-
MySQL面试题
为什么建议InnoDB表必须建立主键?
使用InnoDB创建的索引和数据都放在
idb文件中,整个文件就是一颗B+树,而这颗B+树是按照主键来组织的,因此必须有主键- 如果有主键,直接使用主键索引来组织整张表的数据
- 如果不建立主键,mysql会自动在列中找出一个没有重复数据的列建立唯一索引
- 找不到建立唯一索引的列,就会自动生成一个隐藏列建立唯一索引,来组织整张表
所以如果我们不手动建立主键索引的话,InnoDB最终还是会建立的,因此在创建表的时候就可以直接建立主键
为什么InnoDB推荐使用 int 整型的自增主键?
使用整形作为主键:
- 比uuid更省空间,int4字节,UUID16字节
- 比uuid之间比较大小,快了很多
- 如果主键字段过长,引用主键的辅助索引也会过长,浪费资源
使用自增:
- B+树本身是有序的数据结构,如果主键不是⾃增的,在进行增删数据的时候,要判断数据应该存放的位置,进行插⼊和删除,为了保持B+树有序的特性,会频繁地分裂来调整B+树,严重影响性能,所以主键需要是自增的,插⼊时,插⼊在索引数据页末尾。
B+树索引 与 Hash索引
Hash索引
- 对索引的key进行一次hash计算,定位出数据的存储位置
- hash索引定位数据更高效
- 但是只能满足“=”、“IN”,不支持范围查询、模糊查询、排序操作、最左前缀原则
而B+树支持范围查询
因为B+树的叶子节点存储的是索引和数据,每个叶子节点之间都有双向指针指向,适合范围查找最左前缀原则的原理
多个字段建立组合索引时,查询时,必须出现组合索引中最左边的字段,否则这条语句不走索引。
为什么不符合最左前缀就不走索引?
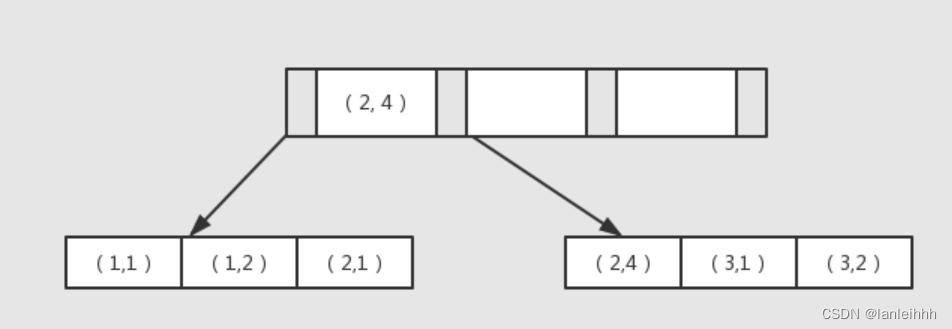
组合索引也是用B+树来存储的,也是有序的
对a.b两个字段建立组合索引-
a字段是排序的,而b字段相对于a的同一个记录中,b是排序的
a=1时,b=1,2 排序
a=2时,b=1,4 排序
a=3时,b=1,2 排序 -
脱离了a字段,b就是1,2,1,4,1,2;不是排序的
因此,如果查询的时候,直接查询b字段,select * from table where b = ?,索引是有序的数据结构,这样查询,索引会失效,只有先查到a字段,才能查到a字段相同记录中b的排序情况
同理,对于(a, b, c)联合索引来说,查询 (a, b) 可以用到这个联合索引,但是查询 (b, c) 就没办法使用这个联合索引,因为 b 和 c 列的有序性都是依托于 a 列的存在的。
B树 与 B+ 树区别
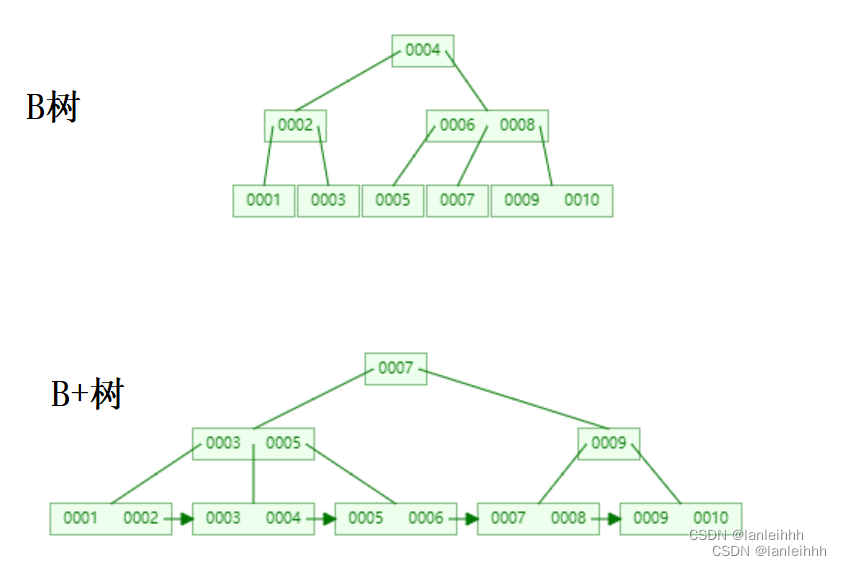
数据库中范围查找是常态
- B树叶子结点之间没有指针指向,不适合区间范围查询,只能一个一个遍历,每遍历一个元素都会走一次根节点到叶子节点,效率低
- B+树叶子节点之间有指针指向,适合区间范围查询,找到区间的边界元素后,只需要遍历一次叶子节点就可以完成区间查询
节点存储数据
- B+树的叶子结点存储索引和数据,非叶子节点只存储冗余的索引,不存储指向磁盘中数据的地址,相比B树可以存储更多的索引。每次读到内存中的数据也更多,减少了磁盘IO。每次查询的路径都是从根节点到叶子节点,查询效率稳定
- B树结点存储索引和数据在磁盘中的地址。
MyISAM 和 InnoDB的区别
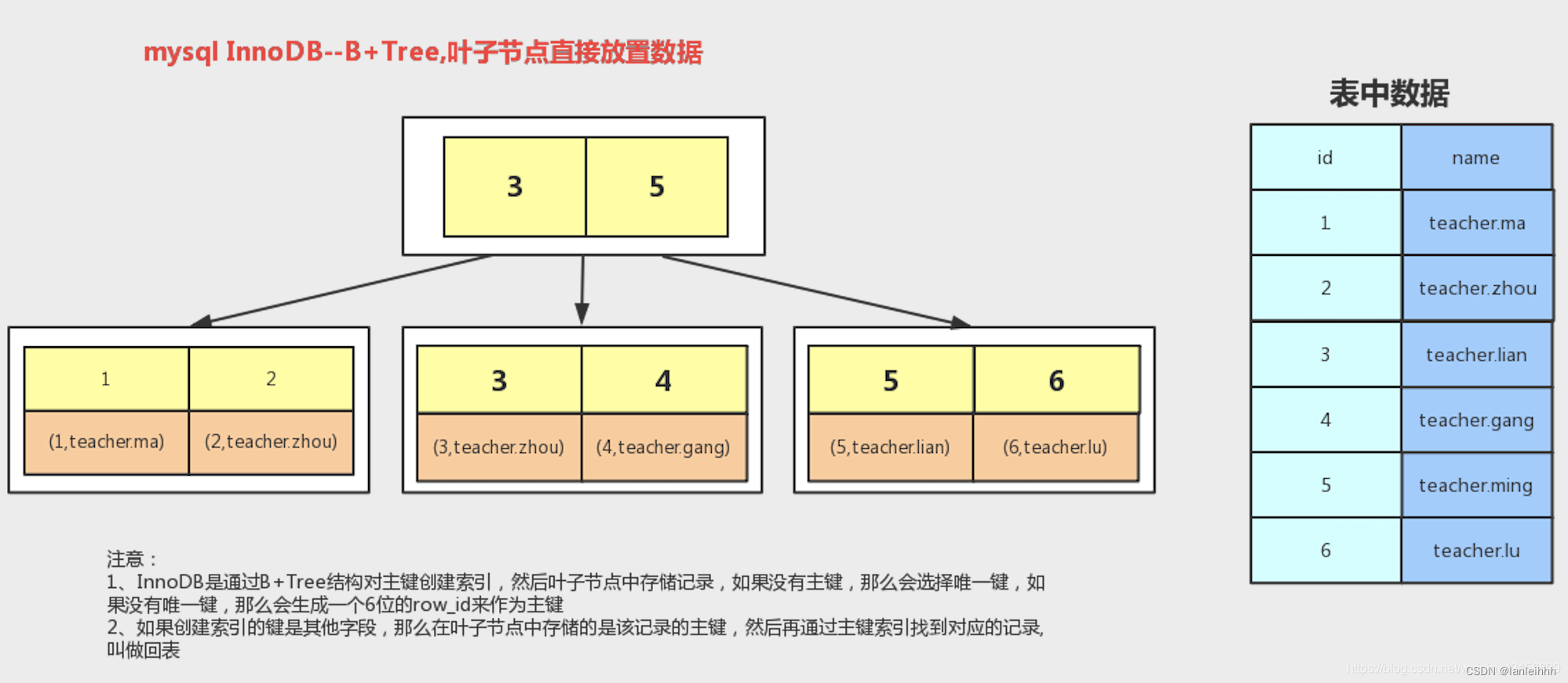
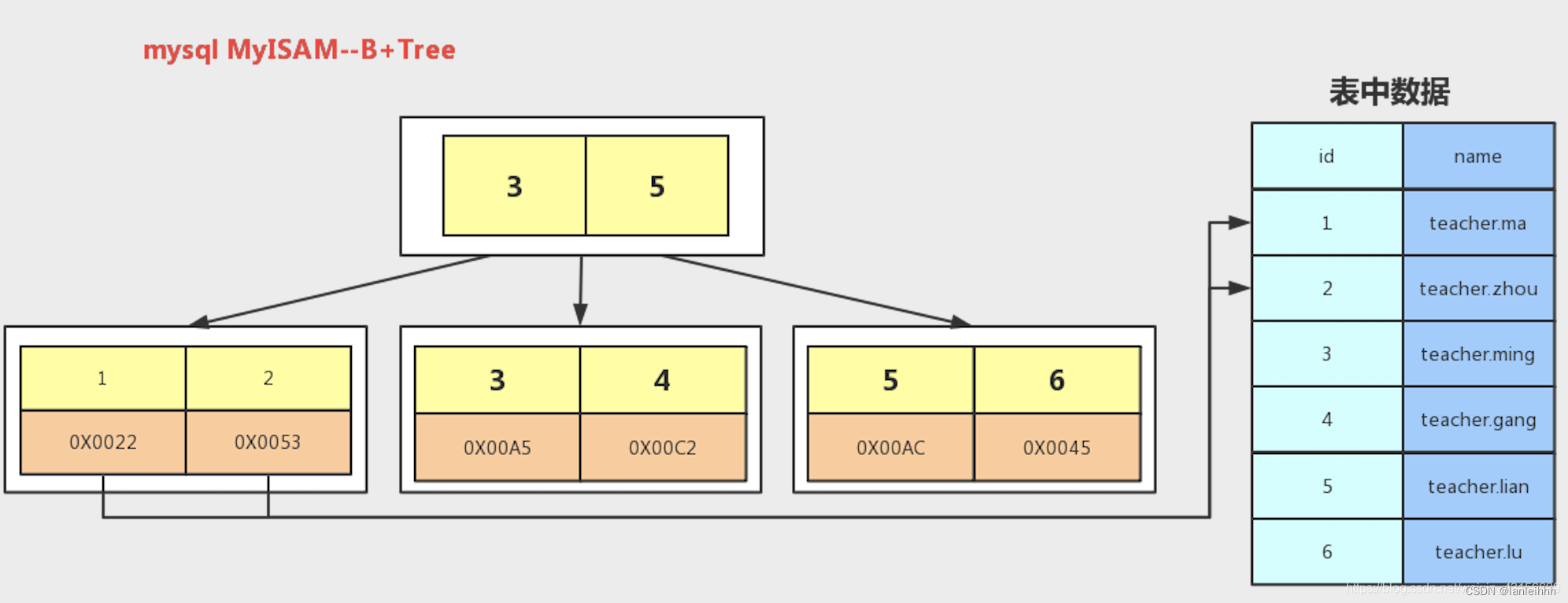

- InnoDB ⽀持事务,MyISAM 不⽀持事务。
- InnoDB ⽀持外键,MyISAM 不⽀持。
对⼀个包含外键的 InnoDB 表转为 MYISAM 会失败; - InnoDB 是聚簇索引,MyISAM 是非聚簇索引。
- 聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很⾼。
但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据(回表)。所以主键不应该过大,如果主键太大,引用主键的辅助索引这些也都会很大。 - MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的地址。主键索引和辅助索引是独立的。
- 聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很⾼。
-
- InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。
- MyISAM 用⼀个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
- InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。
事务、并发是数据库必不可少的,因此,默认存储引擎由MyISAM变成了InnoDB
InnoDB是如何支持范围查找 走索引的?
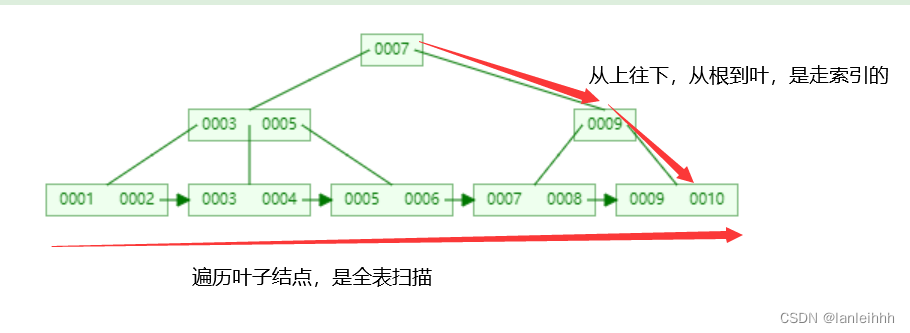
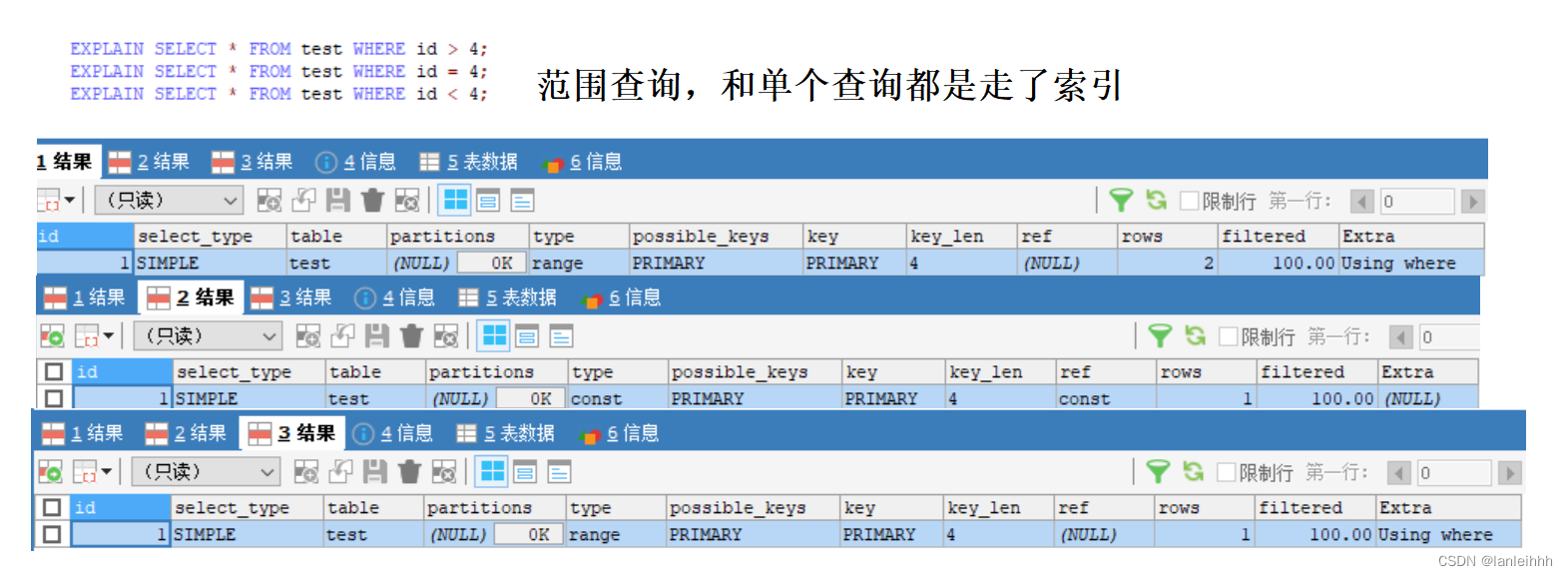
- 查找id>6的,先走索引查到id=6的叶子结点,返回该结点后面的所有数据
- 查找id<6,先走索引查找到id=6的叶子结点,返回该阶段之前的所有数据
- B+树叶子节点直接维护了双向指针,可以向前或者向后查找
联合索引中范围查找,索引失效的原因?
a,b,c建立联合索引
select * from table where a = ? and b > ? and c = ?;根据 a 找到 m行数据,在这m行数据中,根据b>?找到这n行数据,在这n行数据中,c的大小不是有序的,无法再走索引,所以失效了
只有前面的字段条件相同时,当前的字段才是有序的,才可以走索引,一旦前面的条件不是唯一的,当前字段就不是有序的了,无法走索引
覆盖索引
- 主键索引:叶子节点保存数据
- 辅助索引:叶子结点保存主键值
回表:使用辅助索引查找数据,先找到主键索引的值,再去主键索引中找到叶子结点上的数据
覆盖索引:辅助索引上已经存在了需要查找的数据,这样就不会再去主键索引中查找了;a,b,c建立联合索引
select b from table where b = ?;select b,c from table where b = ?;

-
相关阅读:
自制操作系统日志——第十七天
项目示例 - 4.配置中心 - 1.Nacos
优雅的实现EasyPoi动态导出列的两种方式
VNC:Timed out waiting for a response from the computer
超写实虚拟人制作教程
无线耳机什么质量好?音质较高的无线蓝牙耳机盘点
MaxViT: Multi-Axis Vision Transformer
qt 多语言版本 QLinguist使用方法
云计算技术 — 混合云 — 技术架构
SQL注入作业
- 原文地址:https://blog.csdn.net/lanleihhh/article/details/126062492

