-
机器学习模型的评估方法
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、模型评估依据——测试集
通常我们使用测试集来测试我们的模型对新样本的判别能力,并且以测试误差作为泛化误差的近似。通常我们尽可能的让测试集中的测试样本不在训练集中出现。
一般来说,测试集至少含30个样例。
对于我们手上一个包含m个样例的数据集D,我们有以下几个评估方法来产生训练集S和测试集T。
考虑点:评估结果要有高稳定性,可靠性和保真性。
二、留出法
1、方法描述
直接将数据集D划分为两个互斥的集合——一个作为训练集S,另一个作为测试集T。
2、注意点和实际做法
(1)在划分的过程中要尽可能保持数据分布的一致性,避免因数据划分过程中引入的额外偏差而对最终结果产生影响。
(比如说在分类任务中保持样本的类别比例相似——举个二分类的例子:S的正反例占比各50%,那么T的比例应与之相似)
(2)即便在给定训练集和测试集的样本比例后,仍存在多种划分方式对初始数据集D进行分割。不同的划分方法会产生不同的训练集和测试集,模型评估结果也会因此改变。
所以:
🌳单次使用留出法得到的估计结果往往不够可靠稳定。
🌳一般要采用若干次随机划分,重复进行试验评估后取均值作为留出法的评估结果
3、问题和其对应的通用解决做法
(1)问题描述
若训练集较大,那么训练出来的模型更接近于直接拿数据集D训练得出的模型,并且测试集T比较小,评估结果可能不太稳定可靠;
若让测试集T大些,那么训练集和数据集的差别更大了,训练出来的模型与直接拿数据集D训练得出的模型相差较大,从而降低了评估结果的保真性(预测结果和真实结果的拟合程度)。
(2)做法:
没有完美解决方案,一般情况下将2/3到4/5的样本用于训练,其余的用于测试。
4、python具体实现
- from sklearn.model_selection import train_test_split
- x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)
三、交叉验证法(k倍/折交叉验证)
1、方法描述
先将数据集D分为k个大小相似的互斥子集,即
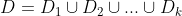 ,
, 。并且每个子集都尽可能地保持数据分布的一致性——通过从D中分层采样得到。
。并且每个子集都尽可能地保持数据分布的一致性——通过从D中分层采样得到。然后每次使用k-1个子集的并集作为训练集,剩下的作为测试集,这样就有k组训练集+测试集,可以进行k次训练,最终的评估结果就是着k次结果的均值。
2、注意点和实际做法
(1)该方法的评估结果的稳定性和保真性与k密切相关。k最常取值为10。
(2)与留出法类似:存在多种划分方式对初始数据集D进行分割。不同的划分方法会产生不同的训练集和测试集,模型评估结果也会因此改变。
因此:
🌳k折交叉验证通常随即使用不同的划分重复p次,最终评估结果取均值。即最终进行了p*k次训练+测试。
🌳常见的有10次10折交叉验证。
3、交叉验证法特例——留一法
令k=m(数据集D的样例数),它不受随机样本划分方式的影响。
优点:
🎈每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠;
🎈实验没有随机因素,整个过程是可重复的。缺点:
计算成本高。—— 当m非常大时,计算耗时。除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。
4、python实现
以iris数据和逻辑回归为例子
- from sklearn.datasets import load_iris
- from sklearn.model_selection import cross_val_score,KFold
- from sklearn.linear_model import LogisticRegression
- iris=load_iris()
- X=iris.data
- Y=iris.target
- logreg=LogisticRegression()
- kf=KFold(n_splits=10)
- score=cross_val_score(logreg,X,Y,cv=kf)
四、自助法
1、方法描述
我们进行m次可重复地在D中进行随机抽取一个样本出来,组成新的数据集D‘(有一部分样本可能会在D’中反复出现,而有些不存在)
样本在m次采样中始终不被采到的概率是
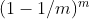 ,则
,则
我们把D‘作为训练集,D-D’作为测试集。
2、优缺点
(1)优点:
- 在数据集小,难以有效划分训练/测试集时效果很好
- 能从数据集D中产生多个不同的训练集
(2)缺点:
自助法产生的数据集改变了原数据集的分布,可能会引入估计偏差
(因此,该方法比较少用)
欢迎大家在评论区批评指正,谢谢大家~
-
相关阅读:
戴森创“新”公开课再度开讲,持续助力打造洁净居家环境 以升级科技守护家庭健康
2023最新SSM计算机毕业设计选题大全(附源码+LW)之java计算机专业建设管理系统3286d
<学习笔记>从零开始自学Python-之-web应用框架Django( 九)自定义标签和过滤器
如何完成繁杂的身份治理
实验七 循环神经网络(3)LSTM的记忆能力实验
图书管理系统的设计与实现/ssm的图书管理网站
宏任务、微任务理解
macOS电池续航工具:Endurance中文
设计模式-创建型模式
这几招教你如何增加食物中铁的吸收
- 原文地址:https://blog.csdn.net/weixin_55073640/article/details/125803479