-
【记第一次kaggle比赛】PetFinder.my - Pawpularity Contest 宠物预测
前言
记半年前打的一次”划水“Kaggle比赛,第一次打Kaggle比赛所以选了个比较简单的分类比赛,但是打到一半发现这个比赛也不容易,表明上是个分类比赛,其实又可以看作回归问题来做,而且还有很多的Meta数据,又可以当作多模态问题来做,再加上3500+的参赛人数,比赛难度直线上升。
最终是拿到了A榜800多名,B榜700多名的成绩。虽然名次有点划水,但是还是从中学到很多东西的。半年前打的比赛,当时名次比较差气的不想看,就没有心思记录,最近找工作整理一下这个比赛,发现好多细节已经忘了,所以又翻开代码重头过了一遍,这里再记录一下防止以后又忘了。
最后,想说下,大家千万不要像我这样,打比赛还是以学东西为重,特别是刚开始参加比赛,不要把排名看的太重要!
一、数据介绍
数据给了很多的宠物数据(全是猫狗),让我们给这些猫狗打分,对宠物的可爱度打分,总共有1-100分,评分标准是均方根误差,所以这其实是一个回归问题。同时,比赛除了给了每张图片的分数,还给了每张图片的12个视觉信息和构图信息,比如图片当中面部是否是面向正面,宠物是否佩戴配饰等等,所以我们又可以利用这些Meta信息和图像信息来进行一个多模态融合。
所以说整个任务:多模态融合的分类任务
训练集:9912张图片 测试集:6800张图片
评价指标:RMSE 均方根误差 :误差平方和取均值再开根

图片的分辨率大部分在400-800之间,是否可以使用400-800之间的多尺度训练?
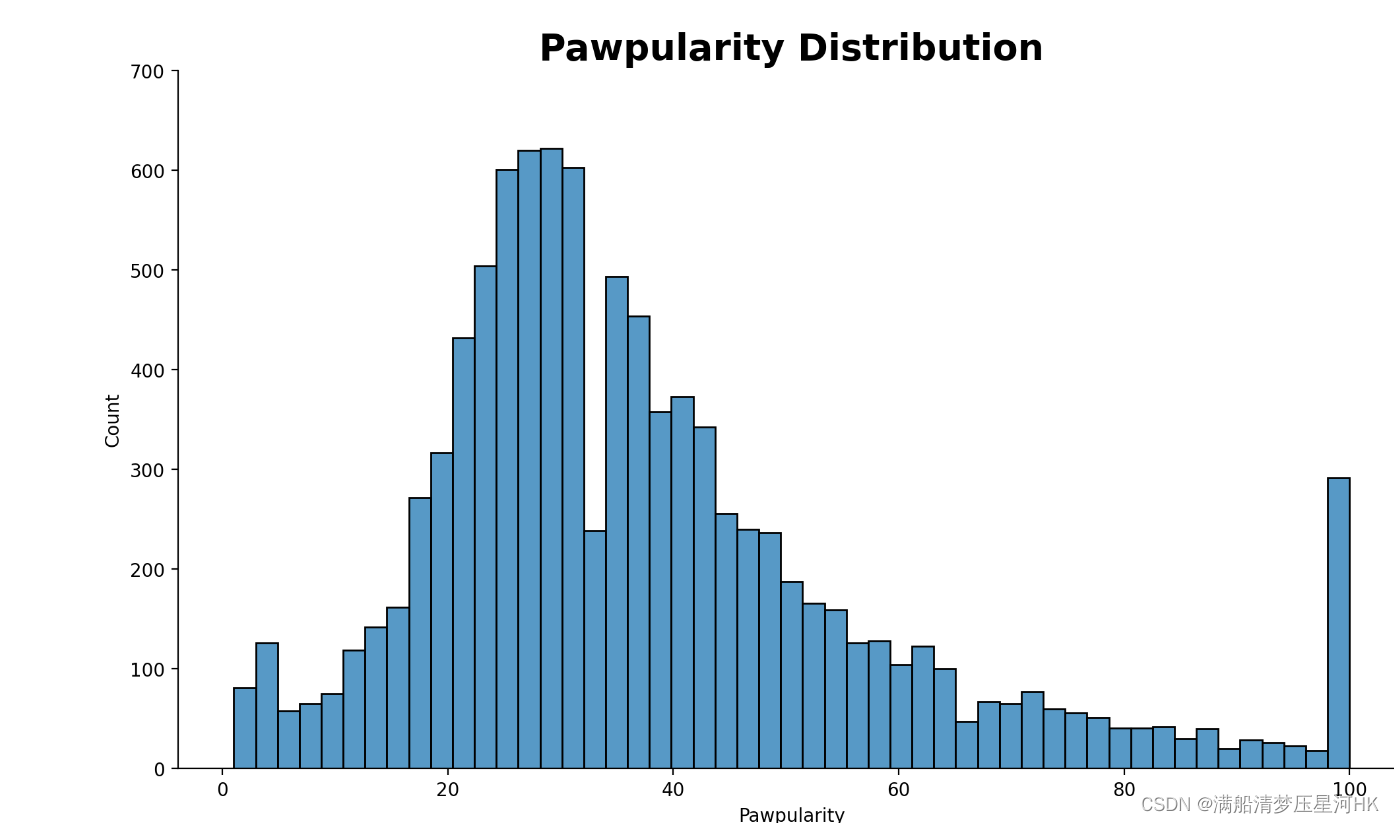
1-100个打分分布(呈现类似正太分布 大部分集中在20-60分之间):
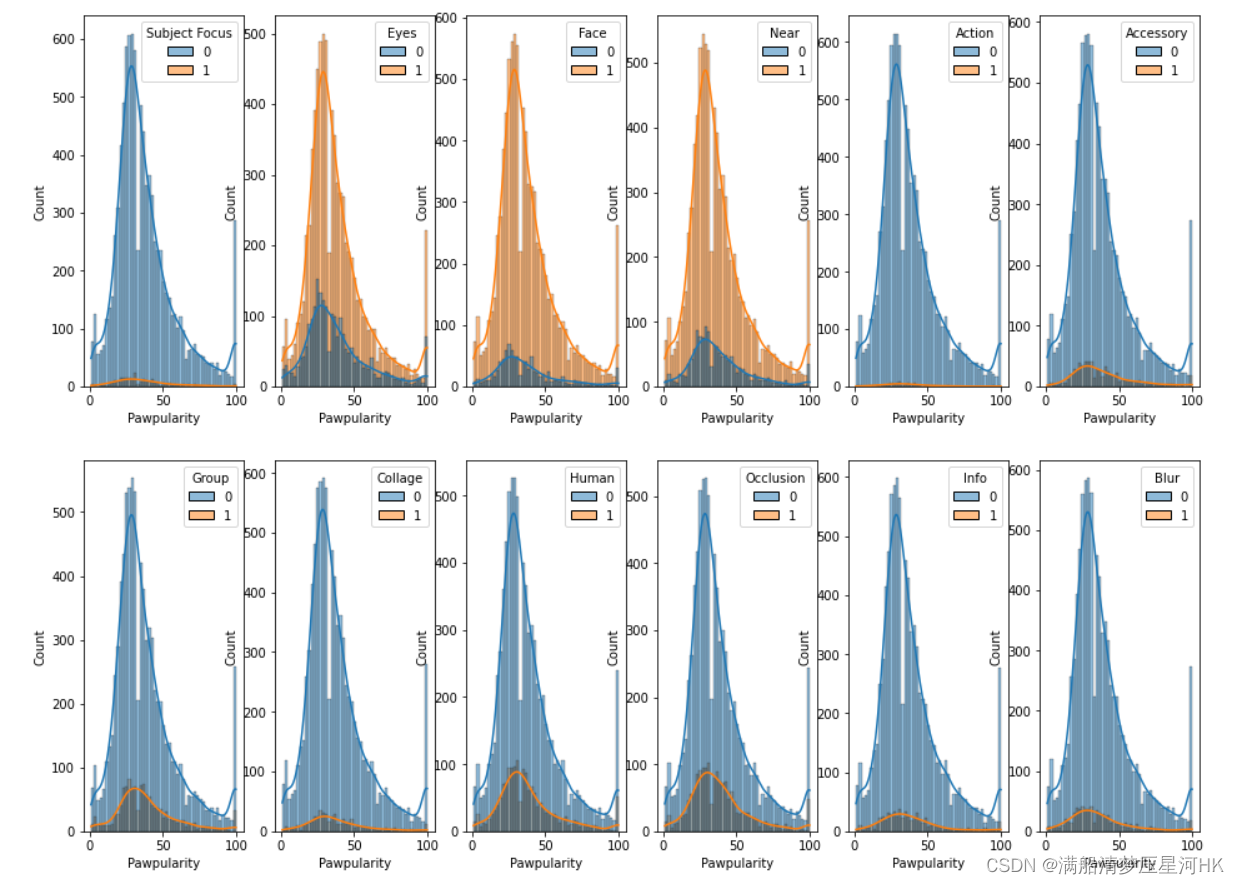
12个Meta数据介绍:
- 焦点 - 宠物在整洁的背景中脱颖而出,而不是太近/太远。
- 眼睛 - 双眼朝前或近前,至少有1只眼睛/瞳孔清晰。
- 面部 - 体面清晰的脸,面向正面或近前方。
- 近 - 单只宠物占据了照片的很大一部分(大约超过照片宽度或高度的50%)。
- 动作 - 在动作(例如,跳跃)中途的宠物。
- 配件 - 随附的物理或数字配件/道具(即玩具、数码贴纸),不包括衣领和皮带。
- 团体 - 照片中有超过1只宠物。
- 拼贴 - 数字修饰的照片(即使用数码相框,多张照片的组合)。
- 人类 - 照片中的人类。
- 遮挡 - 特定的不良物体阻挡宠物的一部分(即人,笼子或围栏)。请注意,并非所有遮挡对象都被视为遮挡。
- 信息 - 自定义添加的文本或标签(即宠物名称、描述)。
- 模糊 - 明显失焦或嘈杂,特别是对于宠物的眼睛和脸部。对于模糊条目,“眼睛”列始终设置为 0。
每个Meta数据都是0-1分布的二元值(稀疏特征)
12个Meta数据分布情况:
训练集实例:

二、我的探索
2.1、基于Classification Head的方案
原本的问题是一个回归任务:对猫狗图片打分0-100分,评分标准均方根损失函数。
这里把它转为2分类任务,把gt标签1-100归一化到0-1,0表示不受欢迎,1表示收欢迎。预测输出一个数,再取sigmoid归一化到0-1,再*100就是最终预测的分数。
baseline方案:训练时输入一张图像,然后经过一个backbone输出特征,然后接一个全连接层输出一个预测值,再和归一化后的gt计算交叉熵损失(BCEWithLogitsLoss)。测试时就将预测值先进行sigmoid处理再*100,得到一个0-100的值,提交submission.csv,然后后台计算平方根损失函数,得到分数。
配置:
框架:pytorch_lightning swin_large_patch4_window7_224 5折交叉验证:StratifiedKFold batch_size = 16 epoch = 10 optimizer:AdamW scheduler:CosineAnnealingWarmRestarts lr = 1e-5 loss:BCEWithLogitsLoss data aug: RandomHorizontalFlip RandomVerticalFlip() RandomAffine ColorJitter- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
lb = 18.37 排1800多名 好家伙,这比赛真卷啊
2.1.1、删除重复数据(打分差别很大)
这个比赛会有一些重复的数据,而且这些重复的数据他的label都相差的比较大的,会对模型造成很大的伤害,而且官方是建议删除label小的那些图片。
来自这几个Discussion:
Correcting errors in data!Identify duplicates and share findings (+ dataset w/o duplicates)
there are no usages of duplicate images
代码:
def return_imgfilepath(name, folder=Config.img_train_dir): path = os.path.join(folder, f'{name}.jpg') return path train_df = pd.read_csv(os.path.join(Config.data_dir, 'train.csv')) # set image filepath train_df['file_path'] = train_df['Id'].progress_apply(lambda x: return_imgfilepath(x)) # del 27 image del_list = ["b148cbea87c3dcc65a05b15f78910715", "9a0238499efb15551f06ad583a6fa951", "e359704524fa26d6a3dcd8bfeeaedd2e", "5a642ecc14e9c57a05b8e010414011f2", "bf8501acaeeedc2a421bac3d9af58bb7", "01430d6ae02e79774b651175edd40842", "1feb99c2a4cac3f3c4f8a4510421d6f5", "6ae42b731c00756ddd291fa615c822a1", "13d215b4c71c3dc603cd13fc3ec80181", "3877f2981e502fe1812af38d4f511fd2", "5ef7ba98fc97917aec56ded5d5c2b099", "988b31dd48a1bc867dbc9e14d21b05f6", "9b3267c1652691240d78b7b3d072baf3", "72b33c9c368d86648b756143ab19baeb", "2b737750362ef6b31068c4a4194909ed", "b49ad3aac4296376d7520445a27726de", "9f5a457ce7e22eecd0992f4ea17b6107", "dd042410dc7f02e648162d7764b50900", "a9513f7f0c93e179b87c01be847b3e4c", "1059231cf2948216fcc2ac6afb4f8db8", "87c6a8f85af93b84594a36f8ffd5d6b8", "8ffde3ae7ab3726cff7ca28697687a42", "dbc47155644aeb3edd1bd39dba9b6953", "38426ba3cbf5484555f2b5e9504a6b03", "54563ff51aa70ea8c6a9325c15f55399", "fe47539e989df047507eaa60a16bc3fd", "78a02b3cb6ed38b2772215c0c0a7f78e"] train_df = train_df.drop(train_df[train_df["Id"].isin(del_list)].index).reset_index(drop=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
lb = 18.35
2.1.2、数据增强
常规的数据增强:
transform = { "train": T.Compose( [ T.RandomHorizontalFlip(p=0.5), # 图像几乎都是正着的图像 # T.RandomVerticalFlip(p=0.5), 没有意义 没用倒着的宠物 T.RandomAffine(15, translate=(0.1, 0.1), scale=(0.9, 1.1)), # 缩放 平移 旋转 T.ColorJitter(brightness=0.1, contrast=0.1, saturation=0.1), # 色彩抖动 T.ConvertImageDtype(torch.float), T.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD), ] ), "val": T.Compose( [ T.ConvertImageDtype(torch.float), T.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD), ] ),- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
因为这个任务很像一个细粒度分类的任务,所以我用了mixup数据增强,代码:
def mixup(x: torch.Tensor, y: torch.Tensor, alpha: float = 0.1): assert alpha > 0, "alpha should be larger than 0" assert x.size(0) > 1, "Mixup cannot be applied to a single instance." lam = np.random.beta(alpha, alpha) rand_index = torch.randperm(x.size()[0]) mixed_x = lam * x + (1 - lam) * x[rand_index, :] target_a, target_b = y, y[rand_index] return mixed_x, target_a, target_b, lam # train model # 以0.5的概率进行mixup if torch.rand(1)[0] < 0.5 and mode == 'train': # mix_images = [2, 3, 224, 224] # target_a = [0.47, 0.36] = labels # target_b = [0.36, 0.47] # lam: 0.32680363842002164 mix_images, target_a, target_b, lam = mixup(images, labels, alpha=0.2) logits = self.forward(mix_images).squeeze(1) # loss = self._criterion(logits, target_a) * lam + \ (1 - lam) * self._criterion(logits, target_b) else: logits = self.forward(images).squeeze(1) # labels = [0.2000, 0.2100] logits = [0.1757, -0.0525] loss = self._criterion(logits, labels)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
删掉随机垂直翻转,lb = 18.34
mixup(alpha=0.2,p=0.5):lb = 18.312.1.3、损失函数
一开始为了和评价指标均方根误差对齐用的是均方根损失,但是后来发现效果不好,就改成了交叉熵损失函数:SmoothBCEwLogits(把sigmoid层加入了BCE上)系数=0.1,训练更稳定,防止上溢和下溢问题。work可能原因:
均方根损失对预测值均值的移动是敏感的,而Dropout和BN都会造成均值移动,而BCE对均值移动是不敏感的 RSME is very sensitive to Neural Networks shifting prediction means. Using dropout and batch norm will shift means. BCE is not sensitive to shifting means.- 1
- 2
改进:CrossEntropyLabelSmooth 标签平滑:这个比赛的标签可能本身就是有问题的,因为对宠物的可爱度打分,这根本就没有一个标准的定义可爱度是什么?每个人定义的宠物可爱也不一样,就像我在数据集里找过,两只长的差不多的狗,但是他的可爱度就相差了很多。所以我对于这个比赛的标签是存在疑虑的。
而如果本身的标签就有问题的话,对于模型的伤害是很大的,因为模型会强行学习这些错误样本,可能让模型在一定程度上过拟合,下次在测试集里看到差不多的样本,可能预测出来就完全错了。所以为了降低标签错误带来的影响,我使用了标签平滑的策略,相当于降低对错误样本的损失(关注),算是一种损失正则。具体原理看这篇博客: 【trick 1】Label Smoothing(标签平滑)—— 分类问题中错误标注的一种解决方法
class SmoothBCEwLogits(_WeightedLoss): def __init__(self, weight = None, reduction = 'mean', smoothing = 0.0, pos_weight = None): super().__init__(weight=weight, reduction=reduction) self.smoothing = smoothing self.weight = weight self.reduction = reduction self.pos_weight = pos_weight @staticmethod def _smooth(targets, n_labels, smoothing = 0.0): assert 0 <= smoothing < 1 with torch.no_grad(): targets = targets * (1.0 - smoothing) + 0.5 * smoothing return targets def forward(self, inputs, targets): targets = SmoothBCEwLogits._smooth(targets, inputs.size(-1), self.smoothing) loss = F.binary_cross_entropy_with_logits(inputs, targets,self.weight, pos_weight = self.pos_weight) if self.reduction == 'sum': loss = loss.sum() elif self.reduction == 'mean': loss = loss.mean() return loss- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这个trick挺适合这个比赛的,lb = 18.25
2.1.4、优化器和学习率
Adamw = Adam + weight decate 效果和 Adam + L2正则化相同,但是计算效率更高。
lr = optim.lr_scheduler.CosineAnnealingWarmRestarts 余弦退火学习率这里直接用的baseline的优化器和学习率。
2.2、基于Classification Head + SVR Regression Head的方案
方案有点类似后处理,特别简单,在Inference的时候,冻结backbone,用之前训练好的Swim transformer backbone输出的特征图【bs, 128】输入到SVR Head中,训练SVR Head模型,再将分类模型和SVR模型分别做推理,再取均值,得到最终的推理结果。
SVR原理: Python:机器学习:SVM(SVR)
简单说下:
- SVM:二类分类模型,优化方向是间隔最大化(使离超平面最近的样本点的间隔最大);SVR:回归模型,使离超平面最远的样本点之间的间隔最小。
- C是调节间隔与准确率的因子,C值越大,越不愿放弃那些离群点;c值越小,越不重视那些离群点;
代码:
super_final_predictions = [] super_final_predictions2 = [] super_final_oof_predictions = [] super_final_oof_predictions2 = [] super_final_oof_true = [] for fold_ in range(5): print('#'*25) print('### FOLD',fold_) print('#'*25) model = PetNet() model.load_state_dict(torch.load(model_weight[fold_])) model = model.to(device) model.eval() df_test = pd.read_csv("../input/petfinder-pawpularity-score/test.csv") test_img_paths = [f"../input/petfinder-pawpularity-score/test/{x}.jpg" for x in df_test["Id"].values] df_valid = df[df.fold == fold_].reset_index(drop=True)#.iloc[:160] valid_img_paths = [f"../input/petfinder-pawpularity-score/train/{x}.jpg" for x in df_valid["Id"].values] dense_features = [ 'Subject Focus', 'Eyes', 'Face', 'Near', 'Action', 'Accessory', 'Group', 'Collage', 'Human', 'Occlusion', 'Info', 'Blur' ] name = f"SVR_fold_{fold_}.pkl" if LOAD_SVR_FROM_PATH is None: # EXTRACT TRAIN EMBEDDINGS df_train = df[df.fold != fold_].reset_index(drop=True)#.iloc[:320] train_img_paths = [f"../input/petfinder-pawpularity-score/train/{x}.jpg" for x in df_train["Id"].values] train_dataset = PetDataset( image_filepaths = train_img_paths, targets = df_train['Pawpularity'].values/100, transform = get_inference_fixed_transforms(0) ) train_loader = DataLoader(train_dataset, batch_size=Config.batch_size, shuffle=False, num_workers=Config.num_workers, pin_memory = True) print('Extracting train embedding...') fold_preds = [] for i, (images, target) in enumerate(tqdm(train_loader), start = 1): images = images.to(device, non_blocking = True).float() target = target.to(device, non_blocking = True).float().view(-1, 1) with torch.no_grad(): _, output = model(images) # [bs, 129] fold_preds.append(output.detach().cpu().numpy()) embed = np.array([]).reshape((0,128)) for preds in fold_preds: embed = np.concatenate([embed,preds[:,1:]],axis=0) # [bs, 128] # FIT RAPIDS SVR print('Fitting SVR...') clf = SVR(C=20.0) clf.fit(embed.astype('float32'), df_train.Pawpularity.values.astype('int32')) # SAVE RAPIDS SVR pickle.dump(clf, open(name, "wb")) else: # LOAD RAPIDS SVR print('Loading SVR...',LOAD_SVR_FROM_PATH+name) clf = pickle.load(open(LOAD_SVR_FROM_PATH+name, "rb")) # ************ TEST PREDICTIONS ************ test_dataset = PetDataset( image_filepaths = test_img_paths, targets = np.zeros(len(test_img_paths)), transform = get_inference_fixed_transforms(0) ) test_loader = DataLoader(test_dataset, batch_size=Config.batch_size, shuffle=False, num_workers=Config.num_workers, pin_memory = True) print('Predicting test...') fold_preds = [] for i, (images, target) in enumerate(tqdm(test_loader), start = 1): images = images.to(device, non_blocking = True).float() target = target.to(device, non_blocking = True).float().view(-1, 1) with torch.no_grad(): _, output = model(images) fold_preds.append(output.detach().cpu().numpy()) final_test_predictions = [] embed = np.array([]).reshape((0,128)) for preds in fold_preds: #tqdm final_test_predictions.extend(preds[:,:1].ravel().tolist()) embed = np.concatenate([embed,preds[:,1:]],axis=0) final_test_predictions = [sigmoid(x) * 100 for x in final_test_predictions] final_test_predictions2 = clf.predict(embed) super_final_predictions.append(final_test_predictions) super_final_predictions2.append(final_test_predictions2)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
最佳的trick lb = 17.95
2.3、融合Meta数据
这里我想了两种融合Meta数据的方法:
- 将Meta数据融入分类模型中,在Backbone输出特征图【bs,128】后,Concat我们的Meta特征数据【bs,12】,再送入2个全连接层+sigmoid完成分类任务;
- 将Meta数据融入回归模型中,在Backbone输出特征图【bs,128】后,Concat我们的Meta特征数据【bs,12】-> 【bs,140】,再送入SVR进行;
事实证明meta数据不work,不管怎么融合都掉点。
推测:可能是因为Meta数据太脏了?或者Meta数据本身和label关联度不高?2.4、最后模型融合
Backbone:swin_large_patch4_window12_384、vit_base_patch32_384
5折交叉验证
TTA:hflip
Classification Head + SVR Head
average策略lb = 17.88 800多名 b榜:17.13 700多名
三、不work
CNN(ResNet、EfficientNet) < Transformer
More TTA
RMSE loss
Metadata(花了超多时间)三、其他TOP方案
Model: Vit + Swin T + EfficientNet
Ensemble: 10-fold average
XGBoost Head
看看人家的模型融合(惊了 大力出奇迹吗?):
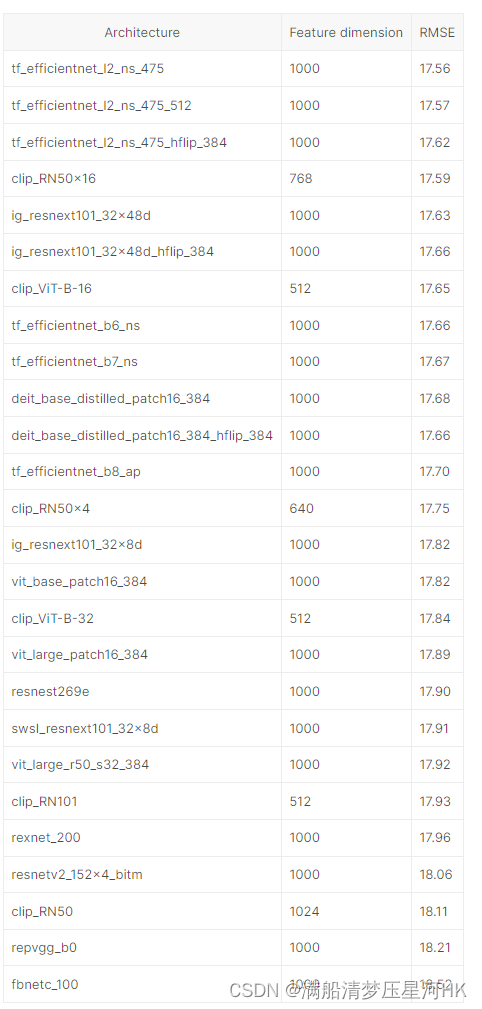
四、经验、教训
我看了我的方案其实和大家的方案差不多,都是从Discussion中找来的,大家真的在Discussion中讨论了很多东西,然后第一名是16.82,差0.3作用,我分析了下好像就是他用了很多模型,10几个模型融合,然后分会好很多,唉,可惜我只有一个3090,前面试了这么多实验后面就没多试试一些transformer模型了。然后再有一个就是我用的是5折交叉验证,普遍看前面几名都是10折交叉验证,这也是我分差排名不好的原因。
第一次打Kaggle比赛,不过已经从这个比赛学到了很多东西了:
- Swin Transformer、ViT原理
- SVM、SVR 原理
- 多模态,多数据如何融合?
- Smooth Loss对于数据集label可能标错的数据集非常非常有效
- 打比赛的流程:从Discussion找EDA数据分析,了解数据 - > 从Code中找到高分且容易看懂复现的代码作为baseline(K折交叉验证必有效) -> 分析数据特征进行数据增强探索 -> 模型探索 -> 损失函数探索 -> 模型融合(多backbone、TTA)-> 【后处理】-> 【超参探索,lr、优化器等 这部分比较玄学】
记得打比赛要多融合模型,融合不同类型的模型,没准可以起到一个补充信息的作用。
Reference
Petfinder Pawpularity EDA & fastai starter
PyTorch 学习笔记:transforms的二十二个方法(transforms用法非常详细)
summarize PetFinder.my discussions for new comers
-
相关阅读:
百度智能云千帆大模型三连击:接入LLaMA2等33个模型、上线插件功能和103个Prompt模板
Torch知识点总结【持续更新中......】
技术分享 | 无人驾驶汽车的眼睛
低代码平台受欢迎度排行榜:揭秘市场热门之选
Vue3框架中CompositionAPI的基本使用(第十课)
Android 运营商与APN配置简介
minitest使用笔记1
Spring之Bean的实例化
数学建模--优化类模型
LLM 位置编码及外推
- 原文地址:https://blog.csdn.net/qq_38253797/article/details/126049921
