-
pytorch与keras的相互转换(代码以LeNet-5为例)
本文以LeNet-5为例,简单介绍pytorch与keras的相互转换。
一、Keras
1.1 数据集加载与预处理
首先是导入相关包,然后加载MNIST数据
#加载数据 (x_train, y_train), (x_test, y_test) = mnist.load_data() # #(60000,28,28) # print('x_shape',x_train.shape) # #(60000) # print('y_shape',y_train.shape)- 1
- 2
- 3
- 4
- 5
- 6
然后对数据集进行处理:将数据reshape为(-1,28,28,1)的四维向量,1表示黑白图像(3表示彩色图像),之后进行归一化,将标签转为one-hot编码。
#数据集处理 x_train=x_train.reshape(-1,28,28,1)/255.0 #reshape为(60000,28,28,1)的四维向量,1表示黑白图像(3表示彩色图像);/255表示归一化 x_test=x_test.reshape(-1,28,28,1)/255 #标签转换为one-hot编码 y_train=np_utils.to_categorical(y_train,num_classes=10) y_test=np_utils.to_categorical(y_test,num_classes=10)- 1
- 2
- 3
- 4
- 5
- 6
1.2 搭建模型
模型结构如下:
model = Sequential() model.add(Conv2D(6,kernel_size=(5,5),padding='same',strides=(1,1),activation='sigmoid')) model.add(AveragePooling2D(pool_size=(2,2))) model.add(Conv2D(16, kernel_size=(5,5), activation='sigmoid')) model.add(AveragePooling2D(pool_size=(2,2))) #池化后变成16个4x4的矩阵,然后把矩阵压平变成一维的,一共256个单元 model.add(Flatten()) # 下面就是全连接层了 model.add(Dense(120, activation='sigmoid')) model.add(Dense(84, activation='sigmoid')) # softmax激活函数是用于计算该输入图像属于0-9数字的概率 model.add(Dense(10,activation='softmax'))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以使用summary查看模型结构,模型结构如下:

1.3 训练模型
使用Adam优化器进行加速,以及二元交叉熵损失作为损失函数:
adam=Adam(lr=0.01) model.compile(loss="categorical_crossentropy", optimizer=adam, metrics=['accuracy'])- 1
- 2
然后使用fit函数进行训练:
model.fit(x_train,y_train,batch_size=64,epochs=10,validation_split=0.2,shuffle=True)- 1
1.4 评估模型
可以使用evaluate函数评估模型的准确率和损失:
#评估模型 loss,accuracy=model.evaluate(x_test,y_test) print('\naccuracy:',np.round_(accuracy*100,5),'%') print('\ntest loss:',loss)- 1
- 2
- 3
- 4
运行的准确率和损失如下:
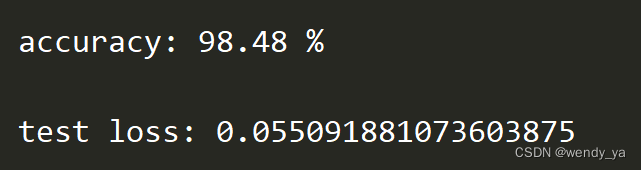
二、Pytorch
2.1 数据集加载与预处理
首先是导入相关包,然后加载MNIST数据集:
#定义加载数据集函数 def load_data_mnist(batch_size): '''下载MNIST数据集然后加载到内存中''' train_dataset=datasets.MNIST(root='data',train=True,transform=transforms.ToTensor(),download=True) test_dataset=datasets.MNIST(root='data',train=False,transform=transforms.ToTensor(),download=True) return (data.DataLoader(train_dataset,batch_size,shuffle=True), data.DataLoader(test_dataset,batch_size,shuffle=False)) #LeNet-5在MNIST数据集上的表现 batch_size=64 train_iter,test_iter=load_data_mnist(batch_size=batch_size)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.2 搭建模型
接下来进行搭建模型,模型输入为(-1,1,28,28)【注意这里与keras不同】,然后进行搭建:
#LeNet-5网络结构 net=nn.Sequential( Reshape(),nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(), nn.AvgPool2d(kernel_size=2,stride=2), nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(), nn.AvgPool2d(kernel_size=2,stride=2),nn.Flatten(), nn.Linear(16*5*5,120),nn.Sigmoid(), nn.Linear(120,84),nn.Sigmoid(), nn.Linear(84,10))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
搭建完成后对模型检查模型层次:
#检查模型 x=torch.rand(size=(1,1,28,28),dtype=torch.float32) for layer in net: x=layer(x) print(layer.__class__.__name__,'output shape:\t',x.shape)- 1
- 2
- 3
- 4
- 5
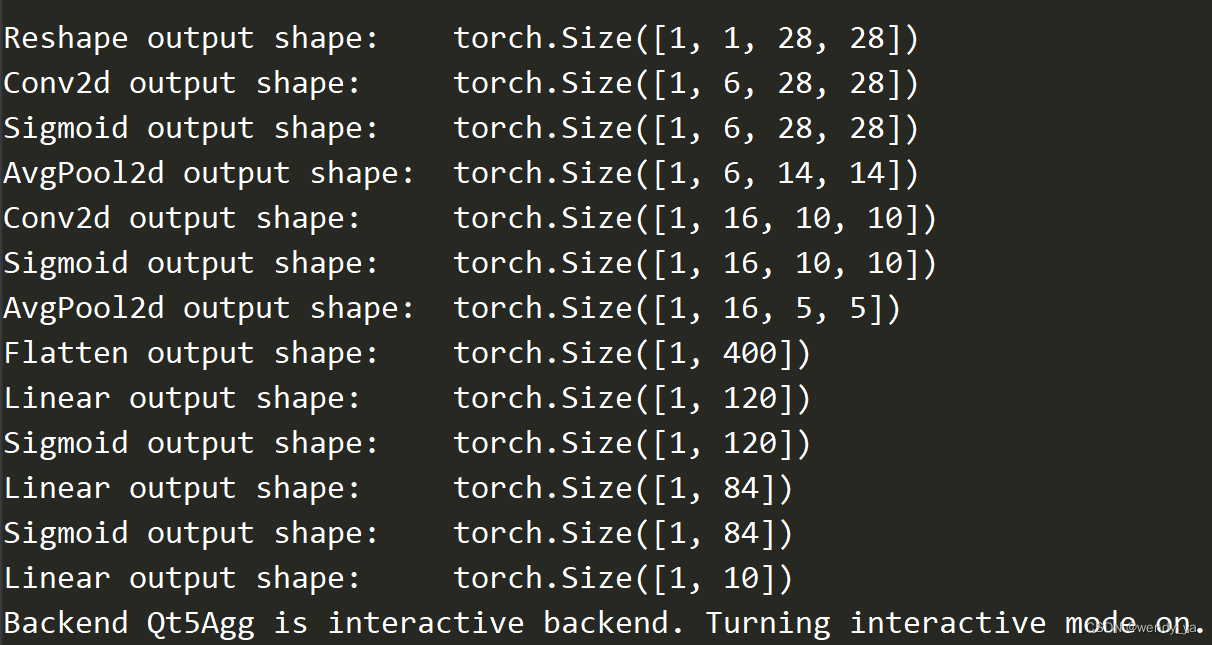
2.3 训练模型
定义损失函数和优化器,损失函数使用二元交叉熵损失CrossEntropyLoss,优化器采用Adam优化器:
#损失函数 loss_function=nn.CrossEntropyLoss() #优化器 optimizer=torch.optim.Adam(net.parameters())- 1
- 2
- 3
- 4
训练10个批次,训练代码如下:
# 开始训练 num_epochs = 10 train_loss = [] for epoch in range(num_epochs): for batch_idx, (x, y) in enumerate(train_iter): # x = x.view(x.size(0), 28 * 28) out = net(x) y_onehot = F.one_hot(y, num_classes=10).float() # 转为one-hot编码 loss = loss_function(out, y_onehot) # 均方差 # 清零梯度 optimizer.zero_grad() loss.backward() # w' = w -lr * grad optimizer.step() train_loss.append(loss.item()) if batch_idx % 10 == 0: print(epoch, batch_idx, loss.item())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
并绘制损失曲线:
#绘制损失曲线 plt.figure(figsize=(8,3)) plt.grid(True,linestyle='--',alpha=0.5) plt.plot(train_loss,label='loss') plt.legend(loc="best") plt.show()- 1
- 2
- 3
- 4
- 5
- 6
2.4 评估模型
利用训练好的模型评估测试准确率:
total_correct = 0 for batch_idx, (x, y) in enumerate(test_iter): # x = x.view(x.size(0),28*28) out = net(x) pred = out.argmax(dim=1) correct = pred.eq(y).sum().float().item() total_correct += correct total_num = len(test_iter.dataset) test_acc = total_correct / total_num print(total_correct, total_num) print("test acc:", test_acc)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行结果如下:
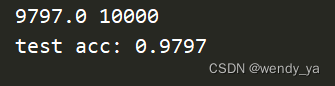
三、区别与联系
通过以上代码,可以明显看到,Keras的代码要比PyTorch更简单。
总结:Keras PyTorch 输入 Keras的输入是(-1,28,28,1)的四维向量,通道放在最后一维上 Pytorch的输入是(-1,1,28,28),通道在第二个维度上 模型搭建 Keras的模型无需表明输入,只需表明输出即可 Pytorch的模型搭建必须标明输入和输出 模型训练 Keras利用fit函数进行模型训练,较为简洁 Pytorch利用迭代进行模型训练且梯度清零、误差反馈和梯度更新这三行代码是必不可少的代码 评估模型 Keras利用evaluate评估模型 Pytorch利用net网络的输出评估模型 参考:
-
相关阅读:
【无标题】
714. 买卖股票的最佳时机含手续费
Vue3前端实现一个本地消息队列(MQ), 让消息延迟消费或者做缓存
AOP实现注解式脱敏数据明文查询
AXI Quad SPI IP核配置详解
CV面试知识点总结
easyrecovery数据恢复软件免费版下载
多目标进化算法详细讲解及代码实现(样例:MOEA/D、NSGA-Ⅱ求解多目标(柔性)作业车间调度问题)
Windows基础命令(目录文件、文本、网络操作)
如何使用LoRA和PEFT微调 Mistral 7B 模型
- 原文地址:https://blog.csdn.net/didi_ya/article/details/126061099
