-
Pandas 基础入门(一)
一、Pandas是什么
Pandas 是一个开源的第三方 Python 库,从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。
Pandas 已经成为 Python 数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。
Pandas 这个名字来源于面板数据(Panel Data)与数据分析(data analysis)这两个名词的组合。Pandas 最初被应用于金融量化交易领域,现在它的应用领域更加广泛,涵盖了农业、工业、交通等许多行业
二、Pandas主要特点
- 提供了一个简单、高效、带有默认标签(也可以自定义标签)的 DataFrame 对象。
- 能够快速得从不同格式的文件中加载数据(比如 Excel、CSV 、SQL文件),然后将其转换为可处理的对象;
- 能够按数据的行、列标签进行分组,并对分组后的对象执行聚合和转换操作;
- 能够很方便地实现数据归一化操作和缺失值处理;
- 能够很方便地对 DataFrame 的数据列进行增加、修改或者删除的操作;
- 能够处理不同格式的数据集,比如矩阵数据、异构数据表、时间序列等;
- 提供了多种处理数据集的方式,比如构建子集、切片、过滤、分组以及重新排序等。
三、Pandas主要优势
- Pandas 的 DataFrame 和 Series 构建了适用于数据分析的存储结构;
- Pandas 简洁的 API 能够让你专注于代码的核心层面; Pandas 实现了与其他库的集成,比如 Scipy、scikit-learn 和 Matplotlib;
- Pandas 官方网站(点击访问)提供了完善资料支持,及其良好的社区环境。
四、Pandas内置数据结构
Pandas 为解决构建和处理二维、多维数组是一项繁琐的任务。 在 ndarray 数组(NumPy 中的数组)的基础上构建出了
两种不同的数据结构:
- Series(一维数据结构)
- DataFrame(二维数据结构)

五、Pandas安装
pip install pandas
import pandas as pd
六、Series结构
6.1 Series结构概念
Series 结构,也称 Series 序列,是 Pandas 常用的数据结构之一,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。 Series 可以保存任何数据类型,比如整数、字符串、浮点数、Python 对象等,它的标签默认为整数,从 0 开始依次递增。
 6.2 Series对象
6.2 Series对象使用 Series() 函数来创建 Series 对象,通过这个对象可以调用相应的方法和属性
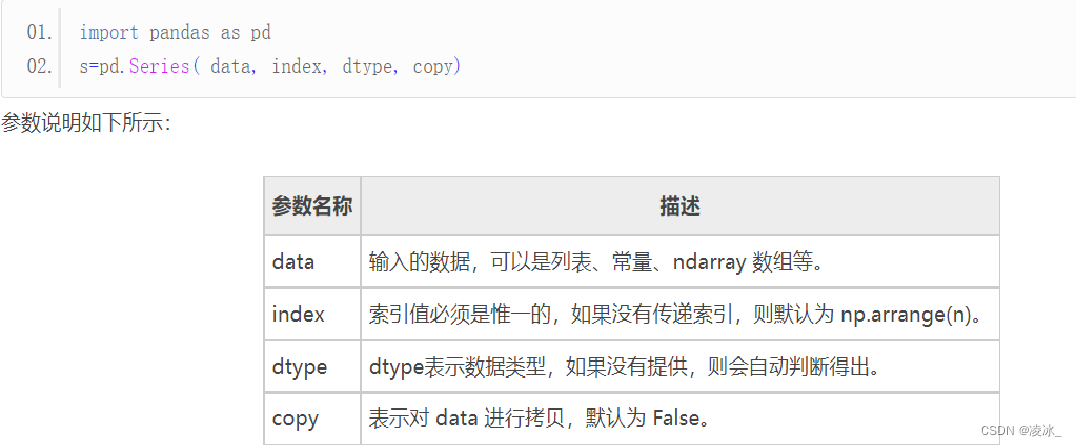 6.3 Series创建对象
6.3 Series创建对象1、创建一个空Series对象
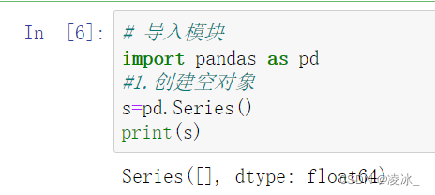
2、字典创建Series对象
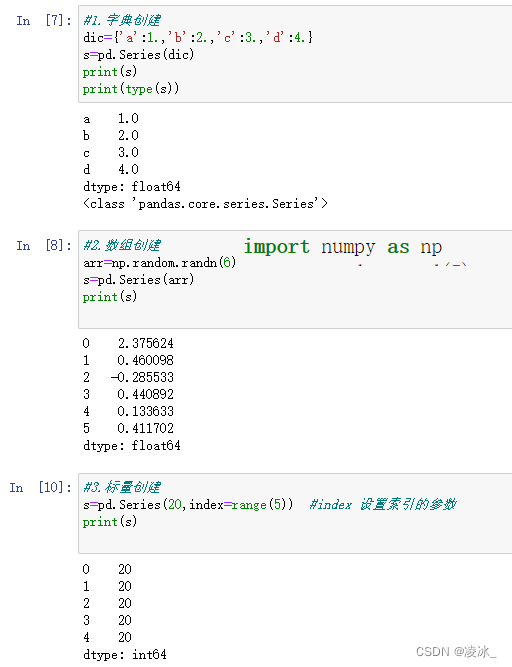
3、数组创建Series对象
4、标量创建Series对象
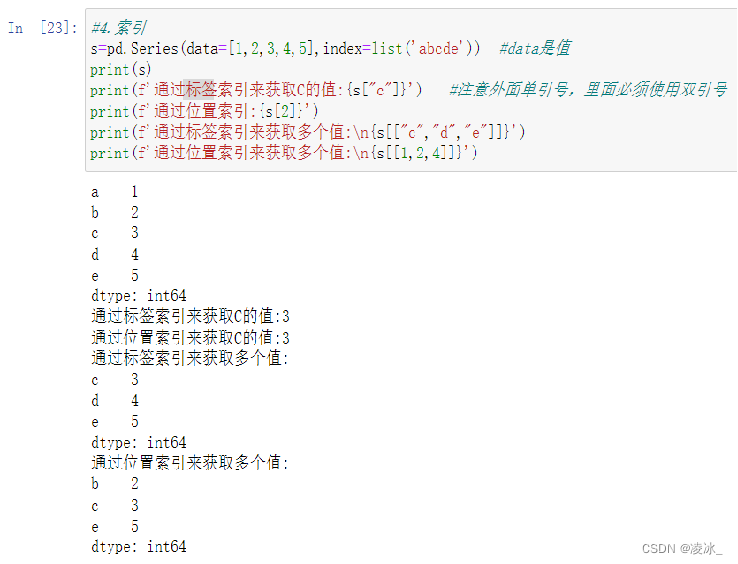
6.4 Series访问数据
分为两种方式: (1) 位置索引访问 (2) 标签索引访问

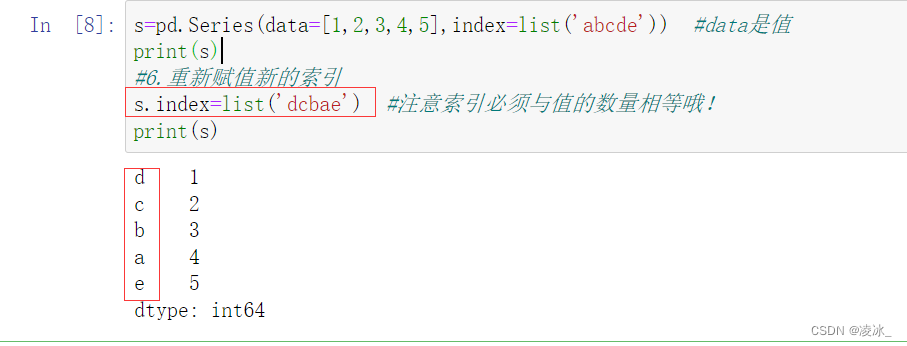
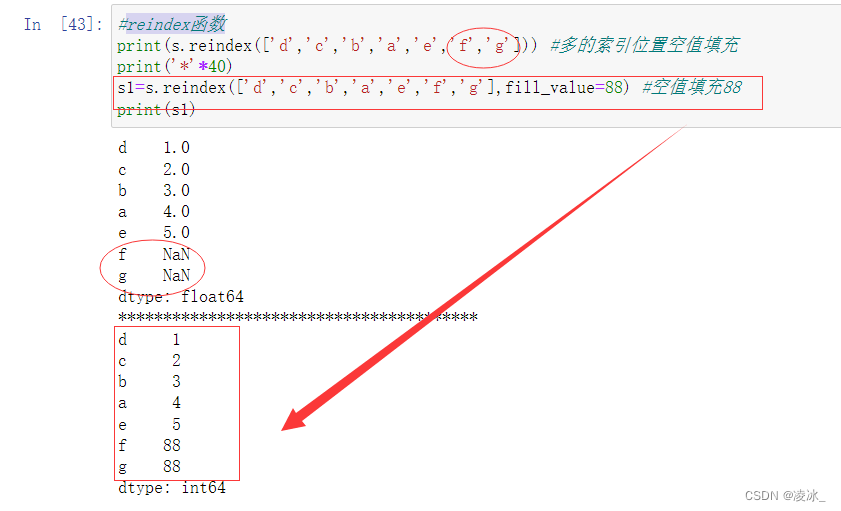
6.5 Pandas的reindex函数
返回->数据符合新的索引来构造一个新的对象
语法:DataFrame.reindex(index=None, columns=None, **kwargs)
reindex 函数的参数说明:
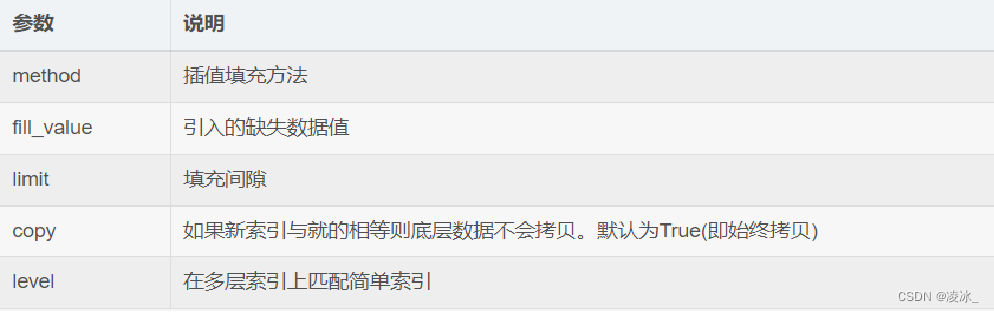
6.6 Series常用属性
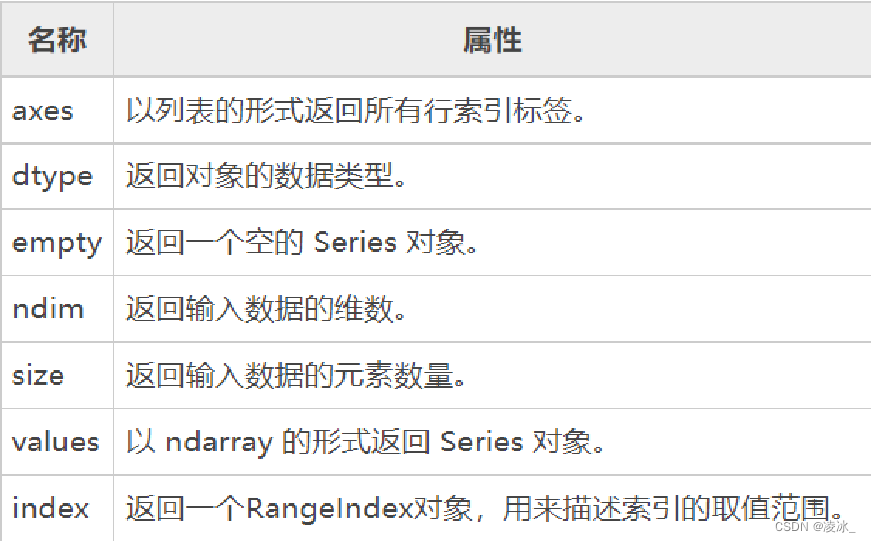
6.7 Series常用方法
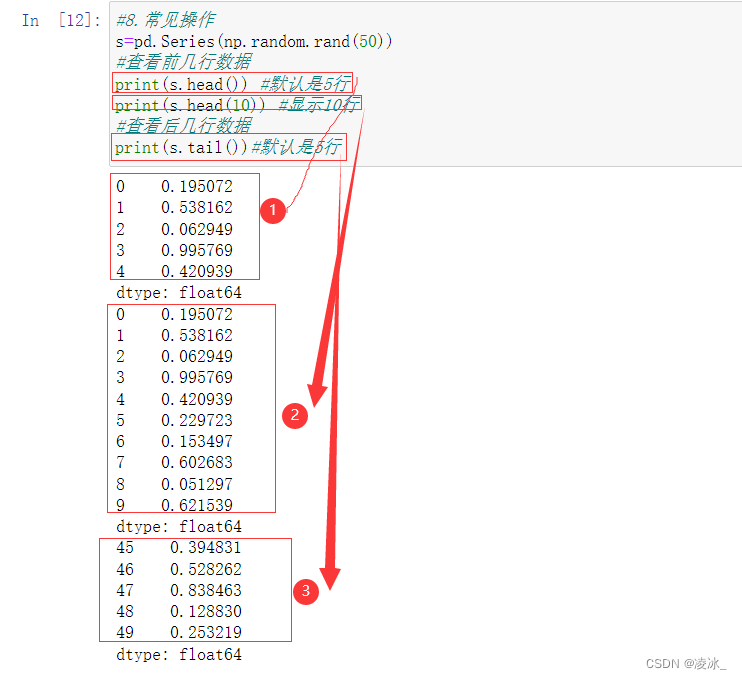
1、head()、tail()查看数据
- head() 返回前 n 行数据,默认显示前 5 行数据
- tail() 返回后 n 行数据,默认显示后 5 行数据
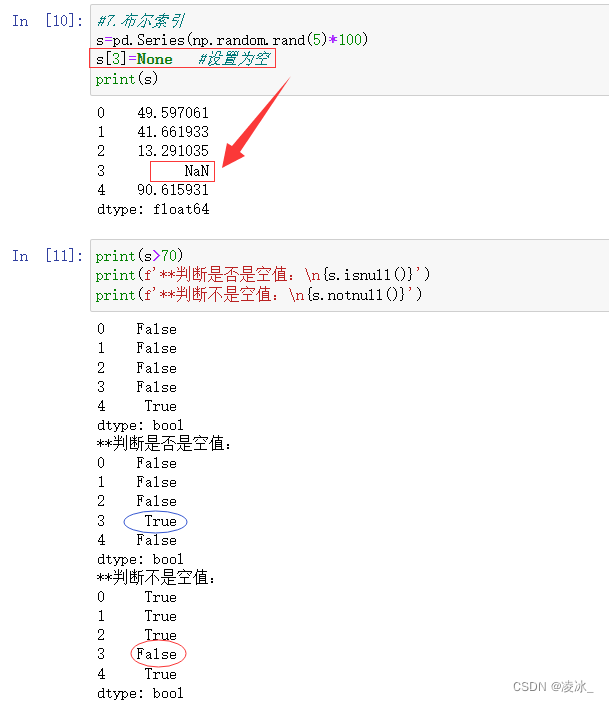
2、isnull()、nonull()检测缺失值 所谓缺失值,顾名思义就是值不存在、丢失、缺少。
- isnull(): 如果为值不存在或者缺失,则返回 True。
- notnull():如果值不存在或者缺失,则返回 False。
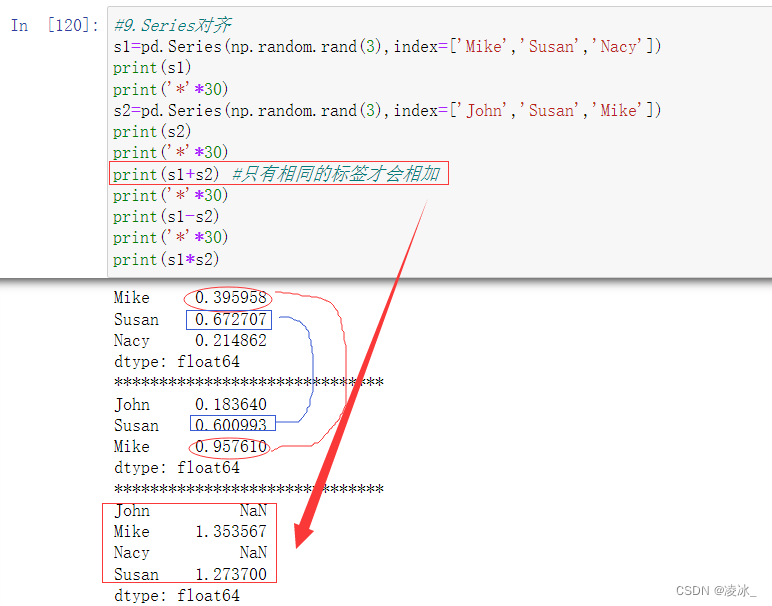
6.8 Series算术运算
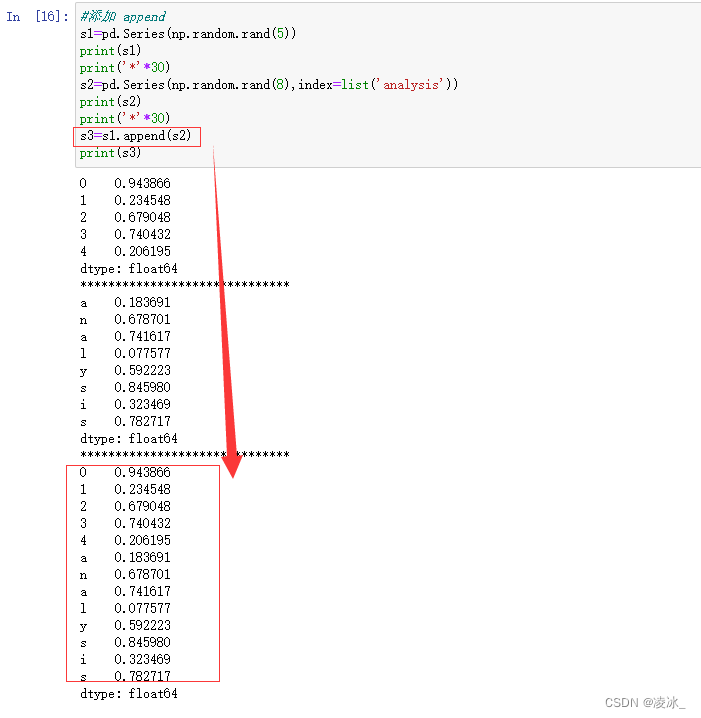
6.9 Series添加append
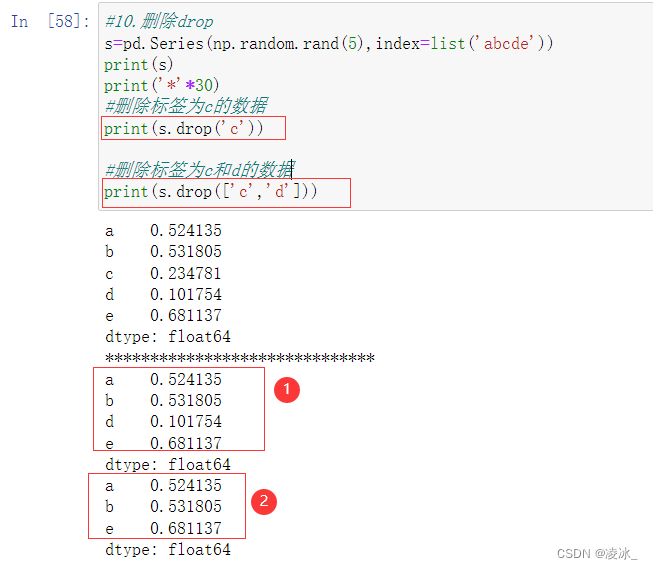
6.10 Series删除drop
删除数据集中多余的数据
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')

七、DataFrame结构
7.1 dataFrame概念
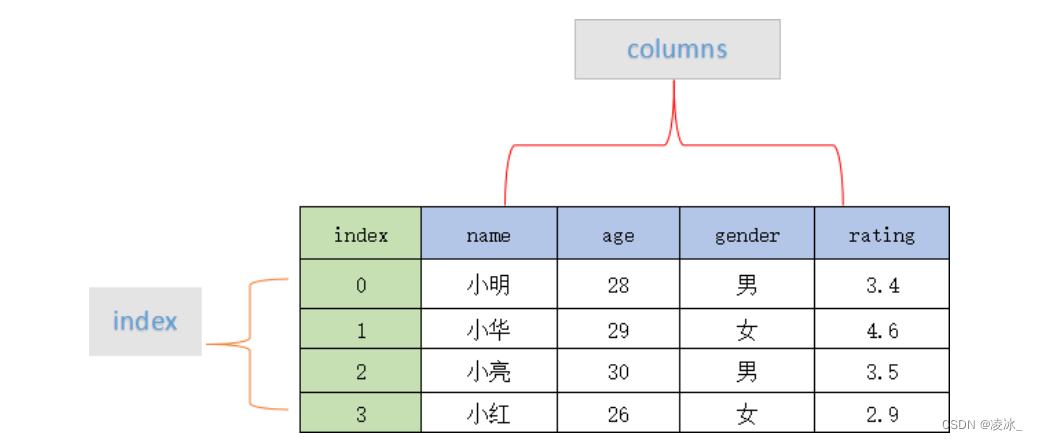
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
7.2 DataFrame对象
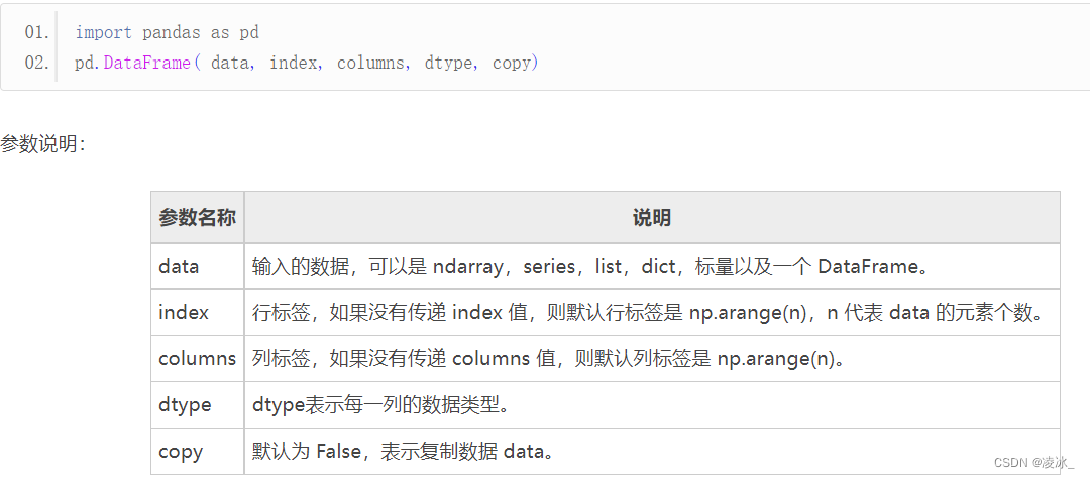
创建 DataFrame 对象的语法格式
7.3 DataFrame创建对象
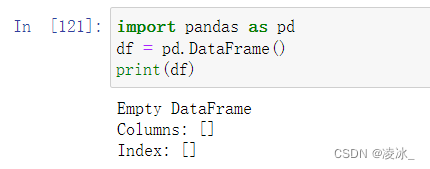
1、创建空对象
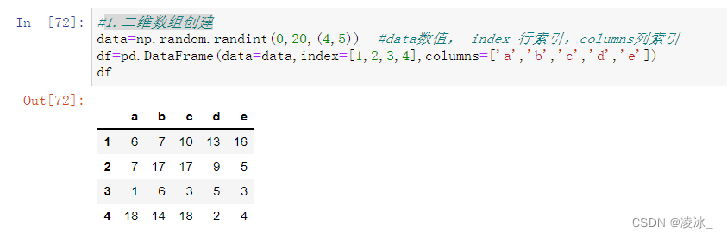
2、二维数组创建
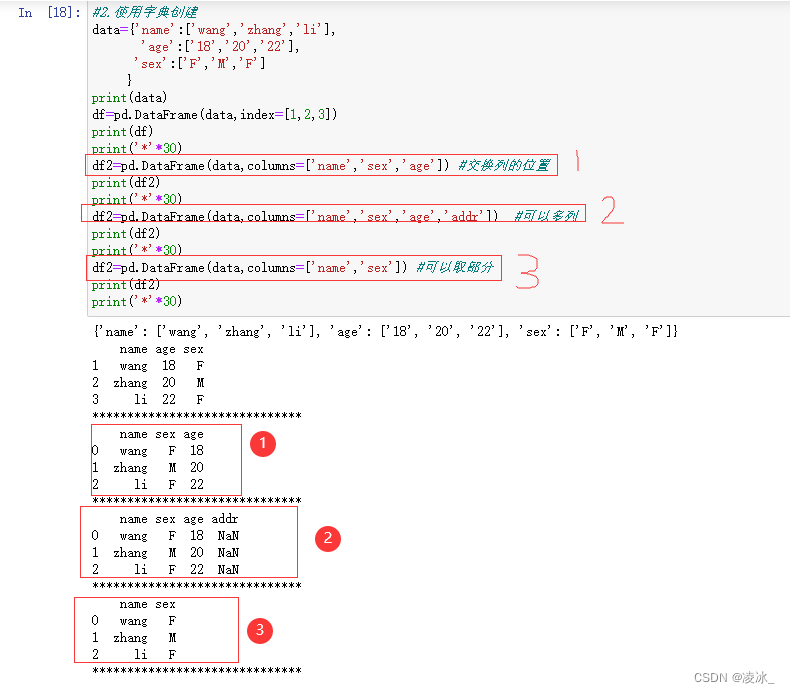
3、字典创建
4、from_dict()创建

5、列表嵌套字典创建

7.4 DataFrame常见属性&方法


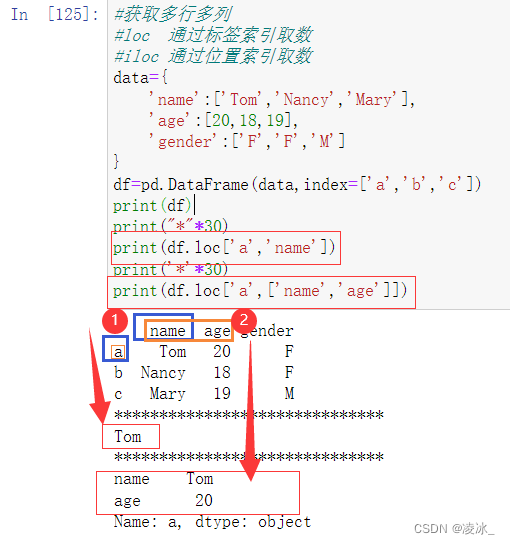
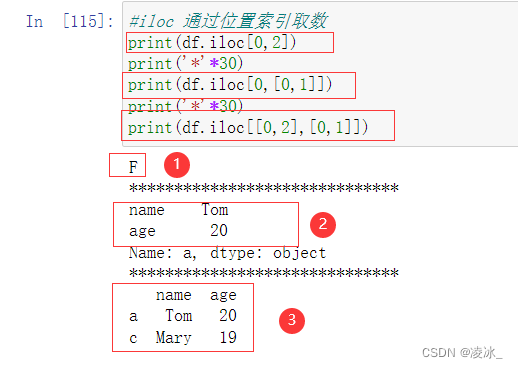
7.5 Pandas loc/iloc用法

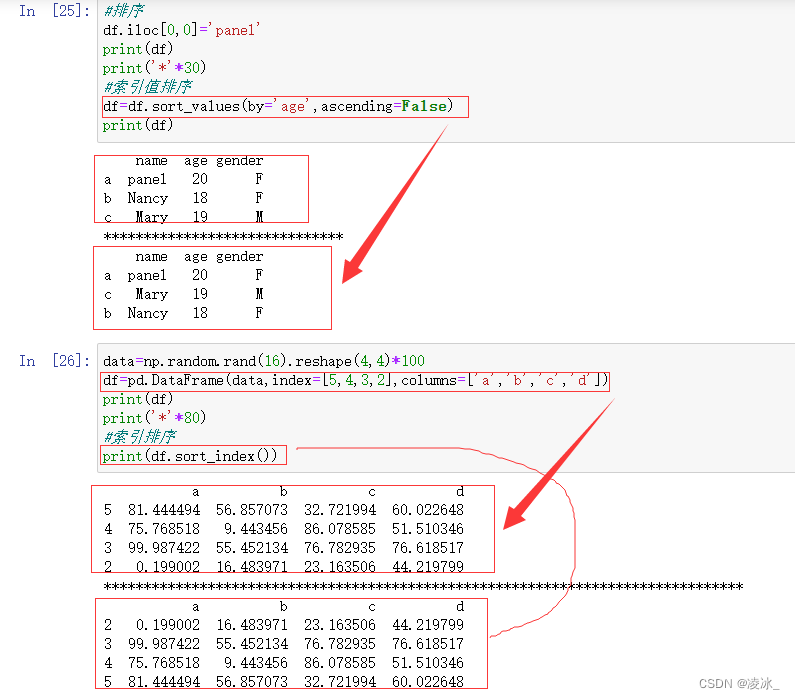
7.6 Pandas sorting排序
两种排序方法:
1、按索引排序 sort_index(axis= , ascending= , inplace=)
2、按值排序 sort_values(by= , axis= , ascending= , inplace=)

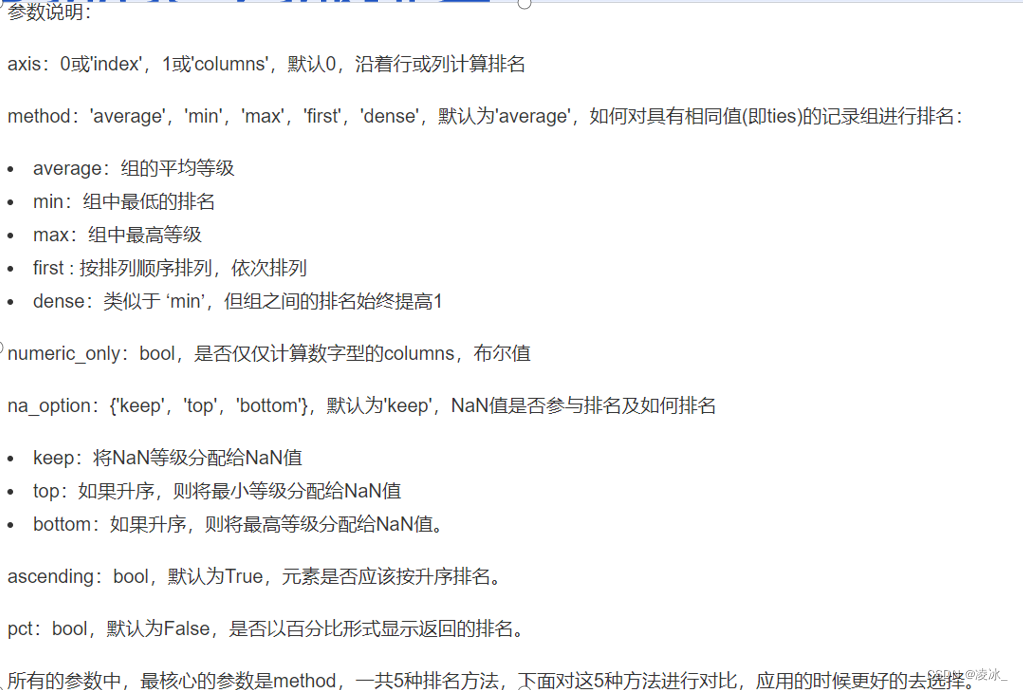
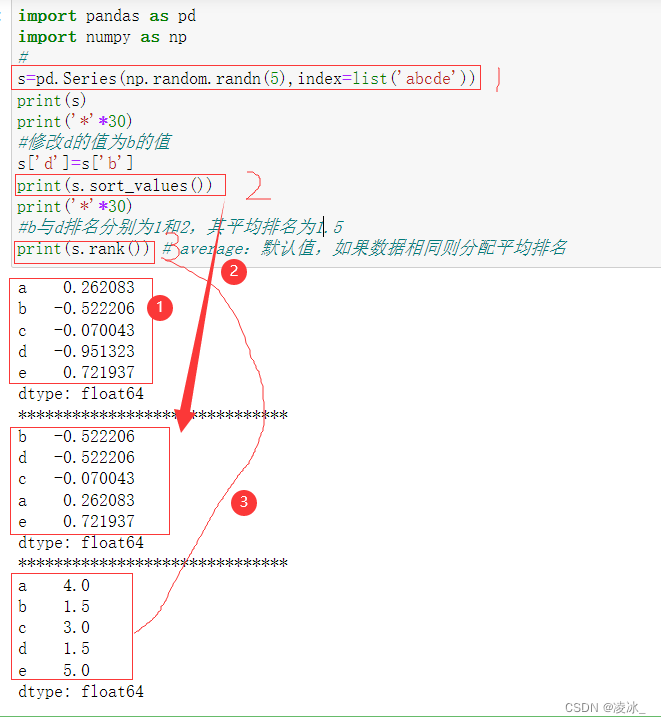
7.7 Pandas rank排名
rank函数语法:
DataFrame.rank(axis=0,method='average',numeric_only=None, na_option='keep',ascending=True,pct=False)

-
相关阅读:
python学习--特殊方法和属性
windows下应急响应工具列表
VS2019 错误 MSB8066 自定义生成已退出,代码为 3
9面阿里Java岗,最终定级P6拿P7工资,分享学习经验
微信小程序是否可以使用自建SSL证书?
Dajngo01_Django框架基础与环境搭建
通过平台生态系统加速业务创新
Windows11+Ubuntu 3系统如何安全地删掉最后一个Ubuntu系统?
Mysql — 刷题知识点
PX4使用P900数传
- 原文地址:https://blog.csdn.net/hlx20080808/article/details/126049567