-
PP-yoloE论文的理解
目录
2.4 Efficient Task-aligned Head(ET-head)
2.4.2 distribution focal loss(DFL)
出自:百度 2022.44.2
论文:https://arxiv.org/pdf/2203.16250.pdf
代码:https://github.com/PaddlePaddle/PaddleDetection

PP-YOLOE的整体框架图:

1.简单回顾PP-YOLOv2
论文:https://arxiv.org/abs/2104.10419
代码:https://github.com/paddlepaddle/paddledetection
主干ResNet50-vd,deformable convolution,PAN neck with SPP layer and DropBlock【7】,lightweight IOU aware head。 主干激活使用relu,neck 激活使用mish。 loss函数有分类loss,回归loss和目标loss,且PP-yolov2使用了IoU loss和Iou aware loss;
2.本文的贡献
①anchor-free
②powerful backbone and neck equipped with CSPRepResStage
③ET-head
④TAL动态label assign

2.1 anchor free
原因:基于anchor的方法掺杂太多人工设定,且同一组anchor参数无法适用于所有数据集;
细节:anchor free方法参考FCOS【25】,PPYOLOE中的anchor free方法,主要就是将之前anchor base中预测相较于anchor的xywh,改进为预测ltrb(left,top,right,bottom),并将ltrb结果乘上当前特征图的stride。
结果:速度略有提升,且ap下降0.3;
2.2 Backbone and Neck
提出了RepResBlock:
使用了resdiual connections和dense connection,将这种模块用于backbone和neck中;
参考TreeBlock【20】,作者提出了RepResBlock,训练阶段如fig3(b),推理阶段如图3(c),简化的TreeBlock如fig3(a),将concat替换成element-wise add operation就得到了fig3(b)作者的backbone命名为CSPRepResBlock,包括三个卷积和四个RepResBlock,如fig3(d) 通过ESE(Effective Squeeze and Extraction) layer施加通道注意力。

2.2.1 ESE的原始架构
SE(Squeeze-and-Excitation(SE))结构:
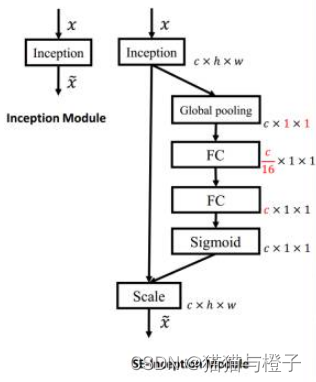

ESE结构:


区别:se有两个fc,ese只有一个fc;
2.3 TAL和T-head
物体检测方法的2个局限性:
①分类和定位的独立性。分类和定位一般用的是2个独立的分支,这样使得2个任务之间缺乏交互,在预测的时候就会出现:得分高的预测位置不准,位置准的预测得分不高。
②任务无关的样本分配:对于分类最优的anchor和对于定位最优的anchor往往并不是同一个。
解决办法:TOOD提出任务对齐头(Task-aligned head, T-head)和新的任务对齐学习(Task-aligned Learning, TAL)来更明确地对齐两个任务; 操作流程:首先,T-head对FPN特征进行预测。然后,计算每个定位点的任务对齐度量,TAL根据此度量为T-head生成学习信号。最后,T-head对分类和定位的分布进行相应的调整。其中,最对齐的锚通过概率图prob (probability map)获得更高的分类得分,通过学习偏移获得更准确的锚框预测。

2.3.1 TAL
Task Alignment Learning:为了进一步指导T-Head做出与任务对齐的预测提出TAL。
它包括一个分配策略和新损失的函数;
分配策略 ①Task-aligned Sample Assignment:
1)对齐良好的锚点应能联合精确定位预测出较高的分类分数;
2)不对齐的锚应具有较低的分类评分,并随后予以抑制。
②Anchor alignment metric:分类得分和IoU的高阶组合来衡量任务对齐程度,

其中:s和u分别表示分类分数和IOU值
③Training sample assignment:选择t值最大的m个锚点为正样本,而使用其余的锚点作为负样本;
损失函数

t^是对t的归一化
2.4 Efficient Task-aligned Head(ET-head)
解决的点:分类和定位的任务冲突
YOLOX使用了decopled head 该方法的缺点:导致分类任务和定位任务分离,使得两个任务独立; 缺乏特定任务学习;
解决方法:参考TOOD【5】,优化得到ET-head 改进点:
①相比较TOOD,使用ESE block替换layer attention。
②分类分支添加了shortcut。
③分类分支使用varifocal loss (VFL),优点:这种实现使得iou高的正样本对损耗的贡献相对较大,促使模型更加关注高质量样本;
④回归分支使用distribution focal loss(DFL)。
最终loss:

结果:map提升0.5;
2.4.1 varifocal loss (VFL)
focal loss:
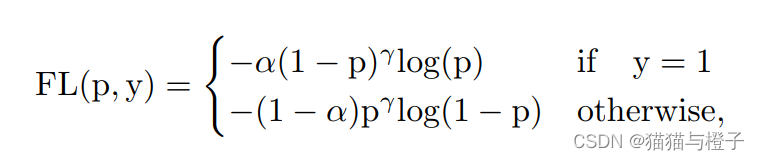
其中a用来均衡正负样本的权重,y为gt,前景类的预测概率p∈[0,1],(1-p)的r次和p的r次用来调制每个样本的权重。使困难样本有更高的权重; VFL从focal loss中借鉴了样本加权思想来解决类不平衡问题;
VFL loss:

其中p是预测的IACS(分类)得分,q是目标IoU得分。 对于训练中的正样本,将q设置为生成的bbox和gt box之间的IoU;而对于负样本,q为0。
2.4.2 distribution focal loss(DFL)

参考:《Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection》 -清华大学,南京大学 https://blog.csdn.net/qq_52302919/article/details/125304230 https://zhuanlan.zhihu.com/p/310229973
3. 实验
实验数据:MS COCO-2017(80个类别,118000张图片)
数据处理细节:random crop,random horizontal filp,color distortion,和multi-scale;
参数设置细节:SGD,momentum=0.9,weight decay=5e-4,cosine learning rate schedule,epochs=300,warmup epochs=5,base learning rate=0.01,batch size=64;exponential moving average(EMA) 硬件设备:8*32G V100 GPU
3.1 与sota检测器相比

科普性相关信息
一文看懂Label Assignment--标签分配最新论文总结 - 知乎
涉及到的论文
《Bag of Tricks for Image Classification with Convolutional Neural Networks》
可学习的各种训练策略(文中用于分类):
1.学习率的调整
当batch_size=256时,初始化lr=0.1,当batch_size=b,则学习率调整为

如:b=128,

2.学习率热身效应
在训练初期使用较小的学习率进行热身,逐渐增大到设置的学习率
 ,则前m个batches使用warm up使用的学习率:
,则前m个batches使用warm up使用的学习率: ,1<=i<=qm
,1<=i<=qm3.使的网络初始阶段更容易训练
Zero γ(可查看原文)
4.只对卷积层和全连接层的weight的weights使用weight decay
在SGD中优化中相当于L2正则,作者认为并不是所有的参数weight decay;
5.其他策略
(使用广泛,不一一细讲了):
1.提升模型的训练速度,FP16和FP32的混合训练;
2.ResNet网络结构的优化;
3.Cosine Learning Rate Decay;
4.Label Smoothing
5.Knowledge Distillation
6.Mixup Training
参考:https://www.jianshu.com/p/02a76ac73d48
《Dropblock:A regularization method for convolutional networks:Advaces in neural information process system》
dropblock:一种正则化方法,在ImageNet分类任务中,使用Resnet-50精度提升了1.6%个点,在coco检测任务中,精度提升了1.6%。
SPP layer :将不同尺寸使用max pooling输出为固定长度的尺寸
Relu激活:又称为修正线性单元(Rectified Linear Unit),是一种分段线性函数,其弥补了sigmoid函数以及tanh函数的梯度消失问题。
函数:


ReLU函数的优点:
1. 在输入为正数的时候(对于大多数输入 z 空间来说),不存在梯度消失问题。
2. 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
ReLU函数的缺点:
当输入为负时,梯度为0,会产生梯度消失问题。mish激活:
一种自正则的非单调神经激活函数,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。根据论文实验,该函数在最终准确度上比Swish(+0.494%)和ReLU(+ 1.671%)都有提高。
函数:


图形来自于:https://wenku.baidu.com/view/9cbad2976adc5022aaea998fcc22bcd126ff4236.html
IOU loss的使用:
标检测任务的损失函数由Classificition Loss和Bounding Box Regeression Loss两部分构成。
Bounding Box Regression Loss Function的演进路线是:
Smooth L1 Loss --> IoU Loss --> GIoU Loss --> DIoU Loss --> CIoU LossIou loss提出前,大家主要通过4个坐标点独立回归Bounding box(bbox,边界框),这样做的缺点有:
目标检测的评价方式是使用IoU,而实际回归坐标框的时候使用4个坐标点,二者是不等价的,如下图所示;
L1或者L2 Loss相同的框,其IoU 不是唯一的
通过4个坐标点回归坐标框的方式,是假设4个点相互独立的,没有考虑其相关性,实际4个坐标点具有一定的相关性
基于L1和L2的距离的loss对于尺度 不具有 不变性
————————————————
版权声明:本文为CSDN博主「寻找永不遗憾」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45377629/article/details/124911293《Fcos:Fully convolutional one-stage object detection》
提出的无anchor的网络结构:

分类使用fcoal loss,回归使用iou loss;center-ness大小为0-1,用BCE loss计算。用于抑制FCOS产生的低质量的bbox,尤其是那些离目标中心较远的locations ;
residual connections:
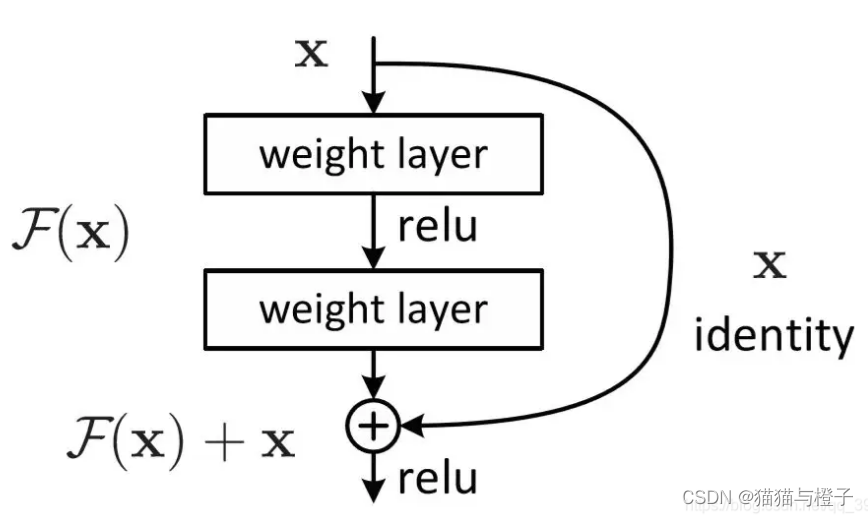
残差链接主要是为了解决梯度消失问题;
dense connections :

密集连接主要是使用更多的感受野扩大中间特征;
-
相关阅读:
python科学计算环境搭建
java虚拟机堆空间
AppGallery Connect场景化开发实战—图片存储分享
【Spring】@Component组件
【JavaWeb】登录权限验证,AJAX异步验证用账号是否存在
webpack(一)模块化
Http实战之Wireshark抓包分析
免费好用的Mac电脑磁盘清理工具CleanMyMac
第20节-PhotoShop基础课程-橡皮檫工具
redis修改默认存储数据目录
- 原文地址:https://blog.csdn.net/qq_22764813/article/details/125456458