-
MySQL-数据操作-分组查询-连接查询-子查询-
分组查询
基础
引入:求每个部门的平均工资。
语法
select 分组函数,分组后的字段(要求出现在group by的后面) from 表 【where 筛选条件】 group by 分组列表 【having 分组后的筛选条件】 【order by 排序列表】- 1
- 2
- 3
- 4
- 5
- 6
注意
查询列表是特殊的,必须是分组函数 或者 group by 后面的字段;
order by 是支持别名的,同样group by 和 having 也是支持别名的,但是不经常使用。
分组函数包括:sum、max、min、avg、count。
分组后查询使用having;
多个分组字段之间使用逗号分隔开来;执行顺序
from → where → group by → having → select → order by案例

特点
分组查询中的筛选条件分为两类
类别 数据源 位置 关键字 分组前筛选 原始表 group by 子句的前面 where 分组后筛选 分组后的结果集 group by 子句的后面 having 注意事项
分组函数做条件肯定是放在having子句中
能用分组前筛选的,就优先考虑使用分组前筛选
having子句即可包含聚合函数(分组函数)作用的字段 也可以包括 普通的标量字段
having子句 必须与 group by 子句同时使用,不能单独使用
group by 子句支持单个字段分组,多个字段分组(多个字段之间用逗号隔开没有顺序要求),表达式或函数(用的较少)。
也可以添加排序(排序放在整个分组查询的最后)分组查询案例

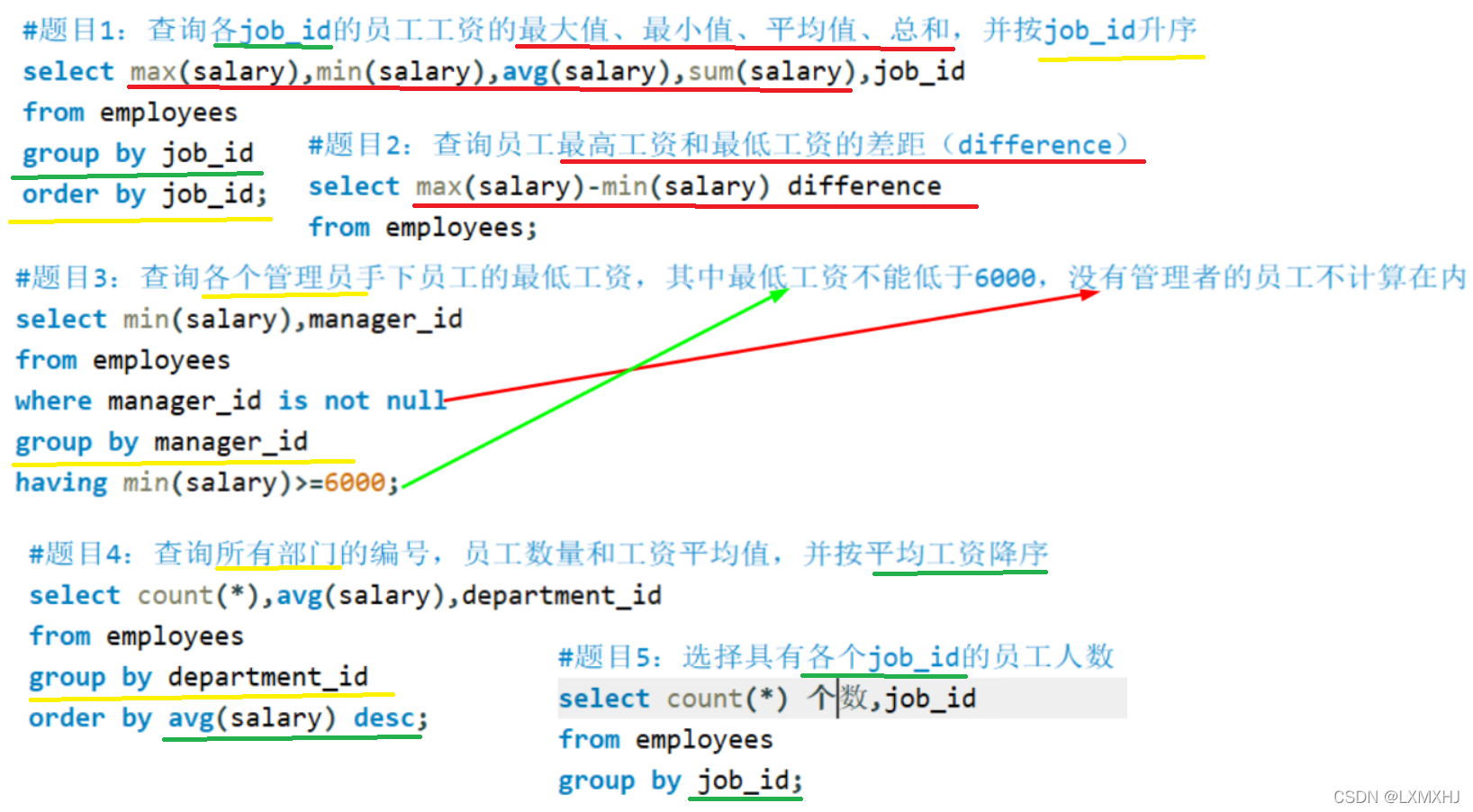
案例
连接查询
概述
概念:
又称为多表查询,当查询的字段来自于多个表时,就会用到连接查询。笛卡尔乘积现象 表1 有m行,表2 有n行,结果有n*m行。
当查询多个表时,没有添加有效的连接条件,导致多个表所有行实行完全连接。
发生原因:没有有效的连接条件;
如何避免:添加有效的连接条件。
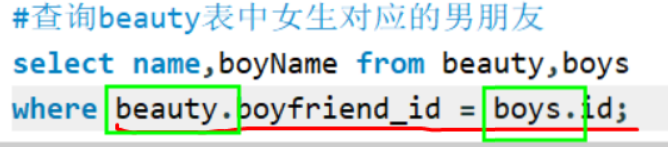
分类-
按年代分类
sql92标准:在mysql中支持内连接,也支持一部分外连接(oracle、sqlserver支持,mysql不支持)。
sql99标准【推荐使用】:在mysql中支持内连接+外连接(左外、右外)+交叉连接。 -
按功能分类
内连接:等值连接、非等值连接、自连接。
外连接:左外连接、右外连接、全连接。
交叉连接。
sql92标准
概述
语法:
select 字段1,字段2.... from 表1,表2.....; 使用的连接方式是:sql92语法- 1
- 2
- 3
等值连接
语法
select 查询列表 from 表1 ,表2 where 表1.key = 表2.key 【and 筛选条件】 【group by 分组字段】 【having 分组后的筛选条件】 【order by 排序字段】- 1
- 2
- 3
- 4
- 5
- 6
- 7
特点
多表等值连接的结果为多表的交集部分。
n表连接,至少需要n-1个连接条件 。
多表的顺序没有要求,可以调换。
一般需要为表起别名。
可以搭配前面介绍的所有子句使用,比如筛选(select)、分组(group by)、排序(order by)。案例

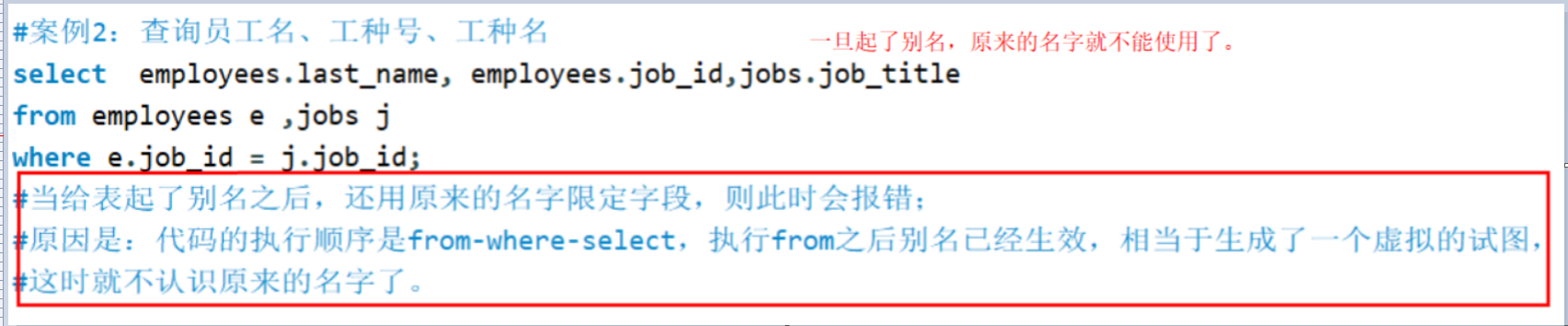
备注2022/7/30- 为表起别名,使用连接查询:
①提高语句的简洁度;
②区分多个重名的字段;
③如果对表起了别名,则查询的字段就不能用原来表名去限定了。
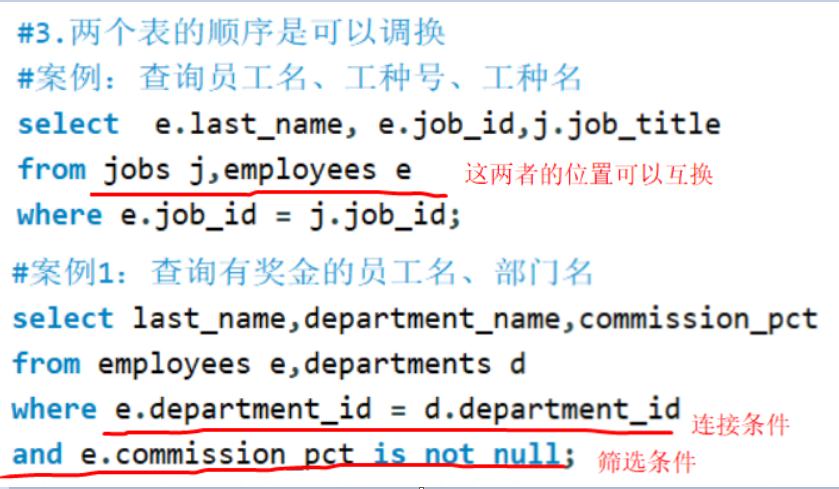
备注
两个表连接,连接条件中的两个表的顺序可以交换;
连接查询中,需要连接条件和筛选条件的时候,and前 = 连接条件,and后=筛选条件。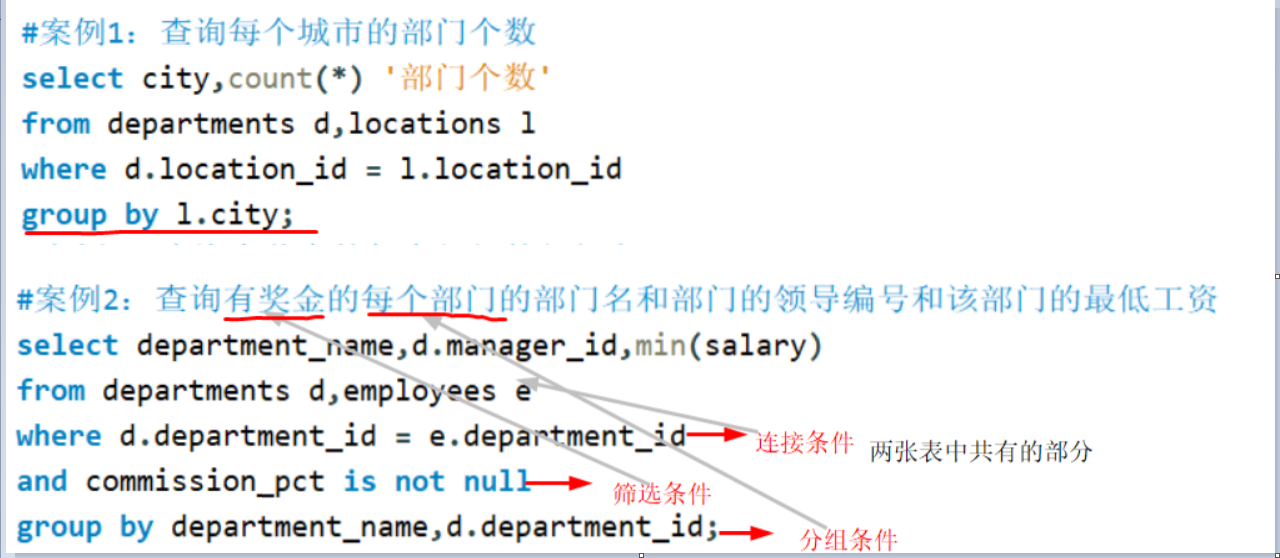
备注
等值连接 可以和分组搭配使用。
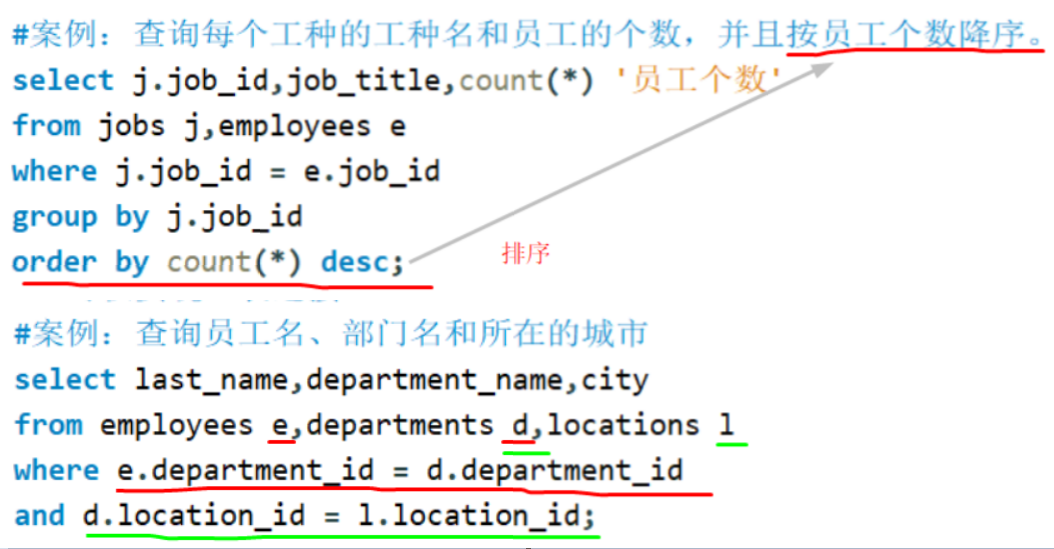
备注
连接查询可以和排序一起存在;
三表连接要求,后一个表和前面已经连接成功的表之间需要有相同的字段。非等值连接
语法
select 字段1,字段2... from 表1 别名1,表2 别名2... where 非等值连接的条件 【and 筛选条件】 【group by 分组条件】 【having 分组后的筛选条件】 【order by 排序字段】- 1
- 2
- 3
- 4
- 5
- 6
- 7
案例
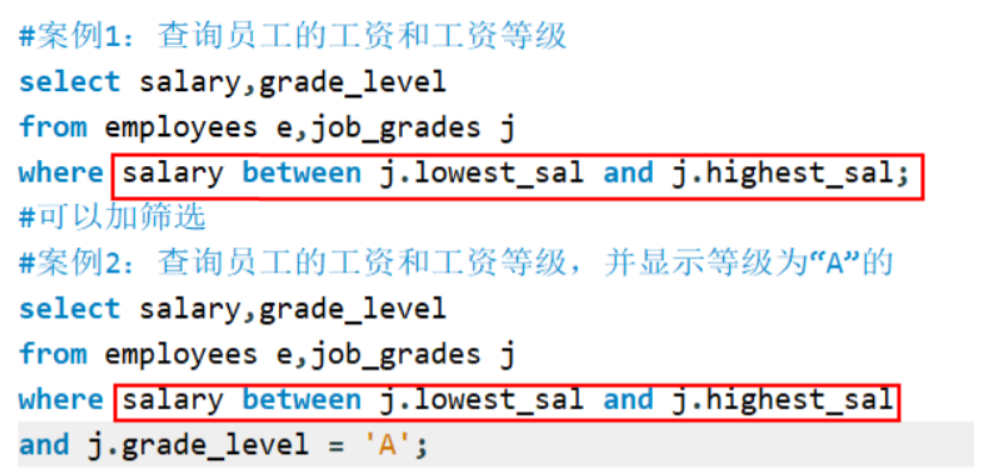
备注
非等值连接 大部分筛选条件都涉及between and。自连接
概念
将自身的表当作多张表去使用。语法
select 字段1,字段2... from 表 别名1,表 别名2 where 等值连接(别名1.key = 别名2.key) 【and 筛选条件】 【group by 分组条件】 【having 分组后的筛选条件】 【order by 排序字段】- 1
- 2
- 3
- 4
- 5
- 6
- 7
案例
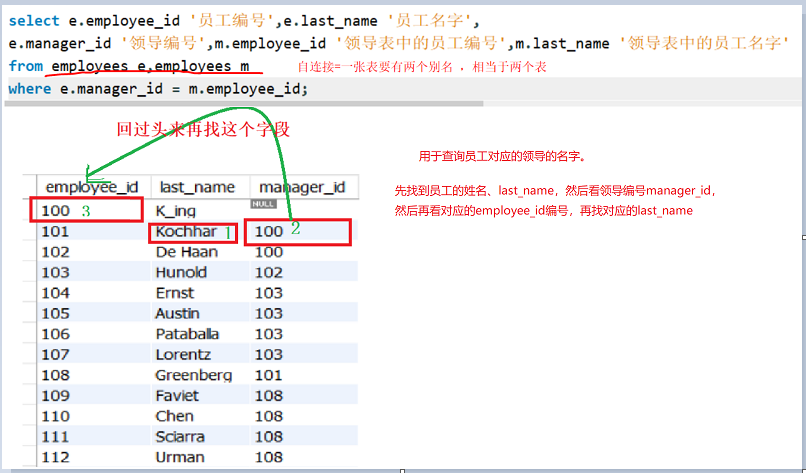
备注
自连接,需要为同一张表取两个别名;案例

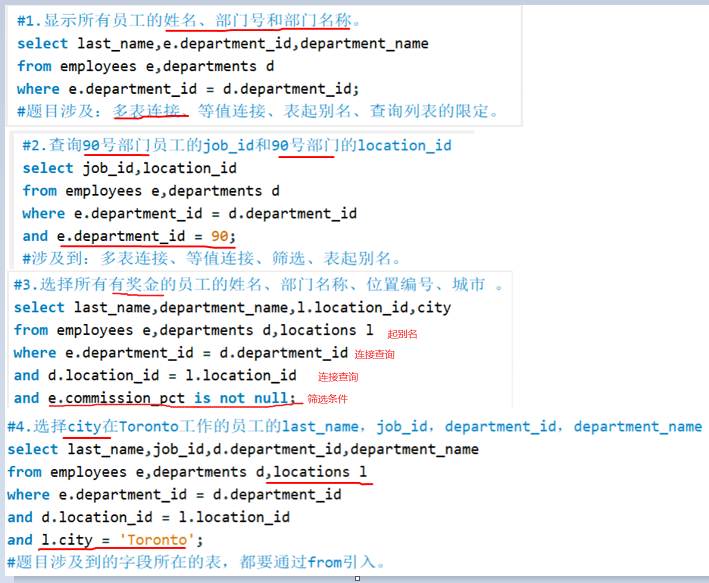
sql99标准
概述
语法
select 查询列表 from 表1 别名1 【连接类型】 join 表2 别名1 on 连接条件 【where 筛选条件】 【group by 分组字段】 【having 分组后的筛选】 【order by 排序列表】- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
分类
内连接:关键字——【inner】
外连接:左外连接(left 【outer】)、右外连接(right 【outer】)、全连接(full 【outer】)
交叉连接:关键字——cross内连接
场景
查询的信息存在于两个表中。语法
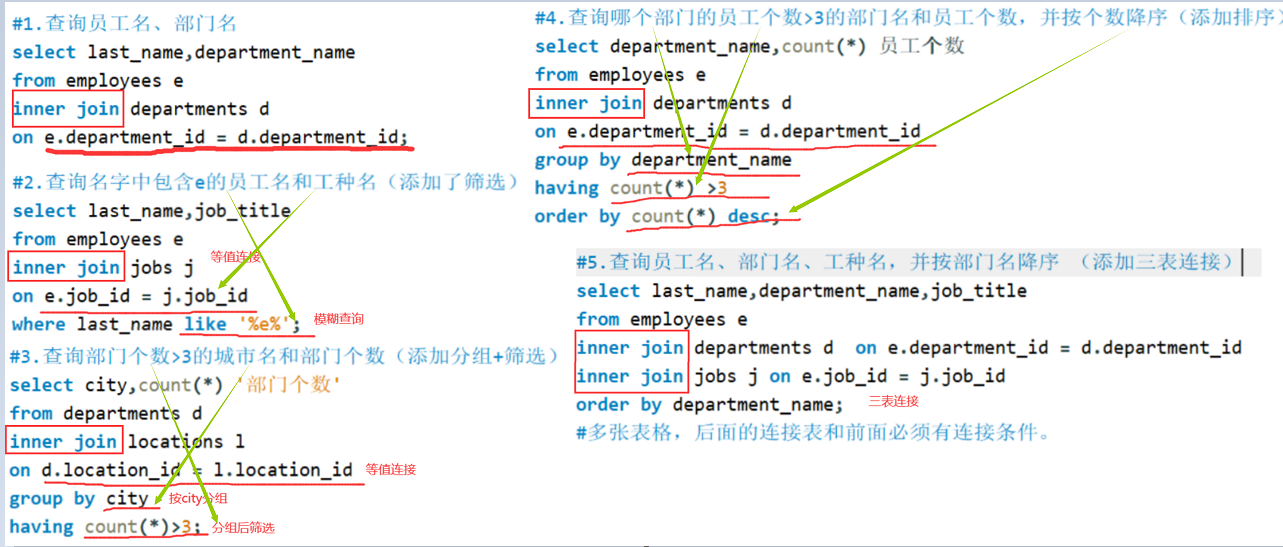
select 查询列表 from 表1 别名1 【inner】 join 表2 别名2 on 连接条件 【where 筛选条件】 【group by 分组条件】 【having 分组后的查询】 【order by 排序字段】- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
特点
添加筛选、分组、排序;
inner可以省略;
筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读;
inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集;
表的顺序可以调换;
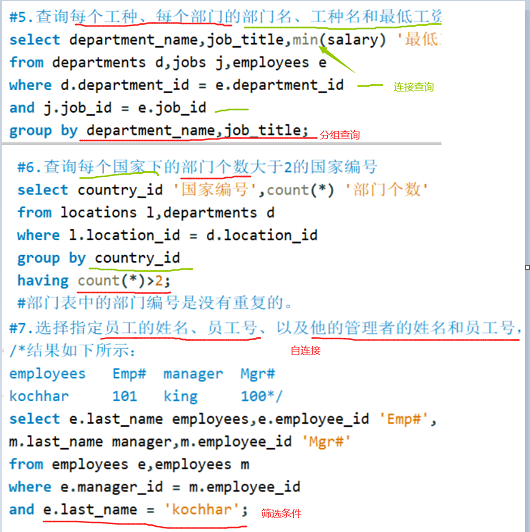
n表连接至少需要n-1个连接条件;多表连接语法
select 查询列表 from 表1 别名1 [type] join 表2 别名2 on 连接条件 [type] join 表3 别名3 on 连接条件 [where 筛选条件] [group by 分组条件] [having 分组后筛选条件] [order by 排序条件];- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
分类
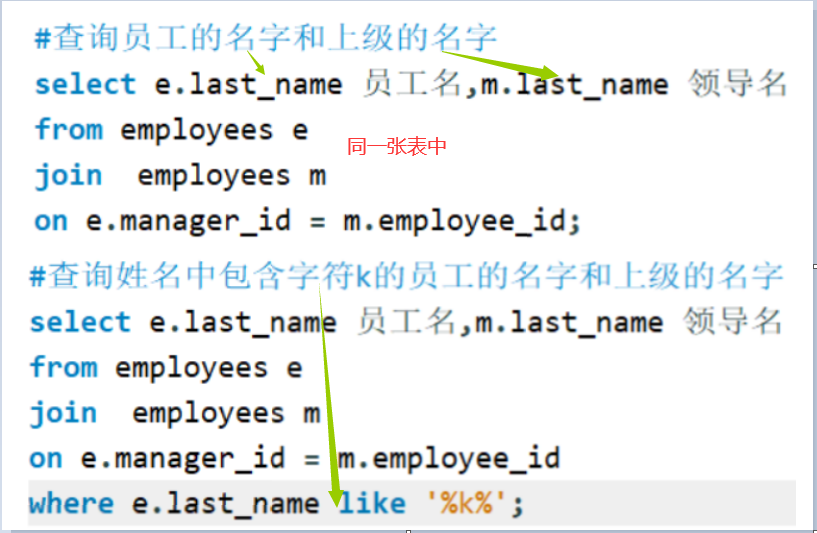
等值连接、非等值连接、自连接案例:等值连接
案例:非等值连接
案例:自连接
外连接
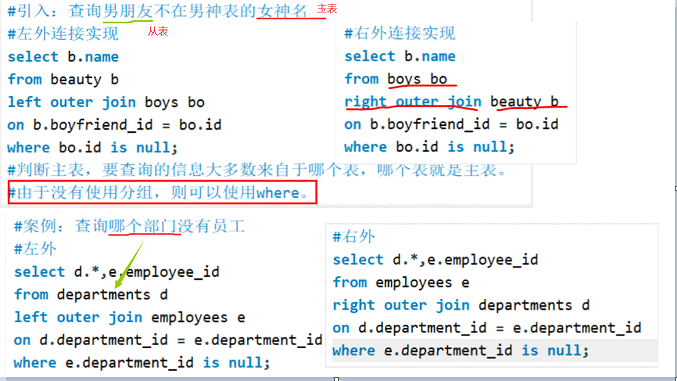
场景
用于查询一个表中有,另一个表没有的记录。语法
select 查询列表 from 表1 别名1 left | right | full 【outer】 join 表2 别名2 on 连接条件 【where 筛选条件】 【group by 分组字段】 【having 分组后的筛选条件】 【order by 排序字段】 【limit 起始索引,长度】;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
特点
-
外连接的查询结果为主表中所有记录(行)
如果从表中有和它匹配的,则显示匹配的值;
如果从表中没有和它匹配的,则显示null;
外连接的查询结果 = 内连接的结果 + 主表中有而从表中没有的记录。 -
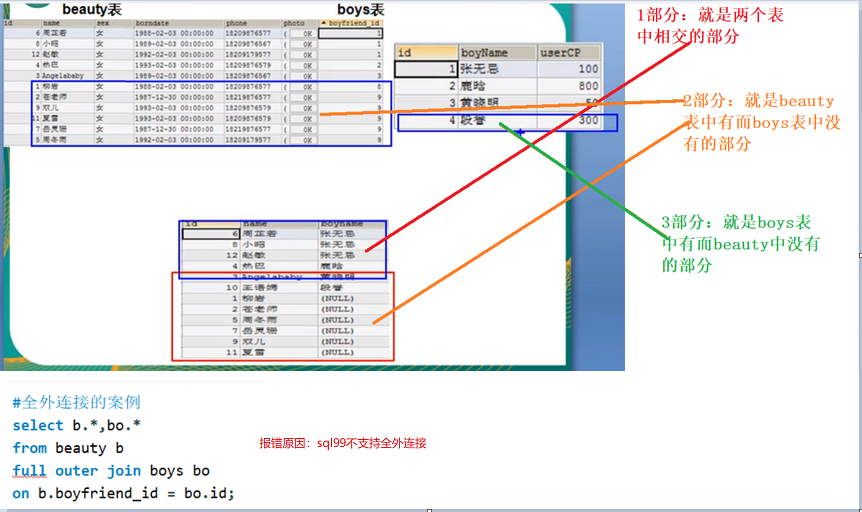
左外、右外、全外介绍
外连接 语法 说明 左外连接 表1 left 【join】 表2 on 连接条件 左边是主表(表1) 右外连接 表1 right 【join】 表2 on 连接条件 右边是主表(表2) 全外连接 表1 full 【join】 表2 on 连接条件 两边都是主表(表1 和 表2) - 一般用于查询除了交集部分的剩余的不匹配的行。
- 左外和右外交换两个表的顺序,可以实现同样的效果。
例如:表1 left 【outer】 join 表2 等价于 表2 right 【outer】 join 表1 - 全外连接 = 内连接的结果 + 表1中有但表2没有的 + 表2中有但表1没有的。
如果想实现只有后两者的情况,那么需要的就是添加where条件。 - 主表和从表的判断,大部分信息来自于哪个表,哪个表就是主表,另一个就是从表。
- sql99规则不支持全外连接
案例:左外连接 、右外连接
案例:全外连接
交叉连接
语法
select 查询列表 from 表1 别名1 cross join 表2 别名2;- 1
- 2
- 3
特点
类似笛卡尔乘积。案例

总结
sql92 和sql99 比较
功能:sql99支持的较多。
可读性:sql99实现连接条件和筛选条件的分离,可读性较高。join连接总结(sql99)




案例
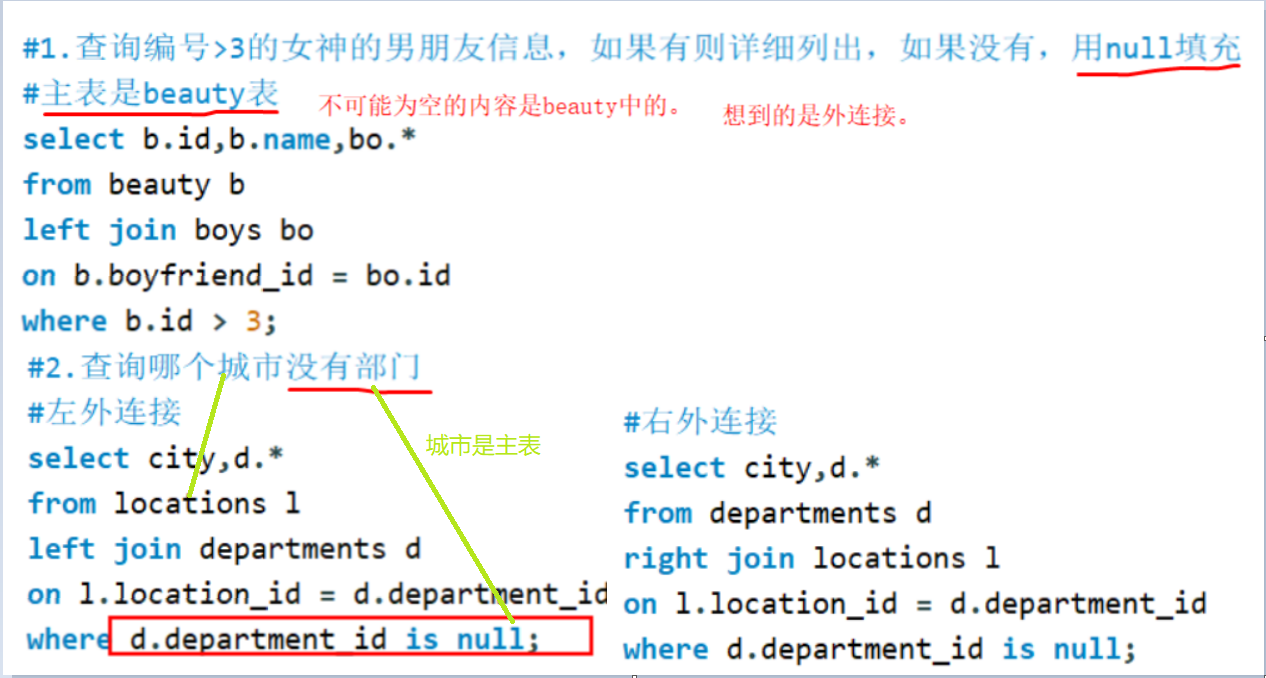
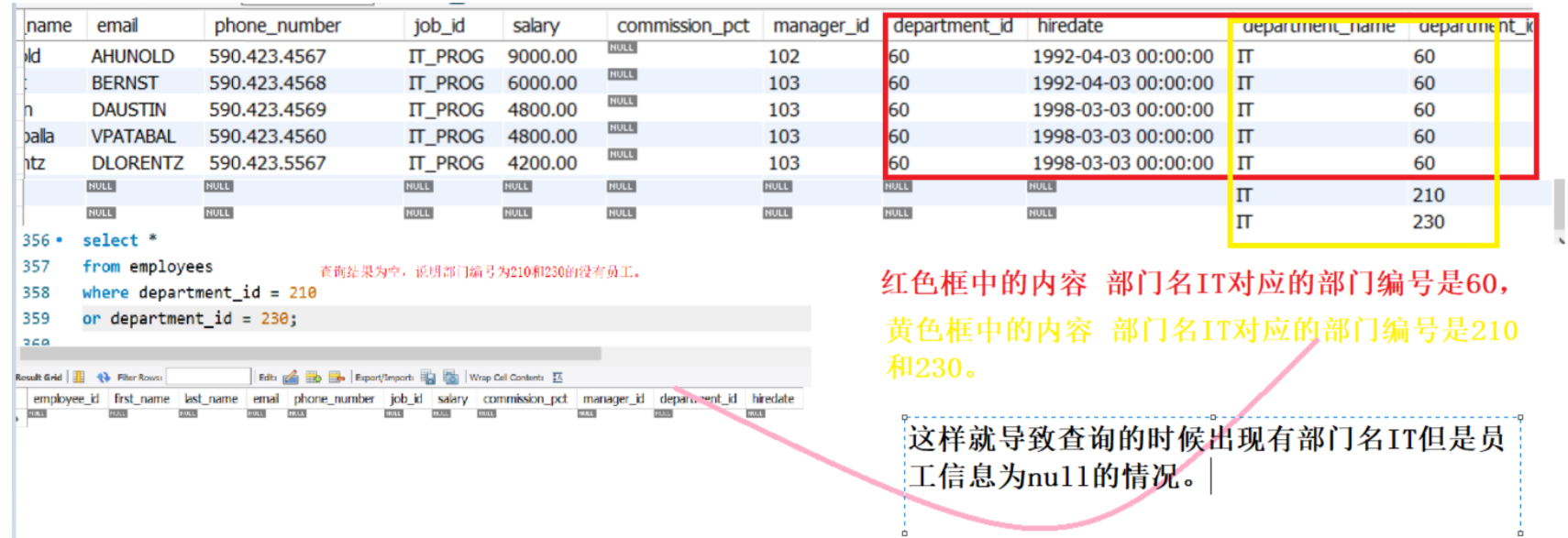
备注
没有使用外连接查询。
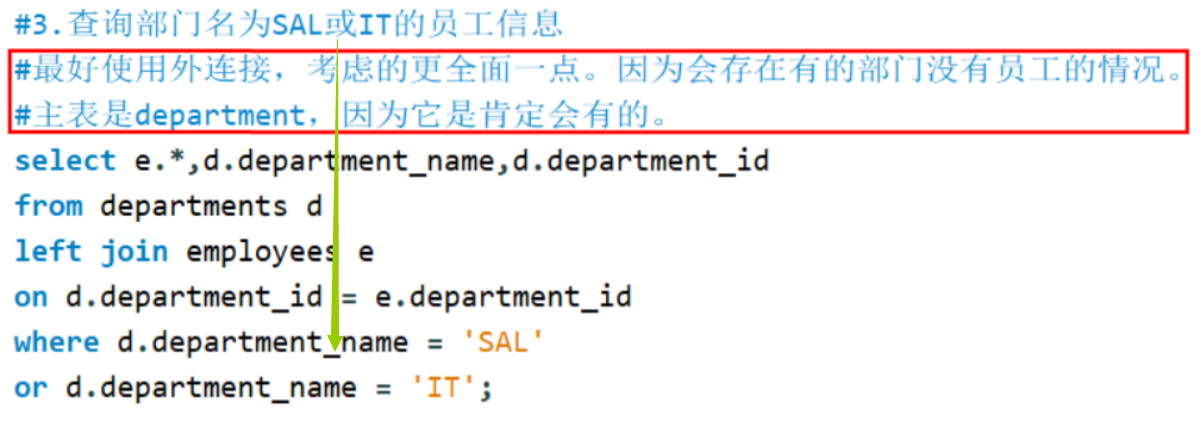
子查询
概述
概念
嵌套在其他语句中的select语句,称为子查询或内查询。
外面的语句可以是insert、update、delete、select等,一般select作为外语句较多。
外部如果是select语句,则此语句称为主查询或外查询。分类:子查询出现的位置
位置 结果集 select后面 标量子查询 from后面 表子查询 where 或 having后面 标量子查询(单行)
列子查询(多行)
行子查询exists后面 标量子查询
列子查询
行子查询
表子查询分类:结果集的行列数
种类 结果集 标量子查询 单行子查询
一行一列列子查询 多行子查询
多行一列行子查询 一行多列、多行多列 表子查询 一般多行多列 where 或having后面
概述
结果集
标量子查询(一行一列)、列子查询(多行一列)、行子查询(一行多列 或 多行多列)
没有表子查询。特点
- 子查询放在小括号内。
- 子查询一般放在条件的右侧。
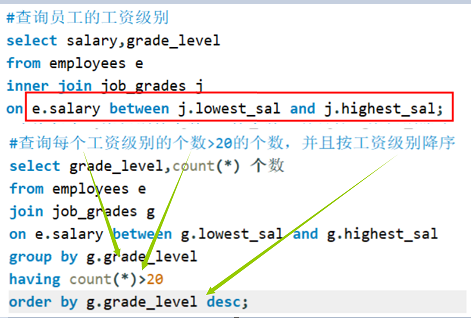
- 标量子查询,一般搭配着单行操作符使用(单行操作符> < = <= >= <>)。
- 列子查询,一般搭配着多行操作符使用(多行操作符 in、any/some、all)。
多行操作符介绍:
符号 含义 in 等于列表中的任意一个 not in 不等于列表中的任意一个 any / some 和子查询返回的某一个值比较 all 和子查询返回的所有值比较 举例:
假设a>any(1,2,3,4,5)——a大于括号中的任何一个,为真,否则为假;
假设a>all(1,2,3,4,5)——a大于括号中的所有,为真,否则为假;- 子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果。
案例:非法子查询
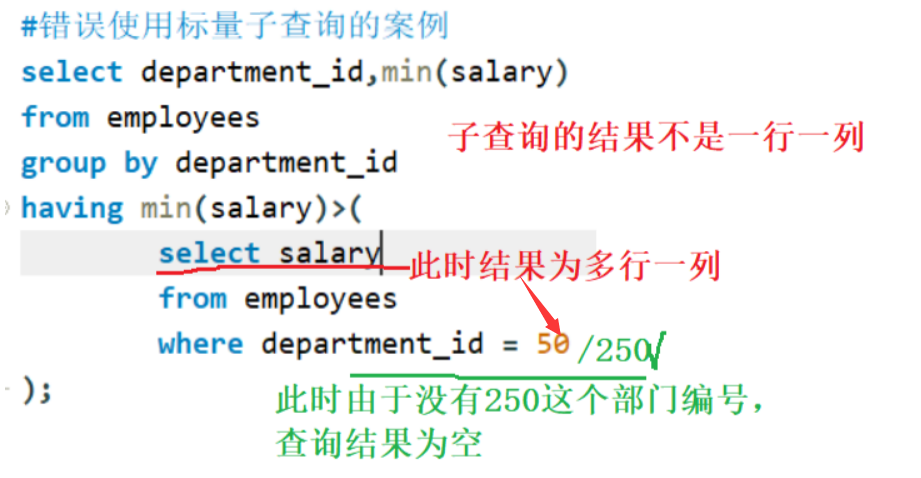
备注
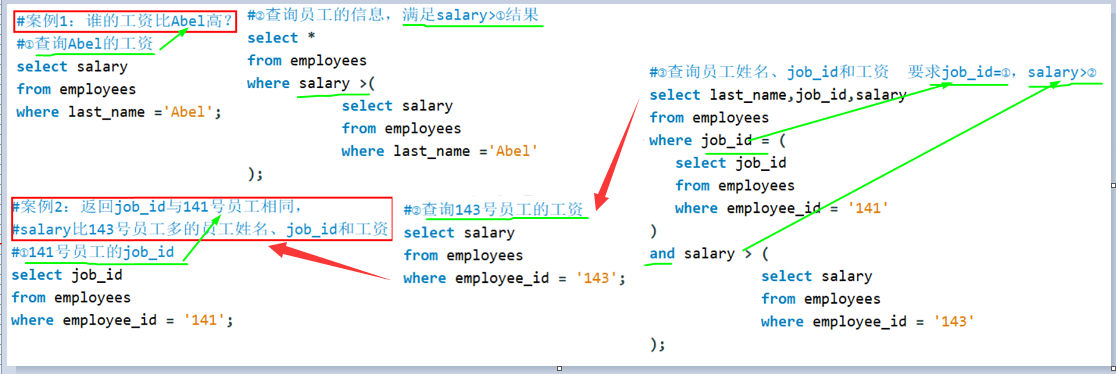
子查询使用的是单行操作符,则子查询必须是标量子查询,但是题目中却是列子查询(多行一列),所以报错。案例:标量子查询
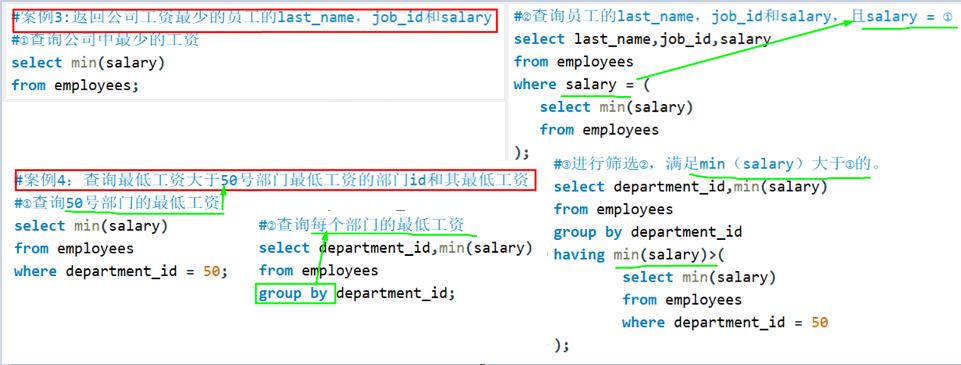
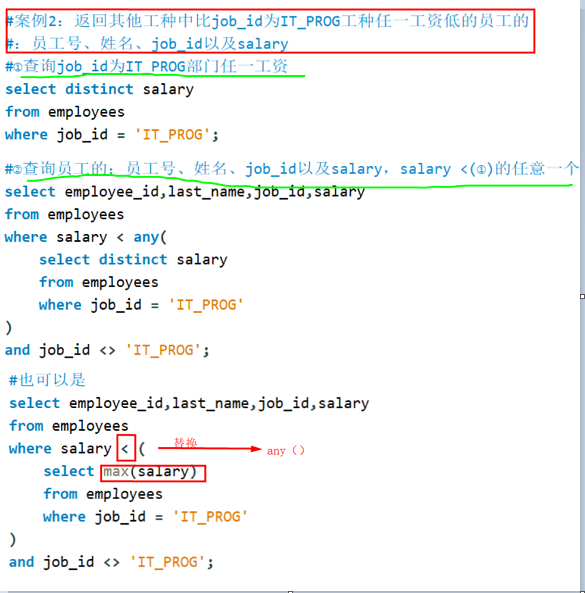
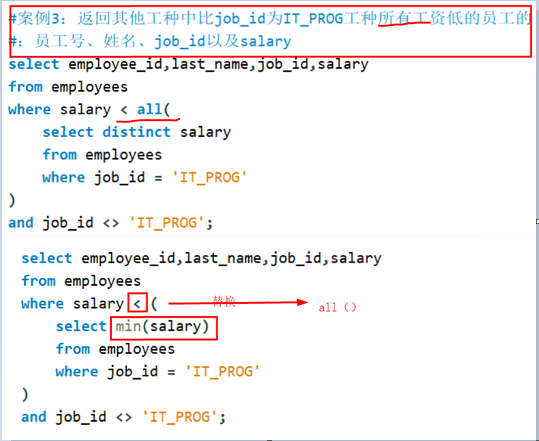
案例:列子查询

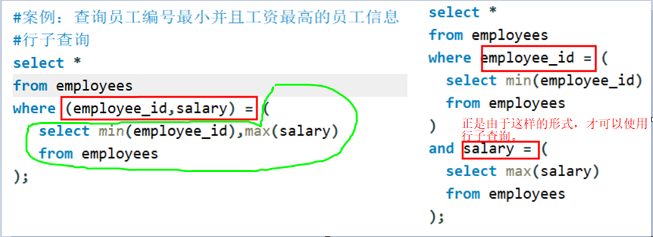
案例:行子查询
select后面
概述
结果集
仅仅支持标量子查询(一行一列)案例:标量子查询
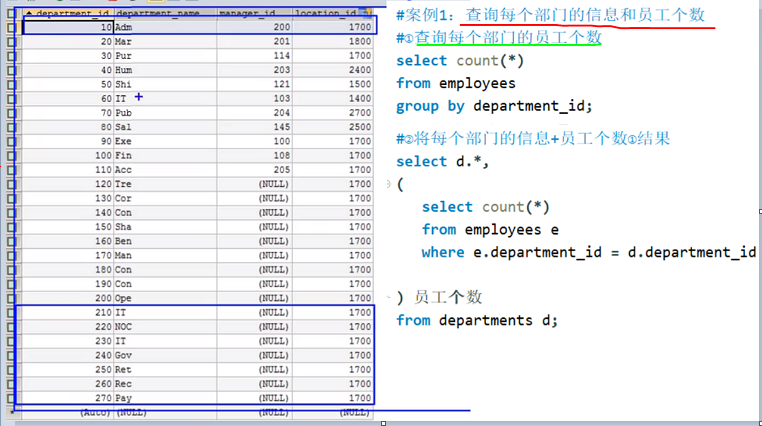
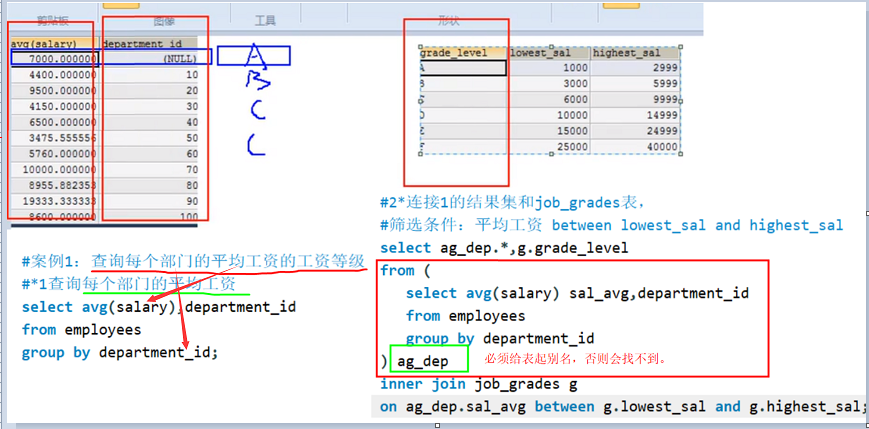
from后面
概述
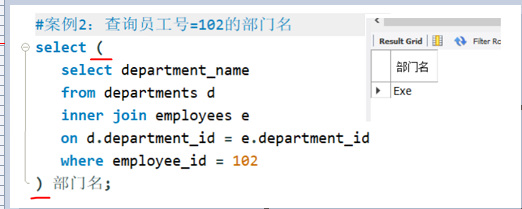
要求把子查询的结果集当成一张表,必须给表起别名。
案例:表子查询
exists后面
概述
语法
exists(完整的查询语句) 返回值是:0 或者 1- 1
- 2
作用
用于判断子查询是否有记录。案例

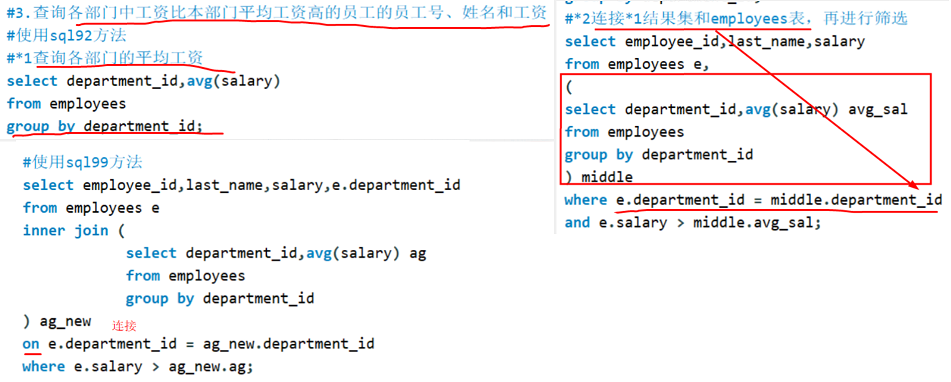
子查询案例
where后面 : = >
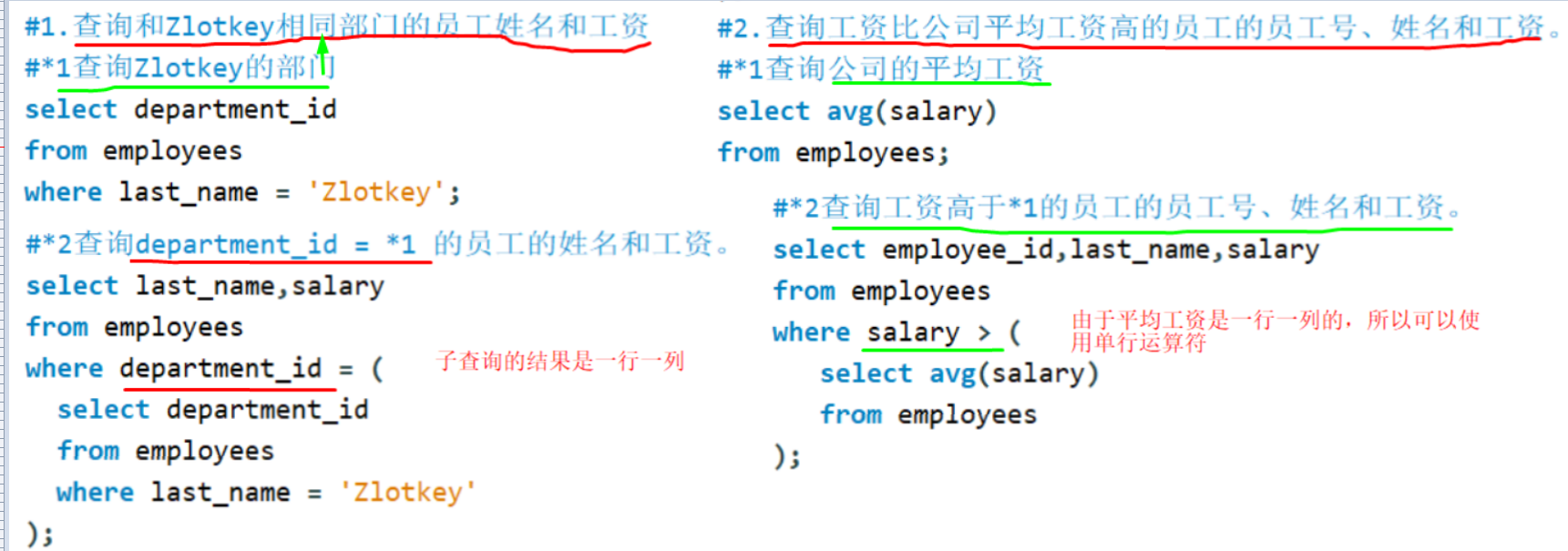
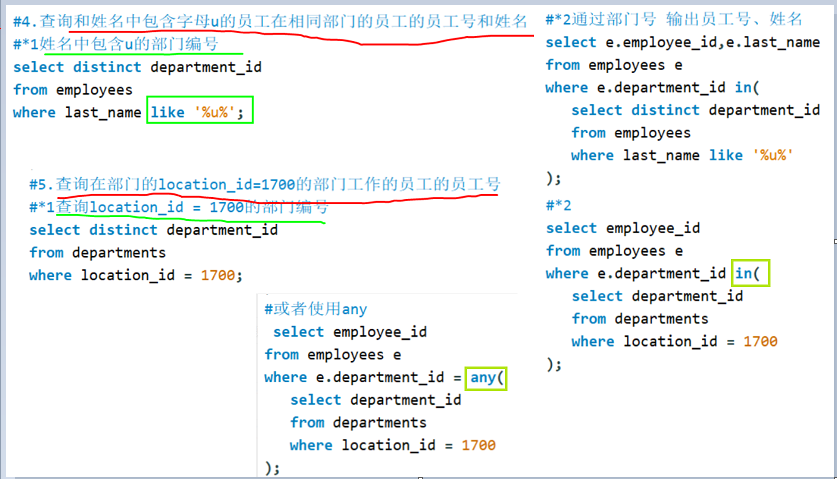
**from后面 **
where后面:in any
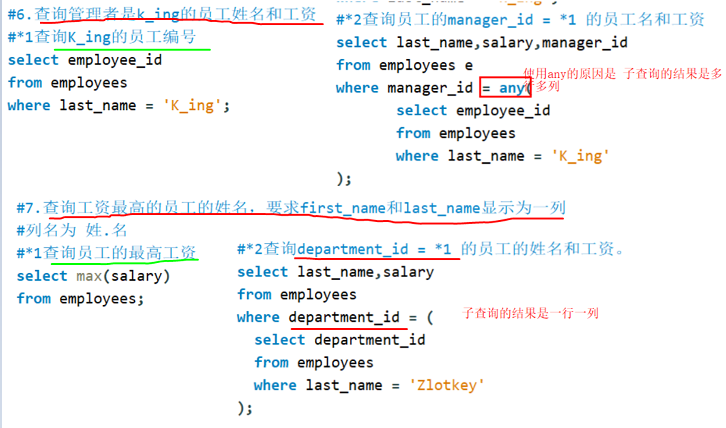
where后面:标量子查询
分页查询
概述
应用场景
当要显示的数据条目数太多,一页显示不全,需要分页提交sql请求 。语法
select 查询列表 from 表1 [连接类型] join 表2 # 采用sql99连接 on 连接条件 where 筛选条件 group by 分组字段 having 分组后的筛选条件 order by 排序字段 limit [offset,] size; # offset:要显示条目的起始索引(索引从0开始); # size:要显示的条目数。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
特点
- limit语句放在查询语句的最后;
- 执行顺序
from→on→where→group by→having→order by→select→limit - 要显示的页数是page,每一页的条目数是size
第一页 起始0 结束9 个数10
第二页 起始10 结束19 个数10
起始索引 = (page-1)*size
语法:
select 查询列表 from 表 limit (page - 1)*size,size;- 1
- 2
- 3
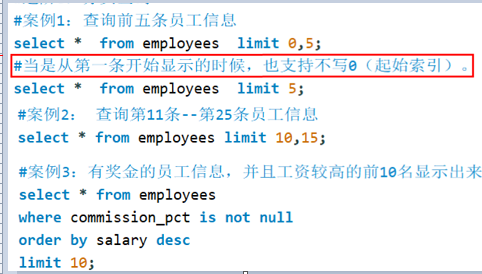
案例:limit
案例:stuinfo
分析2022/7/31
①涉及到数字函数 instr、substr;
②分组group by、分组后筛选having;
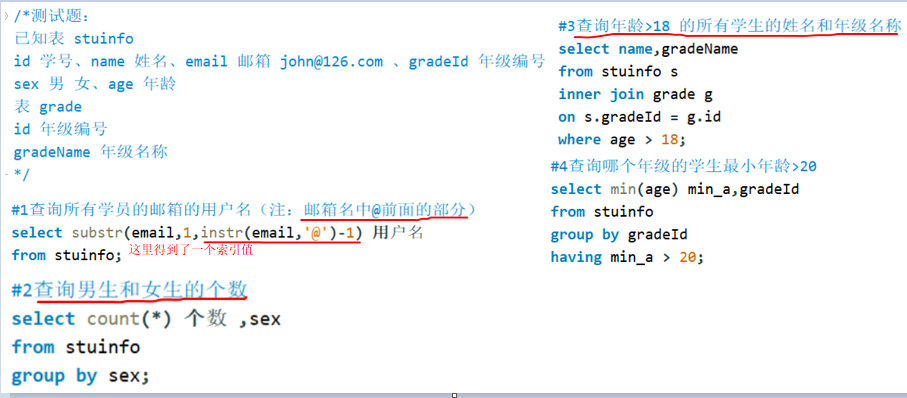
案例
**where后面:标量子查询 = **


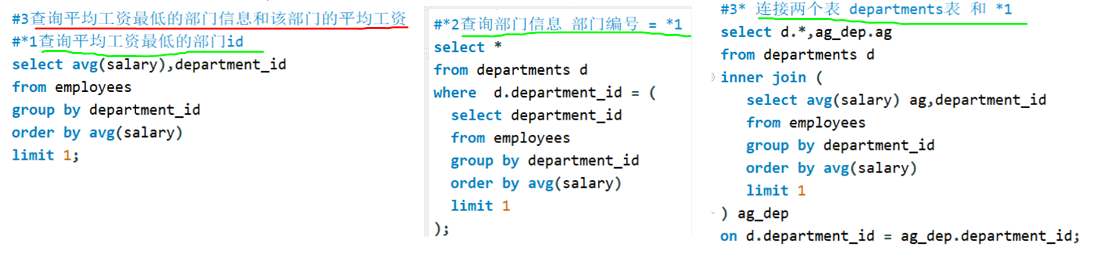
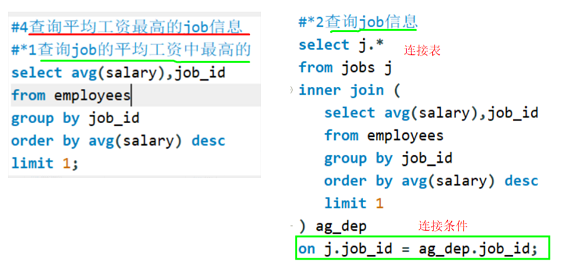
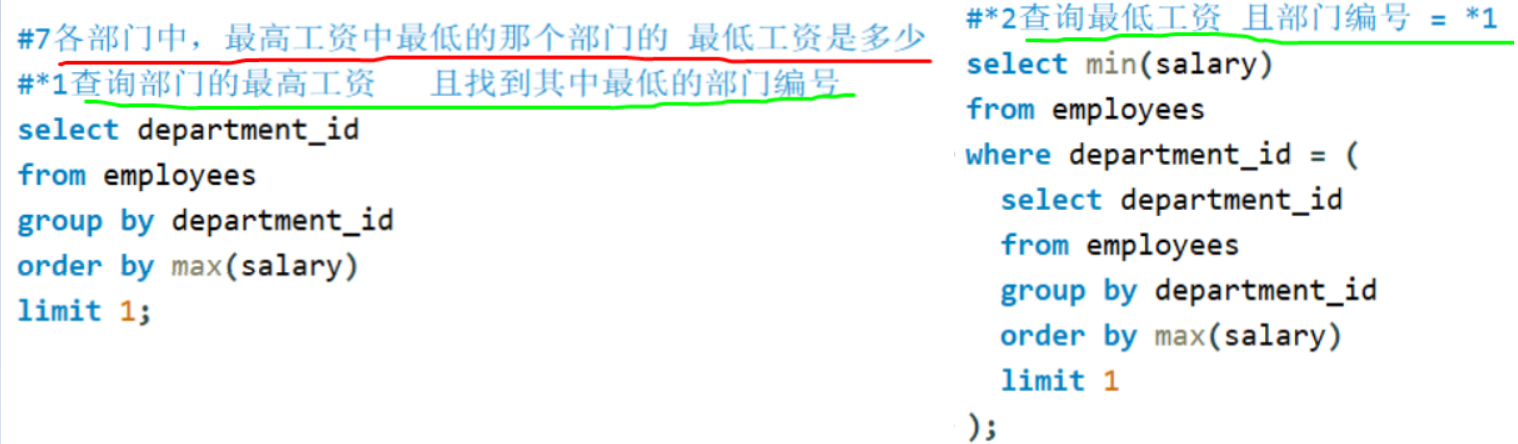
备注:分组后筛选
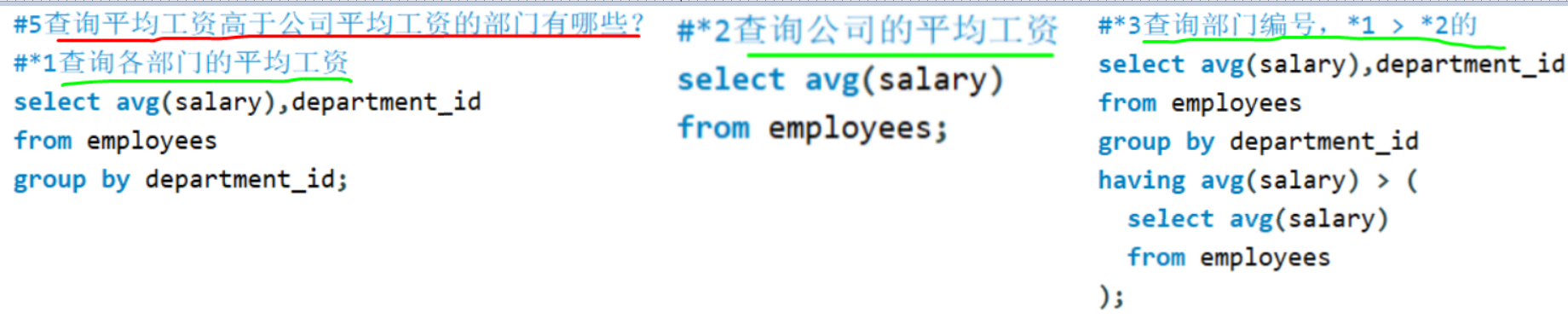
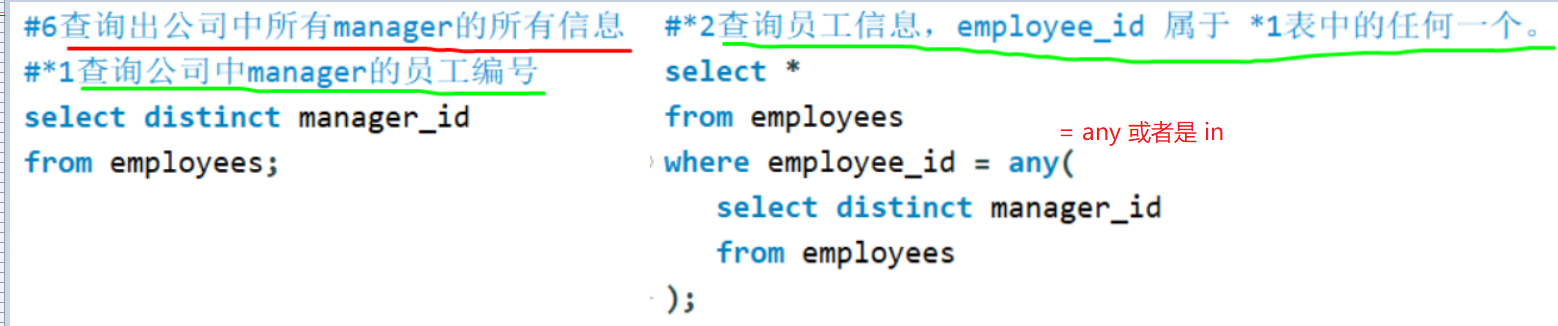
备注: = any 或者 in
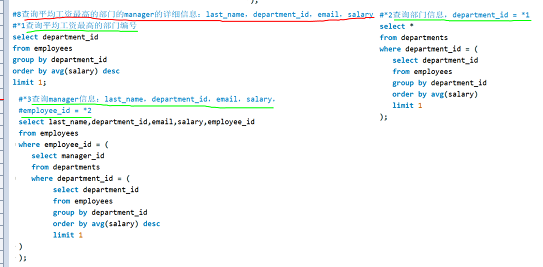
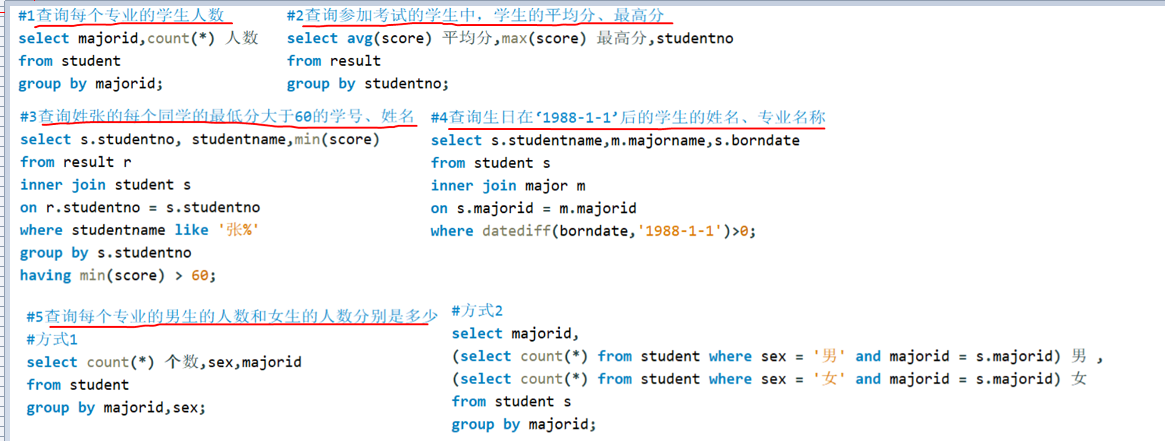
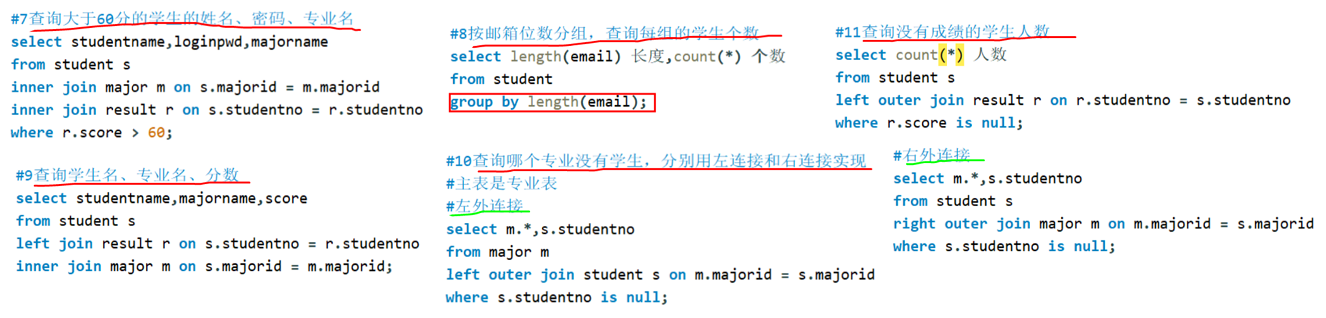
作业案例
联合查询
概述
概念
union 联合 合并:将多条查询语句的结果合并成一个结果语法
查询语句1 union [all] 查询语句2 union [all]- 1
- 2
- 3
- 4
应用场景
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致特点
多条查询语句的查询列数是一致的。
多条查询语句查询的每一列的类型和顺序最好是一致的。
union关键字默认是去重的,如果使用union all可以包含重复项。意义
将一条比较复杂的查询语句拆分成多条语句。
适用于查询多个表的时候,查询的列基本是一致的。案例

-
相关阅读:
docker
java多线程
Linux学习之:环境变量
Linux操作文档——Oracle数据库备份与恢复
目标检测YOLO实战应用案例100讲-基于单阶段网络的小目标检测(下)
pycharm的debug,你知道每个按钮对应哪个功能吗?
高可用网站架构云化
【Java】二月份有多少天?
【业务功能篇 131】23种设计模式介绍
29. 一道简单背包题
- 原文地址:https://blog.csdn.net/LXMXHJ/article/details/126060771