-
第二好PyTorch新手课程;论文写作指南;使用µGo语言开发迷你编译器;超高效使用Transformer的扩展库;前沿论文 | ShowMeAI资讯日报

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
工具&框架
🚧 『Vector Hub』数据向量化(嵌入)模型库
https://github.com/RelevanceAI/vectorhub
Vector Hub 是一个将数据向量化的模型库,包括 Text2Vec、Image2Vec、Video2Vec、Face2Vec、Bert2Vec、Inception2Vec、Code2Vec、LegalBert2Vec 等,给从业者提供快速实验、研究和构建新模型和特征向量的简单方法。Vector Hub 由 Relevance AI 维护,后者是一个可快速实验的矢量平台,用于存储、试验和部署向量的灵活开发工具,支持使用无代码工作流程快速入门,能够在一个平台上分析文本、图像、音频、时间序列。

🚧 『DeepSpeed-MII』Transformer 模型低延迟、低成本推理的 DeepSpeed 扩展库
https://github.com/microsoft/DeepSpeed-MII
Model Implementations for Inference (MII) 是 DeepSpeed 拓展库,提供了数千个高度优化的常用深度学习模型,使得强大的 Transformer 模型能够低延迟、低成本推理地访问。MII 目前处于预发布阶段,密集更新中,有需求的小伙伴们关注起来呀~


🚧 『ares』对抗机器学习基准测试库
https://github.com/thu-ml/ares
ares 是清华大学来源的一个对抗性机器学习(adversarial machine learning)的 Python 库,聚焦于专注于对抗性鲁棒性的基准测试。

🚧 『μKG』多源知识图谱嵌入与应用库
https://github.com/nju-websoft/muKG
μKG 是一个开源 Python 库,用于知识图谱上的表征学习。μKG 支持多源知识图谱上的联合表征学习(当然也支持单一知识图谱),支持 PyTorch 与 TF2 深度学习库,能够完成链接预测 link prediction、实体对齐 entity alignment、实体类型 entity typing 与多源链接预测 multi-source link prediction 等多种嵌入任务,并能支持多进程和多GPU计算等多种并行计算模式。

🚧 『tere』cd + ls的替换快捷命令行工具
https://github.com/mgunyho/tere
tere 是一个终端文件资源管理,可以使用 cd 和 ls 快速浏览终端中的文件夹。tere 最核心的功能是使用 TUI 有效地导航到一个文件夹,然后在退出时打印出该文件夹的路径。


项目&代码
📌『µGo语言实现』从头开发一个迷你Go语言编译器
https://github.com/wa-lang/ugo-compiler-book
µGo 是 Go 语言的子集(不含标准库部分), 可以直接作为Go代码编译执行。本书尝试以实现 µGo 编译器为线索,以边学习边完善的自举方式实现一个玩具语言。作者在蚂蚁集团从事云原生、蚂蚁链DSL语言设计和研发工作,著有多本图书。

博文&分享
👍 『Learn PyTorch for Deep Learning』深度学习入门课程(附资料)
https://github.com/mrdbourke/pytorch-deep-learning
这门课『Learn PyTorch for Deep Learning: Zero to Mastery book』(面向深度学习的PyTorch:从零到精通)是学习 PyTorch 第二好的去处(第一当然是 PyTorch 文档)。课程面向初学者,以代码优先的方式讲解 PyTorch 和机器学习概念,并引领探索更多『高级领域』: PyTorch 神经网络分类、PyTorch 工作流程、计算机视觉、自定义数据集、实验跟踪、模型部署、迁移学习等。
课程学习将 『FoodVision』大项目拆分为三个里程碑小项目,逐步学习使用神经网络和计算机视觉模型进行食物图象分类,并构建学习者自己的实战项目作品集。课程资料全部开源哦!


👍 『高效论文写作』资料集
https://github.com/OpenMindClub/awesome-scholarly-productivity
这是一个关于论文写作的资源合辑,主要是书籍。作者按照主题列写了推荐的书籍资源,包括英语论文写作、通用英语写作、科技论文制图、数学公式写作与论文排版、文献分析工具、论文发表技巧等。有需要的小伙伴可以按需选择~

数据&资源
🔥 『Awesome Pruning at Initialization』初始化时神经网络剪枝相关资料
https://github.com/MingSun-Tse/Awesome-Pruning-at-Initialization
这个 repo 旨在对最近几年关于『Neural Network Pruning at Initialization』(初始化时神经网络剪枝,PaI)的论文进行全面梳理。

研究&论文

可以点击 这里 回复关键字日报,免费获取整理好的论文合辑。
科研进展
- 2022.07.22 『计算机视觉』 Multiface: A Dataset for Neural Face Rendering
- 2022.07.21 『计算机视觉』 In Defense of Online Models for Video Instance Segmentation
- 2022.07.21 『计算机视觉』 Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild
- 2022.07.22 『计算机视觉』 Generative Multiplane Images: Making a 2D GAN 3D-Aware
⚡ 论文:Multiface: A Dataset for Neural Face Rendering
论文时间:22 Jul 2022
所属领域:计算机视觉
对应任务:Novel View Synthesis,新视角的合成
论文地址:https://arxiv.org/abs/2207.11243
代码实现:https://github.com/facebookresearch/multiface
论文作者:Cheng-hsin Wuu, Ningyuan Zheng, Scott Ardisson, Rohan Bali, Danielle Belko, Eric Brockmeyer, Lucas Evans, Timothy Godisart, Hyowon Ha, Alexander Hypes, Taylor Koska, Steven Krenn, Stephen Lombardi, Xiaomin Luo, Kevyn McPhail, Laura Millerschoen, Michal Perdoch, Mark Pitts, Alexander Richard, Jason Saragih, Junko Saragih, Takaaki Shiratori, Tomas Simon, Matt Stewart, Autumn Trimble, Xinshuo Weng, David Whitewolf, Chenglei Wu, Shoou-I Yu, Yaser Sheikh
论文简介:Along with the release of the dataset, we conduct ablation studies on the influence of different model architectures toward the model’s interpolation capacity of novel viewpoint and expressions./随着数据集的发布,我们对不同的模型架构对模型的新视角和表情的插值能力的影响进行了消融研究。
论文摘要:近年来,人脸的虚拟形象已经取得了长足的进步,但由于缺乏公开可用的高质量数据集,包括密集的多视角相机捕捉和捕捉对象的丰富面部表情,这一领域的研究受到限制。在这项工作中,我们提出了Multiface,一个新的多视角、高分辨率的人脸数据集,它是从Reality Labs Research的13个身份中收集的,用于神经人脸渲染。我们介绍了Mugsy,这是一个大规模的多摄像头装置,用于捕捉高分辨率的面部表演的同步视频。Multiface的目标是弥补学术界在获得高质量数据方面的差距,并实现VR远程呈现的研究。随着数据集的发布,我们对不同的模型架构对模型的插值能力的影响进行了消融研究。以条件约束VAE模型作为我们的基线,我们发现增加空间偏差、纹理翘曲场和残差连接可以提高新观点合成的性能。我们的代码和数据见:https://github.com/facebookresearch/multiface。


⚡ 论文:In Defense of Online Models for Video Instance Segmentation
论文时间:21 Jul 2022
所属领域:计算机视觉
对应任务:Contrastive Learning,Instance Segmentation,Semantic Segmentation,Video Instance Segmentation,Video Object Segmentation,Video Semantic Segmentation,对比学习,实例分割,语义分割,视频实例分割,视频对象分割,视频语义分割
论文地址:https://arxiv.org/abs/2207.10661
代码实现:https://github.com/wjf5203/vnext
论文作者:Junfeng Wu, Qihao Liu, Yi Jiang, Song Bai, Alan Yuille, Xiang Bai
论文简介:In recent years, video instance segmentation (VIS) has been largely advanced by offline models, while online models gradually attracted less attention possibly due to their inferior performance./近年来,视频实例分割(VIS)在很大程度上是由离线模型推进的,而在线模型可能由于其性能较差而逐渐吸引了较少的关注。
论文摘要:近年来,视频实例分割(VIS)在很大程度上是由离线模型推进的,而在线模型可能由于其性能较差而逐渐吸引了较少的关注。然而,在线模型在处理长视频序列和正在进行的视频方面有其固有的优势,而离线模型由于计算资源的限制而失败。因此,如果在线模型能够达到与离线模型相当甚至更好的性能,将是非常可取的。通过剖析目前的在线模型和离线模型,我们证明了性能差距的主要原因是特征空间中不同实例之间相似的外观所导致的帧之间容易出错的关联。观察到这一点,我们提出了一个基于对比学习的在线框架,该框架能够学习更多用于关联的鉴别性实例嵌入,并充分利用历史信息来实现稳定性。尽管我们的方法很简单,但在三个基准上,我们的方法优于所有在线和离线方法。具体来说,我们在YouTube-VIS 2019上实现了49.5个AP,比之前的在线和离线艺术分别大幅提高了13.2个AP和2.1个AP。此外,我们在OVIS上取得了30.2AP的成绩,这是一个更具挑战性的数据集,具有明显的拥挤和闭塞现象,超过了现有技术的14.8AP。我们提出的方法在第四届大规模视频物体分割挑战赛(CVPR2022)的视频实例分割赛中获得第一名。我们希望我们的方法的简单性和有效性,以及我们对当前方法的洞察力,能够为VIS模型的探索带来启示。





⚡ 论文:Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild
论文时间:21 Jul 2022
所属领域:计算机视觉
对应任务:3D Object Detection,3D Object Recognition,object-detection,Object Detection,Object Recognition,三维物体检测,三维物体识别,物体探测,物体检测,物体识别
论文地址:https://arxiv.org/abs/2207.10660
代码实现:https://github.com/facebookresearch/omni3d
论文作者:Garrick Brazil, Julian Straub, Nikhila Ravi, Justin Johnson, Georgia Gkioxari
论文简介:Omni3D re-purposes and combines existing datasets resulting in 234k images annotated with more than 3 million instances and 97 categories. 3D detection at such scale is challenging due to variations in camera intrinsics and the rich diversity of scene and object types./Omni3D重新利用并结合了现有的数据集,产生了23.4万张带有300多万个实例和97个类别注释的图像。由于相机本征的变化以及场景和物体类型的丰富多样性,这种规模的3D检测具有挑战性。
论文摘要:从单一图像中识别三维场景和物体是计算机视觉的一个长期目标,在机器人和AR/VR中得到应用。对于二维识别,大型数据集和可扩展的解决方案已经导致了前所未有的进步。在三维方面,现有的基准规模较小,而且方法专门用于少数物体类别和特定领域,例如城市驾驶场景。在二维识别成功的激励下,我们通过引入一个名为Omni3D的大型基准,重新审视了三维物体检测的任务。Omni3D重新利用并结合了现有的数据集,产生了23.4万张图像,注释了超过300万个实例和97个类别。由于相机内在因素的变化以及场景和物体类型的丰富多样性,如此规模的3D检测具有挑战性。我们提出了一个模型,称为Cube R-CNN,旨在通过一个统一的方法来概括不同相机和场景类型。我们表明,Cube R-CNN在较大的Omni3D和现有基准上的表现优于先前的工作。最后,我们证明Omni3D是一个强大的三维物体识别数据集,表明它提高了单数据集的性能,并能通过预训练加速在新的小数据集上的学习。




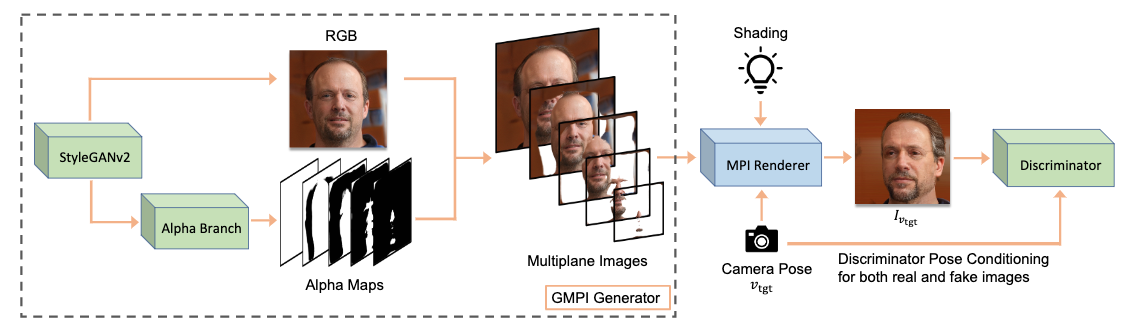
⚡ 论文:Generative Multiplane Images: Making a 2D GAN 3D-Aware
论文时间:21 Jul 2022
所属领域:计算机视觉
对应任务:图像生成
论文地址:https://arxiv.org/abs/2207.10642
代码实现:https://github.com/apple/ml-gmpi
论文作者:Xiaoming Zhao, Fangchang Ma, David Güera, Zhile Ren, Alexander G. Schwing, Alex Colburn
论文简介:What is really needed to make an existing 2D GAN 3D-aware?/让现有的2D GAN实现3D感知的真正需要是什么?
论文摘要:要使现有的2D GAN具有3D意识,到底需要什么?为了回答这个问题,我们尽可能少地修改一个经典的GAN,即StyleGANv2。我们发现,只有两个修改是绝对必要的。1)一个多平面图像风格生成器分支,它产生一组以其深度为条件的阿尔法图;2)一个以姿势约束的判别器。我们将生成的输出称为 “生成性多平面图像”(GMPI),并强调其渲染不仅是高质量的,而且还保证是视图一致的,这使得GMPI与许多先前的工作不同。重要的是,阿尔法图的数量可以动态调整,并且可以在训练和推理之间有所不同,从而减轻了对内存的担忧,并在10242的分辨率下,在不到半天的时间内实现了GMPI的快速训练。我们的发现在三个具有挑战性的常见高分辨率数据集上是一致的,包括FFHQ、AFHQv2和MetFaces。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

-
相关阅读:
(java和c) while循环与++i和i++
如何在自动化测试中使用MitmProxy获取数据返回?
vue 脚手架新手入门(vue cli 3)
PHP + Laravel + RabbitMQ + Redis 实现消息队列 (二) 消费队列在RabbitMQ和redis中的简单使用
MinIO与MySQL对比以及存储的相关知识
pywinauto exists 方法
PDF文档翻译软件哪个好?分享5款快速翻译的工具
如何修改论文,能够避开查重?
kubernetes 之 minikube折腾记
Linux - Ubuntu里安装Python的包
- 原文地址:https://blog.csdn.net/ShowMeAI/article/details/126053200
{kind=link}