-
【指针内功修炼】字符指针 + 指针数组 + 数组指针 + 指针参数(一)

🌟前言
关于 指针 的原理,我们在初级阶段的《指针》文章中已经接触过了,我们知道了指针的概念:
1、指针就是个变量,用来存放地址,地址唯一标识一块内存空间。
2、指针的大小是固定的 4 / 8 个字节(32 位平台 / 64 位平台)。
3、指针是有类型,指针的类型决定了指针的 加减 整数的步长,指针解引用操作的时候的权限。
4、指针的运算。
本篇文章,我们继续探讨指针的高级原理。1. 字符指针
在指针的类型中我们知道有一种指针类型为 字符指针:
char*一般的使用方法如下:
int main() { char ch = 'h'; char* pc = &ch; *pc = 'c'; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
还有一种使用方式如下:
int main() { char* pstr = "hello world!"; printf("%s\n", pstr); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
思考:
代码:
char* pstr = "hello world!";
这里是把一个字符串放到 pstr 指针变量里了吗?答案:
这句代码特别容易让别人以为是把字符串 hello world! 放到字符指针 pstr 里了;
但是本质还是把字符串 hello world! 首字符的地址放到了 pstr 中。

如上图所示,字符串的首字符 h 的地址存放到指针变量 pstr 中是不是很简单?那么我们来分析下面这段代码👇
int main() { char arr1[] = "abcdef"; char arr2[] = "abcdef"; const char* str1 = "abcdef"; const char* str2 = "abcdef"; if (arr1 == arr2) printf("arr1==arr2\n"); else printf("arr1!=arr2\n"); if (str1 == str2) printf("str1==str2\n"); else printf("str1!=str2\n"); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
那么这段代码的打印结果是什么呢?如下👇

那为什么会是这样呢?我们来分析一下
首先,我们在内存中放了 2 个数组:arr1 和 arr2
因为 arr1 和 arr2 是两个完全不同的数组,数组名代表首元素的地址,所以 arr1 和 arr2 表示的地址完全不同(尽管数组元素相同),这是两块内存中不同的空间,所以起始地址肯定不同,所以arr1 !=a rr2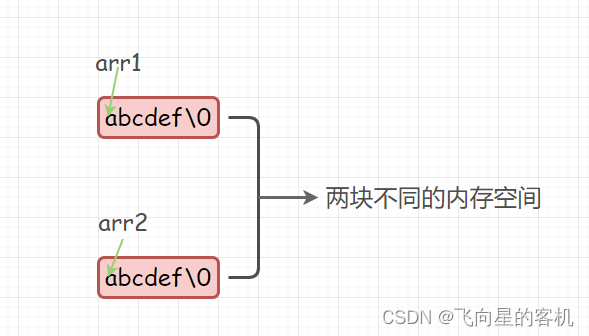
紧接着,我们内存中有个常量字符串"abcdef", 它是存储在内存的只读数据区的,然后我定义了一个指针 str1 用来存放它的地址;
那么我们的 str2 是不是也和 str1 一样,在内存中开辟了一个"abcdef"呢?
注意 str1 和 str2 都是const修饰的常量字符串,并且常量字符串不能修改,所以 str1 和 str2 都指向同一个字符串。

所以当我两个指针分别指向一个常量字符串,并且常量字符串一样时,只需要保存一份字符串就可以了,这样在一定程度上,会让内存的利用率更高!总结:
这里 str1 和 str2 指向的是一个同一个常量字符串。C/C++ 会把常量字符串存储到单独的一个内存区域,当几个指针指向同一个字符串的时候,他们实际会指向同一块内存。
但是用相同的常量字符串去初始化不同的数组的时候就会开辟出不同的内存块。所以 arr1 和 arr2 不同,str1 和 str2 相同。2. 指针数组
在《指针》章节我们也学了指针数组,指针数组是一个存放指针的数组。
这里我们再复习一下,下面指针数组是什么意思?
int* arr1[10]; // 整形指针的数组 char* arr2[4]; // 一级字符指针的数组 char** arr3[5]; // 二级字符指针的数组- 1
- 2
- 3
- 4
- 5
看到这里可能还会有点懵,别急,再举几个例子
示例一
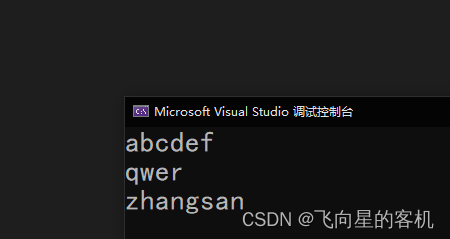
int main() { char* arr[] = { "abcdef", "qwer", "zhangsan" }; int i = 0; int sz = sizeof(arr) / sizeof(arr[0]); for (i = 0; i < sz; i++) { printf("%s\n", arr[i]); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
解释:
首先我们定义了一个 char* 的数组,它在内存中的布局是这样的👇

那我们能不能打印出来呢?运行看看结果👇
示例二
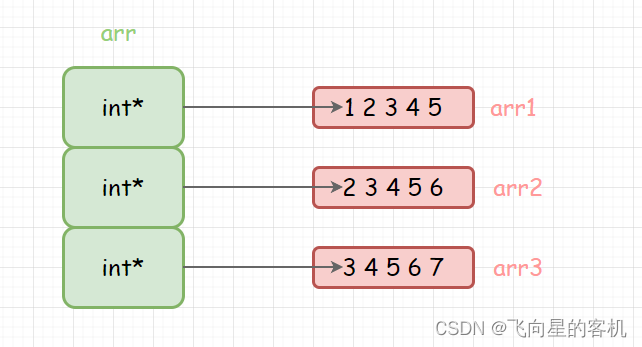
int main() { int arr1[] = { 1,2,3,4,5 }; int arr2[] = { 2,3,4,5,6 }; int arr3[] = { 3,4,5,6,7 }; int* arr[] = {arr1, arr2, arr3}; int i = 0; for (i = 0; i < 3; i++) { int j = 0; for (j = 0; j < 5; j++) { printf("%d ", arr[i][j]);// *(*(arr+i)+j) } printf("\n"); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
解释:
它在内存中的布局是这样的👇
运行结果👇

总结:存放指针的数组就是指针数组
3. 数组指针
🍑 数组指针的定义
数组指针是指针?还是数组?
答案是:指针
我们已经熟悉:
整形指针:
int * pint;能够指向 整形 数据的指针。浮点型指针:
float * pf;能够指向 浮点型 数据的指针。那数组指针应该是:能够指向数组的指针。
那我们分析下面的代码,那个是数组指针呢?
int *p1[10]; int (*p2)[10]; //p1, p2分别是什么?- 1
- 2
- 3
- 4
- 5
解释:
int *p1[10]:p1 首先和[ ]结合,那么它就是一个数组,并且有 10 个元素,每个元素是int*的类型,那么这个数组就是一个存放指针的数组,所以它就是一个 指针数组。
int (*p2)[10]:p2 先和*结合,说明 p 是一个指针变量,然后往后指向的是一个大小为 10 个整型的数组。所以 p2 是一个指针,指向一个数组,叫 数组指针。
注意:[ ]的优先级要高于*号的,所以必须加上( )来保证 p2 先和*结合。🍑 &数组名 VS 数组名
对于下面的数组:
int main() { int arr[10] = { 0 }; printf("%p\n", arr); printf("%p\n", &(arr[0])); printf("%p\n", &arr); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
arr 和 &arr 分别是啥?
我们知道 arr 是数组名,数组名表示数组首元素的地址。
那 &arr 数组名到底是啥?
我们直接打印看下结果

我们发现这三个值竟然一样?我们知道
arr和&(arr[0])都表示数组首元素的地址那么
&arr呢?我们重新升级一下代码👇int main() { int arr[10] = { 0 }; printf("%p\n", arr); printf("%p\n", arr+1); printf("%p\n", &(arr[0])); printf("%p\n", &(arr[0])+1); printf("%p\n", &arr); printf("%p\n", &arr+1); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们再来看看打印的效果是啥👇

可以看到arr+1和&(arr[0])+1都是跳过 1 个int类型的元素,也就是 4 个字节;但是
&arr+1却不是跳过 1 个 ** int** 类型了,而是和&arr差了 28(这里的 28 是用十六进制表示的),换算成十进制也就是 40。所以我们得出结论:
&arr+1跳过了 整个数组 的大小,我们定义的 arr 数组有 10 个元素,每个元素都是 int 类型,所以一共是 40 字节大小;🍑 数组指针的使用
那数组指针是怎么使用的呢?
既然数组指针指向的是数组,那数组指针中存放的应该是数组的地址。
示例一
int main() { char arr[5]; char (*pa)[5] = &arr; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
pa 就是指向字符数组的指针;
示例二
int main() { int* parr[6]; int* (*pp)[6] = &parr; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
pp 就是指向整型数组的指针,pp 的类型就是
int* (*)[6](把数组名去掉,剩下的就是类型)

那么数组指针怎么使用呢?
假设有下面这段代码👇
int main() { int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; int*p = arr; int i = 0; for (i = 0; i < 10; i++) { printf("%d ", *(p + i)); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上面这段代码就是打印数组中的元素

但是有同学可能想,假设我偏要用 数组指针 打印一维数组呢?其实也不是不可以,就是使用起来很别扭,代码如下👇
int main() { int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; int (*p)[10] = &arr; int i = 0; for (i = 0; i < 10; i++) { printf("%d ", *((*p) + i)); } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当然打印结果肯定也是一样的啦

但是,我们在一般情况下,根本不会使用 数组指针 去打印一维数组,更多的是在 二维数组 中去使用一般情况下,我们打印 二维数组 都是像下面这样写的
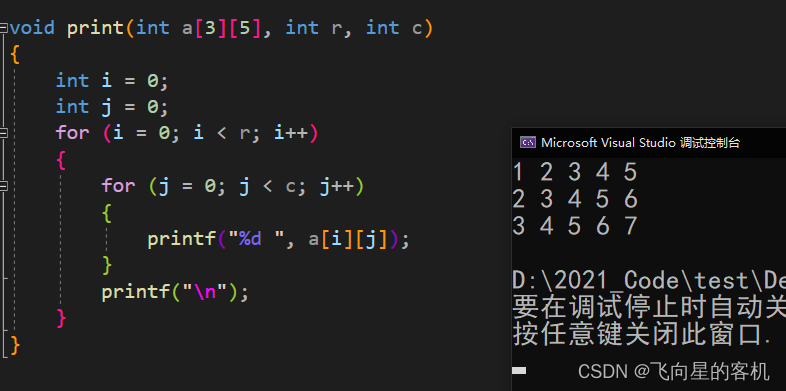
void print(int a[3][5], int r, int c) { int i = 0; int j = 0; for (i = 0; i < r; i++) { for (j = 0; j < c; j++) { printf("%d ", a[i][j]); } printf("\n"); } } int main() { int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} }; print(arr,3,5); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
数组传参的时候,我们拿数组接受,这种写法当然是没问题的
那如果我们想换一种方法,该怎么写呢?我们知道,二维数组中数组名也表示首元素的地址,二维数组的首元素是:第一行
所以,我们直接拿 数组指针 接收
void print(int(*p)[5], int r, int c) { int i = 0; for (i = 0; i < r; i++) { int j = 0; for (j = 0; j < c; j++) { printf("%d ", *(*(p + i) + j)); } printf("\n"); } } int main() { int arr[3][5] = { {1,2,3,4,5},{2,3,4,5,6},{3,4,5,6,7} }; print(arr, 3, 5); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
那么如何理解呢?

并且arr[i]==*(arr+i)==p[i]==*(p+i)是不是很简单?
学了 指针数组 和 数组指针 我们来一起回顾并看看下面代码的意思:
int arr[5]; int *parr1[10]; int (*parr2)[10]; int (*parr3[10])[5];- 1
- 2
- 3
- 4
1、arr 是一个整型数组,有 5 个元素,每个元素是 int 类型
2、parr1 是一个数组,数组有 10 个元素,每个元素的类型是
int*3、parr2 和
*结合,说明 parr2 是一个指针,该指针指向一个数组,数组是 10 个元素,每个元素是 int 类型,所以 parr2 是数组指针4、parr3 和
[ ]结合,说明 parr3 是一个数组,数组是 10 个元素,数组的每个元素是int(*)[5],该类型的指针指向的数组有 5 个 int 类型的元素。

总结
数组名是什么?数组名其实就是个地址
4. 数组参数、指针参数
在写代码的时候难免要把【数组】或者【指针】传给函数,那函数的参数该如何设计呢?
🍑 一维数组传参
我们来分析下面这段代码
void test(int arr[]) //ok? {} void test(int arr[10]) //ok? {} void test(int* arr) //ok? {} void test2(int* arr[20]) //ok? {} void test2(int** arr) //ok? {} int main() { int arr[10] = { 0 }; int* arr2[20] = { 0 }; test(arr); test2(arr2); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
arr 是一个整型数组,arr2 是指针数组;
首先我们对 arr 进行数组传参,第一个 test 函数用
int arr[ ]来接收,完全是没问题的,数组传参,用数组来接收;第二个 test 函数,用
int arr[10]来接收,也是可以的,数组传参的时候,形参写出数组形式;第三个 test 函数,用一个指针来接收,因为数组传参传的数组首元素的地址,所以形参的部分我们用指针来接收;
第四个 test2 函数,数组传参,形参部分写成数组,也是可以的;
第五个 test2 函数,数组名代表首元素的地址,arr2 相当于
int*的地址,所以形参部分拿一个二级指针来接收,也是可以的。🍑 二维数组传参
我们来分析下面这段代码
void test(int arr[3][5])//ok? {} void test(int arr[][])//ok? {} void test(int arr[][5])//ok? {} void test(int* arr)//ok? {} void test(int* arr[5])//ok? {} void test(int(*arr)[5])//ok? {} void test(int** arr)//ok? {} int main() { int arr[3][5] = { 0 }; test(arr); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
我们定义了一个 3 行 5 列的二维数组👇

第一个 test 函数,形参写成int arr[3][5],完全没问题;第二个 test 函数,形参写成
int arr[][]是不可以的,二维数组传参,函数形参的设计只能省略第一个[ ]的数字。因为对一个二维数组,可以不知道有多少行,但是必须知道一行多少元素。这样才方便运算。第三个 test 函数,形参写成
int arr[][5],省略了 行 ,完全是可以的;第四个 test 函数,首先在
mian函数里,我们传过去的是数组名,数组名是首元素的地址。所以传过去的是第一行的地址,第一行是 5 个整型元素的地址,那么就应该放在数组指针里面去,所以这种写法int* arr肯定是错误的;第五个 test函数,
int* arr[5],arr 和后面的[ ]结合,它是一个数组,而我们需要的一个指针,所以这种写法错误;第六个 test 函数,
int(*arr)[5]就是我们的数组指针,完全正确;最后一个 test 函数,形参肯定不能拿二级指针接收,错误。
🍑 一级指针传参
分析下面代码
#includevoid print(int* p, int sz) { int i = 0; for (i = 0; i < sz; i++) { printf("%d\n", *(p + i)); } } int main() { int arr[10] = { 1,2,3,4,5,6,7,8,9 }; int* p = arr; int sz = sizeof(arr) / sizeof(arr[0]); print(p, sz); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
这段代码很简单,一级指针 p,传给函数 print,形参用指针接收;
因为数组传参,形参部分可以写成数组,也可以写成指针;但是指针传参时,形参也要写成指针。
那么,思考下面这个问题🤔
当一个函数的参数部分为一级指针的时候,函数能接收什么参数?
代码如下👇
void test(int* p) {} int main() { int a = 10; int* ptr = &a; int arr[10] = {0}; test(&a); test(ptr); test(arr); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
所以,当 函数的参数部分 为一级指针的时候,函数可以传 地址、指针、数组名。
🍑 二级指针传参
分析下面这段代码
#includevoid test(int** ptr) { printf("num = %d\n", **ptr); } int main() { int n = 10; int*p = &n; int **pp = &p; test(pp); test(&p); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
二级指针传参,用二级指针接收;一级指针的地址传参,拿二级指针接收,也是没问题的。
那么,思考下面这个问题🤔
当函数的参数为二级指针的时候,可以接收什么参数?
代码如下👇
void test(char** p) {} int main() { char ch = 'w'; char* p = &ch; char** pp = &p; char* arr[5]; test(&p); test(pp); test(arr); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
所以,当 函数的参数 为 二级指针 的时候,函数可以传 一级指针的地址、二级指针、指针数组名
-
相关阅读:
Java内存区域及类加载详解
计算机毕业设计springboot家居产品的进销存系统dgo68源码+系统+程序+lw文档+部署
Vue常见问题
Linux高并发服务器开发(六)线程
牛客CM11 - 链表分割【环形链表雏形】
leetcode做题笔记2216. 美化数组的最少删除数
SpringCloud(十)——ElasticSearch简单了解(二)DSL查询语句及RestClient查询文档
neo4j安装使用(windows10)
有一个项目管理软件,名字叫8Manage PM!
nginx主要作用三个(虚拟主机+反向代理+upsteam调度分发)
- 原文地址:https://blog.csdn.net/m0_63325890/article/details/125460201
