-
【单目3D目标检测】项目实战-道路车辆/行人3D目标检测
任务定义
输入:单帧RGB图像
输出:图中目标的3D包围框 ( x , y , z , h , w , l , r y ) (x,y,z,h,w,l,ry) (x,y,z,h,w,l,ry)x,y,z :物体中心点的坐标
h,w,l :物体维度(长、宽、高)
ry :偏航角传统激光雷达3D检测模型 VS 单目3D检测模型
传统依靠激光雷达的3D检测方法存在传感器昂贵难以大规模广泛部署,点云缺失纹理信息,分辨率低等问题。而建立单目3D检测模型,有效的利用了图像相对于点云的各个优势,降低产业落地门槛,更容易部署到需要的各个场景。
单目3D目标检测优点
1 传感器偏移
2 丰富的纹理信息
3 分辨率高

单目3D目标检测难点
1 深度信息缺失,由 2D 图像预测 3D 位置困难
2 相机传感器敏感,受环境影响(夜晚、雨天)等较大
3 图像层面,遮挡、截断等问题严重影响感知精度
数据集
KITTI 数据集是一个用于自动驾驶场景下的计算机视觉算法测评数据集,由德国卡尔斯鲁厄理工学院(KIT)和丰田工业大学芝加哥分校(TTIC)共同创立。包含场景有市区、乡村和高速公路。本案例使用公开的 KITTI 数据集用于训练测试,共有 14999 张图片,分为训练集 3712 张,验证集 3769 张,测试集 7518 张。示例图片如下图所示:

公开KITTI数据集KITTI数据集标注及网络输出形式
整个数据集包含图片 images,标签 labels 和相机参数 calib,每个标签文件种包含以下字段:
type—物体类别
truncated—是否截断
occluded—是否遮挡
alpha—观测角
bbox—障碍物2D框
dimension—障碍物的3D大小
location—障碍物的3D底面中心点位置
rotation_y—障碍物的朝向角
score—障碍物预测的置信度最终数据集文件组织结构为:
kitti
└── training
├── calib
├── image_2
└── label_2KITTI评价指标

纵向:虽然最终关注并使用的是3D检测框,但同时会反馈 2D detection 和 3D BEV检测框的定位精度。横向:根据所标注包围框是否被遮挡、遮挡程度、框的大小将数据集分为Easy,Mod,Hard。
3D detection、2D detection 和 3D BEV 指标计算方式都是AP(根据PR曲线计算)。KITTI主流的评价标准是R11和R40,两者区别是采样点的不同。R40效果更好,更能反映评测的精准度。
模型
整体框架
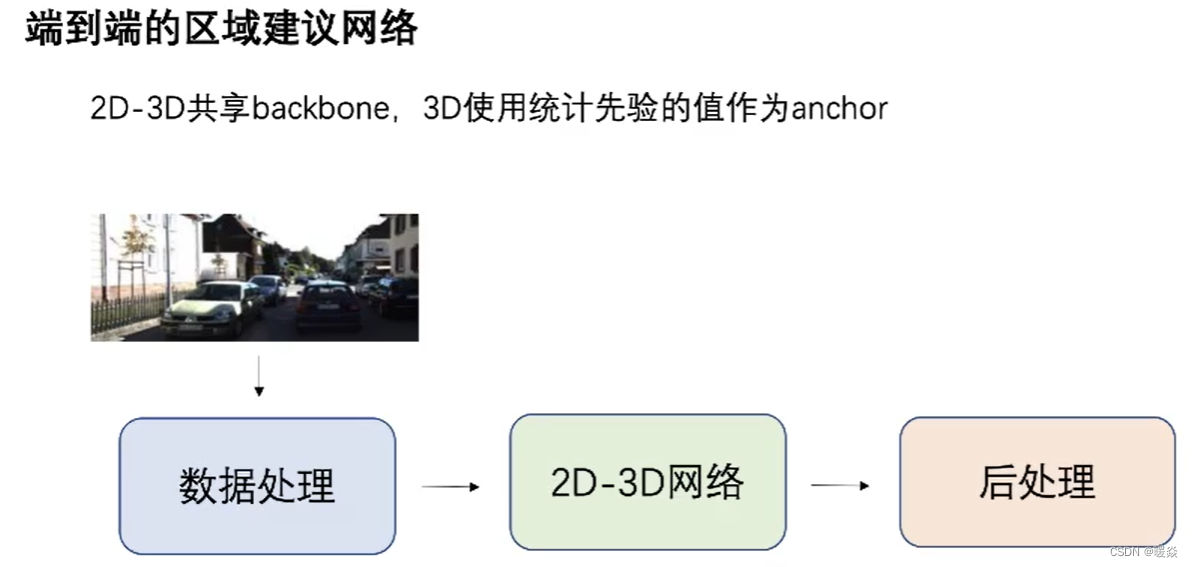
数据过滤
目的:平衡前后背景,保证训练的稳定性。

vis可见程度:遮挡程度分为0,1,2,3四个级别,如果图片遮挡级别是2,3,考虑放弃使用该图片样本,因为可见度太低会影响训练的稳定性。Bbox大小:Bbox过大过小都将其考虑为困难样本,影响训练的稳定性。
类别:只关注car,pedestrian,cyclist三类。
图片标签:无标签图片过滤掉。
Anchor

2D Anchor
1 (min_gt_h, max_gt_h) 间定义11个采样点,总共有12中尺度。
2 横纵比定义三种 [0.5, 1, 2]每个点定义12种尺度 * 3种比例共36个anchor。

3D anchor
对于3D anchor,不会直接预测 ( x , y , z ) (x,y,z) (x,y,z)的值,因为从2D维度预测3D维度真实距离是比较困难的,所以需要一个统计先验量。
相机内参P · 相机3D位置信息 = 2D图像中位置信息
将3D问题转换为2D问题:
只需预测 x,y 在图像上相对anchor点的偏移offset。对于z(即depth),统计一个先验量。如何统计该先验量?
对于每个2D anchor,知道其长宽,索引数据集中所有跟这个长宽计算2D IoU,找到最匹配的一个集合,在该集合中算出 z 对应的平均值作为anchor的先验量。
对于网络模型来说,只需预测该先验量的offset,大大减少了预测真实世界的负担。其他三个维度 ( w , h , l ) (w,h,l) (w,h,l) 和 θ \theta θ 也是类似操作。
3D 7个自由度中的旋转角 ry,是在物体坐标系或者BEV视角下,车辆的偏航角。但是对于单目图像检测任务来说,直接预测BEV视角下的偏航角很困难,所以一般会将偏航角转换为相机的observation angle视场角(从相机光心看过去与车辆的夹角),这样操作使得网络更容易学习。
数据增强
单目3D目标检测任务中数据增强的研究比较少,2D图像变换有时需要改变3D标签,这种改变有时很困难,这里选用两种:Flip 和 Resize(fix resolution)。

Resize 使用 fix resolution 是为了不改变图片的 focal length,这样横纵比例是对应的,所以只需要把 focal length 做过滤变换或直接把 ( x , y , z ) (x,y,z) (x,y,z)坐标进行过滤变换即可。Backbone

后处理优化
使用 3D、2D IoU 投影做后处理变换。
2D目标检测任务的难度要远远小于单目3D目标检测,2D目标检测的精度要远远大于单目3D目标检测。所以可以使用2D目标检测任务的输出作为伪基T,用该伪基T矫正3D预测的一些属性。具体矫正做法是:把单目3D目标检测任务得到的7个自由度先规划成3D bounding box,也就是物体在三维坐标系中的8个顶点,然后通过相机内参把8个顶点投影到图像上。如图:计算橙色3D bbox和绿色2D box的IoU,通过不断的调整某个3D属性让IoU达到最小,以此修正3D预测的属性。
单目3D目标检测任务中,有一些先验量,最不准的是朝向角和深度。所以,主要矫正的也是朝向角和深度。
如图所示为后处理优化效果。


模型部署
见 项目地址
-
相关阅读:
2023年全球新能源云母材料市场发展展望分析:储能云母市场规模快速增长[图]
MFC项目改为多字节字符集界面风格变为win98风格的问题
Redis-Cluster集群的部署(详细步骤)
进程切换及一些常见概念(面试必问)
[pytorch] 2D + 3D EfficientNet代码 实现,改写
ROI tracking by using OpenCV
go 条件变量
仅需一个依赖给Swagger换上新皮肤,既简单又炫酷~
系统日志记录注解方式动态记录
企业架构LNMP学习笔记34
- 原文地址:https://blog.csdn.net/guai7guai11/article/details/125728502