-
SQL力扣刷题七
1251. 平均售价
Create table If Not Exists Prices (product_id int, start_date date, end_date date, price int) Create table If Not Exists UnitsSold (product_id int, purchase_date date, units int) Truncate table Prices insert into Prices (product_id, start_date, end_date, price) values ('1', '2019-02-17', '2019-02-28', '5') insert into Prices (product_id, start_date, end_date, price) values ('1', '2019-03-01', '2019-03-22', '20') insert into Prices (product_id, start_date, end_date, price) values ('2', '2019-02-01', '2019-02-20', '15') insert into Prices (product_id, start_date, end_date, price) values ('2', '2019-02-21', '2019-03-31', '30') Truncate table UnitsSold insert into UnitsSold (product_id, purchase_date, units) values ('1', '2019-02-25', '100') insert into UnitsSold (product_id, purchase_date, units) values ('1', '2019-03-01', '15') insert into UnitsSold (product_id, purchase_date, units) values ('2', '2019-02-10', '200') insert into UnitsSold (product_id, purchase_date, units) values ('2', '2019-03-22', '30')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Table:
Prices+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | start_date | date | | end_date | date | | price | int | +---------------+---------+ (product_id,start_date,end_date) 是 Prices 表的主键。 Prices 表的每一行表示的是某个产品在一段时期内的价格。 每个产品的对应时间段是不会重叠的,这也意味着同一个产品的价格时段不会出现交叉。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Table:
UnitsSold+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | purchase_date | date | | units | int | +---------------+---------+ UnitsSold 表没有主键,它可能包含重复项。 UnitsSold 表的每一行表示的是每种产品的出售日期,单位和产品 id。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
编写SQL查询以查找每种产品的平均售价。
average_price应该四舍五入到小数点后两位。
查询结果格式如下例所示:Prices table: +------------+------------+------------+--------+ | product_id | start_date | end_date | price | +------------+------------+------------+--------+ | 1 | 2019-02-17 | 2019-02-28 | 5 | | 1 | 2019-03-01 | 2019-03-22 | 20 | | 2 | 2019-02-01 | 2019-02-20 | 15 | | 2 | 2019-02-21 | 2019-03-31 | 30 | +------------+------------+------------+--------+ UnitsSold table: +------------+---------------+-------+ | product_id | purchase_date | units | +------------+---------------+-------+ | 1 | 2019-02-25 | 100 | | 1 | 2019-03-01 | 15 | | 2 | 2019-02-10 | 200 | | 2 | 2019-03-22 | 30 | +------------+---------------+-------+ Result table: +------------+---------------+ | product_id | average_price | +------------+---------------+ | 1 | 6.96 | | 2 | 16.96 | +------------+---------------+ 平均售价 = 产品总价 / 销售的产品数量。 产品 1 的平均售价 = ((100 * 5)+(15 * 20) )/ 115 = 6.96 产品 2 的平均售价 = ((200 * 15)+(30 * 30) )/ 230 = 16.96- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
题解一
SELECT product_id, Round(SUM(sales) / SUM(units), 2) AS average_price FROM ( SELECT Prices.product_id AS product_id, Prices.price * UnitsSold.units AS sales, UnitsSold.units AS units FROM Prices JOIN UnitsSold ON Prices.product_id = UnitsSold.product_id WHERE UnitsSold.purchase_date BETWEEN Prices.start_date AND Prices.end_date ) T GROUP BY product_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
题解二
SELECT product_id, ROUND(SUM(total) / SUM(units), 2) average_price FROM( SELECT u.product_id, u.purchase_date, u.units, (p.price * u.units) total FROM (SELECT DISTINCT * FROM unitsSold) u INNER JOIN prices p ON u.product_id = p.product_id AND u.purchase_date >= p.start_date AND u.purchase_date <= p.end_date) a GROUP BY a.product_id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
题解三
select t1.product_id, round(sum(units*price)/sum(units),2) as average_price from UnitsSold t1 left join Prices t2 on t1.product_id = t2.product_id and (t1.purchase_date between t2.start_date and t2.end_date) group by product_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1264. 页面推荐
Create table If Not Exists Friendship (user1_id int, user2_id int) Create table If Not Exists Likes (user_id int, page_id int) Truncate table Friendship insert into Friendship (user1_id, user2_id) values ('1', '2') insert into Friendship (user1_id, user2_id) values ('1', '3') insert into Friendship (user1_id, user2_id) values ('1', '4') insert into Friendship (user1_id, user2_id) values ('2', '3') insert into Friendship (user1_id, user2_id) values ('2', '4') insert into Friendship (user1_id, user2_id) values ('2', '5') insert into Friendship (user1_id, user2_id) values ('6', '1') Truncate table Likes insert into Likes (user_id, page_id) values ('1', '88') insert into Likes (user_id, page_id) values ('2', '23') insert into Likes (user_id, page_id) values ('3', '24') insert into Likes (user_id, page_id) values ('4', '56') insert into Likes (user_id, page_id) values ('5', '11') insert into Likes (user_id, page_id) values ('6', '33') insert into Likes (user_id, page_id) values ('2', '77') insert into Likes (user_id, page_id) values ('3', '77') insert into Likes (user_id, page_id) values ('6', '88')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
朋友关系列表:
Friendship+---------------+---------+ | Column Name | Type | +---------------+---------+ | user1_id | int | | user2_id | int | +---------------+---------+ 这张表的主键是 (user1_id, user2_id)。 这张表的每一行代表着 user1_id 和 user2_id 之间存在着朋友关系。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
喜欢列表:
Likes+-------------+---------+ | Column Name | Type | +-------------+---------+ | user_id | int | | page_id | int | +-------------+---------+ 这张表的主键是 (user_id, page_id)。 这张表的每一行代表着 user_id 喜欢 page_id。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
写一段 SQL 向user_id = 1 的用户,推荐其朋友们喜欢的页面。不要推荐该用户已经喜欢的页面。
你返回的结果中不应当包含重复项。
返回结果的格式如下例所示。
示例 1:
输入: Friendship table: +----------+----------+ | user1_id | user2_id | +----------+----------+ | 1 | 2 | | 1 | 3 | | 1 | 4 | | 2 | 3 | | 2 | 4 | | 2 | 5 | | 6 | 1 | +----------+----------+ Likes table: +---------+---------+ | user_id | page_id | +---------+---------+ | 1 | 88 | | 2 | 23 | | 3 | 24 | | 4 | 56 | | 5 | 11 | | 6 | 33 | | 2 | 77 | | 3 | 77 | | 6 | 88 | +---------+---------+ 输出: +------------------+ | recommended_page | +------------------+ | 23 | | 24 | | 56 | | 33 | | 77 | +------------------+ 解释: 用户1 同 用户2, 3, 4, 6 是朋友关系。 推荐页面为: 页面23 来自于 用户2, 页面24 来自于 用户3, 页面56 来自于 用户3 以及 页面33 来自于 用户6。 页面77 同时被 用户2 和 用户3 推荐。 页面88 没有被推荐,因为 用户1 已经喜欢了它。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
题解一
SELECT DISTINCT page_id AS recommended_page FROM Likes WHERE user_id IN ( SELECT user1_id AS user_id FROM Friendship WHERE user2_id = 1 UNION ALL SELECT user2_id AS user_id FROM Friendship WHERE user1_id = 1 ) AND page_id NOT IN ( SELECT page_id FROM Likes WHERE user_id = 1 )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
题解二
SELECT DISTINCT page_id AS recommended_page FROM Likes WHERE user_id IN (SELECT user2_id FROM Friendship WHERE user1_id=1 UNION SELECT user1_id FROM Friendship WHERE user2_id=1) AND page_id NOT IN (SELECT page_id FROM Likes WHERE user_id=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
题解三
with temp as ( select * from ( select user1_id, user2_id from Friendship UNION select user2_id, user1_id from Friendship ) as d1 where user1_id=1 ) select distinct page_id as recommended_page from ( select a.user1_id, a.user2_id, b.page_id from temp a right join Likes b on a.user2_id = b.user_id ) as dat where user1_id=1 and page_id not in (select page_id from Likes where user_id=1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
题解四
with newtable(a) as ( select user2_id from friendship where user1_id=1 union all select user1_id from friendship where user2_id=1 ) select distinct page_id as recommended_page from newtable,likes where likes.user_id = newtable.a and page_id not in (select page_id from likes where user_id =1 )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1270. 向公司CEO汇报工作的所有人
Create table If Not Exists Employees (employee_id int, employee_name varchar(30), manager_id int) Truncate table Employees insert into Employees (employee_id, employee_name, manager_id) values ('1', 'Boss', '1') insert into Employees (employee_id, employee_name, manager_id) values ('3', 'Alice', '3') insert into Employees (employee_id, employee_name, manager_id) values ('2', 'Bob', '1') insert into Employees (employee_id, employee_name, manager_id) values ('4', 'Daniel', '2') insert into Employees (employee_id, employee_name, manager_id) values ('7', 'Luis', '4') insert into Employees (employee_id, employee_name, manager_id) values ('8', 'John', '3') insert into Employees (employee_id, employee_name, manager_id) values ('9', 'Angela', '8') insert into Employees (employee_id, employee_name, manager_id) values ('77', 'Robert', '1')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
员工表:
Employees+---------------+---------+ | Column Name | Type | +---------------+---------+ | employee_id | int | | employee_name | varchar | | manager_id | int | +---------------+---------+ employee_id 是这个表的主键。 这个表中每一行中,employee_id 表示职工的 ID,employee_name 表示职工的名字,manager_id 表示该职工汇报工作的直线经理。 这个公司 CEO 是 employee_id = 1 的人。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
用 SQL 查询出所有直接或间接向公司 CEO 汇报工作的职工的 employee_id 。
由于公司规模较小,经理之间的间接关系不超过 3 个经理。
可以以任何顺序返回无重复项的结果。
查询结果示例如下:
Employees table: +-------------+---------------+------------+ | employee_id | employee_name | manager_id | +-------------+---------------+------------+ | 1 | Boss | 1 | | 3 | Alice | 3 | | 2 | Bob | 1 | | 4 | Daniel | 2 | | 7 | Luis | 4 | | 8 | Jhon | 3 | | 9 | Angela | 8 | | 77 | Robert | 1 | +-------------+---------------+------------+ Result table: +-------------+ | employee_id | +-------------+ | 2 | | 77 | | 4 | | 7 | +-------------+ 公司 CEO 的 employee_id 是 1. employee_id 是 2 和 77 的职员直接汇报给公司 CEO。 employee_id 是 4 的职员间接汇报给公司 CEO 4 --> 2 --> 1 。 employee_id 是 7 的职员间接汇报给公司 CEO 7 --> 4 --> 2 --> 1 。 employee_id 是 3, 8 ,9 的职员不会直接或间接的汇报给公司 CEO。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
题解一
SELECT DISTINCT employee_id FROM ( SELECT employee_id FROM Employees WHERE manager_id = 1 UNION ALL SELECT employee_id FROM Employees WHERE manager_id IN ( SELECT employee_id FROM Employees WHERE manager_id = 1 ) UNION ALL SELECT employee_id FROM Employees WHERE manager_id IN ( SELECT employee_id FROM Employees WHERE manager_id IN ( SELECT employee_id FROM Employees WHERE manager_id = 1 ) ) ) T WHERE employee_id != 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
题解二
SELECT e1.employee_id FROM Employees e1 JOIN Employees e2 ON e1.manager_id = e2.employee_id JOIN Employees e3 ON e2.manager_id = e3.employee_id WHERE e1.employee_id != 1 AND e3.manager_id = 1- 1
- 2
- 3
- 4
- 5
题解三
SELECT e1.employee_id FROM employees e1 LEFT JOIN employees e2 ON e1.manager_id = e2.employee_id LEFT JOIN employees e3 ON e2.manager_id = e3.employee_id WHERE e1.employee_id != 1 AND e3.manager_id = 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1280. 学生们参加各科测试的次数
Create table If Not Exists Students (student_id int, student_name varchar(20)) Create table If Not Exists Subjects (subject_name varchar(20)) Create table If Not Exists Examinations (student_id int, subject_name varchar(20)) Truncate table Students insert into Students (student_id, student_name) values ('1', 'Alice') insert into Students (student_id, student_name) values ('2', 'Bob') insert into Students (student_id, student_name) values ('13', 'John') insert into Students (student_id, student_name) values ('6', 'Alex') Truncate table Subjects insert into Subjects (subject_name) values ('Math') insert into Subjects (subject_name) values ('Physics') insert into Subjects (subject_name) values ('Programming') Truncate table Examinations insert into Examinations (student_id, subject_name) values ('1', 'Math') insert into Examinations (student_id, subject_name) values ('1', 'Physics') insert into Examinations (student_id, subject_name) values ('1', 'Programming') insert into Examinations (student_id, subject_name) values ('2', 'Programming') insert into Examinations (student_id, subject_name) values ('1', 'Physics') insert into Examinations (student_id, subject_name) values ('1', 'Math') insert into Examinations (student_id, subject_name) values ('13', 'Math') insert into Examinations (student_id, subject_name) values ('13', 'Programming') insert into Examinations (student_id, subject_name) values ('13', 'Physics') insert into Examinations (student_id, subject_name) values ('2', 'Math') insert into Examinations (student_id, subject_name) values ('1', 'Math')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
学生表:
Students+---------------+---------+ | Column Name | Type | +---------------+---------+ | student_id | int | | student_name | varchar | +---------------+---------+ 主键为 student_id(学生ID),该表内的每一行都记录有学校一名学生的信息。- 1
- 2
- 3
- 4
- 5
- 6
- 7
科目表:
Subjects+--------------+---------+ | Column Name | Type | +--------------+---------+ | subject_name | varchar | +--------------+---------+ 主键为 subject_name(科目名称),每一行记录学校的一门科目名称。- 1
- 2
- 3
- 4
- 5
- 6
考试表:
Examinations+--------------+---------+ | Column Name | Type | +--------------+---------+ | student_id | int | | subject_name | varchar | +--------------+---------+ 这张表压根没有主键,可能会有重复行。 学生表里的一个学生修读科目表里的每一门科目,而这张考试表的每一行记录就表示学生表里的某个学生参加了一次科目表里某门科目的测试。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
要求写一段 SQL 语句,查询出每个学生参加每一门科目测试的次数,结果按 student_id 和 subject_name 排序。
查询结构格式如下所示:
Students table: +------------+--------------+ | student_id | student_name | +------------+--------------+ | 1 | Alice | | 2 | Bob | | 13 | John | | 6 | Alex | +------------+--------------+ Subjects table: +--------------+ | subject_name | +--------------+ | Math | | Physics | | Programming | +--------------+ Examinations table: +------------+--------------+ | student_id | subject_name | +------------+--------------+ | 1 | Math | | 1 | Physics | | 1 | Programming | | 2 | Programming | | 1 | Physics | | 1 | Math | | 13 | Math | | 13 | Programming | | 13 | Physics | | 2 | Math | | 1 | Math | +------------+--------------+ Result table: +------------+--------------+--------------+----------------+ | student_id | student_name | subject_name | attended_exams | +------------+--------------+--------------+----------------+ | 1 | Alice | Math | 3 | | 1 | Alice | Physics | 2 | | 1 | Alice | Programming | 1 | | 2 | Bob | Math | 1 | | 2 | Bob | Physics | 0 | | 2 | Bob | Programming | 1 | | 6 | Alex | Math | 0 | | 6 | Alex | Physics | 0 | | 6 | Alex | Programming | 0 | | 13 | John | Math | 1 | | 13 | John | Physics | 1 | | 13 | John | Programming | 1 | +------------+--------------+--------------+----------------+ 结果表需包含所有学生和所有科目(即便测试次数为0): Alice 参加了 3 次数学测试, 2 次物理测试,以及 1 次编程测试; Bob 参加了 1 次数学测试, 1 次编程测试,没有参加物理测试; Alex 啥测试都没参加; John 参加了数学、物理、编程测试各 1 次。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
题解一
SELECT a.student_id, a.student_name, b.subject_name, COUNT(e.subject_name) AS attended_exams FROM Students a CROSS JOIN Subjects b LEFT JOIN Examinations e ON a.student_id = e.student_id AND b.subject_name = e.subject_name GROUP BY a.student_id, b.subject_name ORDER BY a.student_id, b.subject_name- 1
- 2
- 3
- 4
- 5
题解二
select ss.student_id as student_id, ss.student_name as student_name, ss.subject_name as subject_name, ifnull(e1.attended_exams, 0) as attended_exams from ( select * from `Students` as s1 cross join `Subjects` as s2 ) as ss left join ( select student_id, subject_name, count(student_id) as attended_exams from `Examinations` group by student_id,subject_name ) as e1 on ss.student_id = e1.student_id and ss.subject_name = e1.subject_name order by ss.student_id, ss.subject_name- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
题解三
SELECT stu.student_id AS 'student_id', stu.student_name AS 'student_name', sub.subject_name AS 'subject_name', COUNT(exa.subject_name) AS 'attended_exams' #统计考试登记表中的 FROM Students AS stu CROSS JOIN Subjects AS sub #笛卡尔积 LEFT OUTER JOIN Examinations AS exa ON stu.student_id = exa.student_id AND sub.subject_name = exa.subject_name GROUP BY stu.student_id, sub.subject_name ORDER BY stu.student_id, sub.subject_name- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1285. 找到连续区间的开始和结束数字
Create table If Not Exists Logs (log_id int) Truncate table Logs insert into Logs (log_id) values ('1') insert into Logs (log_id) values ('2') insert into Logs (log_id) values ('3') insert into Logs (log_id) values ('7') insert into Logs (log_id) values ('8') insert into Logs (log_id) values ('10')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
表:
Logs+---------------+---------+ | Column Name | Type | +---------------+---------+ | log_id | int | +---------------+---------+ id 是上表的主键。 上表的每一行包含日志表中的一个 ID。- 1
- 2
- 3
- 4
- 5
- 6
- 7
后来一些 ID 从 Logs 表中删除。编写一个 SQL 查询得到 Logs 表中的连续区间的开始数字和结束数字。
将查询表按照 start_id 排序。
查询结果格式如下面的例子。
示例 1:
输入: Logs 表: +------------+ | log_id | +------------+ | 1 | | 2 | | 3 | | 7 | | 8 | | 10 | +------------+ 输出: +------------+--------------+ | start_id | end_id | +------------+--------------+ | 1 | 3 | | 7 | 8 | | 10 | 10 | +------------+--------------+ 解释: 结果表应包含 Logs 表中的所有区间。 从 1 到 3 在表中。 从 4 到 6 不在表中。 从 7 到 8 在表中。 9 不在表中。 10 在表中。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
题解一
select min(log_id) start_id, max(log_id) end_id from ( select log_id, log_id - row_number() over() diff from logs ) temp group by diff- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
题解二
select min(log_id) start_id, max(log_id) end_id from ( select log_id, case when @id = log_id - 1 then @num:=@num else @num:=@num+1 end num, @id:=log_id from logs, (select @id:=null, @num:=0) init ) temp group by num;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
题解三
with l1 as ( select log_id start_id, row_number() over(order by log_id) as rank_id from logs where log_id - 1 not in (select log_id from logs) ), l2 as ( select log_id end_id, row_number() over(order by log_id) as rank_id from logs where log_id + 1 not in (select log_id from logs) ) select start_id, end_id from l1 join l2 using(rank_id);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1294. 不同国家的天气类型
Create table If Not Exists Countries (country_id int, country_name varchar(20)) Create table If Not Exists Weather (country_id int, weather_state int, day date) Truncate table Countries insert into Countries (country_id, country_name) values ('2', 'USA') insert into Countries (country_id, country_name) values ('3', 'Australia') insert into Countries (country_id, country_name) values ('7', 'Peru') insert into Countries (country_id, country_name) values ('5', 'China') insert into Countries (country_id, country_name) values ('8', 'Morocco') insert into Countries (country_id, country_name) values ('9', 'Spain') Truncate table Weather insert into Weather (country_id, weather_state, day) values ('2', '15', '2019-11-01') insert into Weather (country_id, weather_state, day) values ('2', '12', '2019-10-28') insert into Weather (country_id, weather_state, day) values ('2', '12', '2019-10-27') insert into Weather (country_id, weather_state, day) values ('3', '-2', '2019-11-10') insert into Weather (country_id, weather_state, day) values ('3', '0', '2019-11-11') insert into Weather (country_id, weather_state, day) values ('3', '3', '2019-11-12') insert into Weather (country_id, weather_state, day) values ('5', '16', '2019-11-07') insert into Weather (country_id, weather_state, day) values ('5', '18', '2019-11-09') insert into Weather (country_id, weather_state, day) values ('5', '21', '2019-11-23') insert into Weather (country_id, weather_state, day) values ('7', '25', '2019-11-28') insert into Weather (country_id, weather_state, day) values ('7', '22', '2019-12-01') insert into Weather (country_id, weather_state, day) values ('7', '20', '2019-12-02') insert into Weather (country_id, weather_state, day) values ('8', '25', '2019-11-05') insert into Weather (country_id, weather_state, day) values ('8', '27', '2019-11-15') insert into Weather (country_id, weather_state, day) values ('8', '31', '2019-11-25') insert into Weather (country_id, weather_state, day) values ('9', '7', '2019-10-23') insert into Weather (country_id, weather_state, day) values ('9', '3', '2019-12-23')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
国家表:
Countries+---------------+---------+ | Column Name | Type | +---------------+---------+ | country_id | int | | country_name | varchar | +---------------+---------+ country_id 是这张表的主键。 该表的每行有 country_id 和 country_name 两列。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
天气表:
Weather+---------------+---------+ | Column Name | Type | +---------------+---------+ | country_id | int | | weather_state | varchar | | day | date | +---------------+---------+ (country_id, day) 是该表的复合主键。 该表的每一行记录了某个国家某一天的天气情况。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
写一段 SQL 来找到表中每个国家在 2019 年 11 月的天气类型。
天气类型的定义如下:当 weather_state 的平均值小于或等于15返回 Cold,当 weather_state 的平均值大于或等于 25 返回 Hot,否则返回 Warm。
你可以以任意顺序返回你的查询结果。
查询结果格式如下所示:
Countries table: +------------+--------------+ | country_id | country_name | +------------+--------------+ | 2 | USA | | 3 | Australia | | 7 | Peru | | 5 | China | | 8 | Morocco | | 9 | Spain | +------------+--------------+ Weather table: +------------+---------------+------------+ | country_id | weather_state | day | +------------+---------------+------------+ | 2 | 15 | 2019-11-01 | | 2 | 12 | 2019-10-28 | | 2 | 12 | 2019-10-27 | | 3 | -2 | 2019-11-10 | | 3 | 0 | 2019-11-11 | | 3 | 3 | 2019-11-12 | | 5 | 16 | 2019-11-07 | | 5 | 18 | 2019-11-09 | | 5 | 21 | 2019-11-23 | | 7 | 25 | 2019-11-28 | | 7 | 22 | 2019-12-01 | | 7 | 20 | 2019-12-02 | | 8 | 25 | 2019-11-05 | | 8 | 27 | 2019-11-15 | | 8 | 31 | 2019-11-25 | | 9 | 7 | 2019-10-23 | | 9 | 3 | 2019-12-23 | +------------+---------------+------------+ Result table: +--------------+--------------+ | country_name | weather_type | +--------------+--------------+ | USA | Cold | | Austraila | Cold | | Peru | Hot | | China | Warm | | Morocco | Hot | +--------------+--------------+ USA 11 月的平均 weather_state 为 (15) / 1 = 15 所以天气类型为 Cold。 Australia 11 月的平均 weather_state 为 (-2 + 0 + 3) / 3 = 0.333 所以天气类型为 Cold。 Peru 11 月的平均 weather_state 为 (25) / 1 = 25 所以天气类型为 Hot。 China 11 月的平均 weather_state 为 (16 + 18 + 21) / 3 = 18.333 所以天气类型为 Warm。 Morocco 11 月的平均 weather_state 为 (25 + 27 + 31) / 3 = 27.667 所以天气类型为 Hot。 我们并不知道 Spain 在 11 月的 weather_state 情况所以无需将他包含在结果中。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
题解一
SELECT c.country_name AS country_name, (CASE WHEN AVG(w.weather_state)<=15 THEN 'Cold' WHEN AVG(w.weather_state)>=25 THEN 'Hot' ELSE 'Warm' END) AS weather_type FROM Weather w LEFT JOIN Countries c USING(country_id) WHERE year(day)=2019 AND month(day)=11 GROUP BY country_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
题解二
SELECT country_name AS 'country_name', CASE WHEN AVG(w1.weather_state) <= 15 THEN 'Cold' WHEN AVG(w1.weather_state) >= 25 THEN 'Hot' ELSE 'Warm' END AS 'weather_type' FROM Countries AS c1 INNER JOIN Weather AS w1 ON c1.country_id = w1.country_id WHERE w1.day BETWEEN '2019-11-01' AND '2019-11-30' GROUP BY c1.country_id ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
题解三
SELECT country_name AS 'country_name', CASE WHEN AVG(w1.weather_state) <= 15 THEN 'Cold' WHEN AVG(w1.weather_state) >= 25 THEN 'Hot' ELSE 'Warm' END AS 'weather_type' FROM Countries AS c1 INNER JOIN Weather AS w1 ON c1.country_id = w1.country_id WHERE YEAR(w1.day) = 2019 AND MONTH(w1.day) = 11 GROUP BY c1.country_id ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
题解四
SELECT country_name AS 'country_name', CASE WHEN AVG(w1.weather_state) <= 15 THEN 'Cold' WHEN AVG(w1.weather_state) >= 25 THEN 'Hot' ELSE 'Warm' END AS 'weather_type' FROM Countries AS c1 INNER JOIN Weather AS w1 ON c1.country_id = w1.country_id WHERE DATE_FORMAT(w1.day, '%Y-%m') = '2019-11' GROUP BY c1.country_id ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
题解五
select country_name, case when sum(weather_state)/count(weather_state) <= 15 then 'Cold' when sum(weather_state)/count(weather_state) >= 25 then 'Hot' else 'Warm' end as weather_type from Weather w, Countries c where w.country_id = c.country_id and left(day,7)='2019-11' group by country_name- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
题解六
SELECT COUNTRY_NAME, CASE WHEN AVG(WEATHER_STATE) <= 15 THEN 'Cold' WHEN AVG(WEATHER_STATE) >= 25 THEN 'Hot' ELSE 'Warm' END AS WEATHER_TYPE FROM COUNTRIES AS C INNER JOIN WEATHER AS W ON C.COUNTRY_ID = W.COUNTRY_ID WHERE LEFT(DAY, 7) = '2019-11' GROUP BY 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1303. 求团队人数
Create table If Not Exists Employee (employee_id int, team_id int) Truncate table Employee insert into Employee (employee_id, team_id) values ('1', '8') insert into Employee (employee_id, team_id) values ('2', '8') insert into Employee (employee_id, team_id) values ('3', '8') insert into Employee (employee_id, team_id) values ('4', '7') insert into Employee (employee_id, team_id) values ('5', '9') insert into Employee (employee_id, team_id) values ('6', '9')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
员工表:
Employee+---------------+---------+ | Column Name | Type | +---------------+---------+ | employee_id | int | | team_id | int | +---------------+---------+ employee_id 字段是这张表的主键,表中的每一行都包含每个员工的 ID 和他们所属的团队。- 1
- 2
- 3
- 4
- 5
- 6
- 7
编写一个 SQL 查询,以求得每个员工所在团队的总人数。
查询结果中的顺序无特定要求。
查询结果格式示例如下:
Employee Table: +-------------+------------+ | employee_id | team_id | +-------------+------------+ | 1 | 8 | | 2 | 8 | | 3 | 8 | | 4 | 7 | | 5 | 9 | | 6 | 9 | +-------------+------------+ Result table: +-------------+------------+ | employee_id | team_size | +-------------+------------+ | 1 | 3 | | 2 | 3 | | 3 | 3 | | 4 | 1 | | 5 | 2 | | 6 | 2 | +-------------+------------+ ID 为 1、2、3 的员工是 team_id 为 8 的团队的成员, ID 为 4 的员工是 team_id 为 7 的团队的成员, ID 为 5、6 的员工是 team_id 为 9 的团队的成员。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
题解一
SELECT e.employee_id, et.cnt team_size FROM employee e LEFT JOIN ( SELECT team_id, count(*) cnt FROM employee GROUP BY team_id ) et ON e.team_id = et.team_id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
题解二(自连接)
SELECT e1.employee_id, COUNT(*) AS team_size FROM Employee e1 JOIN Employee e2 USING (team_id) GROUP BY e1.employee_id ORDER BY e1.employee_id;- 1
- 2
- 3
- 4
题解三(子查询)
SELECT employee_id, ( SELECT COUNT(*) FROM employee e2 WHERE e1.team_id = e2.team_id ) AS team_size FROM Employee e1 ORDER BY e1.employee_id;- 1
- 2
- 3
- 4
- 5
- 6
- 7
题解四
SELECT employee_id, COUNT(employee_id) OVER(PARTITION BY team_id) AS team_size FROM Employee ORDER BY employee_id;- 1
- 2
- 3
- 4
- 5
1308. 不同性别每日分数总计
Create table If Not Exists Scores (player_name varchar(20), gender varchar(1), day date, score_points int) Truncate table Scores insert into Scores (player_name, gender, day, score_points) values ('Aron', 'F', '2020-01-01', '17') insert into Scores (player_name, gender, day, score_points) values ('Alice', 'F', '2020-01-07', '23') insert into Scores (player_name, gender, day, score_points) values ('Bajrang', 'M', '2020-01-07', '7') insert into Scores (player_name, gender, day, score_points) values ('Khali', 'M', '2019-12-25', '11') insert into Scores (player_name, gender, day, score_points) values ('Slaman', 'M', '2019-12-30', '13') insert into Scores (player_name, gender, day, score_points) values ('Joe', 'M', '2019-12-31', '3') insert into Scores (player_name, gender, day, score_points) values ('Jose', 'M', '2019-12-18', '2') insert into Scores (player_name, gender, day, score_points) values ('Priya', 'F', '2019-12-31', '23') insert into Scores (player_name, gender, day, score_points) values ('Priyanka', 'F', '2019-12-30', '17')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
表:
Scores+---------------+---------+ | Column Name | Type | +---------------+---------+ | player_name | varchar | | gender | varchar | | day | date | | score_points | int | +---------------+---------+ (gender, day)是该表的主键 一场比赛是在女队和男队之间举行的 该表的每一行表示一个名叫 (player_name) 性别为 (gender) 的参赛者在某一天获得了 (score_points) 的分数 如果参赛者是女性,那么 gender 列为 'F',如果参赛者是男性,那么 gender 列为 'M'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
写一条SQL语句查询每种性别在每一天的总分。
返回按 gender 和 day 对查询结果 升序排序 的结果。
查询结果格式的示例如下。
示例 1:
输入: Scores表: +-------------+--------+------------+--------------+ | player_name | gender | day | score_points | +-------------+--------+------------+--------------+ | Aron | F | 2020-01-01 | 17 | | Alice | F | 2020-01-07 | 23 | | Bajrang | M | 2020-01-07 | 7 | | Khali | M | 2019-12-25 | 11 | | Slaman | M | 2019-12-30 | 13 | | Joe | M | 2019-12-31 | 3 | | Jose | M | 2019-12-18 | 2 | | Priya | F | 2019-12-31 | 23 | | Priyanka | F | 2019-12-30 | 17 | +-------------+--------+------------+--------------+ 输出: +--------+------------+-------+ | gender | day | total | +--------+------------+-------+ | F | 2019-12-30 | 17 | | F | 2019-12-31 | 40 | | F | 2020-01-01 | 57 | | F | 2020-01-07 | 80 | | M | 2019-12-18 | 2 | | M | 2019-12-25 | 13 | | M | 2019-12-30 | 26 | | M | 2019-12-31 | 29 | | M | 2020-01-07 | 36 | +--------+------------+-------+ 解释: 女性队伍: 第一天是 2019-12-30,Priyanka 获得 17 分,队伍的总分是 17 分 第二天是 2019-12-31, Priya 获得 23 分,队伍的总分是 40 分 第三天是 2020-01-01, Aron 获得 17 分,队伍的总分是 57 分 第四天是 2020-01-07, Alice 获得 23 分,队伍的总分是 80 分 男性队伍: 第一天是 2019-12-18, Jose 获得 2 分,队伍的总分是 2 分 第二天是 2019-12-25, Khali 获得 11 分,队伍的总分是 13 分 第三天是 2019-12-30, Slaman 获得 13 分,队伍的总分是 26 分 第四天是 2019-12-31, Joe 获得 3 分,队伍的总分是 29 分 第五天是 2020-01-07, Bajrang 获得 7 分,队伍的总分是 36 分- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
题解一
SELECT gender, day, SUM(score_points) OVER (PARTITION BY gender ORDER BY day) total FROM scores;- 1
- 2
- 3
- 4
1321. 餐馆营业额变化增长
Create table If Not Exists Customer (customer_id int, name varchar(20), visited_on date, amount int) Truncate table Customer insert into Customer (customer_id, name, visited_on, amount) values ('1', 'Jhon', '2019-01-01', '100') insert into Customer (customer_id, name, visited_on, amount) values ('2', 'Daniel', '2019-01-02', '110') insert into Customer (customer_id, name, visited_on, amount) values ('3', 'Jade', '2019-01-03', '120') insert into Customer (customer_id, name, visited_on, amount) values ('4', 'Khaled', '2019-01-04', '130') insert into Customer (customer_id, name, visited_on, amount) values ('5', 'Winston', '2019-01-05', '110') insert into Customer (customer_id, name, visited_on, amount) values ('6', 'Elvis', '2019-01-06', '140') insert into Customer (customer_id, name, visited_on, amount) values ('7', 'Anna', '2019-01-07', '150') insert into Customer (customer_id, name, visited_on, amount) values ('8', 'Maria', '2019-01-08', '80') insert into Customer (customer_id, name, visited_on, amount) values ('9', 'Jaze', '2019-01-09', '110') insert into Customer (customer_id, name, visited_on, amount) values ('1', 'Jhon', '2019-01-10', '130') insert into Customer (customer_id, name, visited_on, amount) values ('3', 'Jade', '2019-01-10', '150')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
表:
Customer+---------------+---------+ | Column Name | Type | +---------------+---------+ | customer_id | int | | name | varchar | | visited_on | date | | amount | int | +---------------+---------+ (customer_id, visited_on) 是该表的主键。 该表包含一家餐馆的顾客交易数据。 visited_on 表示 (customer_id) 的顾客在 visited_on 那天访问了餐馆。 amount 是一个顾客某一天的消费总额。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
你是餐馆的老板,现在你想分析一下可能的营业额变化增长(每天至少有一位顾客)。
写一条 SQL 查询计算以 7 天(某日期 + 该日期前的 6 天)为一个时间段的顾客消费平均值。average_amount 要 保留两位小数。
查询结果按 visited_on 排序。
查询结果格式的例子如下。
示例 1:
输入: Customer 表: +-------------+--------------+--------------+-------------+ | customer_id | name | visited_on | amount | +-------------+--------------+--------------+-------------+ | 1 | Jhon | 2019-01-01 | 100 | | 2 | Daniel | 2019-01-02 | 110 | | 3 | Jade | 2019-01-03 | 120 | | 4 | Khaled | 2019-01-04 | 130 | | 5 | Winston | 2019-01-05 | 110 | | 6 | Elvis | 2019-01-06 | 140 | | 7 | Anna | 2019-01-07 | 150 | | 8 | Maria | 2019-01-08 | 80 | | 9 | Jaze | 2019-01-09 | 110 | | 1 | Jhon | 2019-01-10 | 130 | | 3 | Jade | 2019-01-10 | 150 | +-------------+--------------+--------------+-------------+ 输出: +--------------+--------------+----------------+ | visited_on | amount | average_amount | +--------------+--------------+----------------+ | 2019-01-07 | 860 | 122.86 | | 2019-01-08 | 840 | 120 | | 2019-01-09 | 840 | 120 | | 2019-01-10 | 1000 | 142.86 | +--------------+--------------+----------------+ 解释: 第一个七天消费平均值从 2019-01-01 到 2019-01-07 是restaurant-growth/restaurant-growth/ (100 + 110 + 120 + 130 + 110 + 140 + 150)/7 = 122.86 第二个七天消费平均值从 2019-01-02 到 2019-01-08 是 (110 + 120 + 130 + 110 + 140 + 150 + 80)/7 = 120 第三个七天消费平均值从 2019-01-03 到 2019-01-09 是 (120 + 130 + 110 + 140 + 150 + 80 + 110)/7 = 120 第四个七天消费平均值从 2019-01-04 到 2019-01-10 是 (130 + 110 + 140 + 150 + 80 + 110 + 130 + 150)/7 = 142.86- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
题解一
SELECT visited_on,amount,average_amount FROM ( SELECT visited_on, SUM(amount) OVER (ORDER BY visited_on ROWS 6 PRECEDING) AS amount, ROUND(AVG(amount)OVER(ORDER BY visited_on ROWS 6 PRECEDING),2) AS average_amount FROM ( SELECT visited_on,SUM(amount) AS amount FROM Customer GROUP BY visited_on ) TABLE_1 ) TABLE_2 WHERE DATEDIFF(visited_on,(SELECT MIN(visited_on) FROM Customer)) >=6- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
题解二
select distinct a.visited_on,sum(b.amount) as amount,round(sum(b.amount)/7,2) as average_amount from Customer a join Customer b on datediff(a.visited_on,b.visited_on) <= 6 and datediff(a.visited_on,b.visited_on) >= 0 group by a.visited_on,a.customer_id having count(distinct b.visited_on) = 7 order by visited_on- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
题解三
select t1.visited_on, sum(t2.amount) as amount, round(sum(t2.amount)/7, 2) as average_amount from (select visited_on, sum(amount) as amount from customer group by visited_on) as t1, (select visited_on, sum(amount) as amount from customer group by visited_on) as t2 where datediff(t1.visited_on, t2.visited_on)<=6 and datediff(t1.visited_on, t2.visited_on)>=0 and datediff(t1.visited_on, (select min(visited_on) from customer))>=6 group by t1.visited_on;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1322. 广告效果
Create table If Not Exists Ads (ad_id int, user_id int, action ENUM('Clicked', 'Viewed', 'Ignored')) Truncate table Ads insert into Ads (ad_id, user_id, action) values ('1', '1', 'Clicked') insert into Ads (ad_id, user_id, action) values ('2', '2', 'Clicked') insert into Ads (ad_id, user_id, action) values ('3', '3', 'Viewed') insert into Ads (ad_id, user_id, action) values ('5', '5', 'Ignored') insert into Ads (ad_id, user_id, action) values ('1', '7', 'Ignored') insert into Ads (ad_id, user_id, action) values ('2', '7', 'Viewed') insert into Ads (ad_id, user_id, action) values ('3', '5', 'Clicked') insert into Ads (ad_id, user_id, action) values ('1', '4', 'Viewed') insert into Ads (ad_id, user_id, action) values ('2', '11', 'Viewed') insert into Ads (ad_id, user_id, action) values ('1', '2', 'Clicked')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
表:
Ads+---------------+---------+ | Column Name | Type | +---------------+---------+ | ad_id | int | | user_id | int | | action | enum | +---------------+---------+ (ad_id, user_id) 是该表的主键 该表的每一行包含一条广告的 ID(ad_id),用户的 ID(user_id) 和用户对广告采取的行为 (action) action 列是一个枚举类型 ('Clicked', 'Viewed', 'Ignored') 。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
一家公司正在运营这些广告并想计算每条广告的效果。
广告效果用点击通过率(Click-Through Rate:CTR)来衡量,公式如下:
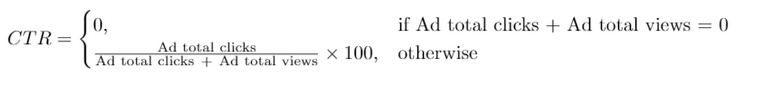
写一条SQL语句来查询每一条广告的 ctr ,
ctr 要保留两位小数。结果需要按 ctr 降序、按 ad_id 升序 进行排序。
题解一
SELECT ad_id AS 'ad_id', ROUND( IFNULL( SUM(action='Clicked') / SUM(action IN ('Clicked', 'Viewed')) * 100 , 0) , 2) AS 'ctr' FROM Ads GROUP BY ad_id ORDER BY ctr DESC, ad_id ASC ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
题解二
SELECT ad_id, ROUND(IFNULL(SUM(action = 'Clicked') / (SUM(action = 'Clicked') + SUM(action = 'Viewed')) * 100, 0), 2) AS ctr FROM Ads GROUP BY ad_id ORDER BY ctr DESC, ad_id ASC;- 1
- 2
- 3
- 4
- 5
- 6
1327. 列出指定时间段内所有的下单产品
Create table If Not Exists Products (product_id int, product_name varchar(40), product_category varchar(40)) Create table If Not Exists Orders (product_id int, order_date date, unit int) Truncate table Products insert into Products (product_id, product_name, product_category) values ('1', 'Leetcode Solutions', 'Book') insert into Products (product_id, product_name, product_category) values ('2', 'Jewels of Stringology', 'Book') insert into Products (product_id, product_name, product_category) values ('3', 'HP', 'Laptop') insert into Products (product_id, product_name, product_category) values ('4', 'Lenovo', 'Laptop') insert into Products (product_id, product_name, product_category) values ('5', 'Leetcode Kit', 'T-shirt') Truncate table Orders insert into Orders (product_id, order_date, unit) values ('1', '2020-02-05', '60') insert into Orders (product_id, order_date, unit) values ('1', '2020-02-10', '70') insert into Orders (product_id, order_date, unit) values ('2', '2020-01-18', '30') insert into Orders (product_id, order_date, unit) values ('2', '2020-02-11', '80') insert into Orders (product_id, order_date, unit) values ('3', '2020-02-17', '2') insert into Orders (product_id, order_date, unit) values ('3', '2020-02-24', '3') insert into Orders (product_id, order_date, unit) values ('4', '2020-03-01', '20') insert into Orders (product_id, order_date, unit) values ('4', '2020-03-04', '30') insert into Orders (product_id, order_date, unit) values ('4', '2020-03-04', '60') insert into Orders (product_id, order_date, unit) values ('5', '2020-02-25', '50') insert into Orders (product_id, order_date, unit) values ('5', '2020-02-27', '50') insert into Orders (product_id, order_date, unit) values ('5', '2020-03-01', '50')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
表:
Products+------------------+---------+ | Column Name | Type | +------------------+---------+ | product_id | int | | product_name | varchar | | product_category | varchar | +------------------+---------+ product_id 是该表主键。 该表包含该公司产品的数据。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
表:
Orders+---------------+---------+ | Column Name | Type | +---------------+---------+ | product_id | int | | order_date | date | | unit | int | +---------------+---------+ 该表无主键,可能包含重复行。 product_id 是表单 Products 的外键。 unit 是在日期 order_date 内下单产品的数目。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
写一个 SQL 语句,要求获取在 2020 年 2 月份下单的数量不少于 100 的产品的名字和数目。
返回结果表单的 顺序无要求 。
查询结果的格式如下。
示例 1:
输入: Products 表: +-------------+-----------------------+------------------+ | product_id | product_name | product_category | +-------------+-----------------------+------------------+ | 1 | Leetcode Solutions | Book | | 2 | Jewels of Stringology | Book | | 3 | HP | Laptop | | 4 | Lenovo | Laptop | | 5 | Leetcode Kit | T-shirt | +-------------+-----------------------+------------------+ Orders 表: +--------------+--------------+----------+ | product_id | order_date | unit | +--------------+--------------+----------+ | 1 | 2020-02-05 | 60 | | 1 | 2020-02-10 | 70 | | 2 | 2020-01-18 | 30 | | 2 | 2020-02-11 | 80 | | 3 | 2020-02-17 | 2 | | 3 | 2020-02-24 | 3 | | 4 | 2020-03-01 | 20 | | 4 | 2020-03-04 | 30 | | 4 | 2020-03-04 | 60 | | 5 | 2020-02-25 | 50 | | 5 | 2020-02-27 | 50 | | 5 | 2020-03-01 | 50 | +--------------+--------------+----------+ 输出: +--------------------+---------+ | product_name | unit | +--------------------+---------+ | Leetcode Solutions | 130 | | Leetcode Kit | 100 | +--------------------+---------+ 解释: 2020 年 2 月份下单 product_id = 1 的产品的数目总和为 (60 + 70) = 130 。 2020 年 2 月份下单 product_id = 2 的产品的数目总和为 80 。 2020 年 2 月份下单 product_id = 3 的产品的数目总和为 (2 + 3) = 5 。 2020 年 2 月份 product_id = 4 的产品并没有下单。 2020 年 2 月份下单 product_id = 5 的产品的数目总和为 (50 + 50) = 100 。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
题解一
with b as ( select product_id ,sum(unit) as unit from orders a where date_format(order_date,'%Y-%m')='2020-02' group by product_id having sum(unit)>=100 ) select a.product_name ,unit from Products a inner join b on a.product_id=b.product_id- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
题解二
SELECT product_name, SUM(unit) AS unit FROM Products JOIN Orders USING (product_id) WHERE order_date LIKE "2020-02%" GROUP BY product_name HAVING unit >= 100;- 1
- 2
- 3
- 4
- 5
题解三
SELECT p1.product_name AS 'product_name', SUM(o1.unit) AS 'unit' FROM Orders AS o1 LEFT OUTER JOIN Products AS p1 ON o1.product_id = p1.product_id WHERE o1.order_date BETWEEN '2020-02-01' AND '2020-02-29' GROUP BY o1.product_id HAVING SUM(o1.unit) >= 100 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
题解四
SELECT p1.product_name AS 'product_name', SUM(o1.unit) AS 'unit' FROM Orders AS o1 LEFT OUTER JOIN Products AS p1 ON o1.product_id = p1.product_id WHERE LEFT(o1.order_date, 7) = '2020-02' GROUP BY o1.product_id HAVING SUM(o1.unit) >= 100 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
题解五
SELECT p1.product_name AS 'product_name', SUM(o1.unit) AS 'unit' FROM Orders AS o1 LEFT OUTER JOIN Products AS p1 ON o1.product_id = p1.product_id WHERE DATE_FORMAT(o1.order_date ,'%Y-%m') = '2020-02' GROUP BY o1.product_id HAVING SUM(o1.unit) >= 100 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
题解六
SELECT p1.product_name AS 'product_name', SUM(o1.unit) AS 'unit' FROM Orders AS o1 LEFT OUTER JOIN Products AS p1 ON o1.product_id = p1.product_id WHERE YEAR(o1.order_date) = '2020' AND MONTH(o1.order_date) = '02' GROUP BY o1.product_id HAVING SUM(o1.unit) >= 100 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
题解七
SELECT p1.product_name AS 'product_name', SUM(o1.unit) AS 'unit' FROM Orders AS o1 LEFT OUTER JOIN Products AS p1 ON o1.product_id = p1.product_id WHERE o1.order_date LIKE '2020-02-%' GROUP BY o1.product_id HAVING SUM(o1.unit) >= 100 ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
1336. 每次访问的交易次数
Create table If Not Exists Visits (user_id int, visit_date date) Create table If Not Exists Transactions (user_id int, transaction_date date, amount int) Truncate table Visits insert into Visits (user_id, visit_date) values ('1', '2020-01-01') insert into Visits (user_id, visit_date) values ('2', '2020-01-02') insert into Visits (user_id, visit_date) values ('12', '2020-01-01') insert into Visits (user_id, visit_date) values ('19', '2020-01-03') insert into Visits (user_id, visit_date) values ('1', '2020-01-02') insert into Visits (user_id, visit_date) values ('2', '2020-01-03') insert into Visits (user_id, visit_date) values ('1', '2020-01-04') insert into Visits (user_id, visit_date) values ('7', '2020-01-11') insert into Visits (user_id, visit_date) values ('9', '2020-01-25') insert into Visits (user_id, visit_date) values ('8', '2020-01-28') Truncate table Transactions insert into Transactions (user_id, transaction_date, amount) values ('1', '2020-01-02', '120') insert into Transactions (user_id, transaction_date, amount) values ('2', '2020-01-03', '22') insert into Transactions (user_id, transaction_date, amount) values ('7', '2020-01-11', '232') insert into Transactions (user_id, transaction_date, amount) values ('1', '2020-01-04', '7') insert into Transactions (user_id, transaction_date, amount) values ('9', '2020-01-25', '33') insert into Transactions (user_id, transaction_date, amount) values ('9', '2020-01-25', '66') insert into Transactions (user_id, transaction_date, amount) values ('8', '2020-01-28', '1') insert into Transactions (user_id, transaction_date, amount) values ('9', '2020-01-25', '99')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
表:
Visits+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | visit_date | date | +---------------+---------+ (user_id, visit_date) 是该表的主键 该表的每行表示 user_id 在 visit_date 访问了银行- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
表:
Transactions+------------------+---------+ | Column Name | Type | +------------------+---------+ | user_id | int | | transaction_date | date | | amount | int | +------------------+---------+ 该表没有主键,所以可能有重复行 该表的每一行表示 user_id 在 transaction_date 完成了一笔 amount 数额的交易 可以保证用户 (user) 在 transaction_date 访问了银行 (也就是说 Visits 表包含 (user_id, transaction_date) 行)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
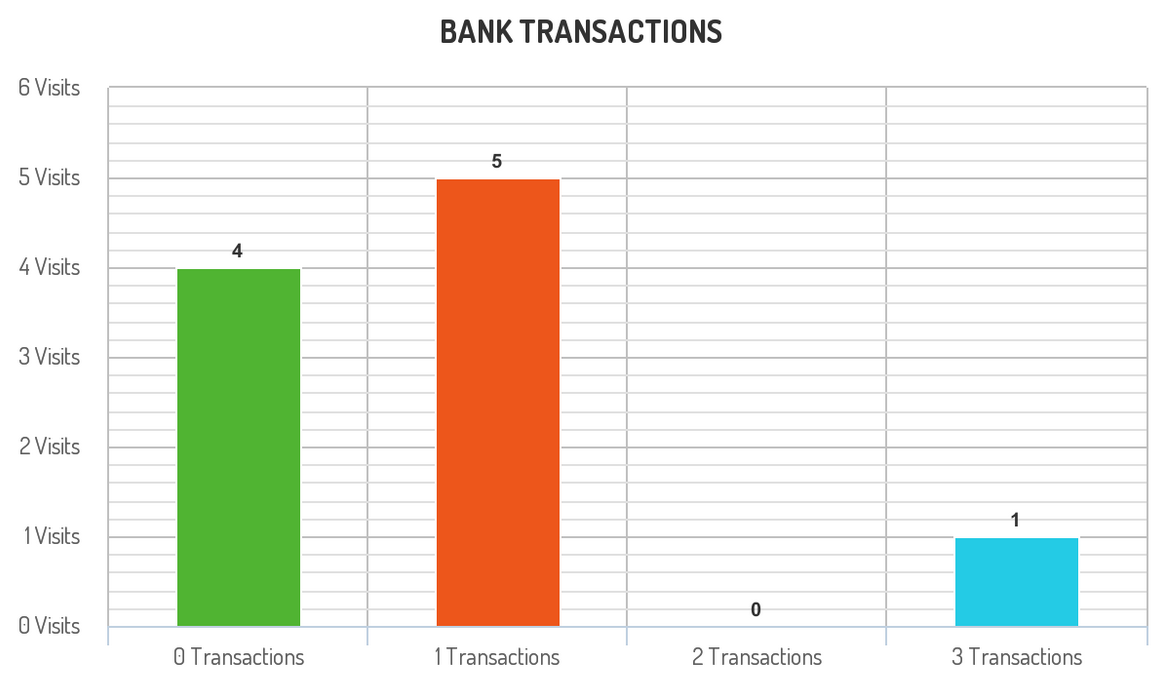
银行想要得到银行客户在一次访问时的交易次数和相应的在一次访问时该交易次数的客户数量的图表
写一条 SQL 查询多少客户访问了银行但没有进行任何交易,多少客户访问了银行进行了一次交易等等
结果包含两列:
transactions_count: 客户在一次访问中的交易次数 visits_count: 在 transactions_count 交易次数下相应的一次访问时的客户数量- 1
- 2
transactions_count 的值从 0 到所有用户一次访问中的 max(transactions_count)
按 transactions_count 排序
下面是查询结果格式的例子:
Visits 表: +---------+------------+ | user_id | visit_date | +---------+------------+ | 1 | 2020-01-01 | | 2 | 2020-01-02 | | 12 | 2020-01-01 | | 19 | 2020-01-03 | | 1 | 2020-01-02 | | 2 | 2020-01-03 | | 1 | 2020-01-04 | | 7 | 2020-01-11 | | 9 | 2020-01-25 | | 8 | 2020-01-28 | +---------+------------+ Transactions 表: +---------+------------------+--------+ | user_id | transaction_date | amount | +---------+------------------+--------+ | 1 | 2020-01-02 | 120 | | 2 | 2020-01-03 | 22 | | 7 | 2020-01-11 | 232 | | 1 | 2020-01-04 | 7 | | 9 | 2020-01-25 | 33 | | 9 | 2020-01-25 | 66 | | 8 | 2020-01-28 | 1 | | 9 | 2020-01-25 | 99 | +---------+------------------+--------+ 结果表: +--------------------+--------------+ | transactions_count | visits_count | +--------------------+--------------+ | 0 | 4 | | 1 | 5 | | 2 | 0 | | 3 | 1 | +--------------------+--------------+ * 对于 transactions_count = 0, visits 中 (1, "2020-01-01"), (2, "2020-01-02"), (12, "2020-01-01") 和 (19, "2020-01-03") 没有进行交易,所以 visits_count = 4 。 * 对于 transactions_count = 1, visits 中 (2, "2020-01-03"), (7, "2020-01-11"), (8, "2020-01-28"), (1, "2020-01-02") 和 (1, "2020-01-04") 进行了一次交易,所以 visits_count = 5 。 * 对于 transactions_count = 2, 没有客户访问银行进行了两次交易,所以 visits_count = 0 。 * 对于 transactions_count = 3, visits 中 (9, "2020-01-25") 进行了三次交易,所以 visits_count = 1 。 * 对于 transactions_count >= 4, 没有客户访问银行进行了超过3次交易,所以我们停止在 transactions_count = 3 。 如下是这个例子的图表:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
题解一
WITH RECURSIVE cte(n) AS #关键字RECURSIVE表明这段表达式是递归表达式 ( SELECT 0 #返回初始数据集 n=0 UNION ALL SELECT n+1 #返回其他数据集,迭代表达式n=n+1 FROM cte #引用自身,是实现递归的关键逻辑所在 WHERE n<( #终止条件,让n小于所有用户一次访问中的 max(transactions_count) SELECT COUNT(*) max_tra FROM Transactions GROUP BY transaction_date,user_id ORDER BY max_tra DESC LIMIT 1 ) ) SELECT n transactions_count, IFNULL(visits_count,0) visits_count #a2中交易次数tran_num没有2,又因为是左连接,transactions_count=2时,visits_count对应NULL,所以用IFNULL FROM cte c LEFT JOIN( SELECT tran_num, COUNT(tran_num) visits_count FROM( SELECT v.user_id user_id, v.visit_date visit_dat, COUNT(transaction_date) tran_num #COUNT中是transaction_date计算交易数 FROM Visits v LEFT JOIN Transactions t ON v.user_id=t.user_id AND v.visit_date=t.transaction_date GROUP BY v.user_id,v.visit_date ) a1 #a1返回某客户在某一天到银行的交易次数tran_num,因为transaction_date必然发生在visit_date中,所以使用左连接 GROUP BY tran_num ) a2 #a2主要返回在tran_num交易次数(0、1、3)中的一次访问时客户数量 ON c.n=a2.tran_num ORDER BY transactions_count- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
题解二
with recursive a as( select 0 as n union all select n+1 from a where n < (select max(transactions_count) from(select count(amount) as transactions_count from visits left join transactions on visits.user_id = transactions.user_id and visit_date = transaction_date group by visits.user_id,visit_date)x) ) select n as transactions_count,ifnull(visits_count,0) as visits_count from a left join (select transactions_count,count(1) as visits_count from( select count(amount) as transactions_count from visits left join transactions on visits.user_id = transactions.user_id and visit_date = transaction_date group by visits.user_id,visit_date )x group by transactions_count order by transactions_count)x on n = transactions_count- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
题解三
with tmp as ( select sum(amt>0) cnt from ( select user_id,visit_date dt,0 amt from Visits union all select user_id,transaction_date dt,amount amt from Transactions ) all_data group by user_id,dt ) select floor(n) transactions_count,count(cnt) visits_count from ( select 0 as n union all select (@x := @x+1) as n from Transactions,(select @x := 0) num ) nums left join tmp on nums.n = tmp.cnt where n <= (select max(cnt) from tmp) group by n- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1341. 电影评分
Create table If Not Exists Movies (movie_id int, title varchar(30)) Create table If Not Exists Users (user_id int, name varchar(30)) Create table If Not Exists MovieRating (movie_id int, user_id int, rating int, created_at date) Truncate table Movies insert into Movies (movie_id, title) values ('1', 'Avengers') insert into Movies (movie_id, title) values ('2', 'Frozen 2') insert into Movies (movie_id, title) values ('3', 'Joker') Truncate table Users insert into Users (user_id, name) values ('1', 'Daniel') insert into Users (user_id, name) values ('2', 'Monica') insert into Users (user_id, name) values ('3', 'Maria') insert into Users (user_id, name) values ('4', 'James') Truncate table MovieRating insert into MovieRating (movie_id, user_id, rating, created_at) values ('1', '1', '3', '2020-01-12') insert into MovieRating (movie_id, user_id, rating, created_at) values ('1', '2', '4', '2020-02-11') insert into MovieRating (movie_id, user_id, rating, created_at) values ('1', '3', '2', '2020-02-12') insert into MovieRating (movie_id, user_id, rating, created_at) values ('1', '4', '1', '2020-01-01') insert into MovieRating (movie_id, user_id, rating, created_at) values ('2', '1', '5', '2020-02-17') insert into MovieRating (movie_id, user_id, rating, created_at) values ('2', '2', '2', '2020-02-01') insert into MovieRating (movie_id, user_id, rating, created_at) values ('2', '3', '2', '2020-03-01') insert into MovieRating (movie_id, user_id, rating, created_at) values ('3', '1', '3', '2020-02-22') insert into MovieRating (movie_id, user_id, rating, created_at) values ('3', '2', '4', '2020-02-25')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
表:
Movies+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | title | varchar | +---------------+---------+ movie_id 是这个表的主键。 title 是电影的名字。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
表:
Users+---------------+---------+ | Column Name | Type | +---------------+---------+ | user_id | int | | name | varchar | +---------------+---------+ user_id 是表的主键。- 1
- 2
- 3
- 4
- 5
- 6
- 7
表:
MovieRating+---------------+---------+ | Column Name | Type | +---------------+---------+ | movie_id | int | | user_id | int | | rating | int | | created_at | date | +---------------+---------+ (movie_id, user_id) 是这个表的主键。 这个表包含用户在其评论中对电影的评分 rating 。 created_at 是用户的点评日期。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
请你编写一组 SQL 查询:
查找评论电影数量最多的用户名。如果出现平局,返回字典序较小的用户名。 查找在 February 2020 平均评分最高 的电影名称。如果出现平局,返回字典序较小的电影名称。- 1
- 2
字典序 ,即按字母在字典中出现顺序对字符串排序,字典序较小则意味着排序靠前。
查询结果格式如下例所示。
示例:
输入: Movies 表: +-------------+--------------+ | movie_id | title | +-------------+--------------+ | 1 | Avengers | | 2 | Frozen 2 | | 3 | Joker | +-------------+--------------+ Users 表: +-------------+--------------+ | user_id | name | +-------------+--------------+ | 1 | Daniel | | 2 | Monica | | 3 | Maria | | 4 | James | +-------------+--------------+ MovieRating 表: +-------------+--------------+--------------+-------------+ | movie_id | user_id | rating | created_at | +-------------+--------------+--------------+-------------+ | 1 | 1 | 3 | 2020-01-12 | | 1 | 2 | 4 | 2020-02-11 | | 1 | 3 | 2 | 2020-02-12 | | 1 | 4 | 1 | 2020-01-01 | | 2 | 1 | 5 | 2020-02-17 | | 2 | 2 | 2 | 2020-02-01 | | 2 | 3 | 2 | 2020-03-01 | | 3 | 1 | 3 | 2020-02-22 | | 3 | 2 | 4 | 2020-02-25 | +-------------+--------------+--------------+-------------+ 输出: Result 表: +--------------+ | results | +--------------+ | Daniel | | Frozen 2 | +--------------+ 解释: Daniel 和 Monica 都点评了 3 部电影("Avengers", "Frozen 2" 和 "Joker") 但是 Daniel 字典序比较小。 Frozen 2 和 Joker 在 2 月的评分都是 3.5,但是 Frozen 2 的字典序比较小。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
题解一
( select u.name as results from MovieRating r join Users u on r.user_id=u.user_id group by r.user_id order by count(r.movie_id) desc, u.name limit 0,1 ) union all ( select m.title as results from MovieRating r join Movies m on r.movie_id=m.movie_id where r.created_at between '2020-02-01' and '2020-02-29' group by r.movie_id order by avg(r.rating) desc, m.title limit 0,1 ) ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1350. 院系无效的学生
Create table If Not Exists Departments (id int, name varchar(30)) Create table If Not Exists Students (id int, name varchar(30), department_id int) Truncate table Departments insert into Departments (id, name) values ('1', 'Electrical Engineering') insert into Departments (id, name) values ('7', 'Computer Engineering') insert into Departments (id, name) values ('13', 'Bussiness Administration') Truncate table Students insert into Students (id, name, department_id) values ('23', 'Alice', '1') insert into Students (id, name, department_id) values ('1', 'Bob', '7') insert into Students (id, name, department_id) values ('5', 'Jennifer', '13') insert into Students (id, name, department_id) values ('2', 'John', '14') insert into Students (id, name, department_id) values ('4', 'Jasmine', '77') insert into Students (id, name, department_id) values ('3', 'Steve', '74') insert into Students (id, name, department_id) values ('6', 'Luis', '1') insert into Students (id, name, department_id) values ('8', 'Jonathan', '7') insert into Students (id, name, department_id) values ('7', 'Daiana', '33') insert into Students (id, name, department_id) values ('11', 'Madelynn', '1')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
ozen 2 |
±-------------+
解释:
Daniel 和 Monica 都点评了 3 部电影(“Avengers”, “Frozen 2” 和 “Joker”) 但是 Daniel 字典序比较小。
Frozen 2 和 Joker 在 2 月的评分都是 3.5,但是 Frozen 2 的字典序比较小。题解一 ```sql ( select u.name as results from MovieRating r join Users u on r.user_id=u.user_id group by r.user_id order by count(r.movie_id) desc, u.name limit 0,1 ) union all ( select m.title as results from MovieRating r join Movies m on r.movie_id=m.movie_id where r.created_at between '2020-02-01' and '2020-02-29' group by r.movie_id order by avg(r.rating) desc, m.title limit 0,1 ) ;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
1350. 院系无效的学生
Create table If Not Exists Departments (id int, name varchar(30)) Create table If Not Exists Students (id int, name varchar(30), department_id int) Truncate table Departments insert into Departments (id, name) values ('1', 'Electrical Engineering') insert into Departments (id, name) values ('7', 'Computer Engineering') insert into Departments (id, name) values ('13', 'Bussiness Administration') Truncate table Students insert into Students (id, name, department_id) values ('23', 'Alice', '1') insert into Students (id, name, department_id) values ('1', 'Bob', '7') insert into Students (id, name, department_id) values ('5', 'Jennifer', '13') insert into Students (id, name, department_id) values ('2', 'John', '14') insert into Students (id, name, department_id) values ('4', 'Jasmine', '77') insert into Students (id, name, department_id) values ('3', 'Steve', '74') insert into Students (id, name, department_id) values ('6', 'Luis', '1') insert into Students (id, name, department_id) values ('8', 'Jonathan', '7') insert into Students (id, name, department_id) values ('7', 'Daiana', '33') insert into Students (id, name, department_id) values ('11', 'Madelynn', '1')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
-
相关阅读:
NFTScan 浏览器再升级:优质数据服务新体验来袭
Hive主要介绍
《Java8实战》读书笔记09:用 Optional 处理值为 null 的情况
(D卷,100分)- 最富裕的小家庭(Java & JS & Python & C)
Map集合保存数据库
怎么做线性回归?多元线性回归_图灵死的很传奇_咬一口苹果有氯化钠?什么鬼..深度学习_机器学习_人工智能深度回顾---人工智能工作笔记0019
qt中判断字符相等这样才可以否则一直为false,buffer[0]==(char)(0xaa)
编译原理总结
提出问题,解答问题!这才是理解代码设计的正确方法
第9关:生成器与 yield
- 原文地址:https://blog.csdn.net/weixin_45682261/article/details/126066565
