-
MySQL 23道经典面试吊打面试官
1.说一说三大范式
-
「第一范式」:数据库中的字段具有**「原子性」**,不可再分,并且是单一职责
-
「第二范式」:「建立在第一范式的基础上」,第二范式要求数据库表中的每个实例或行必须**「可以被惟一地区分」**。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键
-
「第三范式」:「建立在第一,第二范式的基础上」,确保每列都和主键列直接相关,而不是间接相关不存在其他表的非主键信息
但是在我们的日常开发当中,「并不是所有的表一定要满足三大范式」,有时候冗余几个字段可以少关联几张表,带来的查询效率的提升有可能是质变的
2.MyISAM 与 InnoDB 的区别是什么?

-
- 「InnoDB支持事务,MyISAM不支持」。
-
- 「InnoDB 支持外键,而 MyISAM 不支持」。
-
- 「InnoDB是聚集索引」,使用B+Tree作为索引结构,数据文件是和索引绑在一起的,必须要有主键。「MyISAM是非聚集索引」,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
-
- 「InnoDB 不保存表的具体行数」。「MyISAM 用一个变量保存了整个表的行数」。
-
5.Innodb 有 「redolog」 日志文件,MyISAM 没有
-
6.「Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI」
-
-
Innodb:frm是表定义文件,ibd是数据文件
-
Myisam:frm是表定义文件,myd是数据文件,myi是索引文件
-
-
- 「InnoDB(没有使用索引时会查全表) 支持表、行锁,而 MyISAM 支持表级锁」
-
8、「InnoDB 必须有唯一索引(主键)」,如果没有指定的话 InnoDB 会自己生成一个隐藏列Row_id来充当默认主键,「MyISAM 可以没有」
3,redolog和binlog
(1)MySQL 分两层: Server (服务器) 层和引擎层。区别如下:
Server (服务器) 层:主要做的是 MySQL 功能层面的事情。 Server (服务器) 层也有自己的日志,称为 binlog(归档日志)
引擎层:负责存储相关的具体事宜。redo log 是 InnoDB 引擎特有的日志。
(2)redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
(3)redo log 是循环写的,空间固定会用完;
(4)binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
4什么时候不走索引(sql优化)
-
like这种模糊查询的时候,%在前面不走索引,%在后面走索引
-
用索引列计算的时候不走索引 比如:select * from student where age + 8 = 18
-
索引引用函数的时候不走索引 比如:select * from student where concat(‘name’,‘哈’) =‘王哈哈’
-
索引用了!=,not,in,or,not in的时候不走索引
-
null列的时候不走索引
-
数据库的类型转换了不走索引
-
组合索引的时候必须满足左匹配原则
-
查询的时候只想取一条数据,那么要用limit 1
5.left join、right join和inner join区别
-
left join和right join是一个外连接 inner join是自连接
-
left join 是查询左表全部,右表相同的数据
-
right join是查询右表全部,左表相同的数据
-
inner join是查询两表共同的数据,取交集
6.数据库索引包括
聚集索引(主键索引):数据库中,所有的行数都是按照主键索引进行排序、非聚集索引:给普通字段加索引、联合索引:好几个字段组成索引
数据库索引结构
主键索引、唯一索引、全文索引、普通索引、组合索引
uuid为什么不做主键
内容较长,是无序的,io查询的次数比较多,一级索引(主键索引)会和二级索引产生关联 除了主键索引以外都是二级索引,uuid可以看做是唯一索引,那么中间会有一个回表的操作除了一级索引不会回表,其他都会回表
1万条订单,有三种状态,那么这个状态适合设为索引吗
不适合,因为重复的数据太多,在建立索引的时候要保证 离散型强的一列(重复的数据少的,单一的)
7.覆盖索引
对于索引的覆盖,就是在查询的时候,不查询全部信息,查询的信息是设置了索引的,在这种情况下就是索引覆盖
例子:
student 表,给name设置 了索引
select * from student where name=‘王甜甜’
这种情况是不会造成索引覆盖的,中途有一个回表的操作 所以说不会造成索引的覆盖
select name from student where name=‘王甜甜’
这种情况是会造成索引的覆盖的。因为name是索引,不需要回表操作的就是索引覆盖
8.什么是回表

回表就是先通过数据库索引扫描出该索引树中数据所在的行,取到主键 id,再通过主键 id 取出主键索引数中的数据,即基于非主键索引的查询需要多扫描一棵索引树.
9.什么是事务其特性是什么
事务是指是程序中一系列操作必须全部成功完成,有一个失败则全部失败。

特性
-
「1.原子性(Atomicity)」:要么全部执行成功,要么全部不执行。
-
「2.一致性(Consistency)」:事务前后数据的完整性必须保持一致。
-
「3.隔离性(Isolation)」:隔离性是当多个事务同事触发时,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
-
「4.持久性(Durability)」:事务完成之后的改变是永久的。
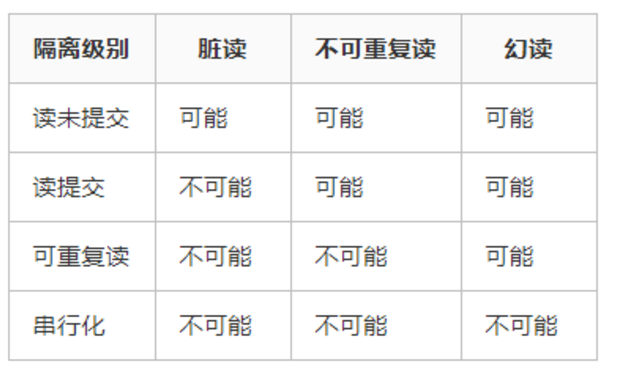
10.事务的隔离级别
-
1.「读提交」:即能够**「读取到那些已经提交」**的数据
-
2.「读未提交」:即能够**「读取到没有被提交」**的数据
-
3.「可重复读」:可重复读指的是在一个事务内,最开始读到的数据和事务结束前的**「任意时刻读到的同一批数据都是一致的」**
-
4.「可串行化」:最高事务隔离级别,不管多少事务,都是**「依次按序一个一个执行」**
-
「脏读」
-
- 脏读指的是**「读到了其他事务未提交的数据」**,未提交意味着这些数据可能会回滚,也就是可能最终不会存到数据库中,也就是不存在的数据。读到了并一定最终存在的数据,这就是脏读
-
「不可重复读」
-
- 对比可重复读,不可重复读指的是在同一事务内,「不同的时刻读到的同一批数据可能是不一样的」。
-
「幻读」
-
- 幻读是针对数据插入(INSERT)操作来说的。假设事务A对某些行的内容作了更改,但是还未提交,此时事务B插入了与事务A更改前的记录相同的记录行,并且在事务A提交之前先提交了,而这时,在事务A中查询,会发现**「好像刚刚的更改对于某些数据未起作用」**,但其实是事务B刚插入进来的这就叫幻读
11.一条 Sql 语句查询一直慢会是什么原因

-
「1.没有用到索引」
-
- 比如函数导致的索引失效,或者本身就没有加索引
-
「2.表数据量太大」
-
- 考虑分库分表吧
-
「3.优化器选错了索引」
-
- 「考虑使用」 force index 强制走索引
12.一条 Sql 语句查询偶尔慢会是什么原因

-
「1. 数据库在刷新脏页」
-
- 比如 「redolog 写满了」,**「内存不够用了」**释放内存如果是脏页也需要刷,mysql 「正常空闲状态刷脏页」
-
「2. 没有拿到锁」
13.主从复制主要有以下流程:
-
master服务器将数据的改变记录到binlog中;
-
slave服务器会在一定时间间隔内对master 的binlog进行检查,如果发生改变,则开始一个 I/O Thread 请求读取 master 中 binlog;
-
同时主节点为每个 I/O 线程启动一个dump线程,用于向其发送二进制日志,并保存至从节点本地的中继日志中,从节点将启动 SQL 线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后 I/O Thread和 SQL Thread将进入睡眠状态,等待下一次被唤醒;
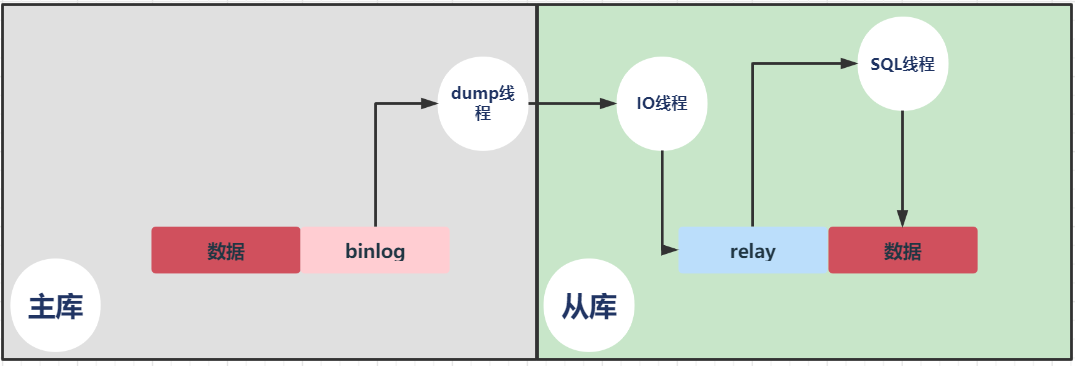
大白话就是:
从库会生成两个线程,一个I/O线程,一个SQL线程;
I/O线程会去请求主库的binlog,并将得到的binlog写到本地的relay-log(中继日志)文件中;
主库会生成一个dump线程,用来给从库I/O线程传binlog;
SQL线程,会读取relay log文件中的日志,并解析成sql语句逐一执行;
主从复制存在数据丢失问题的解决方案:在使用过程中需要开启半同步复制;
主从复制的使用场景主要有以下两种:HA、读写分离。
高可用(HA)架构:
MySQL的高可用由互为主从的MySQL构成,平时只有主库提供服务,备库不提供服务。当主库停止服务时,服务自动切换到备库。
-
MHA管理工具 MHA存在Manager、Node两种节点;Manager节点通过探测Node节点去判断 MySQL运行是否正常,如果发现 Master故障。
-
就把他的一个Slave提升为Master,然后剩余Slave都挂到新的Master。
-
LVS+Keepalived
Keepalived可以进行检查心跳和动态漂移;当Master节点出现异常主服务所在keepalived会发出通知,然后slave节点的keepalived通知从节点切换为master。
读写分离架构:
高并发下读写分离会出现数据延迟问题。
解决方案如下:
-
分库分表;
-
开启并行复制;
-
在业务逻辑上避免;
补充资料:
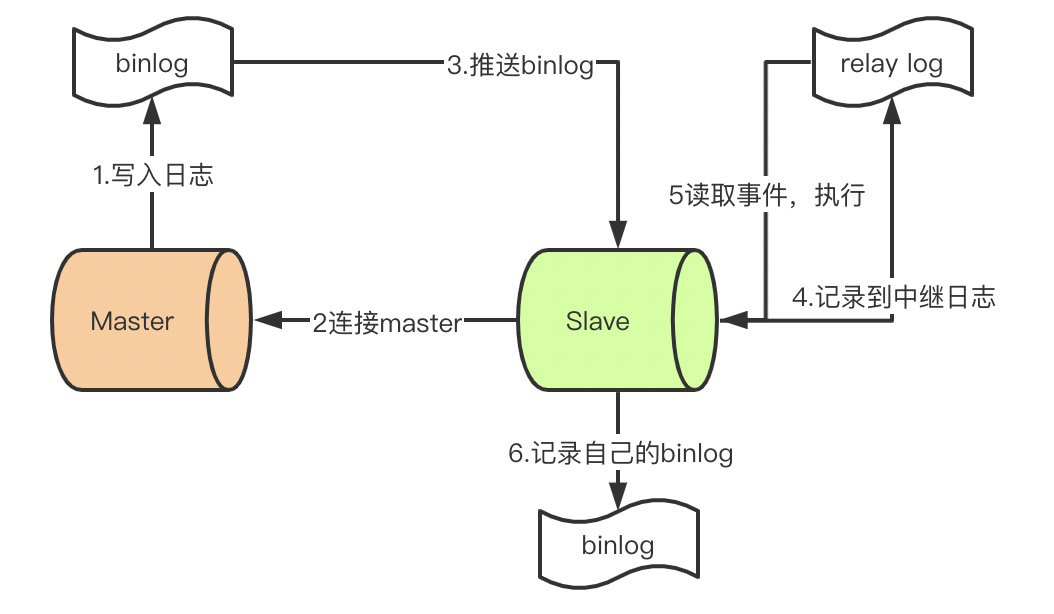
(以下MySQL 主从同步的原理的补充资料来自艾小仙)
-
master提交完事务后,写入binlog。
-
slave连接到master,获取binlog。
-
master创建dump线程,推送binglog到slave。
-
slave启动一个IO线程读取同步过来的master的binlog,记录到relay log中继日志中。
-
slave再开启一个sql线程读取relay log事件并在slave执行,完成同步。
-
slave记录自己的binglog。
由于mysql默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理,这样会产生一个问题就是假设主库挂了,从库处理失败了,这时候从库升为主库后,日志就丢失了。由此产生两个概念。
全同步复制
主库写入binlog后强制同步日志到从库,所有的从库都执行完成后才返回给客户端,但是很显然这个方式的话性能会受到严重影响。
半同步复制
和全同步不同的是,半同步复制的逻辑是这样,从库写入日志成功后返回ACK确认给主库,主库收到至少一个从库的确认就认为写操作完成。
-
14.主从延迟要怎么解决
-
1.MySQL 5.6 版本以后,提供了一种**「并行复制」**的方式,通过将 SQL 线程转换为多个 work 线程来进行重放
-
2.「提高机器配置」(王道)
-
3.在业务初期就选择合适的分库、分表策略,**「避免单表单库过大」**带来额外的复制压力
-
4.「避免长事务」
-
5.「避免让数据库进行各种大量运算」
-
6.对于一些对延迟很敏感的业务**「直接使用主库读」**
15.删除表数据后表的大小却没有变动,这是为什么
在使用 delete 删除数据时,其实对应的数据行并不是真正的删除,是**「逻辑删除」,InnoDB 仅仅是将其「标记成可复用的状态」**,所以表空间不会变小
16.为什么 VarChar 建议不要超过255

当定义varchar长度小于等于255时,长度标识位需要一个字节(utf-8编码)
当大于255时,长度标识位需要两个字节,并且建立的**「索引也会失效」**
17.Mysql 中有哪些锁
以下并不全,主要理解下锁的意义即可
-
基于锁的属性分类:共享锁、排他锁
-
基于锁的粒度分类:表锁、行锁、记录锁、间隙锁、临键锁
-
基于锁的状态分类:意向共享锁、意向排它锁、死锁
18.说说你的 Sql 调优思路吧

-
1.「表结构优化」
-
-
1.1拆分字段
-
1.2字段类型的选择
-
1.3字段类型大小的限制
-
1.4合理的增加冗余字段
-
1.5新建字段一定要有默认值
-
-
2.「索引方面」
-
-
2.1索引字段的选择
-
2.2利用好mysql支持的索引下推,覆盖索引等功能
-
2.3唯一索引和普通索引的选择
-
-
3.「查询语句方面」
-
-
3.1避免索引失效
-
3.2合理的书写where条件字段顺序
-
3.3小表驱动大表
-
3.4可以使用force index()防止优化器选错索引
-
-
4.「分库分表」
19.什么是索引
相信大家小时候学习汉字的时候都会查字典,想想你查字典的步骤,我们是通过汉字的首字母 a~z 一个一个在字典目录中查找,最终找到该字的页数。想想,如果没有目录会怎么样,最差的结果是你有可能翻到字典的最后一页才找到你想要找的字。
索引就**「相当于我们字典中的目录」**,可以极大的提高我们在数据库的查询效率。
20.说说创建索引的优势,负面影响和原则
1.索引的优势,检索速度快
2.缺点创建索引和维护索引需要耗费时间占空间:索引需要占用物理空间
3,创建索引的原则,在最频繁操作的字段进行创建索引,比如id
4什么情况下不适合创建索引:对于一个字段的值重复比较多的时候,
21.为什么采用 B+ 树,而不是 B-树
B+ 树只在叶子结点储存数据,非叶子结点不存具体数据,只存 key,查询更稳定,增大了广度,而一个节点就是磁盘一个内存页,内存页大小固定,那么相比 B 树,B- 树这些**「可以存更多的索引结点」**,宽度更大,树高矮,节点小,拉取一次数据的磁盘 IO 次数少,并且 B+ 树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,效率更高。
22.说下 MySQL 中的 MVCC 机制?
#每天一道面试题# 50
#悟空拧螺丝# 2021-09-03
引入undo日志、roll_pointer、trx_id三个概念:
undo日志:事务回滚时恢复数据到未变更状态,每次执行增、删、改操作时都会记录变更前的原始数据到undo日志;
roll_pointer属性:表记录的隐藏字段;
trx_id属性:表记录隐藏字段表示事务ID;
设想一个场景数据库,两个不同用户分别读取和修改同一条数据,为了保证数据的正确性;数据库需要引入读锁、写锁,在读数据加读锁禁止写操作,写数据加写锁禁止读操作,这么做会影响数据性能;
MVCC:引入版本链机制解决读写并发访问问题,由于每次对数据进行增、删、改操作都会备份数据到undo中,因此如果某个记录被多次修改会存在多个版本数据,这些版本信息之间通过roll_pointer属性连成一个链表;在RR级别下,数据记录具有可重复读特性,即在同一个事务执行的过程中对某条数据执行查询(快照读)操作,然后间隔几秒钟继续查询(快照读)数据记录不会发生变化,哪怕在间隔的几秒钟有其它事务对该记录进行了修改操作。
MySQL 中有四种隔离级别,Read Repeatable (RR)级别可以防止脏读、不可重复读、幻读问题。Read Committed (RC)级别解决了脏读问题。
那它是怎么做到的呢?就是利用了 MVCC 多版本控制机制。而且可以实现 读-写,写-读不冲突。
本解答尽量通俗易懂:
多版本
就是有多个某行记录更新后的版本,然后将这些版本从上到下串起来。有点像串糖葫芦,这个就是版本链。
比如说银行转账记录,将多次对账户的修改都串起来了。记录里面有是哪个事务做的转账记录,最后值等于多少。
(1)账户 A = 初始值 200元,事务 id = 40 ->
(2)账户 A = 初始值 200元 + 100 元 = 300 元,事务 id = 51 ->
(3)账户 A = 300 元 + 50 元 = 350 元,事务 id = 59 ->
(4)账户 A = 350 元 - 30 元 = 320 元,事务 id = 72
在 MySQL 就是利用 undo log 日志将这些串起来的。
如下图所示,undolog 的版本串起来长这样:

控制
用自身的事务 id 和其他地方存的事务 id 进行比较,看是否符合读取版本链上的条件,如果符合,读取后就返回了。 怎么控制的呢?利用 ReadView。ReadView 其实也不难理解,就是对当前活跃事务的一个统计。然后 MySQL 利用这个数据统计 + 版本链上的事务 id 来进行比较,获得某个可读到的版本。
ReadView
保证你只能读到事务开启之前,别的事务提交的值,或者自己提交的值。其他情况下无法读取到其他事务提交的值,避免了脏读。
ReadView 生成时机?
每个事务执行查询时都会生成自己事务的 ReadView。 RC 级别是每次查询都会重新生成一份,RR 级别是事务中的 ReadView 都不变。
ReadView 里面有四个重要的属性:
m_ids 事务列表:有哪些事务在MySQL里执行还没提交的; min_trx_id 最小事务 id:m_ids 列表中最小的值 ; max_trx_id 最大事务 id:下一个要生成的事务id,就是最大事务id; creator_trx_id:当前事务的 id。
这四个属性怎么用的呢?
比如说事务 A 用来查询,事务 B 用来更新,它俩都开启了事务,也都还没有提交,对应的事务 id 分别为 51 和 59,那么 ReadView 就长这样:

活跃事务列表就是 [51,59]。不是一个区间,只有两个值 51 和 59。另外图中的 B 事务 id 应该改为 59。
最小事务 id = 51。
最大事务 id = 59+1 = 60。
当前事务 id = 51。
事务 A 首先拿着这几个属性值,到版本链上一个一个比较版本上的事务 id,符合条件就返回。比较又分三种情况:
-
1、如果版本上的事务 id < 最小值 51,说明这个行记录在这些活跃的事务创建前就已经提交了,这个行记录的版本对于当前事务 A 是可见的,就返回了。
-
2、如果版本上的事务 id >= 最大值 60,则说明提交的事务是 ReadView 生成之后创建的,这个版本也是不可读的,就接着往下找。
-
3、如果版本上的事务 id 在在最小和最大值之间,就进行下一步判断:
-
3.1、如果版本上的事务 id 在这个列表 [51,59] 里面,这个列表其实就两个值,51 和 59,只要等于 51 或者 59,就说明不在列表中。说明提交的事务是和 A 事务差不多时间开启的事务,被 ReadView 记录在列表里面了。这种事务提交的版本也是不可读的,就接着往下找。(避免了脏读)
-
3.2、如果不在这个列表 [51,59] 里面(不等于 51 和 59),说明事务已提交了,是可以读取的,读到了就返回。
-
RC 的读已提交怎么做到的?
我们说 RC 隔离级别下,事务 A 下次查询时,就可以读到其他事务提交的数据了(读已提交),但是根据上面的3.1 的情况来看,事务 A 是读取不到事务 B 提交的呀?
这就需要在 A 查询时重新生成一个 ReadView 了,来看下重新生成的长啥样:
活跃事务列表就是 [51]。
最小事务 id = 51。
最大事务 id = 60。注意:这是 MySQL 下一个要生成的事务 id,不是指活跃事务中的最大事务 id。
当前事务 id = 51。
看到了吗?
事务 B 的 事务 id 59 不在活跃事务列表啦!但是又是小于最大事务 id 60 的。这就符合 3.2 的情况啦,可以读到这个版本了。
那下次 事务 A 再次查询时,又会生成一个 ReadView,可以读到其他事务提交的数据,这个数据和上次的数据很有可能不一样,也就是说不能保证每次读到的数据一样的,这就是不可重复读。 RR 的可重复读怎么做到的?
它和 RC 不同的地方在于,事务 A 查询时,是不会重新生成 ReadView 的,也就是说 B 提交的事务读取不到的,那就顺着版本链继续找呗。找着找着就只能读事务 A 自己提交的,或者事务开启之前,其他事务提交的,那么事务 A 每次查询都是读到一样的数据啦,但是读取的都不是最新的数据,这就是可重复读,避免了读取数据不一致的情况。
注意:不管其他事务怎么修改数据,事务 A 生成的 ReadView 是不会改变的,基于这个 ReadView 看到的值都是一样的!
RR 的幻读是怎么避免的?
比如 A 执行范围查询:select * from table where age > 10,查到了一条数据 X。然后事务 C 72 插入了一条数据,事务 A 再次查询时,可以查到两条数据 X 和 Y。但是 Y 的版本链上事务 id 等于 72,大于最大事务 id 60,说明是事务 A 发起查询后,当然是不可读到的了,所以事务 A 还是只能读到数据 X。
小结
通过版本链 + ReadView 做到了这些事情: 避免了 RR 隔离级别下的脏读、不可重复度、幻读问题。 避免了 RC 隔离级别下的脏读问题,实现了读取已提交数据的功能。
23.生成唯一ID的雪花算法
snowflake(雪花算法):Twitter 开源的分布式 id 生成算法,64 位的 long 型的 id,分为 4 部分:
-
1 bit:不用,统一为 0
-
41 bits:毫秒时间戳,可以表示 69 年的时间。
-
10 bits:5 bits 代表机房 id,5 个 bits 代表机器 id。最多代表 32 个机房,每个机房最多代表 32 台机器。
-
12 bits:同一毫秒内的 id,最多 4096 个不同 id,自增模式
优点:
-
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
-
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
-
可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨(可以搜索 2017 年闰秒 7:59:60),会导致发号重复或者服务会处于不可用状态。
-
-
相关阅读:
Unity中Shader矩阵的乘法
服务器内存不足的原因
移动平台助力推进智慧型科研院所信息化建设
使用qemu运行risc-v ubuntu
合成孔径雷达地面运动目标检测技术研究——基于概率图(Matlab代码实现)
Linux上部署net6应用
Python之基础数据类型(二)
Kafka: Windows环境-单机部署和伪集群、集群部署
大模型技术实践(三)|用LangChain和Llama 2打造心灵疗愈机器人
c++ condition_variable使用场景
- 原文地址:https://blog.csdn.net/m0_67391907/article/details/126035362