-
R语言 第一部分
R语言 第一章
1.对象赋值与运行


2.脚本代码

3.帮助文件

4.向量,矩阵和数组
(1)向量

(2)矩阵
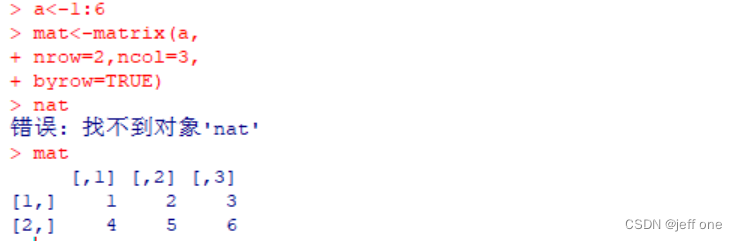

(3).数组
5.数据框
1)创建数据框

2)数据框的合并
mytable<-rbind(table1_1,table1_2)
cbind(mytable,table1_3[2:3]) # 按列合并数据框3)数据框排序

6.因子和列表1)因子

2)列表

7.R语言数据处理1)数据读取和保存
1.读取包含标题的csv格式数据 table1_1<-read.csv(“C:/mydata/chap01/table1_1.csv”)
2. 读取不包含标题的csv格式数据
3. table1_1<-read.csv(“C:/mydata/chap01/table1_1.csv”,header=FALSE)
3.读取R格式数据 load(“C:/mydata/chap01/table1_1.RData”)
4.将tablel_1存为csv格式文件 write.csv(table1_1,file=“C:/mydata/chap01/table1_1.csv”)2)随机数和数据抽样

3)生成频数分布表一频表:
生成满意度的简单频数表。
data1_1<-read.csv(“C:/mydata/chap01/data1_1.csv”) attach(data1_1)
mytable1<-table(满意度);mytable1 prop.table(mytable1)*100二频表:
生成性别和满意度的二维列联表。 data1_1<-read.csv(“C:/mydata/chap01/data1_1.csv”)
attach(data1_1) mytable2<-table(性别,满意度) # 生成性别和满意度的二维列联表 mytable2
addmargins(mytable2) # 为列联表添加边际和
addmargins(prop.table(mytable2)*100) # 将列联表转换成百分比表多维表:
生成三维频数表(列变量为“满意度”)
data1_1<-read.csv(“C:/mydata/chap01/data1_1.csv”)
mytable3<-ftable(data1_1,row.vars=c(“性别”,“网购次数”),col.vars=“满意度”)
mytable3 生成三维频数表(列变量为"性别"和"满意度")
mytable4<-ftable(data1_1,row.vars=c(“网购次数”),col.vars=c(“性别”,“满意度”))
mytable44)生成频数分布表——数值数据——cut 函数
data1_2<-read.csv(“C:/mydata/chap01/data1_2.csv”)
v<-as.vector(data1_2KaTeX parse error: Expected 'EOF', got '#' at position 8: 销售额) #̲ 将销售额转化成向量 d<-t…Freq/sum(ddKaTeX parse error: Expected 'EOF', got '#' at position 14: Freq)*100,2) #̲ 计算频数百分比,结果保留2位…Var1,频数=df F r e q , 频数百分比 = d f Freq,频数百分比=df Freq,频数百分比=dfpercent)
重新命名并组织成频数分布表 mytable #
显示频数分布表5) 生成频数分布表——数值数据——Freq 函数
data1_2<-read.csv(“C:/mydata/chap01/data1_2.csv”) library(DescTools)
加载包DescTools 使用默认分组,含上限值
tab<- Freq(data1_2 销售额 ) t a b 使用 F r e q 函数并生成频数分布表,指定组距 = 20 (不含上限值) t a b 1 < − F r e q ( d a t a 1 2 销售额) tab 使用Freq函数并生成频数分布表,指定组距=20(不含上限值) tab1<-Freq(data1_2 销售额)tab使用Freq函数并生成频数分布表,指定组距=20(不含上限值)tab1<−Freq(data12
销售额, breaks=c(500,520,540,560,580,625,600,620,640,660,680,700,720),right=FALSE)
指定组距=20,不含上限值
tab2<-data.frame(分组=tab1 l e v e l , 频数 = t a b 1 level,频数=tab1 level,频数=tab1freq,频数百分比=tab1 p e r c ∗ 100 , 累积频数 = t a b 1 perc*100,累积频数=tab1 perc∗100,累积频数=tab1cumfreq,累积百分比=tab1$cumperc*100)
重新命名频数表中的变量 print(tab2,digits=3)
用print函数定义输出结果的小数位数 -
相关阅读:
2023年数维杯数学建模C题宫内节育器的生产求解全过程文档及程序
MYSQL(索引篇)
linux 创建全局快捷方式
linux非root用户配置SSH免密登录
Python学习笔记()——文件操作
java抽象工厂&责任链模式&观察者模式
Proteus 新建工程
1. 封装自己的脚手架 2.创建代码模块
上一次梦见小时候
realloc一定要注意的细节,不然很容易崩溃
- 原文地址:https://blog.csdn.net/weixin_57038822/article/details/126014663