-
【Java成王之路】EE初阶第十四篇:(网络原理) 4
上节回顾
TCP的核心就是可靠性!!
1.确认应答.保证可靠性的核心机制.针对传输数据以字节为单位进行编号.
2.超时重传:
①.传输的数据丢了
②.ack应答报文丢了
都要重传
超时时间是动态变化的.500ms为单位
3.连接管理(最爱考)
三次握手 状态转换 LISTEN ESTABLISHED
四次挥手 CLOSE_WAIT TIME_WAIT
4.滑动窗口
在可靠性的基础上,提升通信效率
把数据进行批量发送,批量等待ACK
窗口大小.批量发送多少数据不用等待ACK
5.流量控制
根据接收方的处理能力(接收方的缓冲区剩余空间),来解决窗口大小
接上一篇继续
TCP的第六个机制
6.拥塞控制
站在另外一个角度来限制发送方的窗口大小
什么叫另外一个角度?网络传输仅仅是受限于接收方的接收速率吗?
接收方和发送方难道就是一根网线直连的吗
 很明显并不是这么简单
很明显并不是这么简单在这中间会有很多其他的网络设备,我们的网络环境是非常的错综复杂的,发送方传输的数据可能会经过很多硬件设备,七扭八歪的才能到达接收方.
 前面描述的流量控制,指的是针对接收方的处理能力.
前面描述的流量控制,指的是针对接收方的处理能力.假设接收方处理速度很快,但是中间某个节点的处理速度很慢,这个时候发的快还是不行,发的快可能就在中间节点就丢包了,还没到接收方呢.所以说这里面的情况并不能只看接收方,还得看网络中的中间过程.
拥塞控制是站在一个宏观角度来看待问题.
把整个中间的链路都看成了以整体.
只看结果
逐渐尝试的过程.
先使用一个比较小的窗口来传输数据.
看看是否丢包,如果不丢包,说明网络比较通畅.
如果丢包,说明网络发生拥堵.
当网络通畅的时候,就逐渐加大发送速率.
当网络出现丢包的时候,就立即降低发送速率.
通过这样的方式,就可以逐渐实验出一个比较合适的窗口大小.
真实的发送窗口的大小 = min(流量控制的窗口,拥塞控制的窗口)
慢启动:刚开始启动的时候,给一个较小的窗口(比较慢的发送速率)
 这个图描述了拥塞控制中,窗口大小的变化规则.
这个图描述了拥塞控制中,窗口大小的变化规则.此时通过指数增长,就能在很少的轮次中就把窗口大小给顶上去.
如果达到阈值,就从指数增长变成线性增长.
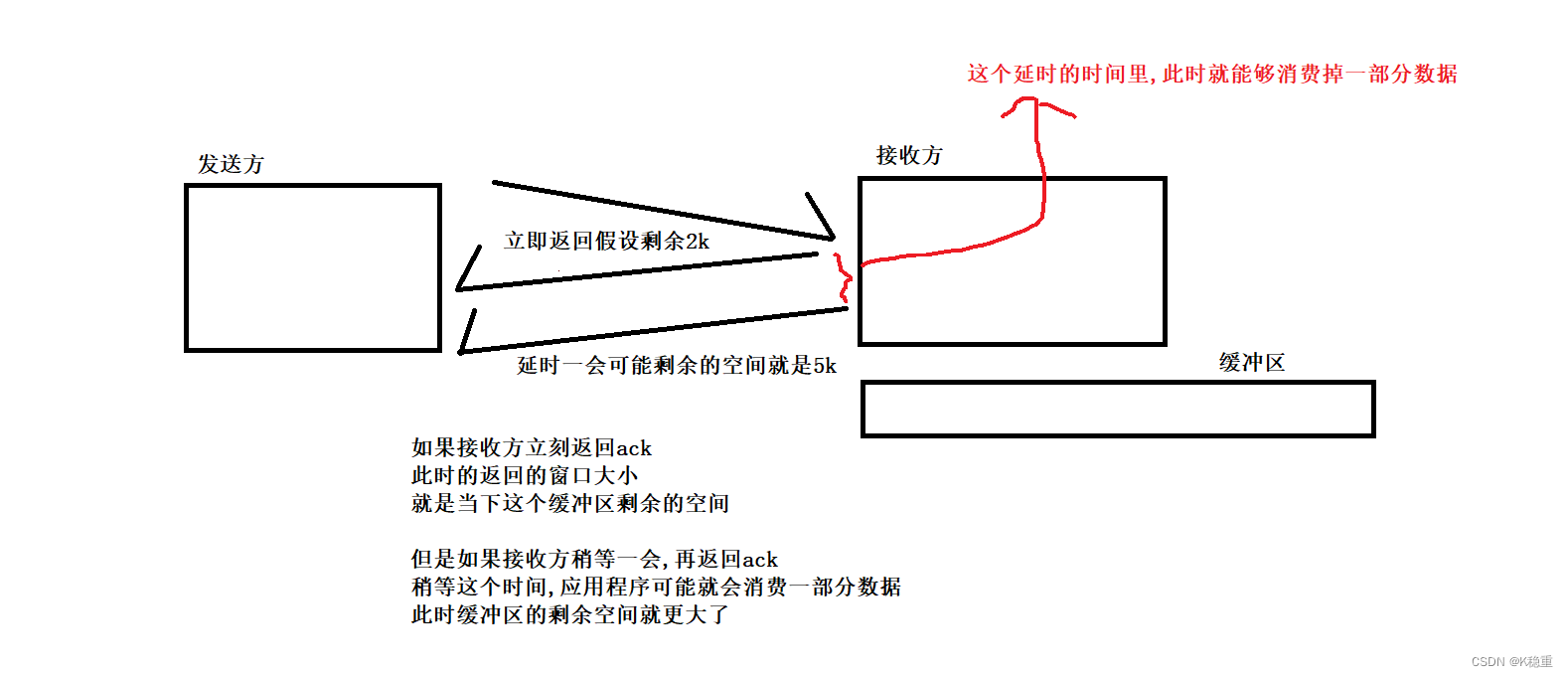
7.延时应答
提高效率(从窗口大小入手)
核心就是让窗口大小,在保证可靠的基础之上,能尽量再大一点.
关键在于:
流量控制来说,窗口大小就是接收缓冲区的剩余空间大小.
8.捎带应答.
延时应答的基础之上来完成的
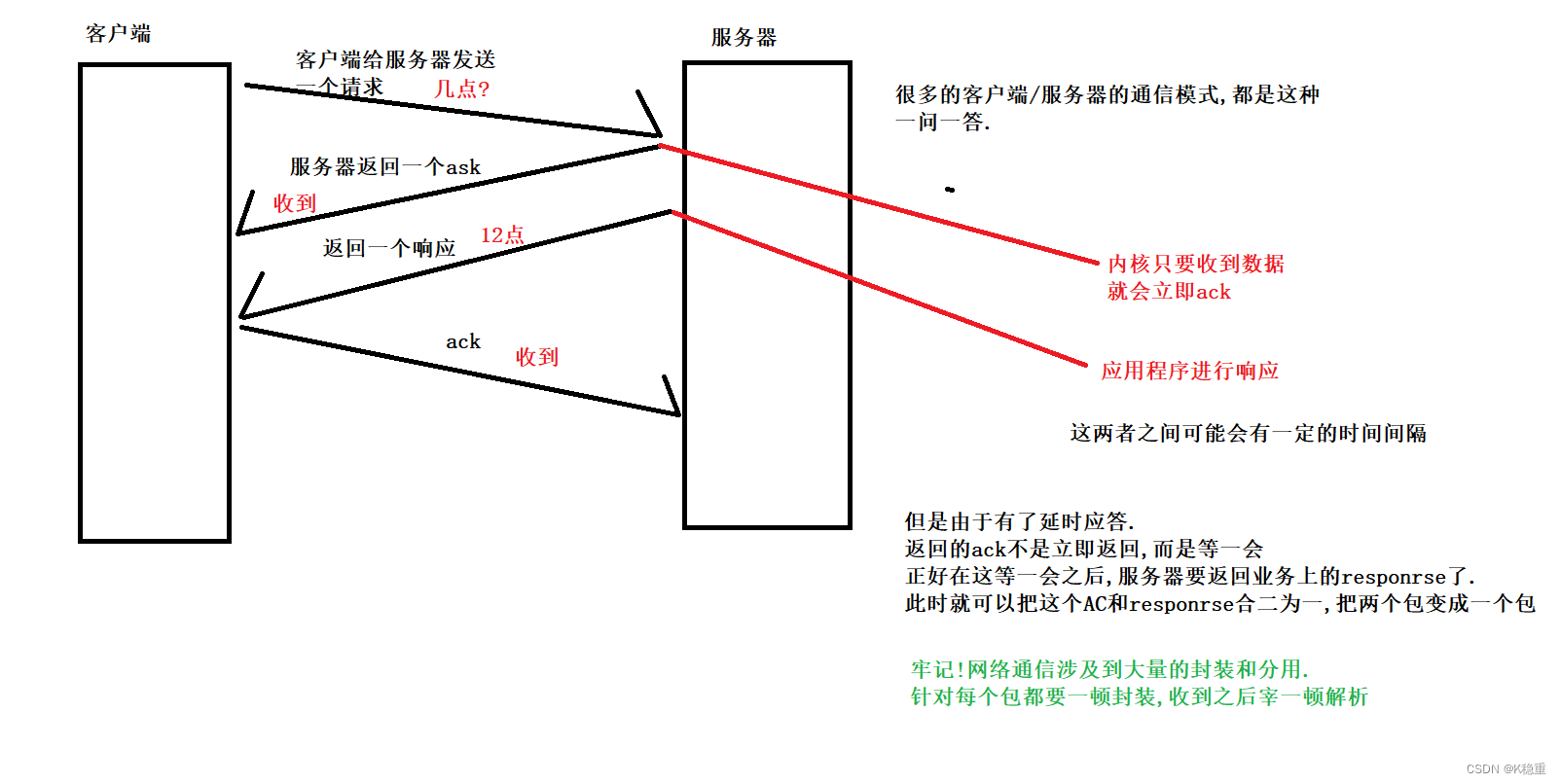 捎带应答本身是一个"概率性的机制"
捎带应答本身是一个"概率性的机制"当前ACK延时的时间正好要比接下来发业务数据的时间要更长一些.
例如:
服务器从收到请求到返回响应,这个过程消耗时间50ms
但是延时应答假设最多等20ms,这个情况就无法触发延时应答了.
但是延时应答如果假设是最多等60ms,到第50ms的时候,此时出发了响应,ACK既可以和这个响应一起过去了,也就触发了延时应答.
9.面向字节流
在这种面向字节流的情况下,需要注意一个重要的问题:粘包问题(粘包指的是应用层的数据报).
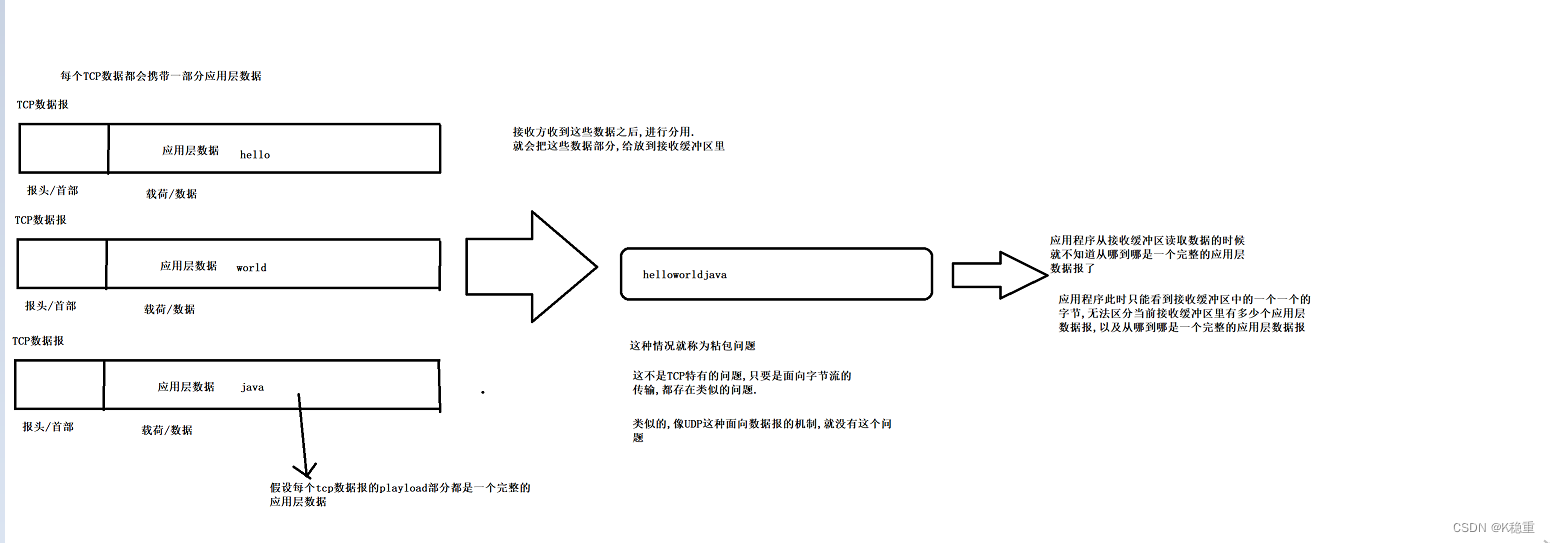


这种情况就被称为粘包问题.
这不是TCP特有的问题,只要是面向字节流传输,都存在类似的问题.
类似的,像UDP这种面向数据报的机制,就没有这个问题
我们再来画一下:



如何解决粘包问题?
通过设计一个合理的应用层协议来解决.
1.给应用层数据设定"结束符"/"分隔符".
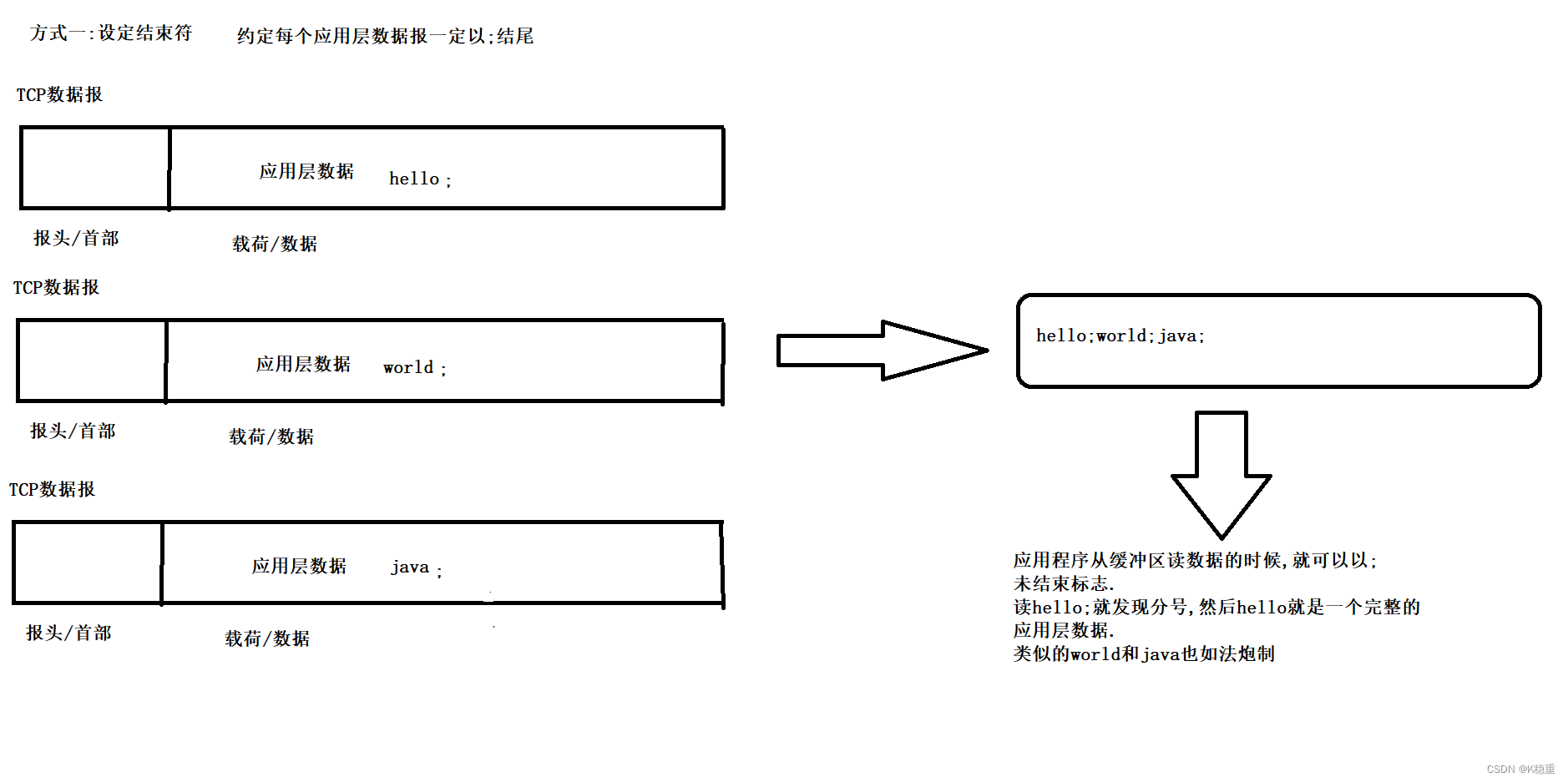
2.给应用层数据设定"长度".
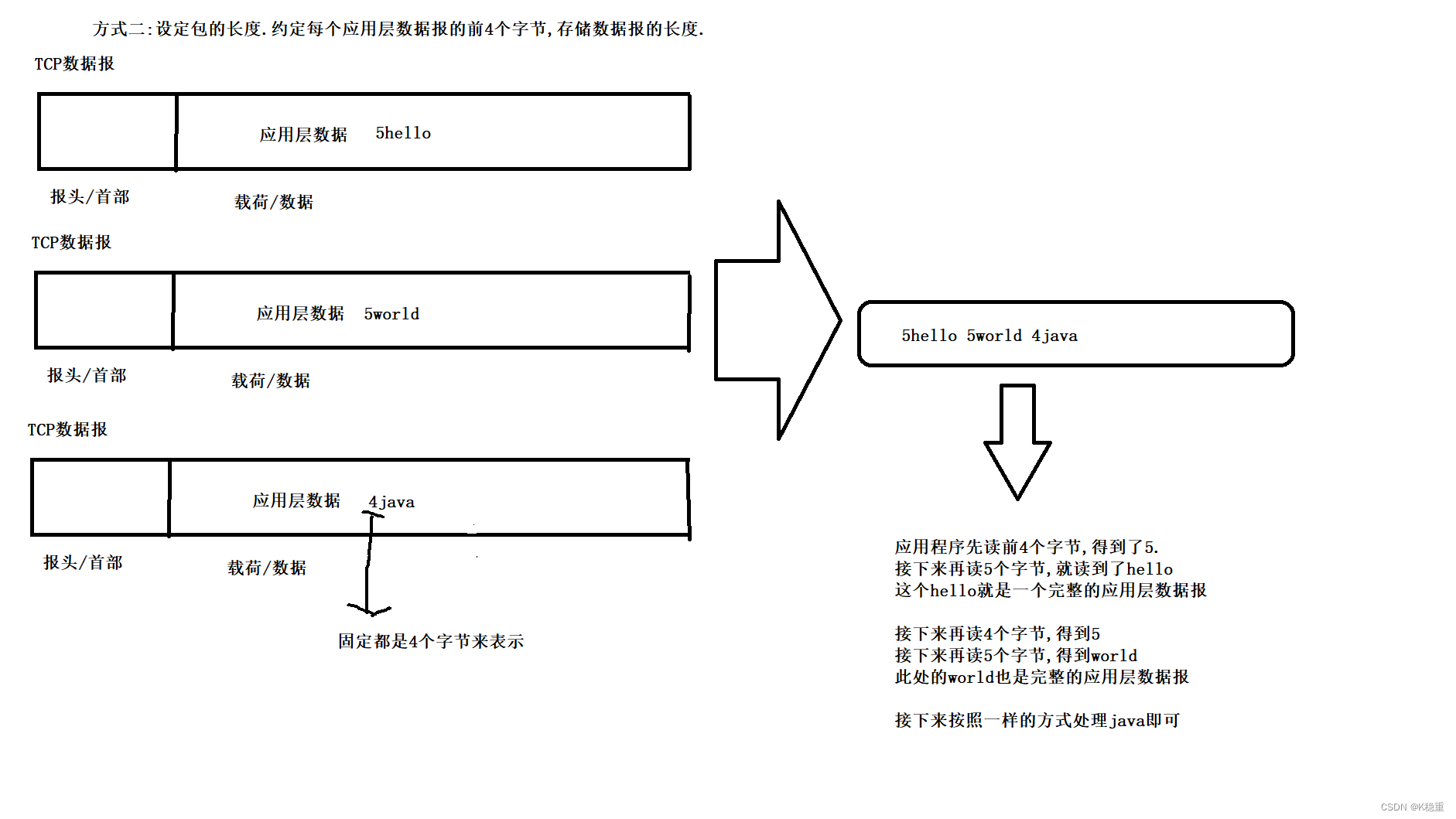
核心就要明确应用层数据中,包和包之间的边界.
10.TCP中的一些异常情况.
常见的异常情况:
1.进程终止
不管进程是咋终止的,本质上都会释放对应的PCB,也会释放对应的文件描述符,一样会触发四次挥手.进程终止,不代表连接就终止.进程终止其实就相当于调用了socket.close()而已.
2.机器重启
这个事情重启的时候,其实也是杀进程.仍然是四次挥手.
3.机器掉电/网线断开
这个是突发情况,机器来不及进行任何动作.
分两种情况讨论:
1.掉电的是接收方,此时另外一遍还在发送数据,此时显然发送方不会再有ack
于是就会超时重传.
重传几次之后,就会尝试重置连接.复位报文段

接收方一直没有反应
再然后发东方就会放弃这个连接
把连接对应的资源就回收了
2,掉电的是发送方,此时另外的一方再尝试接收数据,此时接收不到任何数据.
接收方如何知道,发送方是挂了?还是说发送方暂时还没有发呢?
此时接收方采取的策略,就是"心跳包"机制.(也称作"保活")
每隔一段时间,向对方发送一个PING包,期待对方返回一个PONG包.
如果PING包发过去,过了很久还有PONG,并且重试几次也不行,此时就认为对方挂了.
1
心跳包,这是一个应用非常广泛的机制.不仅仅是在TCP.
总结
TCP机制:
1.确认应答(保证可靠性)
2.超时重传(保证可靠性)
3.连接管理(可靠性)
4.滑动窗口(效率)
5.流量控制(可靠性)
6.拥塞控制(可靠性)
7.延时应答(效率)
8.捎带应答(效率)
9.面向字节流(粘包问题)(其他)
10.异常情况(心跳机制) (其他)
一个非常经典的面试题:
如何基于UDP协议实现可靠传输?
让自己写代码在应用层实现.
说白了这道题看似是在问UDP,其实是在考TCP.
1.实现确认应答机制,把每个数据接收到之后,都要反馈一个ACK(这就不是内核返回了,而是应用程序自己定义一个ack包,发送回去)
2.实现序号/确认序号,以及实现去重
3.超时重传
4.实现连接管理
5.要想提高效率,实现滑动窗口
6.为看限制滑动窗口,实现流量控制/拥塞控制
7.实现延时应答,捎带应答,心跳机制.
注意:这个题是在问你实现的思路,不是让你真写代码!!!
第二个:
啥样的场景中是个使用TCP,啥样的场景中适合使用UDP?
1.如果需要可靠性.肯定首选TCP
2.如果传输的单个数据报比较长超过64k还是使用TCP
3.如果特别注重效率,优先考虑UDP.(典型的场景:机房内部的主机之间通信,网络环境简单,带宽充裕,丢包的概率本身就不大.机房内部主机之间的通信,往往传输数据量更大,更需要速度.尤其是在当下的"微服务"这样的环境中,其实特别需要)但不是一定的.也有使用TCP的
4.如果是用广播,优先考虑UDP(什么是广播,就是一份数据同时发给多个主机,UDP自身就支持广播的,但是TCP自身不支持,就只能在应用层程序中通过多个连接,轮询的方式给每个主机发送数据(伪广播))
像LOL,王者农药这样的moba类游戏,传输的时候,使用是TCP还是UDP??
很可能,既不是TCP,也不是UDP!!
传输层协议,并不仅仅是TCP和UDP;两种!!
除了TCP或者UDP之外,还有很多其他的传输层协议.
有的协议就尽可能的荐股到可靠性和效率.(兼顾可靠性和效率,付出的代价可能就是更多的机器资源)
-
相关阅读:
解决spawn-fcgi:child exited with: 127/126/1报错
2022年03月 Scratch(一级)真题解析#中国电子学会#全国青少年软件编程等级考试
【深度学习】Transformer梳理
Java线程的学习
性能测试知识科普(一)
听说90%的人都没搞定手撕协程池这道面试题!
Chrome清除Cookie未生效
【基础】Linux 进阶
理论篇2:深度学习之----优化器(1)
【深度学习】YOLO-Pose 人体关键点估计 人体姿态估计
- 原文地址:https://blog.csdn.net/m0_64397675/article/details/126051608