-
RoBERTa:A Robustly Optimized BERT Pretraining Approach
模型概述
RoBERTa可以看作是BERT的改进版,从模型结构上讲,相比BERT,RoBERTa基本没有什么创新,它更像是关于BERT在预训练方面进一步的探索。其改进了BERT很多的预训练策略,其结果显示,原始BERT可能训练不足,并没有充分地学习到训练数据中的语言知识。
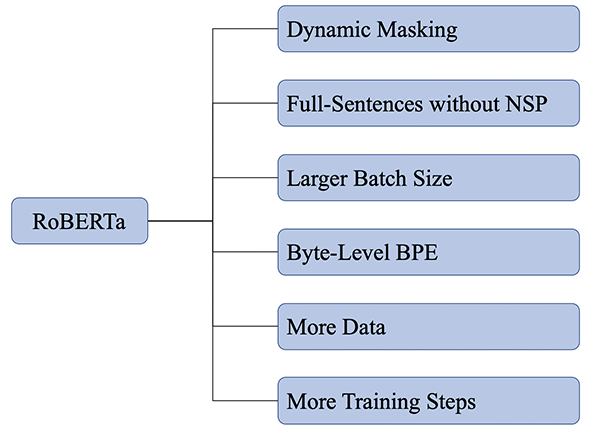
RoBERTa在模型规模、算力和数据上,与BERT相比主要有以下改进:
更大的bacth size。RoBERTa在训练过程中使用了更大的bacth size。尝试过从256到8000不等的bacth size。
更多的训练数据。RoBERTa采用了160G的训练文本,而BERT仅采用了16G的训练文本。
更长的训练步骤。RoBERT在160G的训练数据、8K的batch size上训练步骤高达500K。RoBERTa在训练方法上对比BERT改进的地方有:去掉下一句预测(NSP)任务;采用动态掩码;采用BPE编码方式。
总结一下,用一张图来表示:
模型优化
采用动态掩码
BERT中有个Masking Language Model(MLM)预训练任务,在准备训练数据的时候,需要Mask掉一些token,训练过程中让模型去预测这些token,这里将数据Mask后,训练数据将不再变化,将使用这些数据一直训练直到结束,这种Mask方式被称为Static Masking。
如果在训练过程中,期望每轮的训练数据中,Mask的位置也相应地发生变化,这就是Dynamic Masking,RoBERTa使用的就是Dynamic Masking。
在RoBERTa中,它具体是这么实现的,将原始的训练数据复制多份,然后进行Masking。这样相同的数据被随机Masking的位置也就发生了变化,相当于实现了Dynamic Masking的目的。例如原始数据共计复制了10份数据,共计需要训练40轮,则每种mask的方式在训练中会被使用4次。
取消NSP任务,使用FULL-SENTENCES构造数据的方式
BERT中在构造数据进行NSP任务的时候是这么做的,将两个segment进行拼接作为一串序列输入模型,然后使用NSP任务去预测这两个segment是否具有上下文的关系,但序列整体的长度小于512。
然而,RoBERTa通过实验发现,去掉NSP任务将会提升down-stream任务的指标。如图所示:
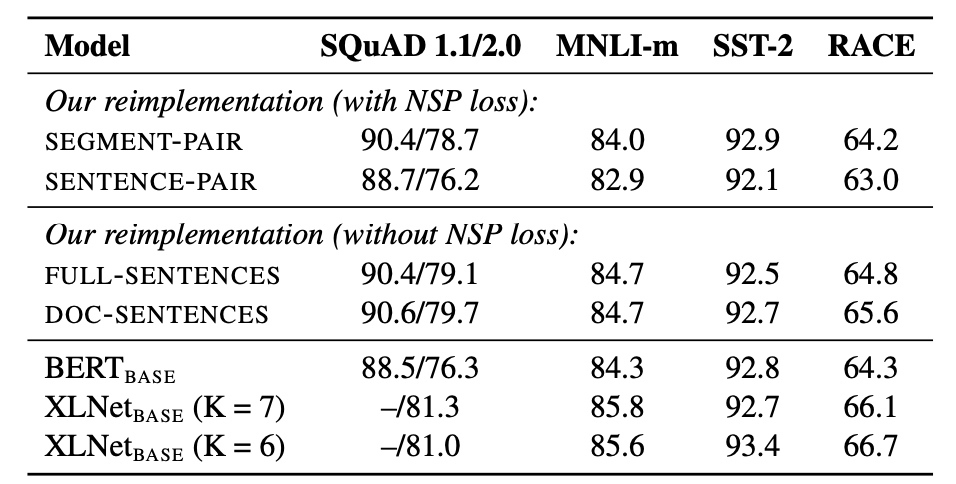
其中,SEGMENT-PAIR、SENTENCE-PAIR、FULL-SENTENCES、DOC-SENTENCE分别表示不同的构造输入数据的方式,RoBERTa使用了FULL-SENTENCES,并且去掉了NSP任务。
FULL-SENTENCES表示从一篇文章或者多篇文章中连续抽取句子,填充到模型输入序列中。也就是说,一个输入序列有可能是跨越多个文章边界的。具体来讲,它会从一篇文章中连续地抽取句子填充输入序列,但是如果到了文章结尾,那么将会从下一个文章中继续抽取句子填充到该序列中,不同文章中的内容还是按照SEP分隔符进行分割。
采用BPE编码
Byte-Pair Encodeing(BPE)是一种表示单词,生成词表的方式。BERT中的BPE算法是基于字符的BPE算法,由它构造的”单词”往往位于字符和单词之间,常见的形式就是单词中的片段作为一个独立的”单词”,特别是对于那些比较长的单词。比如单词woderful有可能会被拆分成两个子单词”wonder”和”ful”。
不同于BERT,RoBERTa使用了基于Byte的BPE,词表中共计包含50K左右的单词,这种方式的不需要担心未登录词的出现,因为它会从Byte的层面去分解单词。
更大的数据
相比BERT, RoBERTa使用了更多的训练数据:

更长的训练步骤
RoBERTa随着训练数据和训练步数的增加,模型在down-stream的表现也不断提升。

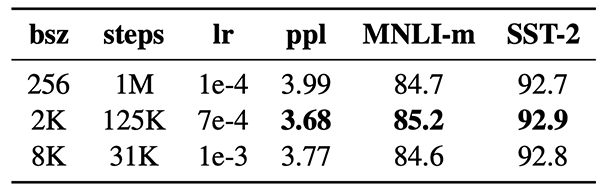
更大的batch size
RoBERTa通过增加训练过程中Batch Size的大小,来观看模型的在预训练任务和down-stream任务上的表现。发现增加Batch Size有利于降低保留的训练数据的Perplexity,提高down-stream的指标。
另外,RoBERTa参考transformer的改进,使用 β 1 \beta_1 β1=0.9, β 2 \beta_2 β2=0.999, ϵ \epsilon ϵ=1e-6,weight_decay_rate=0.01,num_warmup_steps=10000,init_lr=1e-4的自适应学习率的Adam优化器。
-
相关阅读:
【汇编】模块化程序——call指令和ret指令作用、具有子程序的源程序框架、mul乘法指令、8位与16位乘法、寄存器冲突问题
40 道Typescript 面试题及其答案与代码示例(上)
Eclipse切JRE环境后如何恢复- Unrecognized option: --enable-preview
LoRA大模型加速微调和训练算法解读
【K8s入门必看】第二篇 —— 快速部署集群指南
实现页面图片滑块效果
nvidia显卡驱动安装失败怎么办?
日期类练习题
Python丨tkinter开发常用的29种功能用法(建议码住)
七甲川荧光染料标记酸,Cy7 酸,Cy7-acid,CAS 943298-08-6参数及特性解析
- 原文地址:https://blog.csdn.net/weixin_49346755/article/details/126040391