80%左右报这个错了)
数据集:coco2017
模型:Model_zoo YOLOv4_Cspdarknet53 (配置都是用的默认的)
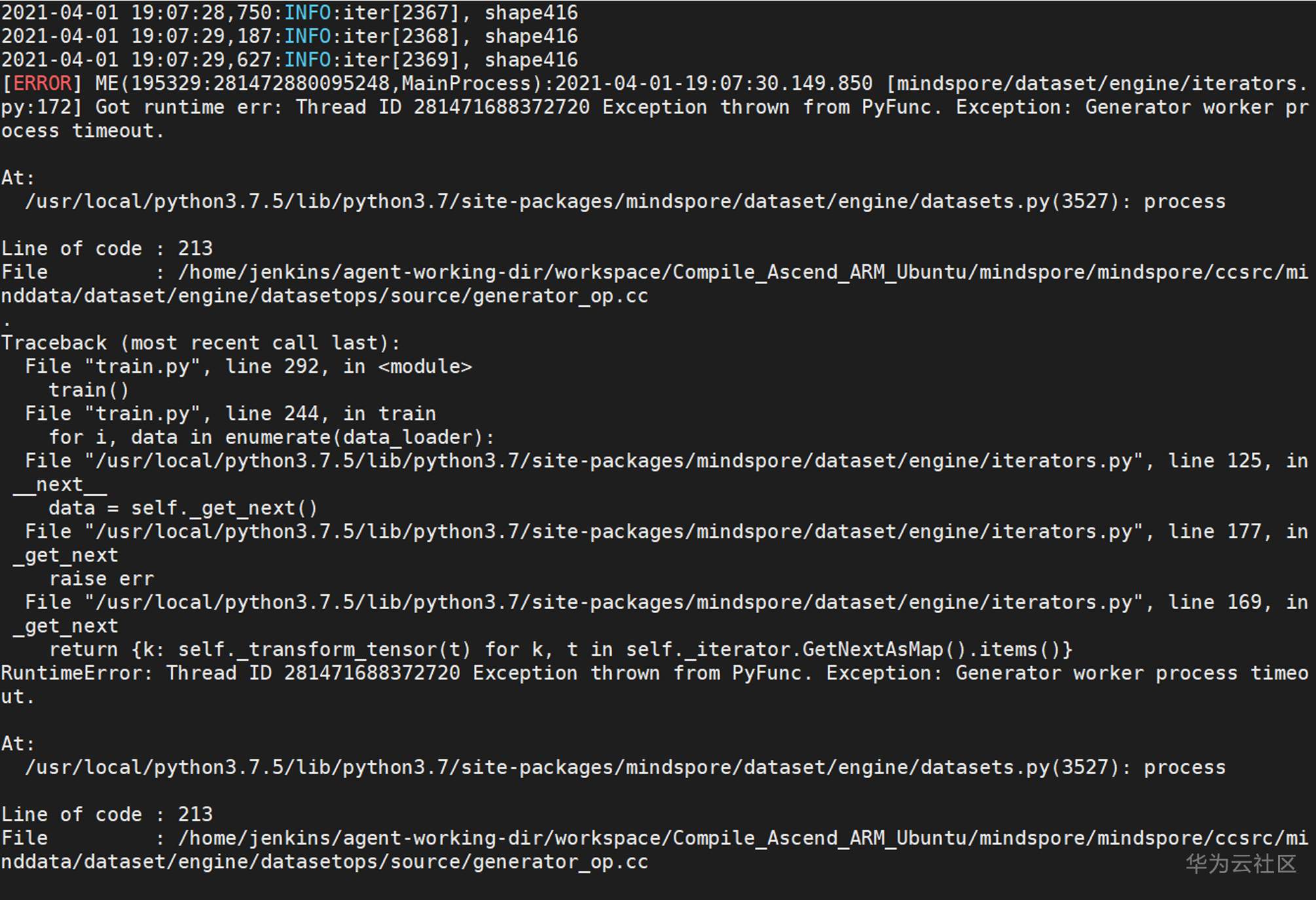
解决方案:
从错误截图中初步分析的结论是,数据集可能不完整或是有错误,导致一定step之后再也无法迭代出数据进行训练了。
我们建议按照如下方式排查故障:
1、确保coco2017数据集来源正确,mindspore model_zoo中yolo v4 README提供了coco数据集的官方下载链接:COCO - Common Objects in Context
2、上述错误一般源于src/yolo_dataset.py读取coco数据集时发生了错误,建议采用如下方式进行排查:
在src/yolo_dataset.py的代码底部增加如下调试代码:
from src.config import ConfigYOLOV3DarkNet53
if __name__ == '__main__':
config = ConfigYOLOV3DarkNet53()
config.label_smooth = 0
config.label_smooth_factor = 0.1
image_dir = "/your_path/coco2017/train2017"
anno_path = "/your_path/coco2017/annotations/instances_train2017.json"
yolo_dataset = COCOYoloDataset(image_dir, anno_path)
nums = 0
for data in yolo_dataset:
nums += 1
print("nums is ", nums)
以上代码主要用于调试COCOYoloDataset,正常情况下,yolo_dataset是可以正确完整输出所有数据的,请参照以上调试代码,确保读取coco数据集完整无误。
-
相关阅读:
Spring Boot + Netty + WebSocket 实现消息推送
Tomcat域名访问文件出现访问不到的问题
【单片机毕业设计】【mcuclub-jj-004】基于单片机的楼道节能灯的设计
这些视频转音频软件你知道吗?
【JAVA - List】差集removeAll() 四种方法实现与优化
Go-Zero技能提升:深度探究goctl的妙用,轻松应对微服务开发挑战!(三)
常用的SSH,你了解多少?(长文警告)
进程管理学习
map-set
安卓四大组件之——Activity
- 原文地址:https://blog.csdn.net/weixin_45666880/article/details/126060229