-
2、图机器学习——Graph Embedding
Graph Embedding

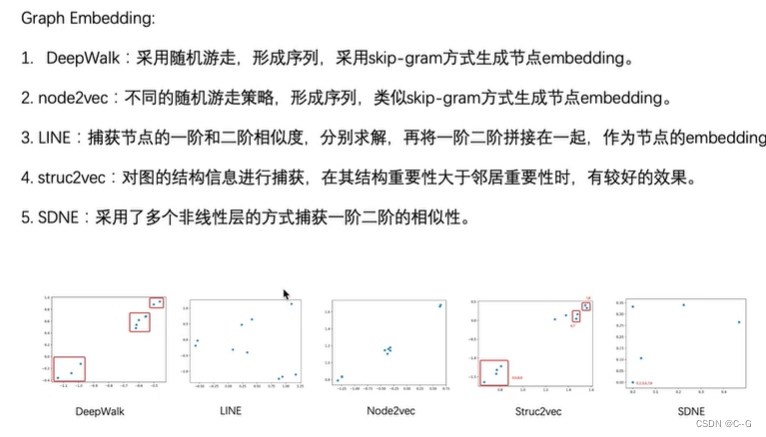
DeepWalk
DeepWalk方法首先以随机游走(Random Walk)的方式在网络中进行节点采样,生成序列,然后使用Skip-Gram模型将序列转换为Embedding。首先使用Random Walk的方式进行节点采样。Random Walk是一种可重复访问已访问节点的深度优先遍历算法。然后给定当前访问起始节点,从其邻居中随机选择一个节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。获取足够数量的节点访问序列后,使用Skip-Gram模型进行向量学习,最终获得每个节点的Embedding
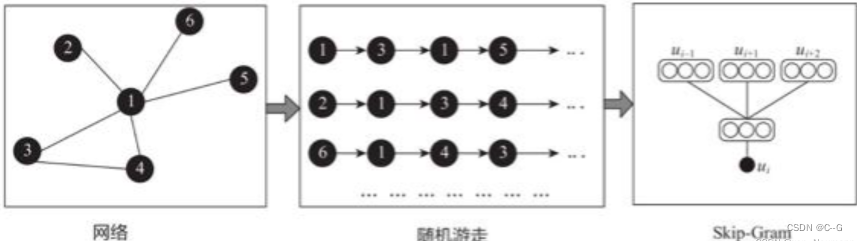
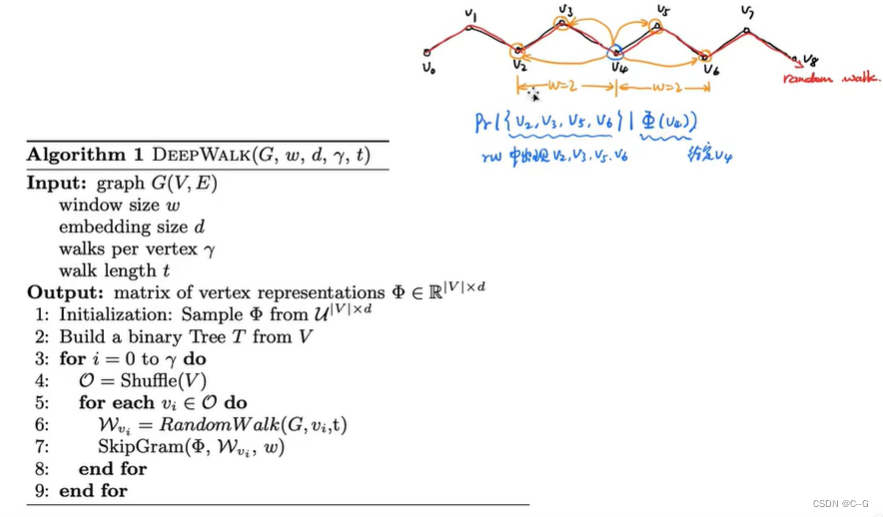
DeepWalk方法的优点首先是它可以按需生成,随机游走。由于Skip-Gram模型也针对每个样本进行了优化,因此随机游走和Skip-Gram的组合使DeepWalk成为在线算法。其次,DeepWalk是可扩展的,生成随机游走和优化Skip-Gram模型的过程都是高效且平凡的并行化。最重要的是,DeepWalk引入了深度学习图形的范例。用Skip-Gram方法对网络中节点进行训练。那么,根据Skip-Gram的实现原理,最重要的就是定义Context,也就是Neighborhood。在自然语言处理中,Neighborhood是当前Word周围的字,DeepWalk用随机游走得到Graph或者Network中节点的NeighborhoodLINE(Large-scale Information Network Embedding)
DeepWalk只适用无向、无权重的图。在2015年,微软亚洲研究院发布了LINE(Large-scale Information Network Embedding,大型信息网络嵌入)。LINE使用边采样方法克服了传统的随机梯度法容易出现的Node Embedding聚集问题,同时提高了最后结果的效率和效果



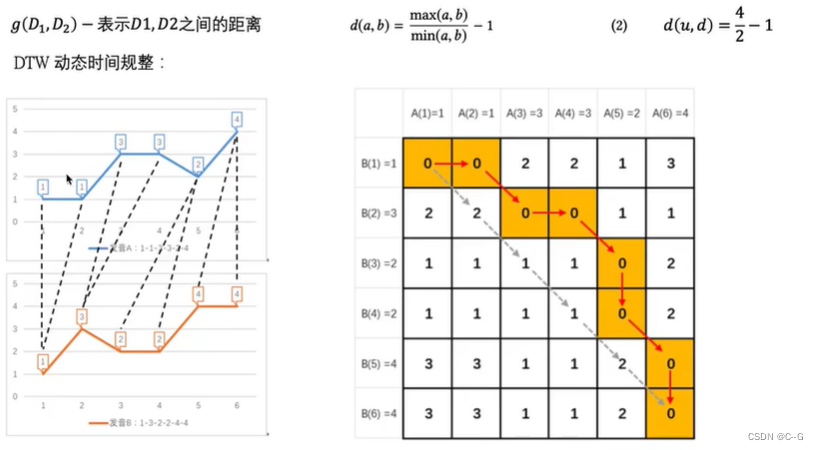
1阶相似度用于描述图中成对顶点之间的局部相似度,形式化描述为若image.png之间存在直连边,则边权image.png即为两个顶点的相似度,若不存在直连边,则1阶相似度为0。如上图,6和7之间存在直连边,且边权较大,则认为两者相似且1阶相似度较高,而5和6之间不存在直连边,则两者间1阶相似度为0。
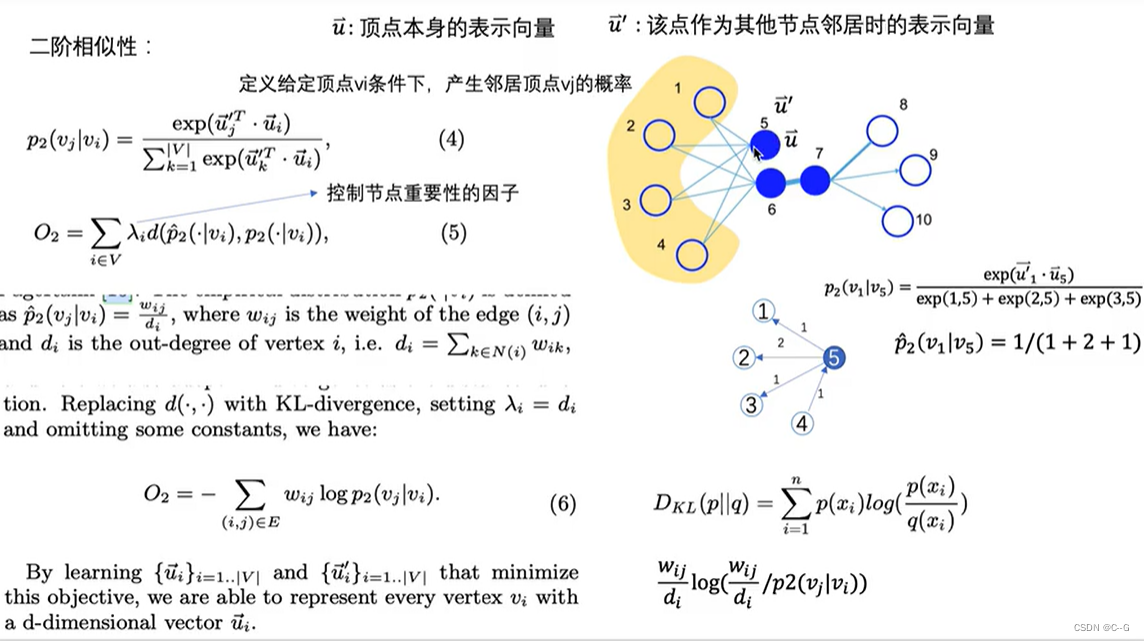
仅有1阶相似度就够了吗?显然不够,如上图,虽然5和6之间不存在直连边,但是他们有很多相同的邻居顶点(1,2,3,4),这其实也可以表明5和6是相似的,而2阶相似度就是用来描述这种关系的。形式化定义为,令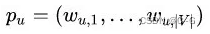
表示顶点与所有其他顶点间的1阶相似度,则与的2阶相似度可以通过和的相似度表示。若与之间不存在相同的邻居顶点,则2阶相似度为0

node2vec
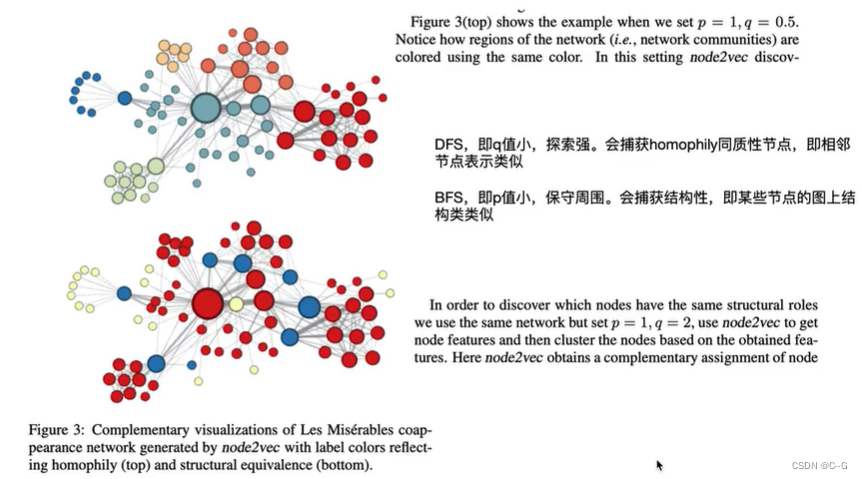
2016年出现的node2vec,node2vec的思想同DeepWalk一样,生成随机游走,对随机游走采样得到(节点,上下文)的组合,然后用处理词向量的方法对这样的组合建模得到网络节点的表示。不过在生成随机游走过程中做了一些创新,node2vec改进了DeepWalk中随机游走的生成方式(通过调整随机游走权重的方法使graph embedding的结果在网络的同质性(homophily)和结构性(structural equivalence)中进行权衡),使得生成的随机游走可以反映深度优先和广度优先两种采样的特性,从而提高网络嵌入的效果。
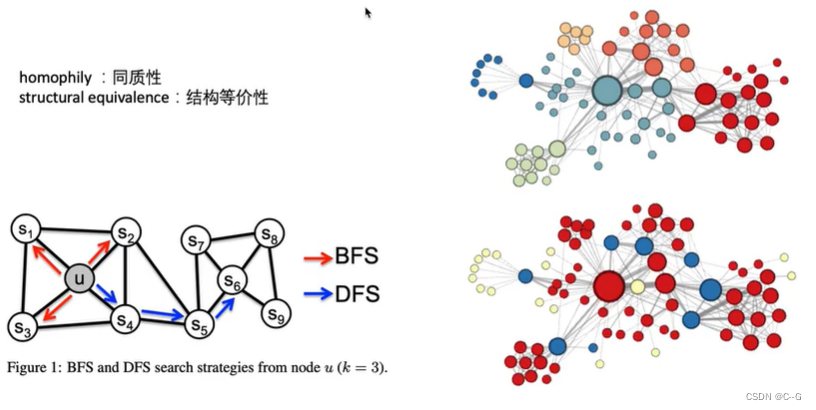
网络的“同质性”指的是距离相近节点的embedding应该尽量近似,如图,节点u与其相连的节点s1、s2、s3、s4的embedding表达应该是接近的,这就是“同质性“的体现。网络的“结构性”指的是结构上相似的节点的embedding应该尽量接近,图中节点u和节点s6都是各自局域网络的中心节点,结构上相似,其embedding的表达也应该近似,这是“结构性”的体现
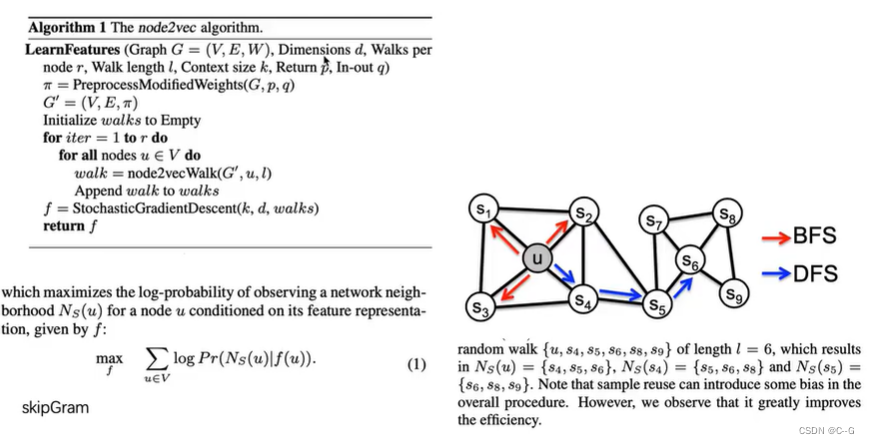
node2vec的主要创新点通过改进游走方式- 深度优先游走DFS
- 广度优先搜索BFS
就如上图的标注所示,深度优先游走策略将会限制游走序列中出现重复的结点,防止游走掉头,促进游走向更远的地方进行。而广度优先游走策略相反将会促进游走不断的回头,去访问上一步结点的其他邻居结点。这样一来,当使用广度优先策略时,游走将会在一个社区内长时间停留,使得一个社区内的结点互相成为context,这也就达到了第一条优化目标。相反,当使用深度优先的策略的时候,游走很难在同一个社区内停留,也就达到了第二条优化目标
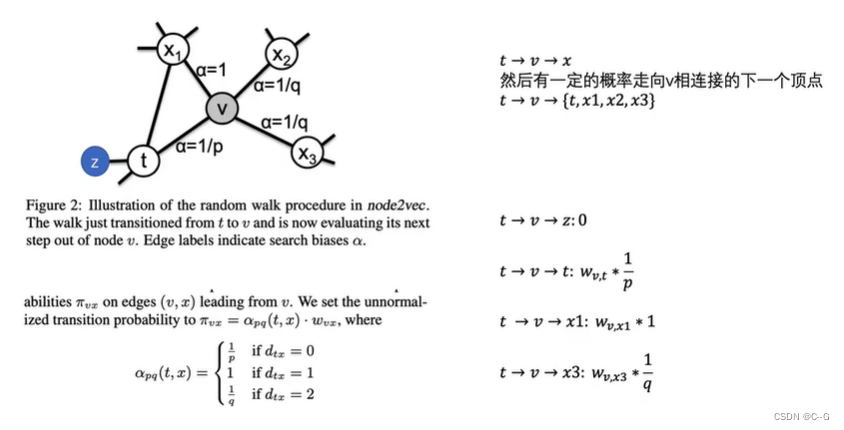

参数p、q的意义分别如下:返回概率p:
- 如果 p > max(q,1) p>max(q,1) p>max(q,1) ,那么采样会尽量不往回走,对应上图的情况,就是下一个节点不太可能是上一个节点t。
- 如果 p < max( q,1) p
出入参数q:
- 如果 q > 1 q>1 q>1,那么游走会倾向于在起始点周围的节点之间跑,可以反映出一个节点的BFS特性。
- 如果 q < 1 q<1 q<1 ,那么游走会倾向于往远处跑,反映出DFS特性。
当p=1,q=1时,游走方式就等同于DeepWalk中的随机游走
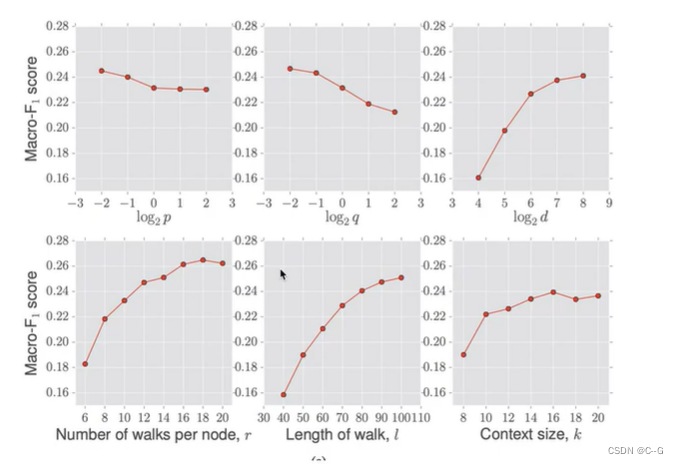

Struc2vec
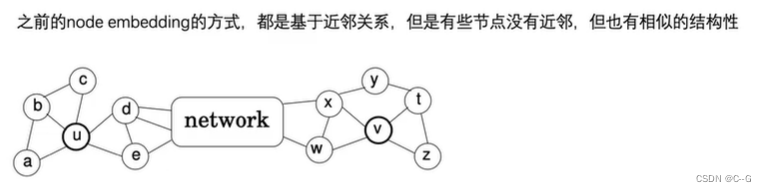





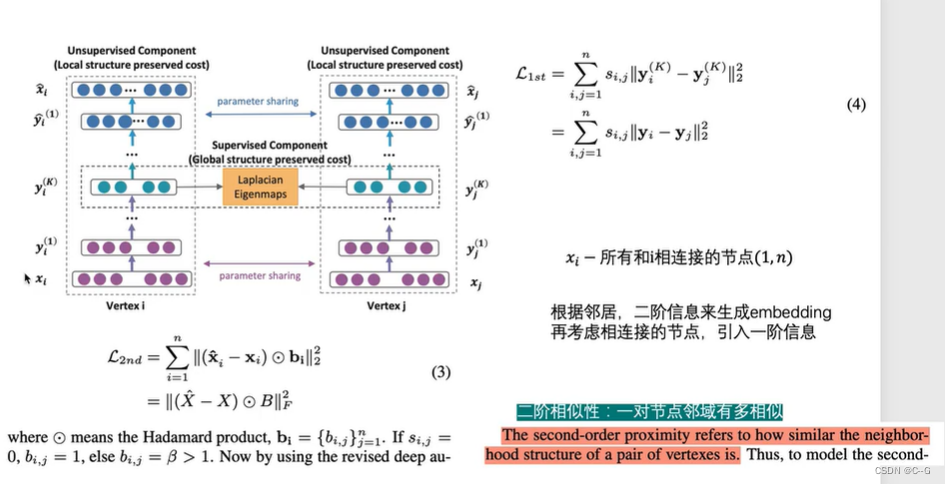
Struc2vec适用于节点分类中,其结构标识比邻居标识更重要SDNE(Structural Deep Network Embedding)


总结
-
相关阅读:
Vue3生命周期
【JavaWeb - 网页编程】七 HTTP 协议 与 Servlet 技术
前端内存泄漏和溢出的情况以及解决办法
数据库管理-第四十二期 复盘一下(20221104)
Apache Flink ML 2.1.0 发布公告
VR模拟仿真实验课件可视化编辑,提高学员实操水平
Visual Studio中vim模拟器
将base64格式的图片画到canvas上(js和vue两种)
机器学习:十大算法快速回顾
自定义JPA函数扩展,在specification中实现位运算
- 原文地址:https://blog.csdn.net/weixin_50973728/article/details/125848142