-
基于深度学习的人脸识别闸机开发(基于飞桨PaddlePaddle)
一、概述
1.1 人脸识别背景
自 20 世纪下半叶,计算机视觉技术逐渐地发展壮大。同时,伴随着数字图像相关的软硬件技术在人们生活中的广泛使用,数字图像已经成为当代社会信息来源的重要构成因素,各种图像处理与分析的需求和应用也不断促使该技术的革新。经过不断发展,计算机视觉已逐步形成一套以数字信号处理技术、计算机图形图像、信息论和语义学相互结合的综合性技术,并具有较强的边缘性和学科交叉性。其中,人脸检测与识别是计算机视觉的一个热门研究课题, 也是目前生物特征识别中最受人们关注的一个分支。
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。通常采用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸。自 2015 年到 2020 年,人脸识别市场规模增长了 166.6%,在众多生物识别技术中增幅居于首位,也成为当下人工智能落地最成功的应用领域。在不同的生物特征识别方法中,人脸识别有其自身特殊的优势,因而在生物识别中有着重要的地位。
具体的,人脸识别有五大优势:
(1) 非侵扰性
人脸识别无需干扰人们的正常行为就能较好地达到识别效果,无需担心被识别者是否愿意将手放在指纹采集设备上,他们的眼睛是否能够对准虹膜扫描装置等等。只要在摄像机前自然地停留片刻,用户的身份就会被正确识别。(2) 便捷性
采集设备简单,使用快捷。一般来说,常见的摄像头就可以用来进行人脸图像的采集, 不需特别复杂的专用设备。图像采集在数秒内即可完成。(3) 友好性
通过人脸识别身份的方法与人类的习惯一致,人和机器都可以使用人脸图片进行识别。而指纹,虹膜等方法没有这个特点,一个没有经过特殊训练的人,无法利用指纹和虹膜图像对其他人进行身份识别。(4) 非接触性
人脸图像信息的采集不同于指纹信息的采集,利用指纹采集信息需要用手指接触到采集设备,既不卫生,也容易引起使用者的反感,而人脸图像采集,用户不需要与设备直接接触。(5) 可扩展性
在人脸识别后,下一步数据的处理和应用,决定着人脸识别设备的实际应用,如应用在出入门禁控制、人脸图片搜索、上下班刷卡、恐怖分子识别等各个领域,可扩展性强。1.2 实现
1.2.1 算法说明
本文将基于现有的开源算法开发出一套类似上班刷脸打卡的人脸识别闸机。整个算法执行过程包括人脸检测(blazeface)和人脸识别(arcface)两个部分。先从图像中精确检测出人脸区域(排除背景干扰信息),再提取人脸特征向量(具备人脸鉴别性能),然后与数据库中的人脸特征库进行比对识别。
1.2.2 环境设置
Ubuntu18.04,编程语言为Python和C#。使用的深度学习框架为PaddlePaddle。
1.2.3 实现思路
先全流程跑通示例程序,然后完成基于Server的服务器端部署,实现http接口服务访问,完整的实现人脸检测和识别。
注意:本教程重点在于如何开发和部署人脸识别闸机,将采用现成的训练好的算法实现。读者如果想要自行训练相关算法,可以参照官网教程实现,本文不再深入讲解。
二、示例脚本
PLSC官方示例中提供了完整的示例代码,本小节先将其跑通再逐步优化部署相关模块。
2.1 安装PaddlePaddle和PLSC
参照官网并结合自己的服务器配置安装PaddlePaddle。本文使用PaddlePaddle2.3稳定版。
接下来准备好PLSC工程代码:
git clone https://github.com/PaddlePaddle/PLSC.git cd PLSC- 1
- 2
2.2 下载人脸检测模型blazeface
先在当前目录下创建models文件夹用于存放训练好的模型参数文件:
mkdir -p models- 1
下载blazeface人脸检测模型
wget https://paddle-model-ecology.bj.bcebos.com/model/insight-face/blazeface_fpn_ssh_1000e_v1.0_infer.tar -P models/ tar -xzf models/blazeface_fpn_ssh_1000e_v1.0_infer.tar -C models/ rm -rf models/blazeface_fpn_ssh_1000e_v1.0_infer.tar- 1
- 2
- 3
下载下来的模型是使用Paddle训练好的人脸检测模型,并且已经转换为了静态图模式,可以直接在工程部署时使用,具体文件如下图所示:
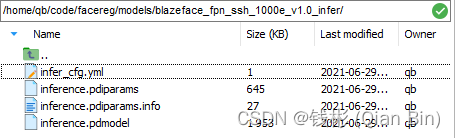
可以看到,下载下来的人脸检测模型本身很小,只有2M左右,适合实时预测需求。2.3 下载人脸识别模型arcface
接下来下载人脸识别模型
wget https://plsc.bj.bcebos.com/pretrained_model/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2.tgz -P models/ tar -xzf models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2.tgz -C models/ rm -rf models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2.tgz- 1
- 2
- 3
这里我们下载的人脸识别模型文件是动态图版本,为了后面部署需求,我们需要将其转换为静态图版本。
python tools/export.py --is_static False --export_type paddle --backbone FresResNet50 --embedding_size 512 --checkpoint_dir models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2/FresResNet50/best_model/cfp_fp/ --output_dir models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer- 1
结束后模型保存在models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer目录下。
2.4 下载示例数据
首先下载示例数据图片:
mkdir -p images/ wget https://plsc.bj.bcebos.com/Friends.tgz -P images/ tar -xzf images/Friends.tgz -C images/- 1
- 2
- 3
完成后在images文件夹下会生成Friends文件夹,该文件夹里面包含gallery和query两个子文件夹,其中gallery用于存放特征库图像,query用于存放待比对人脸。
gallery文件夹如下图所示,其中每个子文件夹代表一个人物。
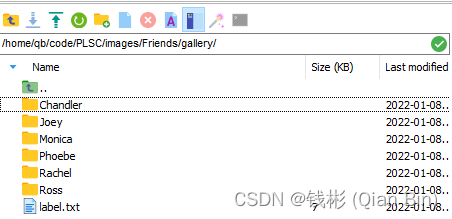
每个子文件夹存放人脸照片,如下图所示:

注意,这里的人脸图像已经是裁剪过后的定位好的人脸图像,如果我们要制作我们自己的人脸特征库,那么我们可以使用人脸检测算法来提取类似的人脸图像或者手工裁剪获得。label.txt文件夹存放对应的人脸识别标签,每行标识一张图片及对应所属的人物,如下所示:
./Chandler/Chandler00037.jpg Chandler- 1
下面下载字体文件用于demo的文字显示:
mkdir -p assets wget https://plsc.bj.bcebos.com/SourceHanSansCN-Medium.otf -P assets/- 1
- 2
2.5 建立人脸特征库索引
python tools/test_recognition.py \ --rec \ --rec_model_file_path models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer/FresResNet50.pdmodel \ --rec_params_file_path models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer/FresResNet50.pdiparams \ --build_index=images/Friends/gallery/index.bin \ --img_dir=images/Friends/gallery \ --label=images/Friends/gallery/lab el.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
最终输出如下:
INFO:root:Build done. Total 245. Index file has been saved in "images/Friends/gallery/index.bin"- 1
当前demo共建立了245条索引,所有的索引数据保存在images/Friends/gallery/index.bin文件中。
2.6 测试
运行下面的代码实现完整的人脸检测和识别:
python tools/test_recognition.py \ --det \ --det_model_file_path models/blazeface_fpn_ssh_1000e_v1.0_infer/inference.pdmodel \ --det_params_file_path models/blazeface_fpn_ssh_1000e_v1.0_infer/inference.pdiparams \ --rec \ --rec_model_file_path models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer/FresResNet50.pdmodel \ --rec_params_file_path models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer/FresResNet50.pdiparams \ --index=images/Friends/gallery/index.bin \ --input=images/Friends/query/friends2.jpg \ --cdd_num 10 \ --output="./output"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里如果出现pillow库的错误,可以先卸载掉原pillow库,然后安装下面版本的pillow:
pip install Pillow==5.3.0- 1
最终输出结果如下:
INFO:root:File: friends2.jpg, predict id_score_list(s): [('Phoebe', 0.6790162), ('Chandler', 0.45572573), ('Rachel', 0.5290625), ('Joey', 0.5297642), ('Ross', 0.71935725), ('Monica', 0.37967032)]- 1
可视化结果在./output文件夹下面,如下所示:

接下来我们在网上随便找张示例照片进行测试,如下所示:

可以看到,当索引库里面没有相关人物的特征时返回结果是unknown,其置信度是-1.0,即当前系统确信这两个人不在特征库里面。虽然PLSC是一个开源算法,但是其训练好的模型精度还是比较高的。后面我们可以基于此开发我们自己的人脸识别系统。到这里,其实我们已经具备使用python脚本进行人脸识别完整流程的能力。接下来,我们只需要对相关代码和模型进行优化部署即可上线。
三、Paddle Serving线上部署
3.1 Paddle Serving简述
前面我们已经可以成功的使用python脚本完成全流程的人脸识别推理,那么为什么这里还需要使用Paddle Serving呢?这个PaddleServing到底是什么呢?下面我们先来解释这两个问题。
一般来说在做算法训练后,都会导出一个静态图模型,在应用中直接使用,就像我们前面做的这样。但是前面我们使用的Python脚本是在本地进行推理的,怎么样才能对外提供推理服务呢?正常的思路是在flask、django或者tornado这种基于Python的web服务框架中嵌入训练好的静态图模型,稍微修改下python推理脚本就可以提供基于rest api的云服务。考虑到并发高可用性,一般会采取多进程的部署方式,即一台云服务器上同时部署多个flask,每个进程独享一部分GPU资源,显然这样是很浪费资源的。
为了帮助用户有效解决这个部署难题,百度飞桨提供了一种生产环境部署工具,他们开发了一个名为paddle-serving的服务,可以自动加载某个路径下的所有模型,模型通过事先定义的输入输出和计算图,直接提供rest服务。Paddle Serving依托深度学习框架PaddlePaddle可以帮助深度学习开发者和企业提供高性能、灵活易用的工业级在线推理服务。Paddle Serving 支持 RESTful、gRPC、bRPC 等多种协议,提供多种异构硬件和多种操作系统环境下推理解决方案。
使用Paddle Serving部署其基本架构原理如下:
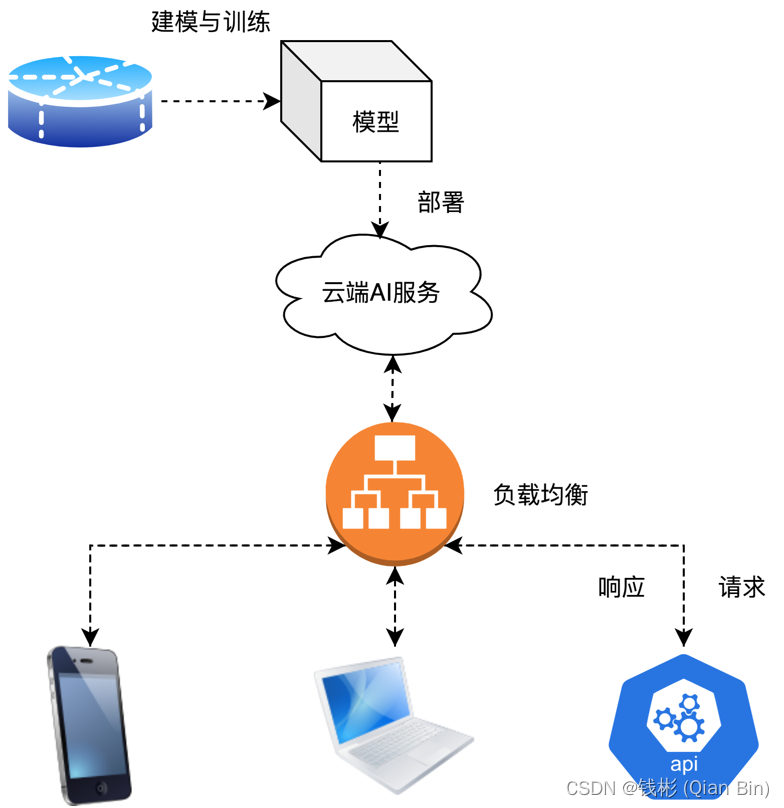
简单来理解,使用Paddle Serving能够最大限度的使用我们的GPU服务器资源,能够充分发挥模型推理性能,并且所有底层的资源调度、负载均衡之类的都已经封装好了,我们只需要简单的按照接口搭建模型就可以完成工业级部署。此外在实际应用中,部署的场景可能会非常复杂。如下图所示,在某些用户的业务中,需要将多个模型分阶段、联合使用,例如本文任务,其中就需要将人脸检测、人脸识别两个模型级联,两者之间形成上下游关系,相互配合实现整个人脸识别业务相关推理功能。因此如何能将类似的串联模型成功稳定的部署到GPU服务器上也是一个亟需解决的问题,为此,Paddle Serving提供了适用于模型串联的Pipeline部署方式,可以用最少的代码帮助我们完成串联模型的部署。

3.1 安装
参照官网安装最新稳定版,各组件安装命令如下(当前最新版为0.9.0):
3.1.1安装客户端paddle_serving_client
客户端主要用于模型转换。安装命令如下:
pip install https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_client-0.9.0-cp36-none-any.whl -i https://mirror.baidu.com/pypi/simple- 1
3.1.2 安装服务器端paddle_serving_server_gpu
服务器端用于真正完成深度学习推理,这里安装时要选择适配当前机器对应的cuda和tensorrt版本,安装命令如下所示:
pip install https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.9.0.post102-py3-none-any.whl -i https://mirror.baidu.com/pypi/simple- 1
3.1.3 安装工具组件paddle_serving_app
工具组件主要用于执行一些预处理和后处理操作,方便部署,安装命令如下:
pip install https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.9.0-py3-none-any.whl -i https://mirror.baidu.com/pypi/simple- 1
3.2 转换serving模型
为了能够使PaddleServing正常推理,我们需要将我们前面准备好的人脸检测和人脸识别静态图模型再进一步的转换为PaddleServing支持的格式才行。
我们将使用paddle_serving_client.convert工具进行转换。需要说明的是,如果我们已经把模型转换完了,那么在新机器上部署时我们不再需要安装paddle_serving_client了,只需要安装paddle_serving_server和paddle_serving_app即可。
首先转换人脸检测模型,具体命令如下:
python -m paddle_serving_client.convert \ --dirname ./models/blazeface_fpn_ssh_1000e_v1.0_infer \ --model_filename inference.pdmodel \ --params_filename inference.pdiparams- 1
- 2
- 3
- 4
转换完成后在当前目录会生成出serving_client和serving_server两个文件夹,这两个文件夹就是最终转换完的可以给Paddle Serving调用的模型文件。为了不跟后面的人脸识别模块冲突,我们将这两个文件夹改名为facedet_serving_client和facedet_serving_server。
接下来按照同样的方法转换人脸识别模型,具体命令如下:
python -m paddle_serving_client.convert \ --dirname ./models/MS1M_v3_arcface_Res50_dynamic_0.1_NHWC_FP16_v2.2_infer \ --model_filename FresResNet50.pdmodel \ --params_filename FresResNet50.pdiparams- 1
- 2
- 3
- 4
转换完成后在当前目录同样的会生成出serving_client和serving_server两个文件夹,我们将这两个文件夹改名为facerec_serving_client和facerec_serving_server。
到这里模型转换就全部结束了,接下来我们需要编写服务器配置文件和启动脚本文件来执行。
3.3 编写服务器配置文件
在当前根目录下创建服务器启动的配置文件,命名为config.yml,内容如下:
dag: is_thread_op: true # True为线程模型;False为进程模型 use_profile: false # 是否开启性能分析 retry: 1 # 重试次数 http_port: 27008 # http端口 build_dag_each_worker: false #False表示框架在进程内创建一条DAG;True表示框架会在每个进程内创建多个独立的DAG worker_num: 1 # 最大并发数。当build_dag_each_worker=True时, 框架会创建worker_num个进程,每个进程内构建grpcSever和DAG op: facedet: concurrency: 1 # 并发数,is_thread_op=True时,为线程并发;否则为进程并发 local_service_conf: client_type: local_predictor # client类型,包括brpc, grpc和local_predictor.local_predictor device_type: 1 # device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu devices: '0' # 当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡 fetch_list: #Fetch结果列表,model中fetch_var的alias_name为准, 如果没有设置则全部返回 - save_infer_model/scale_0.tmp_1 ir_optim: True # 开启内存优化 batch_size: 1 model_config: facedet_serving_server/ # 服务器模型存放路径 facerec: concurrency: 1 # 并发数,is_thread_op=True时,为线程并发;否则为进程并发 local_service_conf: client_type: local_predictor # client类型,包括brpc, grpc和local_predictor.local_predictor device_type: 1 # device_type, 0=cpu, 1=gpu, 2=tensorRT, 3=arm cpu, 4=kunlun xpu devices: '0' # 当devices为""或不写时为CPU预测;当devices为"0", "0,1,2"时为GPU预测,表示使用的GPU卡 fetch_list: #Fetch结果列表,model中fetch_var的alias_name为准, 如果没有设置则全部返回 - batch_norm_78.tmp_3 ir_optim: True # 开启内存优化 batch_size: 1 model_config: facerec_serving_server/ # 服务器模型存放路径- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
由于我们采用模型级联的方式,因此在整个配置文件中定义了两个op对应的配置参数,包括facedet和facerec,分别代表人脸检测和人脸识别。
这里需要注意的是每个模型的输入和输出,可以从每个模型的服务参数文件中获取,例如对于人脸识别,我们在前一小节转换完模型后将文件夹改名为facerec_serving_client和facerec_serving_server,这里我们找到facerec_serving_server/serving_server_conf.prototxt文件,内容如下:
feed_var { name: "inputs" alias_name: "inputs" is_lod_tensor: false feed_type: 1 shape: 3 shape: 112 shape: 112 } fetch_var { name: "batch_norm_78.tmp_3" alias_name: "batch_norm_78.tmp_3" is_lod_tensor: false fetch_type: 1 shape: 512 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
可以发现,这个模型有一个输入(feed_var)变量和一个输出变量(fetch_var),名称分别为inputs和batch_norm_78.tmp_3,这两个名称在我们的yml文件中以及后面的服务器启动脚本中需要使用到,我们需要记住它。如果无法确认每个模型的输入输出,我们还可以使用Paddle提供的可视化工具visualdl查看模型的原始静态图模型结构来观察。
3.4 编写服务器启动脚本
在当前目录下创建web_service.py脚本文件,完整代码如下:
# 导入系统库 import numpy as np import cv2 #from io import BytesIO import base64 import pickle from collections import defaultdict from sklearn.metrics.pairwise import cosine_similarity # 导入Paddle Sering库 from paddle_serving_app.reader import * from paddle_serving_server.web_service import WebService, Op # 读取全局的人脸索引库文件 with open('index.bin', "rb") as f: g_index = pickle.load(f) g_label = g_index["label"] g_index_feature = np.array(g_index["feature"]).squeeze() class FaceDetOp(Op): ''' 定义人脸检测工序 ''' def init_op(self): ''' 初始化 ''' self.target_width = 640 self.target_height = 640 self.img_preprocess = Sequential([ BGR2RGB(), Resize((self.target_width, self.target_height)), Div(255.0), Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225], False), Transpose((2, 0, 1)) ]) def preprocess(self, input_dicts, data_id, log_id): ''' 预处理 ''' (_, input_dict), = input_dicts.items() # 解码图像 feed_dict = {} for key in input_dict.keys(): data = base64.b64decode(input_dict[key].encode('utf8')) data = np.fromstring(data, np.uint8) im = cv2.imdecode(data, cv2.IMREAD_COLOR) self.im = im # 图像边界扩充,提高人脸检测尺度 h, w, _ = im.shape self.delta_h = int(h / 2) self.delta_w = int(w / 2) im = cv2.copyMakeBorder( im, self.delta_h, self.delta_h, self.delta_w, self.delta_w, cv2.BORDER_CONSTANT, value=[255, 255, 255]) # 预处理图像 self.org_height, self.org_width, _ = im.shape self.img_scale_x = self.target_width * 1.0 / self.org_width self.img_scale_y = self.target_height * 1.0 / self.org_height im = self.img_preprocess(im) # 封装输入 feed_dict["im_shape"] = np.array([self.org_height, self.org_width], dtype=np.float32)[np.newaxis, :] feed_dict["scale_factor"] = np.array( [self.img_scale_y, self.img_scale_x], dtype=np.float32)[np.newaxis, :] feed_dict["image"] = im[np.newaxis, :, :, :] return feed_dict, False, None, "" def postprocess(self, input_dicts, fetch_dict, data_id, log_id): ''' 后处理 ''' # 取出检测坐标 face_boxes = fetch_dict["save_infer_model/scale_0.tmp_1"] # 矫正位置 if face_boxes is None: height, width = self.im.shape[:2] face_boxes = [np.array([0, 0, 0, 0, width, height])] else: face_boxes[:,2] = face_boxes[:, 2] * self.img_scale_x - self.delta_w face_boxes[:,4] = face_boxes[:, 4] * self.img_scale_x - self.delta_w face_boxes[:,3] = face_boxes[:, 3] * self.img_scale_y - self.delta_h face_boxes[:,5] = face_boxes[:, 5] * self.img_scale_y - self.delta_h # #封装成字典返回 # bytesio = BytesIO() # np.savetxt(bytesio, face_boxes) # content = bytesio.getvalue() # b64_code = base64.b64encode(content) # face_boxes = str(b64_code, encoding='utf-8') out_dict = {"face_boxes": face_boxes, "image": self.im} return out_dict, None, "" class FaceRecOp(Op): ''' 定义人脸识别工序 ''' def init_op(self): ''' 初始化 ''' self.det_thresh = 0.7 self.rec_thresh = 0.5 self.target_width = 112 self.target_height = 112 self.cdd_num = 5 self.img_preprocess = Sequential([ BGR2RGB(), Resize((self.target_width, self.target_height)), Div(255.0), Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5], False), Transpose((2, 0, 1)) ]) def preprocess(self, input_dicts, data_id, log_id): ''' 预处理 ''' (_, input_dict), = input_dicts.items() im = input_dict["image"] face_boxes = input_dict["face_boxes"] # 取出最大面积区域人脸框 maxarea = 0 is_detected = False xmin, ymin, xmax, ymax = 0,0,0,0 for i, dt in enumerate(face_boxes): if dt.size == 0: print('no face detected') break bbox, score = dt[2:], dt[1] if score < self.det_thresh: continue xmin_, ymin_, xmax_, ymax_ = bbox area = abs(ymax_ - ymin_) * abs(xmax_ - xmin_) if area > maxarea: maxarea = area xmin, ymin, xmax, ymax = int(xmin_), int(ymin_), int(xmax_), int(ymax_) is_detected = True feed_dict = {} if not is_detected: imgs = np.zeros((1, 3, self.target_height, self.target_width)).astype('float32') feed_dict["inputs"] = imgs print('no avaiable face detected') else: h, w, _ = im.shape xmin = max(0, xmin) ymin = max(0, ymin) xmax = min(xmax, w - 1) ymax = min(ymax, h - 1) roi_img = im[ymin:ymax, xmin:xmax, :] # 预处理 roi_img = self.img_preprocess(roi_img) # 封装输入数据 feed_dict["inputs"] = roi_img[np.newaxis, :, :, :] return feed_dict, False, None, "" def postprocess(self, input_dicts, fetch_dict, data_id, log_id): ''' 后处理 ''' # 取出鉴别特征 feature = fetch_dict["batch_norm_78.tmp_3"] # 计算相似特征度 similarity = cosine_similarity(g_index_feature, feature).squeeze() abs_similarity = np.abs(similarity) candidate_idx = np.argpartition(abs_similarity, -self.cdd_num)[-self.cdd_num:] remove_idx = np.where(abs_similarity[candidate_idx] < self.rec_thresh) candidate_idx = np.delete(candidate_idx, remove_idx) candidate_label_list = list(np.array(g_label)[candidate_idx]) candidate_score_list = abs_similarity[candidate_idx] candidate_score_dict = defaultdict(list) for lb, score in zip(candidate_label_list, candidate_score_list): candidate_score_dict[lb].append(score) if len(candidate_label_list) == 0: maxlabel = "unknown" maxscore = -1.0 else: maxlabel = max( candidate_label_list, key=candidate_label_list.count) maxscore = max(candidate_score_dict[maxlabel]) # 返回 out_dict = {"label": maxlabel, "score": str(maxscore)} return out_dict, None, "" class FaceClasService(WebService): ''' 定义服务(级联人脸检测和人脸识别模型) ''' def get_pipeline_response(self, read_op): facedet_op = FaceDetOp(name="facedet", input_ops=[read_op]) facerec_op = FaceRecOp(name="facerec", input_ops=[facedet_op]) return facerec_op # 创建服务 face_service = FaceClasService(name="faceclas") # 加载配置文件 face_service.prepare_pipeline_config("config.yml") # 启动服务 face_service.run_service()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
由于串联了两个模型,整个代码稍微有点复杂,需要结合官方接口定义仔细阅读来理解每行代码的意思。后续读者可以通过print以及查看日志输出来分析和定位代码错误。
上述代码默认从当前根路径中读取人脸库索引文件,因此,我们需要将2.5节中建立的index.bin文件拷贝到当前根目录下。后面如果人脸库发生改变,那么也需要重新建立索引并重新拷贝。
服务器的启动比较简单,跟普通python脚本一样进行启动即可:
python web_service.py- 1
3.5 Python请求测试
在非服务器机器上,启动客户端python脚本,代码如下:
# 导入依赖库 import requests import json import base64 def cv2_to_base64(image): return base64.b64encode(image).decode('utf8') # 定义http接口 url = "http://172.19.17.101:27008/faceclas/prediction" # 打开待预测的图像文件 img_path = '24.jpg' with open(img_path, 'rb') as file: image_data1 = file.read() # 采用base64编码图像文件 image = cv2_to_base64(image_data1) # 按照特定格式封装成字典 data = {"key": ["image"], "value": [image]} # 发送请求 r = requests.post(url=url, data=json.dumps(data)) # 解析返回值 r = r.json() label = r["value"][0] score = r["value"][1] # 保存检测结果到本地 if label is None: print('调用失败') else: # b64_decode = base64.b64decode(id_score_list) # id_score_list = np.loadtxt(BytesIO(b64_decode)) print('姓名:' + label + ' 置信度:' + score) print('完成')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
这里注意http接口的定义,其ip地址即为服务器局域网地址,端口号在config.yml中进行配置,后面跟的faceclas为服务接口名称,在创建服务器启动脚本web_service.py中定义,最后的prediction是默认添加的url。
对应的输入图片24.jpg(从网上随便找的老友记Rachel的剧照)如下:

运行后输出如下:姓名:Rachel 置信度:0.57784843- 1
如果是其他人,如下图所示:

运行后输出如下:姓名:unknown 置信度:-1.0- 1
到这里,我们的整个人脸识别服务已经开发完成了。
对于真实的人脸识别闸机来说,服务器端开发完毕后,我们只需要开发一个简单的客户端程序就可以全流程演示了。
客户端需要实现的功能如下所示:- 实时采集摄像头图像:调用USB摄像头并捕捉每帧图像;
- 人脸检测和识别:对捕获的每帧图像调用人脸检测算法,这里为了简单可以使用opencv现成的人脸检测算法实现;一旦检测到人脸图像,就将当前图像帧发送给远程人脸识别服务进行身份鉴别,并将检测结果显示到界面上;
由于我们将整个耗资源的推理服务放在了GPU服务器上运行,因此,前面的客户端程序就可以用非常轻量的设备来实现,例如树莓派。另外,我们采用的部署方式是Paddle Serving,一旦部署上线,可以支持多个(甚至几十个)人脸识别闸机同时发起请求。这就是为什么我们需要采用Paddle Serving进行部署。
由于前后端使用http进行通信,因此客户端可以使用其它语言(C#、C++、Java都可以)开发,本文不再详细给出每个客户端的实现代码,只需要按照http api的接口定义来实现即可。
四、小结
本文基于PLSC开源库实现了完整的人脸检测和识别功能。本文更偏重部署应用,对于亟需开发上线人脸识别功能的相关读者可以参考本文快速完成开发任务。对于有较高精度要求的读者,也可以在本文基础上,继续深入研究,采用新的人脸识别模型重新训练更高精度的算法,然后结合本文框架,开发出商业级别的人脸识别应用。
想要继续深入学习Paddle的读者,今年年末我会出版一本书籍《深度学习与图像处理—基于PaddlePaddle》,欢迎关注和支持。
由于水平有限,文中如果有错误或更优的解决方案也请读者在评论区指正。欢迎大家一起探讨。
参考文献
【1】J. Deng, J. Guo, N. Xue and S. Zafeiriou, “ArcFace: Additive Angular Margin Loss for Deep Face Recognition,” IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 4685-4694.
【2】https://github.com/littletomatodonkey/insight-face-paddle
【3】https://github.com/PaddlePaddle/PLSC -
相关阅读:
UE5 官方案例Lyra 全特性详解 10.进度汇报和视频推荐
每日汇评:黄金形态确认牛市,再次尝试上行2000美元
Linux中SSHD_CONFIG文件详细注解,便于配置
集线器和交换机
极智开发 | Ant Design 组件库之步骤条
探索大型语言模型(LLM)在人类性格个性评估(MBTI)中的前景与应用
Linux下驱动开发_块设备驱动开发(硬件上采用SD卡+SPI协议)
身份证测试图片
moco接口框架介绍
sw型材利用父子关系找最新特征
- 原文地址:https://blog.csdn.net/qianbin3200896/article/details/125487087
