-
Hive及Sqoop的表操作
环境信息
1. 硬件:
内存ddr3 4G及以上的x86架构主机一部
系统环境:windows2. 软件:
运行vmware或者virtualbox
3. 其他: 无步骤与方法
1. Hive、Sqoop和MySQL的安装和配置
(1)MySql安装配置
1、下载MySql数据库



将安装包复制到master节点的目录下


2、安装MySql数据库
解压
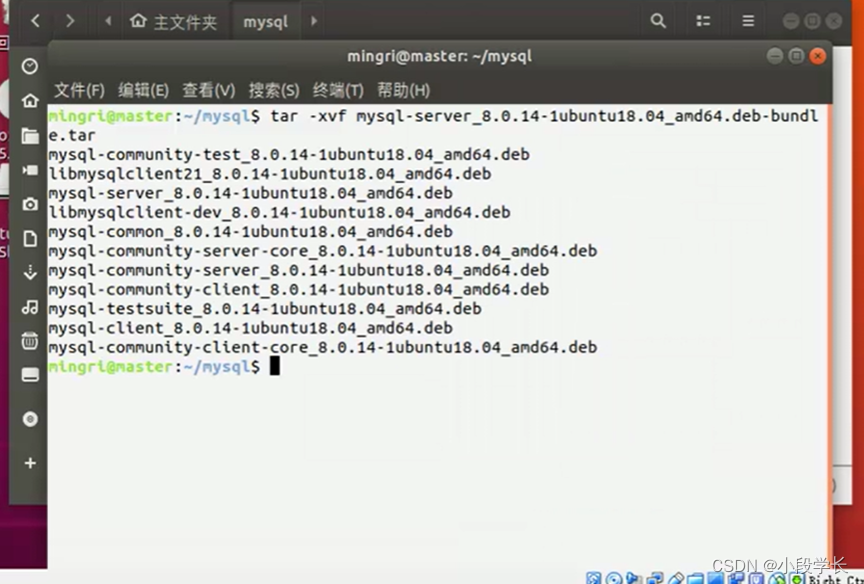
升级依赖

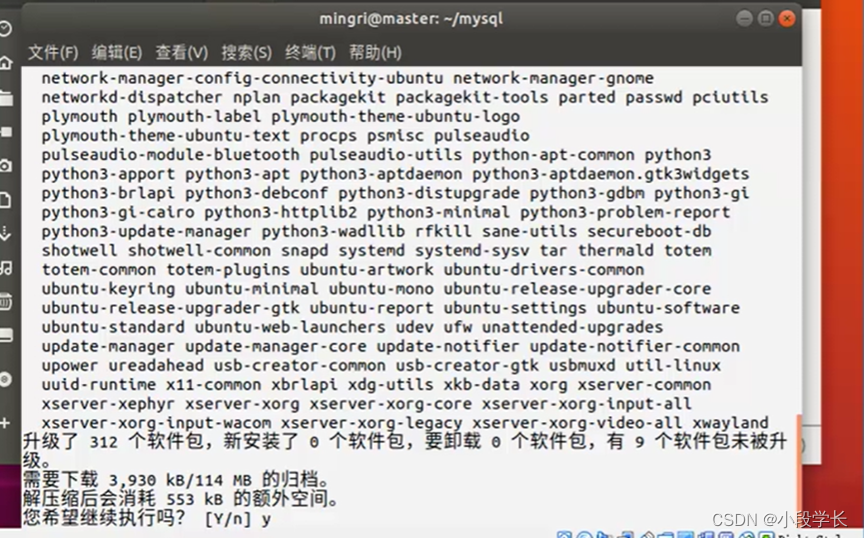

安装依赖包

顺序安装deb程序包


设置root密码





检验mysql是否安装成功

(2)hive安装配置
1、下载hive


安装包移动到master主目录下

解压安装包

配置Hive






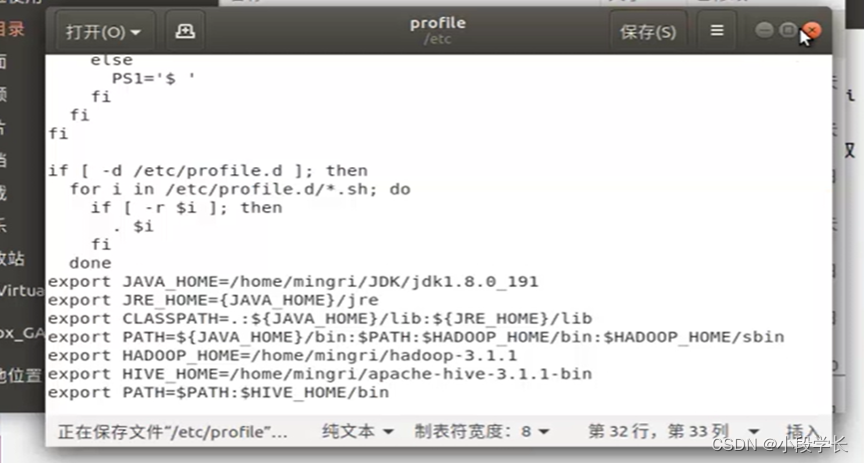



复制MySql的驱动程序


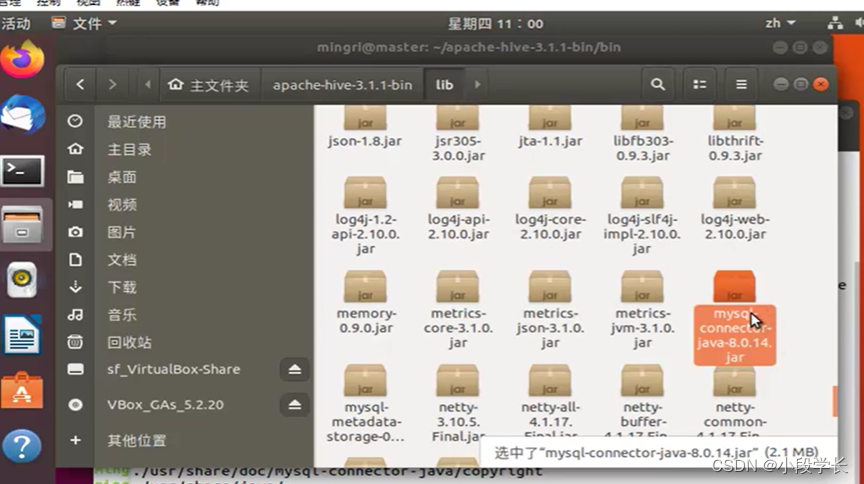
元数据初始化


启动验证Hive
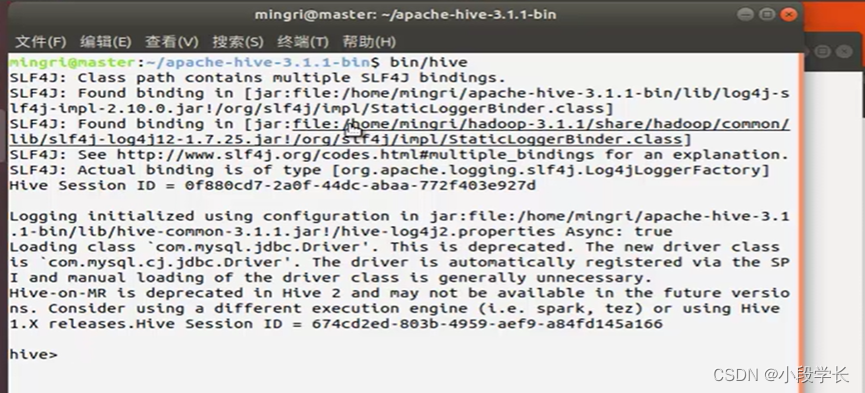
(3)Sqoop安装配置
下载Sqoop


解压并安装Sqoop


复制MySql驱动程序


配置Sqoop变量


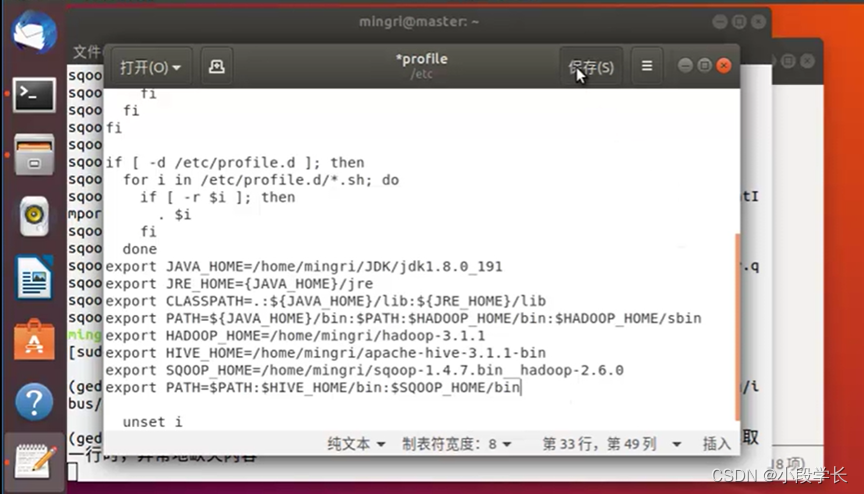

验证Sqoop


Hive中的表操作
(1)查看数据表


(2)创建数据表

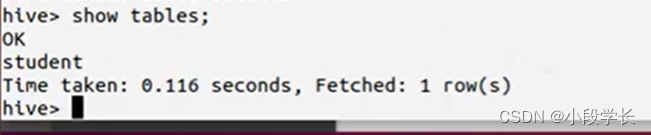
AS查询建表

(3)修改数据表





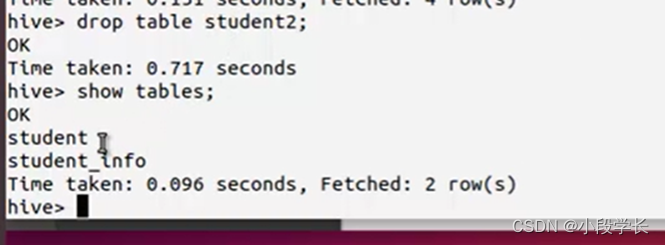
2. Hive和MySQL间的数据导入导出
(1)加载HDFS数据


(2)导出数据到HDFS


3. 使用Sqoop将HDFS数据与SQL数据导入导出
(1)使用Sqoop把MySql数据导入HDFS



(2)使用Sqoop将HDFS数据导出到MySql


4. 使用Sqoop将Hive数据与SQL数据导入导出
使用Sqoop把Msql数据导入HIVE
将文件复制到Sqoop的安装目录的lib目录下面

启动HIVE

确认Hvie中不存在要导入的表

使用Sqoop实现数据导入



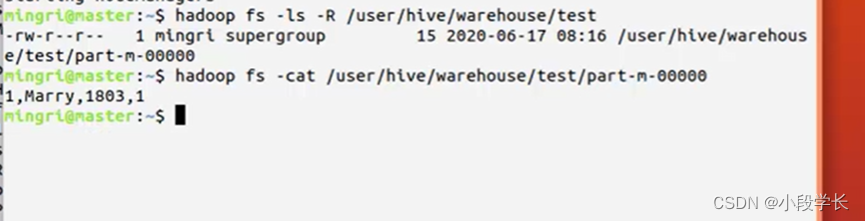
检验Hive是否被导入了student表

查看user/hive/warehouse/student目录文件,并查看次文件内容
出现的问题及解决方法
Sqoop将业务数据SQLServer数据导入到HDFS时,出现如下错误:
Container[pid=19170,containerID=container_e43_1604046194386_1457_01_000004] is running 802816B beyond the ‘PHYSICAL’ memory limit. Current usage: 1.0 GB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used

错误分析:
1.0GB 任务所占的物理内存
1GB: mapreduce.map.memory.mb 参数默认设置大小(设置的是物理内存)
2.5GB:程序所占用的虚拟内存
2.1GB: mapreduce.map.memory.mb 乘以 yarn.nodemanager.vmem-pmem-ratio 得到的其中 yarn.nodemanager.vmem-pmem-ratio是虚拟内存和物理内存的占比,在yarn-site.xml中设置,默认值是2.1
注:mapreduce.map.memory.mb和mapreduce.reduce.memory.mb默认为0,表示会根据最大堆大小 和 堆与容器的比值 设置 需要的物理内存。如果没有指定最大堆大小,则物理内存默认设置为1G
很明显,Container占用了2.5G的虚拟内存,但是分配给Container的却只有2.1G,所以kill掉了这个Continer,
上面只是map中产生的报错,当然也有可能在reduce中报错,如果是在reduce中,那么计算就是mapreduce.reduce.memory.db * yarn.nodemanager.vmem-pmem-ratio
概念解释:
物理内存:真实的硬件设备(内存条)
虚拟内存:利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(Swap Space).(为了满足物理内存的不足而提出的策略)
Linux会在物理内存不足时,使用交换分区的虚拟内存。内核会将暂时不用的内存块信息写到交换空间,这样以来,物理内存得到了释放,这块内存就可以用于其它的目的,当需要用到原始的内容时,这些信息会被重新从交换空间读到物理内存。解决方案:
1、取消虚拟内存检查(yarn-site.xml或程序中中设置yarn.nodemanager.vmem-check-enabled为false)
<property> <name>yarn.nodemanager.vmem-check-enabledname> <value>falsevalue> <description>Whether virtual memory limits will be enforced for containers.description> property>- 1
- 2
- 3
- 4
- 5
除了虚拟内存超了,也有可能是物理内存超了,同样可以设置物理内存的检查yarn.nodemanager.pmem-check-enabled :false
<property> <name>yarn.nodemanager.pmem-check-enabledname> <value>falsevalue> <description>Whether Pyscial memory limits will be enforced for containers.description>- 1
- 2
- 3
- 4
2 、增大mapreduce.map.memory.mb 或者 mapreduce.map.memory.mb
项目中所使用的机器内存为32G,将上述参数调整到2G大小

3 、适当增大 yarn.nodemanager.vmem-pmem-ratio的大小,为物理内存增加对应的虚拟内存,但是该参数不能设置太离谱
4 、如果任务所占用的内存太过离谱,更多考虑的应该是程序是否有内存泄漏,是否存在数据倾斜等,优先程序解决此类问题结果、结果分析
1、MySql安装配置成功
2、Hive安装配置成功

3、Sqoop安装配置成功
4、Hive和MySQL间的数据导入导出
导入:
导出:

5、使用Sqoop将HDFS数据与SQL数据导入导出
导入:

导出:
6、使用Sqoop将Hive数据与SQL数据导入导出
导入:

心得体会
实现了Hive、Sqoop和MySQL的安装和配置; Hive中的表操作;
Hive和MySQL间的数据导入导出使用Sqoop将本地数据、HDFS数据与SQL数据导入导出;使用Sqoop将Hive数据与SQL数据导入导出;
过程中,遇到了多种困难,例如,版本问题,代码运行失败等等。尽管配置过程艰辛,但配置成功时你必然很开心。或许启动会出错,但是每一个错误又何尝不是一种挑战呢?通过对出现问题的学习解决,从中学到了许多,了解到了学习不单单是看和写,更多的是对学习到的知识加以实践和应用。想起一句梗:消灭恐惧的最好方法就是面对恐惧。在学习的过程中我深深体会到了积累知识的重要性。俗话说:“要想为事业多添一把火,自己就得多添一捆材”,我对此话深有感触。再次,“纸上得来终觉浅,绝知此事要躬行!”,在短暂的实验过程中,让我深深的感觉到自己在实际运用中的专业知识的匮乏,以为自己学的不错,一旦接触到实际,才发现自己知道的是多么少,这时才真正领悟到“学无止境”的含义。
欢迎大家加我微信交流讨论(请备注csdn上添加)

-
相关阅读:
用c语言实现矩阵转置
设计模式学习笔记 - 面向对象 - 7.为什么要多用组合少用继承?如何决定该用组合还是继承?
全面解析:Foxit Reader支持的操作系统及其特性
SplitMask:大规模数据集是自我监督预训练的必要条件吗?
分布式session解决方案 — — JWT(生成token)
集群保持集群负载均衡和hash一致性
【图论】最小生成树(python和cpp)
springboot引入外部jar,package打包报错找不到程序包XXX
基于Spark的电影推荐系统实现
华为云双十一服务器数据中心带宽全动态BGP和静态BGP区别
- 原文地址:https://blog.csdn.net/weixin_45962068/article/details/126063658