-
Pytorch框架学习记录7——卷积层
Pytorch框架学习记录7——卷积层
1. torch.nn.Conv2d 介绍
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)参数
- in_channels ( int ) – 输入图像中的通道数
- out_channels ( int ) – 卷积产生的通道数
- kernel_size ( int or tuple ) – 卷积核的大小
- stride ( int or tuple , optional ) – 卷积的步幅。默认值:1
- padding ( int , tuple或str , optional ) – 添加到输入的所有四个边的填充。默认值:0
- padding_mode (字符串*,*可选) –
'zeros','reflect','replicate'或'circular'. 默认:'zeros' - dilation ( int or tuple , optional ) – 内核元素之间的间距。默认值:1
- groups ( int , optional ) – 从输入通道到输出通道的阻塞连接数。默认值:1
- bias ( bool , optional ) – If
True,向输出添加可学习的偏差。默认:True
输入图像高度和宽度与输出图像的高度和宽度计算公式:
H o u t = ⌊ ( H i n + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l _ s i z e [ 0 ] − 1 ) − 1 ) / s t r i d e [ 0 ] + 1 ⌋ H_{out}=⌊(H_{in}+2×padding[0]−dilation[0]×(kernel\_size[0]−1)−1)/stride[0]+1⌋ Hout=⌊(Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1)/stride[0]+1⌋W o u t = ⌊ ( W i n + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l _ s i z e [ 1 ] − 1 ) − 1 ) / s t r i d e [ 1 ] + 1 ⌋ W_{out}=⌊(W_{in}+2×padding[1]−dilation[1]×(kernel\_size[1]−1)−1)/stride[1]+1⌋ Wout=⌊(Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1)/stride[1]+1⌋
这里的output_channels就代表着卷积核的个数,卷积核的个数=输出频道的个数
2. 实例
下面的实例就使用之前学习到的方法构建了一个简单的卷积网络,并对输入输出图像进行展示对比。
import torch import torchvision.datasets from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter dataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True) dataloader = DataLoader(dataset=dataset, batch_size=64, num_workers=0) class Test(nn.Module): def __init__(self): super(Test, self).__init__() self.conv2d = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0) def forward(self, x): x = self.conv2d(x) return x writer = SummaryWriter("logs") test = Test() step = 0 for data in dataloader: imgs, target = data output = test(imgs) print(imgs.shape) print(output.shape) output = torch.reshape(output, (-1, 3, 30, 30)) writer.add_images("input", imgs, step) writer.add_images("output", output, step) step += 1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
原始图像:
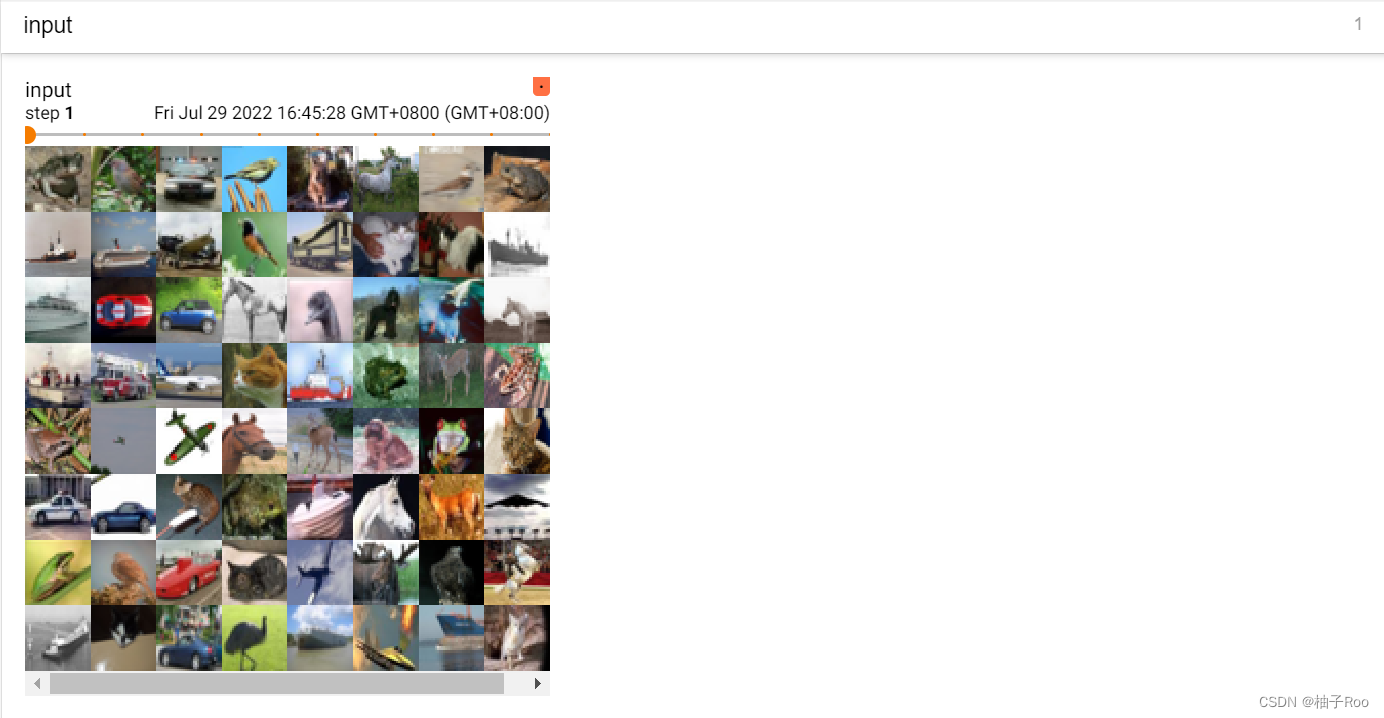
卷积后的图像:

-
相关阅读:
AI/DM相关conference ddl(更新中)
练习计划 01——1,2,3,4能组成多少三位数?
ICCV 2023|Occ2Net,一种基于3D 占据估计的有效且稳健的带有遮挡区域的图像匹配方法...
2022深圳杯D题思路:复杂水平井三维轨道设计
HR人才测评,什么是协调能力?如何提高协调能力?
linux创建ftp账号
CentOS密码重置
【记录】实现从Linux下载下载文件(文件导出功能)并记录过程产生的BUG问题。
计算机视觉系列-YOLOX 在 MMDetection 中复现全流程解析(一)
Golang【Web 入门】 08 集成 Gorilla Mux
- 原文地址:https://blog.csdn.net/qq_45955883/article/details/126060031
