-
【三年面试五年模拟】算法工程师的独孤九剑秘籍(前六式汇总篇)V1版

Rocky Ding 公众号:WeThinkIn 写在前面
【三年面试五年模拟】栏目专注于分享CV算法与机器学习相关的经典&&必备&&高价值的面试知识点,并向着更实战,更真实,更从容的方向不断优化迭代。也欢迎大家提出宝贵的意见或优化ideas,一起交流学习💪
大家好,我是Rocky。
本文是“三年面试五年模拟”之独孤九剑秘籍的特别系列,我们将独孤九剑秘籍前六式进行汇总梳理成汇总篇,并制作成pdf版本,大家可在公众号后台取用。由于本文以及pdf版本都是Rocky在工作之余进行整理总结,难免有疏漏与错误之处,欢迎大家对可优化的部分进行指正,我将在后续的优化迭代版本中及时更正。
Rocky也一致在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于CV算法,算法,开发,IT技术等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请关注公众号并在后台扫描二维码进群;若二维码失效,请加我微信,我拉你进群~)
在【人人都是算法工程师】算法工程师的“三年面试五年模拟”之独孤九剑秘籍(先行版)中我们阐述了这个program的愿景与规划。
希望独孤九剑秘籍的每一式都能让江湖中的英雄豪杰获益。
So,enjoy:
干货篇
----【目录先行】---- 深度学习基础:
-
卷积有什么特点?
-
不同层次的卷积都提取什么类型的特征?
-
卷积核大小如何选取?
-
卷积感受野的相关概念
-
网络每一层是否只能用一种尺寸的卷积核?
-
1 ∗ 1 1*1 1∗1 卷积的作用?
-
转置卷积的作用?
-
空洞卷积的作用?
-
全连接层的作用?
-
CNN中池化的作用?
-
有哪些方法能提升CNN模型的泛化能力?
-
BN层面试高频问题大汇总
经典模型&&热门模型:
-
目标检测中IOU的相关概念与计算
-
目标检测中NMS的相关概念与计算
-
One-stage目标检测与Two-stage目标检测的区别?
-
哪些方法可以提升小目标检测的效果?
-
ResNet模型的特点以及解决的问题?
-
ResNeXt模型的结构和特点?
-
MobileNet系列模型的结构和特点?(二)
-
ViT(Vision Transformer)模型的结构和特点?
-
MobileNet系列模型的结构和特点?
-
EfficientNet系列模型的结构和特点?
-
面试常问的经典模型?
机器学习基础:
-
什么是模型的偏差和方差?
-
数据类别不平衡怎么处理?
-
什么是过拟合,解决过拟合的方法有哪些?
-
什么是欠拟合,解决欠拟合的方法有哪些?
-
常用的距离度量方法
-
正则化的本质以及常用正则化手段?
-
L范数的作用?
-
Dropout的作用?
-
Softmax的定义和作用
-
交叉熵定义和作用
-
训练集/验证集/测试集划分
-
如何找到让F1最高的分类阈值?
数据结构&&算法:
-
常用数据结构的相关知识
-
二叉树遍历(递归)模版
-
不同排序算法的异同?
-
树有哪些遍历模式?
Python/C/C++知识:
-
Python中迭代器的概念?
-
Python中生成器的相关知识
-
Python中装饰器的相关知识
-
Python的深拷贝与浅拷贝?
-
Python是解释语言还是编译语言?
-
Python的垃圾回收机制
-
Python里有多线程吗?
-
Python中range和xrange的区别?
-
Python中列表和元组的区别?
-
Python中dict(字典)的底层结构?
-
常用的深度学习框架有哪些,都是哪家公司开发的?
-
PyTorch动态图和TensorFlow静态图的区别?
-
C/C++中面向对象的相关知识
-
C/C++中struct的内存对齐与内存占用计算?
-
C/C++中智能指针的定义与作用?
-
C/C++中程序的开发流程?
-
C/C++中数组和链表的优缺点?
-
C/C++中的new和malloc有什么区别?
模型部署:
-
模型压缩的必要性与可行性?
-
X86和ARM架构在深度学习侧的区别?
-
FP32,FP16以及Int8的区别?
-
GPU显存占用和GPU利用率的定义
-
神经网络的显存占用分析
-
算法模型部署逻辑?
-
影响模型inference速度的因素?
-
为何在AI端侧设备一般不使用传统图像算法?
-
减小模型内存占用有哪些办法?
-
有哪些经典的轻量化网络?
-
模型参数计算?
-
模型FLOPs怎么算?
图像处理基础:
-
图像二值化的相关概念
-
图像膨胀腐蚀的相关概念
-
高斯滤波的相关概念
-
边缘检测的相关概念
-
图像高/低通滤波的相关概念
-
图像中低频信息和高频信息的定义
-
色深的概念
-
常用空间平滑技术
-
RAW图像和RGB图像的区别?
-
常用的色彩空间格式
-
模型训练时常用的插值算法?
-
常用图像增强的方法?
计算机基础:
-
深度学习中常用的Linux命令汇总
-
计算机多线程和多进程的区别?
-
TCP/IP四层模型的相关概念
-
OSI七层模型的相关概念
开放性问题:
-
如何给一个完全没有接触过机器学习的人介绍机器学习?
-
Transformer会完全替代CNN吗?
-
AI算法如何赋能电商业务?
-
AI算法如何赋能传统工业?
-
黑盒系统如何去强约束与强优化?
-
非标场景如何沉淀?
-
如何对已有业务进行优化?
-
工作中业务侧/竞赛侧/研究侧的配比
-
你能想到哪些新的AI产品形式?
-
如何提高AI业务中各部门之间的沟通/合作的效率?
-
竞赛侧与研究侧的成果如何沉淀到业务中?
-
如何扩展已有业务?
----【深度学习基础】---- 【一】卷积有什么特点?
卷积主要有三大特点:
-
局部连接。比起全连接,局部连接会大大减少网络的参数。在二维图像中,局部像素的关联性很强,设计局部连接保证了卷积网络对图像局部特征的强响应能力。
-
权值共享。参数共享也能减少整体参数量,增强了网络训练的效率。一个卷积核的参数权重被整张图片共享,不会因为图像内位置的不同而改变卷积核内的参数权重。
-
下采样。下采样能逐渐降低图像分辨率,实现了数据的降维,并使浅层的局部特征组合成为深层的特征。下采样还能使计算资源耗费变少,加速模型训练,也能有效控制过拟合。
【二】不同层次的卷积都提取什么类型的特征?
-
浅层卷积 → \rightarrow → 提取边缘特征
-
中层卷积 → \rightarrow → 提取局部特征
-
深层卷积 → \rightarrow → 提取全局特征
【三】卷积核大小如何选取?
最常用的是 3 × 3 3\times3 3×3大小的卷积核,两个 3 × 3 3 \times 3 3×3卷积核和一个 5 × 5 5 \times 5 5×5卷积核的感受野相同,但是减少了参数量和计算量,加快了模型训练。与此同时由于卷积核的增加,模型的非线性表达能力大大增强。

不过大卷积核( 7 × 7 , 9 × 9 7 \times 7,9 \times 9 7×7,9×9)也有使用的空间,在GAN,图像超分辨率,图像融合等领域依然有较多的应用,大家可按需切入感兴趣的领域查看相关论文。
【四】卷积感受野的相关概念
目标检测和目标跟踪很多模型都会用到RPN层,anchor是RPN层的基础,而感受野(receptive field,RF)是anchor的基础。
感受野的作用:
-
一般来说感受野越大越好,比如分类任务中最后卷积层的感受野要大于输入图像。
-
感受野足够大时,被忽略的信息就较少。
-
目标检测任务中设置anchor要对齐感受野,anchor太大或者偏离感受野会对性能产生一定的影响。
感受野计算:

增大感受野的方法:
-
使用空洞卷积
-
使用池化层
-
增大卷积核
【五】网络每一层是否只能用一种尺寸的卷积核?
常规的神经网络一般每层仅用一个尺寸的卷积核,但同一层的特征图可以分别使用多个不同尺寸的卷积核,以获得不同尺度的特征,再把这些特征结合起来,得到的特征往往比使用单一尺寸卷积核的要好,如GoogLeNet 、Inception系列的网络,均是每层使用了多个不同的卷积核结构。如下图所示,输入的特征图在同一层分别经过 1 × 1 1\times 1 1×1, 3 × 3 3\times3 3×3 和 5 × 5 5\times5 5×5三种不同尺寸的卷积核,再将各自的特征图进行整合,得到的新特征可以看作不同感受野提取的特征组合,相比于单一尺寸卷积核会有更强的表达能力。

【六】 1 ∗ 1 1*1 1∗1 卷积的作用?
1 ∗ 1 1 * 1 1∗1卷积的作用主要有以下几点:
-
实现特征信息的交互与整合。
-
对特征图通道数进行升维和降维,降维时可以减少参数量。
-
1 ∗ 1 1*1 1∗1卷积+ 激活函数 → \rightarrow → 增加非线性,提升网络表达能力。


1 ∗ 1 1 * 1 1∗1卷积首发于NIN(Network in Network),后续也在GoogLeNet和ResNet等网络中使用。感兴趣的朋友可追踪这些论文研读细节。
【七】转置卷积的作用?
转置卷积通过训练过程学习到最优的上采样方式,来代替传统的插值上采样方法,以提升图像分割,图像融合,GAN等特定任务的性能。
转置卷积并不是卷积的反向操作,从信息论的角度看,卷积运算是不可逆的。转置卷积可以将输出的特征图尺寸恢复卷积前的特征图尺寸,但不恢复原始数值。
转置卷积的计算公式:
我们设卷积核尺寸为 K × K K\times K K×K,输入特征图为 i × i i \times i i×i。
(1)当 s t r i d e = 1 , p a d d i n g = 0 stride = 1,padding = 0 stride=1,padding=0时:

输入特征图在进行转置卷积操作时相当于进行了 p a d d i n g = K − 1 padding = K - 1 padding=K−1的填充,接着再进行正常卷积转置之后的标准卷积运算。
输出特征图的尺寸 = i + ( K − 1 ) i + (K - 1) i+(K−1)
(2)当 s t r i d e > 1 , p a d d i n g = 0 stride > 1,padding = 0 stride>1,padding=0时:

输入特征图在进行转置卷积操作时相当于进行了 p a d d i n g = K − 1 padding = K - 1 padding=K−1的填充,相邻元素间的空洞大小为 s t r i d e − 1 stride - 1 stride−1,接着再进行正常卷积转置之后的标准卷积运算。
输出特征图的尺寸 = s t r i d e ∗ ( i − 1 ) + K stride * (i - 1) + K stride∗(i−1)+K
【八】空洞卷积的作用?
空洞卷积的作用是在不进行池化操作损失信息的情况下,增大感受野,让每个卷积输出都包含较大范围的信息。
空洞卷积有一个参数可以设置dilation rate,其在卷积核中填充dilation rate个0,因此,当设置不同dilation rate时,感受野就会不一样,也获取了多尺度信息。

(a) 图对应3x3的1-dilated conv,和普通的卷积操作一样。(b)图对应 3 × 3 3\times3 3×3的2-dilated conv,实际的卷积kernel size还是 3 × 3 3\times3 3×3,但是空洞为 1 1 1,也就是对于一个 7 × 7 7\times7 7×7的图像patch,只有 9 9 9个红色的点和 3 × 3 3\times3 3×3的kernel发生卷积操作,其余的点的权重为 0 0 0。©图是4-dilated conv操作。
【九】全连接层的作用?
全连接层将卷积学习到的高维特征映射到label空间,可以作为整个网络的分类器模块。
虽然全连接层参数存在冗余的情况,但是在模型进行迁移学习时,其能保持较大的模型capacity。
目前很多模型使用全局平均池化(GAP)取代全连接层以减小模型参数,并且依然能达到SOTA的性能。
【十】CNN中池化的作用?
池化层的作用是对感受野内的特征进行选择,提取区域内最具代表性的特征,能够有效地减少输出特征数量,进而减少模型参数量。按操作类型通常分为最大池化(Max Pooling)、平均池化(Average Pooling)和求和池化(Sum Pooling),它们分别提取感受野内最大、平均与总和的特征值作为输出,最常用的是最大池化和平均池化。
【十一】有哪些方法能提升CNN模型的泛化能力?
-
采集更多数据:数据决定算法的上限。
-
优化数据分布:数据类别均衡。
-
选用合适的目标函数。
-
设计合适的网络结构。
-
数据增强。
-
权值正则化。
-
使用合适的优化器等。
【十二】BN层面试高频问题大汇总
BN层解决了什么问题?
统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如transfer learning/domain adaptation等。而covariate shift就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。对于神经网络的各层输出,由于它们经过了层内卷积操作,其分布显然与各层对应的输入信号分布不同,而且差异会随着网络深度增大而增大,但是它们所能代表的label仍然是不变的,这便符合了covariate shift的定义。
因为神经网络在做非线性变换前的激活输入值随着网络深度加深,其分布逐渐发生偏移或者变动(即上述的covariate shift)。之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(比如sigmoid),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因。而BN就是通过一定的正则化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,避免因为激活函数导致的梯度弥散问题。所以与其说BN的作用是缓解covariate shift,也可以说BN可缓解梯度弥散问题。
BN的公式

其中scale和shift是两个可学的参数,因为减去均值除方差未必是最好的分布。比如数据本身就很不对称,或者激活函数未必是对方差为1的数据有最好的效果。所以要加入缩放及平移变量来完善数据分布以达到比较好的效果。
BN层训练和测试的不同
在训练阶段,BN层是对每个batch的训练数据进行标准化,即用每一批数据的均值和方差。(每一批数据的方差和标准差不同)
而在测试阶段,我们一般只输入一个测试样本,并没有batch的概念。因此这个时候用的均值和方差是整个数据集训练后的均值和方差,可以通过滑动平均法求得:

上面式子简单理解就是:对于均值来说直接计算所有batch u u u值的平均值;然后对于标准偏差采用每个batch σ B σ_B σB的无偏估计。
在测试时,BN使用的公式是:

BN训练时为什么不用整个训练集的均值和方差?
因为用整个训练集的均值和方差容易过拟合,对于BN,其实就是对每一batch数据标准化到一个相同的分布,而不同batch数据的均值和方差会有一定的差别,而不是固定的值,这个差别能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
BN层用在哪里?
在CNN中,BN层应该用在非线性激活函数前面。由于神经网络隐藏层的输入是上一层非线性激活函数的输出,在训练初期其分布还在剧烈改变,此时约束其一阶矩和二阶矩无法很好地缓解 Covariate Shift;而BN的分布更接近正态分布,限制其一阶矩和二阶矩能使输入到激活函数的值分布更加稳定。
BN层的参数量
我们知道 γ γ γ和 β β β是需要学习的参数,而BN的本质就是利用优化学习改变方差和均值的大小。在CNN中,因为网络的特征是对应到一整张特征图上的,所以做BN的时候也是以特征图为单位而不是按照各个维度。比如在某一层,Batch大小为 m m m,那么做BN的参数量为 m ∗ 2 m * 2 m∗2。
BN的优缺点
优点:
-
可以选择较大的初始学习率。因为这个算法收敛很快。
-
可以不用dropout,L2正则化。
-
不需要使用局部响应归一化。
-
可以把数据集彻底打乱。
-
模型更加健壮。
缺点:
-
Batch Normalization非常依赖Batch的大小,当Batch值很小时,计算的均值和方差不稳定。
-
所以BN不适用于以下几个场景:小Batch,RNN等。
----【经典模型&&热门模型】---- 【一】目标检测中IOU的相关概念与计算
IoU(Intersection over Union)即交并比,是目标检测任务中一个重要的模块,其是GT bbox与pred bbox交集的面积 / 二者并集的面积。

下面我们用坐标(top,left,bottom,right),即左上角坐标,右下角坐标。从而可以在给定的两个矩形中计算IOU值。
def compute_iou(rect1,rect2): # (y0,x0,y1,x1) = (top,left,bottom,right) S_rect1 = (rect1[2] - rect1[0]) * (rect1[3] - rect1[1]) S_rect2 = (rect2[2] - rect2[0]) * (rect2[3] - rect1[1]) sum_all = S_rect1 + S_rect2 left_line = max(rect1[1],rect2[1]) right_line = min(rect1[3],rect2[3]) top_line = max(rect1[0],rect2[0]) bottom_line = min(rect1[2],rect2[2]) if left_line >= right_line or top_line >= bottom_line: return 0 else: intersect = (right_line - left_line) * (bottom_line - top_line) return (intersect / (sum_area - intersect)) * 1.0- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
【二】目标检测中NMS的相关概念与计算
在目标检测中,我们可以利用非极大值抑制(NMS)对生成的大量候选框进行后处理,去除冗余的候选框,得到最具代表性的结果,以加快目标检测的效率。
如下图所示,消除多余的候选框,找到最佳的bbox:

非极大值抑制(NMS)流程:
-
首先我们需要设置两个值:一个Score的阈值,一个IOU的阈值。
-
对于每类对象,遍历该类的所有候选框,过滤掉Score值低于Score阈值的候选框,并根据候选框的类别分类概率进行排序: A < B < C < D < E < F A < B < C < D < E < F A<B<C<D<E<F。
-
先标记最大概率矩形框F是我们要保留下来的候选框。
-
从最大概率矩形框F开始,分别判断A~E与F的交并比(IOU)是否大于IOU的阈值,假设B、D与F的重叠度超过IOU阈值,那么就去除B、D。
-
从剩下的矩形框A、C、E中,选择概率最大的E,标记为要保留下来的候选框,然后判断E与A、C的重叠度,去除重叠度超过设定阈值的矩形框。
-
就这样重复下去,直到剩下的矩形框没有了,并标记所有要保留下来的矩形框。
-
每一类处理完毕后,返回步骤二重新处理下一类对象。
import numpy as np def py_cpu_nms(dets, thresh): #x1、y1(左下角坐标)、x2、y2(右上角坐标)以及score的值 x1 = dets[:, 0] y1 = dets[:, 1] x2 = dets[:, 2] y2 = dets[:, 3] scores = dets[:, 4] #每一个候选框的面积 areas = (x2 - x1 + 1) * (y2 - y1 + 1) #按照score降序排序(保存的是索引) order = scores.argsort()[::-1] keep = [] while order.size > 0: i = order[0] keep.append(i) #计算当前概率最大矩形框与其他矩形框的相交框的坐标,会用到numpy的broadcast机制,得到向量 xx1 = np.maximum(x1[i], x1[order[1:]]) yy1 = np.maximum(y1[i], y1[order[1:]]) xx2 = np.minimum(x2[i], x2[order[1:]]) yy2 = np.minimum(y2[i], y2[order[1:]]) #计算相交框的面积,注意矩形框不相交时w或h算出来会是负数,用0代替 w = np.maximum(0.0, xx2 - xx1 + 1) h = np.maximum(0.0, yy2 - yy1 + 1) inter = w * h #计算重叠度IOU:重叠面积 / (面积1 + 面积2 - 重叠面积) ovr = inter / (areas[i] + areas[order[1:]] - inter) #找到重叠度不高于阈值的矩形框索引 inds = np.where(ovr < thresh)[0] # 将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要加1操作 order = order[inds + 1] return keep- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
【三】One-stage目标检测与Two-stage目标检测的区别?
Two-stage目标检测算法:先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。其精度较高,速度较慢。
主要逻辑:特征提取—>生成RP—>分类/定位回归。
常见的Two-stage目标检测算法有:Faster R-CNN系列和R-FCN等。
One-stage目标检测算法:不用RP,直接在网络中提取特征来预测物体分类和位置。其速度较快,精度比起Two-stage算法稍低。
主要逻辑:特征提取—>分类/定位回归。
常见的One-stage目标检测算法有:YOLO系列、SSD和RetinaNet等。


【四】哪些方法可以提升小目标检测的效果?
-
提高图像分辨率。小目标在边界框中可能只包含几个像素,那么能通过提高图像的分辨率以增加小目标的特征的丰富度。
-
提高模型的输入分辨率。这是一个效果较好的通用方法,但是会带来模型inference速度变慢的问题。
-
平铺图像。

-
数据增强。小目标检测增强包括随机裁剪、随机旋转和镶嵌增强等。
-
自动学习anchor。
-
类别优化。
【五】ResNet模型的特点以及解决的问题?
每次回答这个问题的时候,都会包含我的私心,我喜欢从电气自动化的角度去阐述,而非计算机角度,因为这会让我想起大学时代的青葱岁月。
ResNet就是一个差分放大器。ResNet的结构设计,思想逻辑,就是在机器学习中抽象出了一个差分放大器,其能让深层网络的梯度的相关性增强,在进行梯度反传时突出微小的变化。
模型的特点则是设计了残差结构,其对模型输出的微小变化非常敏感。

为什么加入残差模块会有效果呢?
假设:如果不使用残差模块,输出为 F 1 ( x ) = 5.1 F_{1} (x)= 5.1 F1(x)=5.1,期望输出为 H 1 ( x ) = 5 H_{1} (x)= 5 H1(x)=5,如果想要学习H函数,使得 F 1 ( x ) = H 1 ( x ) = 5 F_{1} (x) = H_{1} (x) = 5 F1(x)=H1(x)=5,这个变化率比较低,学习起来是比较困难的。
但是如果设计为 H 1 ( x ) = F 1 ( x ) + 5 = 5.1 H_{1} (x) = F_{1} (x) + 5 = 5.1 H1(x)=F1(x)+5=5.1,进行一种拆分,使得 F 1 ( x ) = 0.1 F_{1} (x)= 0.1 F1(x)=0.1,那么学习目标就变为让 F 1 ( x ) = 0 F_{1} (x)= 0 F1(x)=0,一个映射函数学习使得它输出由0.1变为0,这个是比较简单的。也就是说引入残差模块后的映射对输出变化更加敏感了。
进一步理解:如果 F 1 ( x ) = 5.1 F_{1} (x)= 5.1 F1(x)=5.1,现在继续训练模型,使得映射函数 F 1 ( x ) = 5 F_{1} (x)= 5 F1(x)=5。变化率为: ( 5.1 − 5 ) / 5.1 = 0.02 (5.1 - 5) / 5.1 = 0.02 (5.1−5)/5.1=0.02,如果不用残差模块的话可能要把学习率从0.01设置为0.0000001。层数少还能对付,一旦层数加深的话可能就不太好使了。
这时如果使用残差模块,也就是 F 1 ( x ) = 0.1 F_{1} (x)= 0.1 F1(x)=0.1变化为 F 1 ( x ) = 0 F_{1} (x)= 0 F1(x)=0。这个变化率增加了100%。明显这样的话对参数权重的调整作用更大。
【六】ResNeXt模型的结构和特点?
ResNeXt模型是在ResNet模型的基础上进行优化。其主要是在ResNeXt中引入Inception思想。如下图所示,左侧是ResNet经典结构,右侧是ResNeXt结构,其将单路卷积转化成多支路的多路卷积,进行分组卷积。

作者进一步提出了ResNeXt的三种等价结构,其中c结构中的分组卷积思想就跃然纸上了。

最后我们看一下ResNeXt50和ResNet50结构上差异的对比图:

ResNeXt论文:《Aggregated Residual Transformations for Deep Neural Networks》
【七】MobileNet系列模型的结构和特点?
MobileNet是一种轻量级的网络结构,主要针对手机等嵌入式设备而设计。MobileNetv1网络结构在VGG的基础上使用depthwise Separable卷积,在保证不损失太大精度的同时,大幅降低模型参数量。
Depthwise separable卷积是由Depthwise卷积和Pointwise卷积构成。
Depthwise卷积(DW)能有效减少参数数量并提升运算速度。但是由于每个特征图只被一个卷积核卷积,因此经过DW输出的特征图只包含输入特征图的全部信息,而且特征之间的信息不能进行交流,导致“信息流通不畅”。Pointwise卷积(PW)实现通道特征信息交流,解决DW卷积导致“信息流通不畅”的问题。
Depthwise Separable卷积和标准卷积的计算量对比:

相比标准卷积,Depthwise Separable卷积可以大幅减小计算量。并且随着卷积通道数的增加,效果更加明显。
并且Mobilenetv1使用stride=2的卷积替换池化操作,直接在卷积时利用stride=2完成了下采样,从而节省了卷积后再去用池化操作去进行一次下采样的时间,可以提升运算速度。
MobileNetv1论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
【八】MobileNet系列模型的结构和特点?(二)
MobileNetV2在MobileNetV1的基础上引入了Linear Bottleneck 和 Inverted Residuals。
MobileNetV2使用Linear Bottleneck(线性变换)来代替原本的非线性激活函数,来捕获感兴趣的流形。实验证明,使用Linear Bottleneck可以在小网络中较好地保留有用特征信息。
Inverted Residuals与经典ResNet残差模块的通道间操作正好相反。由于MobileNetV2使用了Linear Bottleneck结构,使其提取的特征维度整体偏低,如果只是使用低维的feature map效果并不会好。如果卷积层都是使用低维的feature map来提取特征的话,那么就没有办法提取到整体的足够多的信息。如果想要提取全面的特征信息的话,我们就需要有高维的feature map来进行补充,从而达到平衡。

MobileNetV2的论文:《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
MobileNetV3在整体上有两大创新:
1.互补搜索技术组合:由资源受限的NAS执行模块级搜索;由NetAdapt执行局部搜索,对各个模块确定之后网络层的微调。
2.网络结构改进:进一步减少网络层数,并引入h-swish激活函数。
作者发现swish激活函数能够有效提高网络的精度。然而,swish的计算量太大了。作者提出h-swish(hard version of swish)如下所示:

这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。

MobileNetV3模型结构的优化:

MobileNetV3的论文:《Searching for MobileNetV3》
【九】ViT(Vision Transformer)模型的结构和特点?
ViT模型特点:
1.ViT直接将标准的Transformer结构直接用于图像分类,其模型结构中不含CNN。
2.为了满足Transformer输入结构要求,输入端将整个图像拆分成小图像块,然后将这些小图像块的线性嵌入序列输入网络中。在最后的输出端,使用了Class Token形式进行分类预测。
3.Transformer比CNN结构少了一定的平移不变性和局部感知性,在数据量较少的情况下,效果可能不如CNN模型,但是在大规模数据集上预训练过后,再进行迁移学习,可以在特定任务上达到SOTA性能。ViT的整体模型结构:

其可以具体分成如下几个部分:
-
图像分块嵌入
-
多头注意力结构
-
多层感知机结构(MLP)
-
使用DropPath,Class Token,Positional Encoding等操作。
【十】EfficientNet系列模型的结构和特点?
Efficientnet系列模型是通过grid search从深度(depth)、宽度(width)、输入图片分辨率(resolution)三个角度共同调节搜索得来的模型。其从EfficientNet-B0到EfficientNet-L2版本,模型的精度越来越高,同样,参数量和对内存的需求也会随之变大。
深度模型的规模主要是由宽度、深度、分辨率这三个维度的缩放参数决定的。这三个维度并不是相互独立的,对于输入的图片分辨率更高的情况,需要有更深的网络来获得更大的感受视野。同样的,对于更高分辨率的图片,需要有更多的通道来获取更精确的特征。

EfficientNet模型的内部是通过多个MBConv卷积模块实现的,每个MBConv卷积模块的具体结构如下图所示。其用实验证明Depthwise Separable卷积在大模型中依旧非常有效;Depthwise Separable卷积较于标准卷积有更好的特征提取表达能力。

另外论文中使用了Drop_Connect方法来代替传统的Dropout方法来防止模型过拟合。DropConnect与Dropout不同的地方是在训练神经网络模型过程中,它不是对隐层节点的输出进行随机的丢弃,而是对隐层节点的输入进行随机的丢弃。

EfficientNet论文:《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》
说点题外话,隔着paper都能看到作者那窒息的调参过程。。。

【十一】面试常问的经典模型?
面试中经常会问一些关于模型方面的问题,这也是不太好量化定位的问题,因为模型繁杂多样,面试官问哪个都有可能,下面的逻辑图里我抛砖引玉列出了一些不管是在学术界还是工业界都是高价值的模型,供大家参考。
最好还是多用项目,竞赛,科研等工作润色简历,并在面试过程中将模型方面的问题引向这些工作中用到的熟悉模型里。

----【机器学习基础】---- 【一】什么是模型的偏差和方差?
误差(Error)= 偏差(Bias) + 方差(Variance) + 噪声(Noise),一般地,我们把机器学习模型的预测输出与样本的真实label之间的差异称为误差,其反应的是整个模型的准确度。
噪声(Noise):描述了在当前任务上任何机器学习算法所能达到的期望泛化误差的下界,即刻画了当前任务本质的难度。
偏差(Bias):衡量了模型拟合训练数据的能力,偏差反应的是所有采样得到的大小相同的训练集训练出的所有模型的输出平均值和真实label之间的偏差,即模型本身的精确度。
偏差通常是由于我们对机器学习算法做了错误的假设所导致的,比如真实数据分布映射的是某个二次函数,但我们假设模型是一次函数。
偏差(Bias)越小,拟合能力却强(可能产生过拟合);反之,拟合能力越弱(可能产生欠拟合)。偏差越大,越偏离真实数据。
方差描述的是预测值的变化范围,离散程度,也就是离期望值的距离。方差越大,数据的分布越分散,模型的稳定程度越差。
方差也反应了模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。由方差带来的误差通常体现在测试误差相对于训练误差的增量上。
方差通常是由于模型的复杂度相对于训练样本数过高导致的。方差越小,模型的泛化能力越高;反之,模型的泛化能力越低。
如果模型在训练集上拟合效果比较优秀,但是在测试集上拟合效果比较差,则表示方差较大,说明模型的稳定程度较差,出现这种现象可能是由于模型对训练集过拟合造成的。
接下来我们用下面的射击的例子进一步解释这二者的区别。假设一次射击就是机器学习模型对一个样本进行预测。射中靶心位置代表预测准确,偏离靶心越远代表预测误差越大,其中左上角是最好的结果。

【二】数据类别不平衡怎么处理?
-
数据增强。
-
对少数类别数据做过采样,多数类别数据做欠采样。
-
损失函数的权重均衡。(不同类别的loss权重不一样,最佳参数需要手动调节)
-
采集更多少数类别的数据。
-
转化问题定义,将问题转化为异常点检测或变化趋势检测问题。 异常点检测即是对那些罕见事件进行识别,变化趋势检测区别于异常点检测,其通过检测不寻常的变化趋势来进行识别。
-
使用新的评价指标。
-
阈值调整,将原本默认为0.5的阈值调整到:较少类别/(较少类别+较多类别)。
【三】什么是过拟合,解决过拟合的方法有哪些?
过拟合:模型在训练集上拟合的很好,但是模型连噪声数据的特征都学习了,丧失了对测试集的泛化能力。
解决过拟合的方法:
-
重新清洗数据,数据不纯会导致过拟合,此类情况需要重新清洗数据或重新选择数据。
-
增加训练样本数量。使用更多的训练数据是解决过拟合最有效的手段。我们可以通过一定的规则来扩充训练数据,比如在图像分类问题上,可以通过图像的平移、旋转、缩放、加噪声等方式扩充数据;也可以用GAN网络来合成大量的新训练数据。
-
降低模型复杂程度。适当降低模型复杂度可以避免模型拟合过多的噪声数据。在神经网络中减少网络层数、神经元个数等。
-
加入正则化方法,增大正则项系数。给模型的参数加上一定的正则约束,比如将权值的大小加入到损失函数中。
-
采用dropout方法,dropout方法就是在训练的时候让神经元以一定的概率失活。
-
提前截断(early stopping),减少迭代次数。
-
增大学习率。
-
集成学习方法。集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,如Bagging方法。
【四】什么是欠拟合,解决欠拟合的方法有哪些?
欠拟合:模型在训练集和测试集上效果均不好,其根本原因是模型没有学习好数据集的特征。
解决欠拟合的方法:
-
可以增加模型复杂度。对于神经网络可以增加网络层数或者神经元数量。
-
减小正则化系数。正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要有针对性地减小正则化系数。
-
Boosting。
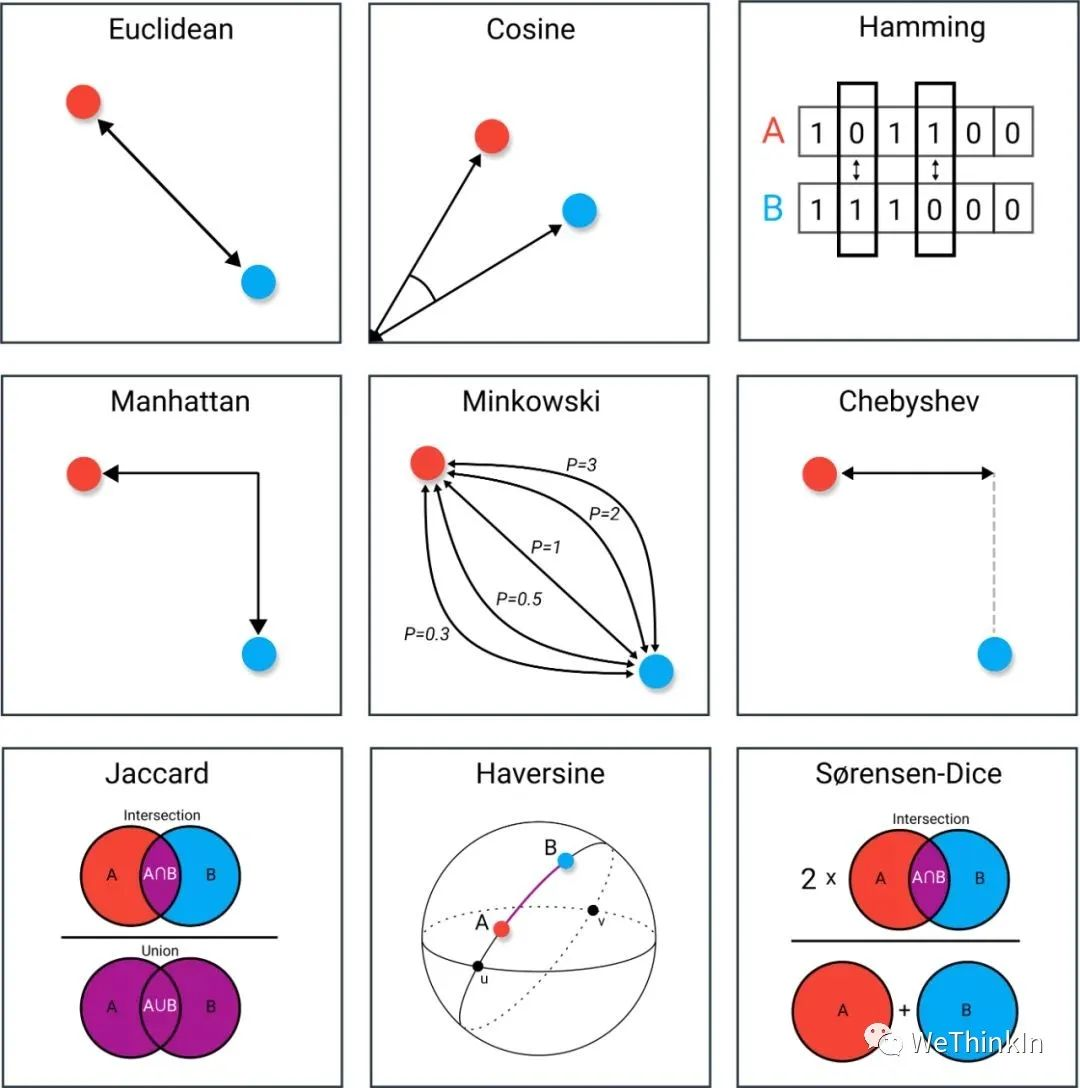
【五】常用的距离度量方法
-
欧式距离
-
闵可夫斯基距离
-
马氏距离
-
互信息
-
余弦距离
-
皮尔逊相关系数
-
Jaccard相关系数
-
曼哈顿距离
【六】正则化的本质以及常用正则化手段?
正则化是机器学习的核心主题之一。正则化本质是对某一问题加以先验的限制或约束以达到某种特定目的的一种操作。在机器学习中我们通过使用正则化方法,防止其过拟合,降低其泛化误差。
常用的正则化手段:
-
数据增强
-
使用L范数约束
-
dropout
-
early stopping
-
对抗训练
【七】L范数的作用?
L范数主要起到了正则化(即用一些先验知识约束或者限制某一抽象问题)的作用,而正则化主要是防止模型过拟合。
范数主要用来表征高维空间中的距离,故在一些生成任务中也直接用L范数来度量生成图像与原图像之间的差别。
下面列出深度学习中的范数:


【八】Dropout的作用?
Dropout是在训练过程中以一定的概率使神经元失活,也就是输出等于0。从而提高模型的泛化能力,减少过拟合。

我们可以从两个方面去直观地理解Dropout的正则化效果:1)在Dropout每一轮训练过程中随机丢失神经元的操作相当于多个模型进行取平均,因此用于预测时具有vote的效果。2)减少神经元之间复杂的共适应性。当隐藏层神经元被随机删除之后,使得全连接网络具有了一定的稀疏化,从而有效地减轻了不同特征的协同效应。也就是说,有些特征可能会依赖于固定关系的隐含节点的共同作用,而通过Dropout的话,就有效地避免了某些特征在其他特征存在下才有效果的情况,增加了神经网络的鲁棒性。
Dropout在训练和测试时的区别:Dropout只在训练时产生作用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合风险。而在测试时,应该用整个训练好的模型,因此不需要Dropout。
【九】Softmax的定义和作用
在二分类问题中,我们可以使用sigmoid函数将输出映射到【0,1】区间中,从而得到单个类别的概率。当我们将问题推广到多分类问题时,可以使用Softmax函数,对输出的值映射为概率值。

其定义为:

其中a代表了模型的输出。
【十】交叉熵定义和作用
交叉熵(cross entropy)常用于深度学习中的分类任务,其可以表示预测值与ground truth之间的差距。
交叉熵是信息论中的概念。其定义为:

P P P代表 g t gt gt的概率分布, q q q代表预测值的概率分布。交叉熵从相对熵(KL散度)演变而来, l o g log log代表了信息量, q q q越大说明可能性越大,其信息量越少;反之则信息量越大。通过不断的训练优化,逐步减小交叉熵损失函数的值来达到缩小 p p p和 q q q距离的目的。
【十一】训练集/验证集/测试集划分
机器学习的直接目的是希望模型在真实场景的数据上有很好的预测效果,泛化误差越低越好。
如何去跟踪泛化误差呢?这时就需要验证集和测试集了。
我们可以使用训练集的数据来训练模型,然后用测试集上的误差推测最终模型在应对现实场景中的泛化误差。有了测试集,我们可以在本地验证模型的最终的近似效果。
与此同时,我们在模型训练过程中要实时监控模型的指标情况,从而进行模型参数优选操作。验证集就用于模型训练过程中的指标评估。
一般来说,如果当数据量不是很大的情况(万级别以下)可以将训练集、验证集和测试集划分为6:2:2;如果是万级别甚至十万级别的数据量,可以将训练集、验证集和测试集比例调整为98:1:1。
(注:在数据集划分时要主要类别的平衡)
【十二】如何找到让F1最高的分类阈值?
首先,这个问题只存在于二分类问题中,对于多分类问题,只需要概率最高的那个预测标签作为输出结果即可。
F1值是综合了精准率和召回率两个指标对模型进行评价:

一般设0.5作为二分类的默认阈值,但一般不是最优阈值。想要精准率高,一般使用高阈值,而想要召回率高,一般使用低阈值。在这种情况下,我们通常可以通过P-R曲线去寻找最优的阈值点或者阈值范围。
----【数据结构&&算法】---- 【一】常用数据结构的相关知识
-
数组:最基本的数据结构,用连续内存存储数字。创建数组时,我们需要首先指定数组的容量大小,然后根据大小分配内存。即使我们只在数组中存储一个数字,也需要为所有的数据预先分配内存。因此数组的空间效率不是很好,经常会有空闲的区域没有得到充分的利用。(可动态分配内存来解决上述问题)由于数组中的内存是连续的,于是可以根据数组下标O(1)时间读/写任何元素,因此它的时间效率是很高的。
-
字符串:最基本的数据结构,用连续内存存储字符。C/C++中每个字符串都以字符’\0’作为结尾,这样我们就能很方便地找到字符串的最后尾部。
-
链表:链表的结构很简单,由指针把若干个节点连接成链状结构,并且链表是一种动态的数据结构,其需要对指针进行操作,因此链表很灵活。在创建链表时,我们无须知到链表的长度。当插入一个节点时,我们只需要为新节点分配内存,然后调整指针的指向来确保新节点被链接到链表中。内存分配不是在创建链表时一次性完成的,而是每添加一个节点分配一次内存。由于没有闲置的内存,链表的空间效率比数组高。
-
树:除根节点之外每个节点只有一个父节点,根节点没有父节点;除叶节点之外所有节点都有一个或多个子节点,叶节点没有子节点。父节点和子节点之间用指针链接。二叉树:是树的一种特殊结构,在二叉树中每个节点最多只能有两个子节点。二叉搜索树:左子节点总是小于或者等于根节点,而右子节点总是大于或者等于根节点。我么可以平均在O(logn)的时间内根据数值在二叉搜索树中找到一个结点。堆:分为最大堆和最小堆。在最大堆中根节点的值最大,在最小堆中根节点的值最小。
-
栈:栈是一个与递归紧密相关的数据结构,它在计算机领域被广泛应用,比如操作系统会给每个线程创建一个栈用来存储函数调用时各个函数的参数、返回地址及临时变量等。栈的特点是先进后出,即最后被压入(push)栈的元素会第一个被弹出(pop)。通常栈是一个不考虑排序的数据结构,我们需要O(n)时间才能找到栈中的最大值或最小值。
-
队列:队列与广度优先遍历算法紧密相关,队列的特点是先进先出。
【二】二叉树遍历(递归)模版
我们在调用递归函数的时候,把递归函数当作普通函数(黑箱)来调用,即明白该函数的输入输出是什么,而不用管此函数的内部运行机制。
前序遍历:
def dfs(root): if not root: return 执行操作 dfs(root.left) dfs(root.right)- 1
- 2
- 3
- 4
- 5
- 6
中序遍历:
def dfs(root): if not root: return dfs(root.left) 执行操作 dfs(root.right)- 1
- 2
- 3
- 4
- 5
- 6
后序遍历:
def dfs(root): if not root: return dfs(root.left) dfs(root.right) 执行操作- 1
- 2
- 3
- 4
- 5
- 6
【三】不同排序算法的异同?

【四】树有哪些遍历模式?
树的遍历模式:
-
前序遍历:先访问根节点,再访问左子节点,最后访问右子节点。
-
中序遍历:先访问左子节点,再访问根节点,最后访问右子节点。
-
后序遍历:先访问左子节点,再访问右子节点,最后访问根节点。
-
宽度优先遍历:先访问树的第一层节点,再访问树的第二层节点,一直到最后一层节点。
----【Python/C/C++知识】---- 【一】Python中迭代器的概念?
可迭代对象是迭代器、生成器和装饰器的基础。简单来说,可以使用for来循环遍历的对象就是可迭代对象。比如常见的list、set和dict。
我们来看一个🌰:
from collections import Iterable print(isinstance('abcddddd', Iterable)) # str是否可迭代 print(isinstance([1,2,3,4,5,6], Iterable)) # list是否可迭代 print(isinstance(12345678, Iterable)) # 整数是否可迭代 -------------结果如下---------------- True True False- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当对所有的可迭代对象调用 dir() 方法时,会发现他们都实现了 iter 方法。这样就可以通过 iter(object) 来返回一个迭代器。
x = [1, 2, 3] y = iter(x) print(type(x)) print(type(y)) ------------结果如下------------- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以看到调用iter()之后,变成了一个list_iterator的对象。可以发现增加了一个__next__方法。所有实现了__iter__和__next__两个方法的对象,都是迭代器。
迭代器是带状态的对象,它会记录当前迭代所在的位置,以方便下次迭代的时候获取正确的元素。__iter__返回迭代器自身,__next__返回容器中的下一个值,如果容器中没有更多元素了,则抛出Stoplteration异常。
x = [1, 2, 3] y = iter(x) print(next(y)) print(next(y)) print(next(y)) print(next(y)) ----------结果如下---------- 1 2 3 Traceback (most recent call last): File "/Users/Desktop/test.py", line 6, inprint(next(y)) StopIteration - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
如何判断对象是否是迭代器,和判断是否是可迭代对象的方法差不多,只要把 Iterable 换成 Iterator。
Python的for循环本质上就是通过不断调用next()函数实现的,举个栗子,下面的代码先将可迭代对象转化为Iterator,再去迭代。这样可以节省对内存,因为迭代器只有在我们调用 next() 才会实际计算下一个值。
x = [1, 2, 3] for elem in x: ...- 1
- 2
- 3

itertools 库提供了很多常见迭代器的使用。
>>> from itertools import count # 计数器 >>> counter = count(start=13) >>> next(counter) 13 >>> next(counter) 14- 1
- 2
- 3
- 4
- 5
- 6
【二】Python中生成器的相关知识
我们创建列表的时候,受到内存限制,容量肯定是有限的,而且不可能全部给他一次枚举出来。Python常用的列表生成式有一个致命的缺点就是定义即生成,非常的浪费空间和效率。
如果列表元素可以按照某种算法推算出来,那我们可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,最简单的方法是改造列表生成式:
a = [x * x for x in range(10)] print(a) b = (x * x for x in range(10)) print(b) --------结果如下-------------- [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]at 0x10557da50> - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
还有一个方法是生成器函数,通过def定义,然后使用yield来支持迭代器协议,比迭代器写起来更简单。
def spam(): yield"first" yield"second" yield"third" for x in spam(): print(x) -------结果如下--------- first second third- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
进行函数调用的时候,返回一个生成器对象。在使用next()调用的时候,遇到yield就返回,记录此时的函数调用位置,下次调用next()时,从断点处开始。
我们完全可以像使用迭代器一样使用 generator ,当然除了定义。定义一个迭代器,需要分别实现 iter() 方法和 next() 方法,但 generator 只需要一个小小的yield。
generator还有 send() 和 close() 方法,都是只能在next()调用之后,生成器处于挂起状态时才能使用的。
python是支持协程的,也就是微线程,就是通过generator来实现的。配合generator我们可以自定义函数的调用层次关系从而自己来调度线程。
【三】Python中装饰器的相关知识
装饰器允许通过将现有函数传递给装饰器,从而向现有函数添加一些额外的功能,该装饰器将执行现有函数的功能和添加的额外功能。
装饰器本质上还是一个函数,它可以让已有的函数不做任何改动的情况下增加功能。
接下来我们使用一些例子来具体说明装饰器的作用:
如果我们不使用装饰器,我们通常会这样来实现在函数执行前插入日志:
def foo(): print('i am foo') def foo(): print('foo is running') print('i am foo')- 1
- 2
- 3
- 4
- 5
- 6
虽然这样写是满足了需求,但是改动了原有的代码,如果有其他的函数也需要插入日志的话,就需要改写所有的函数,这样不能复用代码。
我们可以进行如下改写:
import logging def use_log(func): logging.warning("%s is running" % func.__name__) func() def bar(): print('i am bar') use_log(bar) #将函数作为参数传入 -------------运行结果如下-------------- WARNING:root:bar is running i am bar- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这样写的确可以复用插入的日志,缺点就是显式的封装原来的函数,我们希望能隐式的做这件事。
我们可以用装饰器来写:
import logging def use_log(func): def wrapper(*args, **kwargs): logging.warning('%s is running' % func.__name__) return func(*args, **kwargs) return wrapper def bar(): print('I am bar') bar = use_log(bar) bar() ------------结果如下------------ WARNING:root:bar is running I am bar- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
其中,use_log函数就是装饰器,它把我们真正想要执行的函数bar()封装在里面,返回一个封装了加入代码的新函数,看起来就像是bar()被装饰了一样。
但是这样写还是不够隐式,我们可以通过@语法糖来起到bar = use_log(bar)的作用。
import logging def use_log(func): def wrapper(*args, **kwargs): logging.warning('%s is running' % func.__name__) return func(*args, **kwargs) return wrapper @use_log def bar(): print('I am bar') @use_log def haha(): print('I am haha') bar() haha() ------------结果如下------------ WARNING:root:bar is running I am bar WARNING:root:haha is running I am haha- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这样子看起来就非常简洁,而且代码很容易复用。可以看成是一种智能的高级封装。
【四】Python的深拷贝与浅拷贝?
在Python中,用一个变量给另一个变量赋值,其实就是给当前内存中的对象增加一个“标签”而已。
>>> a = [6, 6, 6, 6] >>> b = a >>> print(id(a), id(b), sep = '\n') 66668888 66668888 >>> a is b True(可以看出,其实a和b指向内存中同一个对象。)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
浅拷贝是指创建一个新的对象,其内容是原对象中元素的引用(新对象与原对象共享内存中的子对象)。
注:浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含了其他对象的对象,如列表,类实例等等。而对于数字、字符串以及其他“原子”类型,没有拷贝一说,产生的都是原对象的引用。
常见的浅拷贝有:切片操作、工厂函数、对象的copy()方法,copy模块中的copy函数。
>>> a = [6, 8, 9] >>> b = list(a) >>> print(id(a), id(b)) 4493469248 4493592128 #a和b的地址不同 >>> for x, y in zip(a, b): ... print(id(x), id(y)) ... 4489786672 4489786672 4489786736 4489786736 4489786768 4489786768 # 但是他们的子对象地址相同- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从上面的例子中可以看出,a浅拷贝得到b,a和b指向内存中不同的list对象,但是他们的元素指向相同的int对象,这就是浅拷贝。
深拷贝是指创建一个新的对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联。
深拷贝只有一种方式:copy模块中的deepcopy函数。
我们接下来用一个包含可变对象的列表来确切地展示浅拷贝和深拷贝的区别:
>>> a = [[6, 6], [8, 8], [9, 9]] >>> b = copy.copy(a) # 浅拷贝 >>> c = copy.deepcopy(a) # 深拷贝 >>> print(id(a), id(b)) # a和b地址不同 4493780304 4494523680 >>> for x, y in zip(a, b): # a和b的子对象地址相同 ... print(id(x), id(y)) ... 4493592128 4493592128 4494528592 4494528592 4493779024 4493779024 >>> print(id(a), id(c)) # a和c不同 4493780304 4493469248 >>> for x, y in zip(a, c): # a和c的子对象地址也不同 ... print(id(x), id(y)) ... 4493592128 4493687696 4494528592 4493686336 4493779024 4493684896- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
【五】Python是解释语言还是编译语言?
Python是解释语言。
解释语言的优点是可移植性好,缺点是运行需要解释环境,运行起来比编译语言要慢,占用的资源也要多一些,代码效率低。
编译语言的优点是运行速度快,代码效率高,编译后程序不可以修改,保密性好。缺点是代码需要经过编译才能运行,可移植性较差,只能在兼容的操作系统上运行。

【六】Python的垃圾回收机制
在Python中,使用引用计数进行垃圾回收;同时通过标记-清除算法解决容器对象可能产生的循环引用问题;最后通过分代回收算法提高垃圾回收效率。
【七】Python里有多线程吗?
Python里的多线程是假的多线程。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核,只有一个线程在解释器中运行。
对于I/O密集型任务,Python的多线程能起到作用,但对于CPU密集型任务,Python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。
对所有面向I/O的(会调用内建的操作系统C代码的)程序来说,GIL会在这个I/O调用之前被释放,以允许其它的线程在这个线程等待I/O的时候运行。
如果是纯计算的程序,没有 I/O 操作,解释器会每隔 100 次操作就释放这把锁,让别的线程有机会执行(这个次数可以通过 sys.setcheckinterval 来调整)如果某线程并未使用很多I/O 操作,它会在自己的时间片内一直占用处理器和GIL。
缓解GIL锁的方法:多进程和协程(协程也只是单CPU,但是能减小切换代价提升性能)
【八】Python中range和xrange的区别?
首先,xrange函数和range函数的用法完全相同,不同的地方是xrange函数生成的不是一个list对象,而是一个生成器。
要生成很大的数字序列时,使用xrange会比range的性能优很多,因为其不需要一上来就开辟很大的内存空间。
Python 2.7.15 | packaged by conda-forge | (default, Jul 2 2019, 00:42:22) [GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> range(10) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> xrange(10) xrange(10) >>> list(xrange(10)) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
xrange函数和range函数一般都用在循环的时候。具体例子如下所示:
>>> for i in range(0,7): ... print(i) ... 0 1 2 3 4 5 6 >>> for i in xrange(0,7): ... print(i) ... 0 1 2 3 4 5 6- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在Python3中,xrange函数被移除了,只保留了range函数的实现,但是此时range函数的功能结合了xrange和range。并且range函数的类型也发生了变化,在Python2中是list类型,但是在Python3中是range序列的对象。
【九】Python中列表和元组的区别?
-
列表是可变的,在创建之后可以对其进行任意的修改。
-
元组是不可变的,元组一旦创建,便不能对其进行更改,可以元组当作一个只读版本的列表。
-
元组无法复制。
-
Python将低开销的较大的块分配给元组,因为它们是不可变的。对于列表则分配小内存块。与列表相比,元组的内存更小。当你拥有大量元素时,元组比列表快。
【十】Python中dict(字典)的底层结构?
Python的dict(字典)为了支持快速查找使用了哈希表作为底层结构,哈希表平均查找时间复杂度为O(1)。CPython 解释器使用二次探查解决哈希冲突问题。
【十一】常用的深度学习框架有哪些,都是哪家公司开发的?
-
PyTorch:Facebook
-
TensorFlow:Google
-
Keras:Google
-
MxNet:Dmlc社区
-
Caffe:UC Berkeley
-
PaddlePaddle:百度
【十二】PyTorch动态图和TensorFlow静态图的区别?
PyTorch动态图:计算图的运算与搭建同时进行;其较灵活,易调节。
TensorFlow静态图:计算图先搭建图,后运算;其较高效,不灵活。

【十三】C/C++中面向对象的相关知识
面向对象程序设计(Object-oriented programming,OOP)有三大特征 ——封装、继承、多态。
封装:把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
关键字:public, protected, private。不写默认为 private。-
public 成员:可以被任意实体访问。
-
protected 成员:只允许被子类及本类的成员函数访问。
-
private 成员:只允许被本类的成员函数、友元类或友元函数访问。
继承:基类(父类)——> 派生类(子类)
多态:即多种状态(形态)。简单来说,我们可以将多态定义为消息以多种形式显示的能力。多态是以封装和继承为基础的。
C++ 多态分类及实现:
-
重载多态(Ad-hoc Polymorphism,编译期):函数重载、运算符重载
-
子类型多态(Subtype Polymorphism,运行期):虚函数
-
参数多态性(Parametric Polymorphism,编译期):类模板、函数模板
-
强制多态(Coercion Polymorphism,编译期/运行期):基本类型转换、自定义类型转换
【十四】C/C++中struct的内存对齐与内存占用计算?
什么是内存对齐?计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是有效对齐值的倍数。
什么是有效对齐值?计算机系统有默认对齐系数n,可以通过#pragma pack(n)来指定。有效对齐值就等与该对齐系数和结构体中最长的数据类型的长度两者最小的那一个值,比如对齐系数是8,而结构体中最长的是int,4个字节,那么有效对齐值为4。
为什么要内存对齐?假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的连续四个字节地址中。当4字节存取粒度的处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器,这需要做很多工作,整体效率较低。

struct内存占用如何计算?结构体的内存计算方式遵循以下规则:
-
数据成员对齐规则:第一个数据成员放在offset为0的地方,以后的每一个成员的offset都必须是该成员的大小与有效对齐值相比较小的数值的整数倍,例如第一个数据成员是int型,第二个是double,有效对齐值为8,所以double的起始地址应该为8,那么第一个int加上内存补齐用了8个字节
-
结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部有效对齐值的整数倍地址开始存储。(比如struct a中存有struct b,b里有char, int, double,那b应该从8的整数倍开始存储)
-
结构体内存的总大小,必须是其有效对齐值的整数倍,不足的要补齐。
我们来举两个🌰:
#include#pragma pack(8) int main() { struct Test { int a; //long double大小为16bytes long double b; char c[10]; }; printf("%d", sizeof(Test)); return 0; } struct的内存占用为40bytes - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
#include#pragma pack(16) int main() { struct Test { int a; //long double大小为16bytes long double b; char c[10]; } printf("%d", sizeof(Test)); return 0; } struct的内存占用为48bytes - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
【十五】C/C++中智能指针的定义与作用?
智能指针是一个类,这个类的构造函数中传入一个普通指针,析构函数中释放传入的指针。智能指针的类都是栈上的对象,所以当函数(或程序)结束时会自动被释放。
(注:不能将指针直接赋值给一个智能指针,一个是类,一个是指针。)
常用的智能指针:智能指针在C++11版本之后提供,包含在头文件中,主要是shared_ptr、unique_ptr、weak_ptr。unique_ptr不支持复制和赋值。当程序试图将一个 unique_ptr 赋值给另一个时,如果源 unique_ptr 是个临时右值,编译器允许这么做;如果原来的unique_ptr 将存在一段时间,编译器将禁止这么做。shared_ptr是基于引用计数的智能指针。可随意赋值,直到内存的引用计数为0的时候这个内存会被释放。weak_ptr能进行弱引用。引用计数有一个问题就是互相引用形成环,这样两个指针指向的内存都无法释放。需要手动打破循环引用或使用weak_ptr。顾名思义,weak_ptr是一个弱引用,只引用,不计数。如果一块内存被shared_ptr和weak_ptr同时引用,当所有shared_ptr析构了之后,不管还有没有weak_ptr引用该内存,内存也会被释放。所以weak_ptr不保证它指向的内存一定是有效的,在使用之前需要检查weak_ptr是否为空指针。
智能指针的作用:C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,野指针,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。
【十六】C/C++中程序的开发流程?
开发一个C++程序的过程通常包括编辑、编译、链接、运行和调试等步骤。
编辑:编辑是C++程序开发过程的第一步,它主要包括程序文本的输入和修改。任何一种文本编辑器都可以完成这项工作。当用户完成了C++程序的编辑时,应将输入的程序文本保存为以.cpp为扩展名的文件(保存C++头文件时应以.h为扩展名)。
编译:C++是一种高级程序设计语言,它的语法规则与汇编语言和机器语言相比更接近人类自然语言的习惯。然而,计算机能够“看”懂的唯一语言是汇编语言。因此,当我们要让计算机“看”懂一个C++程序时,就必须使用编译器将这个C++程序“翻译”成汇编语言。编译器所做的工作实际上是一种由高级语言到汇编语言的等价变换。
汇编:将汇编语言翻译成机器语言指令。汇编器对汇编语言进行一系列处理后最终产生的输出结构称为目标代码,它是某种计算机的机器指令(二进制),并且在功能上与源代码完全等价。保存源代码和目标代码的文件分别称为源文件和目标文件( .obj)。
链接:要将汇编器产生的目标代码变成可执行程序还需要最后一个步骤——链接。链接工作是由“链接器”完成的,它将编译后产生的一个或多个目标文件与程序中用到的库文件链接起来,形成一个可以在操作系统中直接运行的可执行程序。(linux中的.o文件)
运行和调试:我们接下来就可以执行程序了。如果出现问题我们可以进行调试debug。
【十七】C/C++中数组和链表的优缺点?
数组和链表是C/C++中两种基本的数据结构,也是两个最常用的数据结构。
数组的特点是在内存中,数组是一块连续的区域,并且数组需要预留空间。链表的特点是在内存中,元素的空间可以在任意地方,空间是分散的,不需要连续。链表中的元素都会两个属性,一个是元素的值,另一个是指针,此指针标记了下一个元素的地址。每一个数据都会保存下一个数据的内存的地址,通过此地址可以找到下一个数据。
数组的优缺点:
优点:查询效率高,时间复杂度可以达到O(1)。
缺点:新增和修改效率低,时间复杂度为O(N);内存分配是连续的内存,扩容需要重新分配内存。
链表的优缺点:
优点:新增和修改效率高,只需要修改指针指向即可,时间复杂度可以达到O(1);内存分配不需要连续的内存,占用连续内存少。
缺点:链表查询效率低,需要从链表头依次查找,时间复杂度为O(N)。
【十八】C/C++中的new和malloc有什么区别?
new和malloc主要有以下三方面的区别:
-
malloc和free是标准库函数,支持覆盖;new和delete是运算符,支持重载。
-
malloc仅仅分配内存空间,free仅仅回收空间,不具备调用构造函数和析构函数功能,用malloc分配空间存储类的对象存在风险;new和delete除了分配回收功能外,还会调用构造函数和析构函数。
-
malloc和free返回的是void类型指针(必须进行类型转换),new和delete返回的是具体类型指针。
----【模型部署】---- 【一】模型压缩的必要性与可行性?
模型压缩是指对算法模型进行精简,进而得到一个轻量且性能相当的小模型,压缩后的模型具有更小的结构和更少的参数,可以有效降低计算和存储开销,便于部署在端侧设备中。
随着AI技术的飞速发展,不管是移动端产品还是线上产品,进行AI赋能都成为了趋势。这种情况下,AI算法的实时性与减少内存占用都显得极为重要。AI模型的参数在一定程度上能够表达其复杂性,但并不是所有的参数都在模型中发挥作用,部分参数作用有限,表达冗余,甚至会降低模型的性能。
【二】X86和ARM架构在深度学习侧的区别?
AI服务器与PC端一般都是使用X86架构,因为其高性能;AI端侧设备(手机/端侧盒子等)一般使用ARM架构,因为需要低功耗。
X86指令集中的指令是复杂的,一条很长指令就可以很多功能;而ARM指令集的指令是很精简的,需要几条精简的短指令完成很多功能。
X86的方向是高性能方向,因为它追求一条指令完成很多功能;而ARM的方向是面向低功耗,要求指令尽可能精简。
【三】FP32,FP16以及Int8的区别?
常规精度一般使用FP32(32位浮点,单精度)占用4个字节,共32位;低精度则使用FP16(半精度浮点)占用2个字节,共16位,INT8(8位的定点整数)八位整型,占用1个字节等。
混合精度(Mixed precision)指使用FP32和FP16。 使用FP16 可以减少模型一半内存,但有些参数必须采用FP32才能保持模型性能。
虽然INT8精度低,但是数据量小、能耗低,计算速度相对更快,更符合端侧运算的特点。
不同精度进行量化的归程中,量化误差不可避免。
在模型训练阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的阶段,精度要求没有那么高,一般F16或者INT8就足够了,精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在端侧设备中。
【四】GPU显存占用和GPU利用率的定义
GPU在训练时有两个重要指标可以查看,即显存占用和GPU利用率。
显存指的是GPU的空间,即内存大小。显存可以用来放模型,数据等。
GPU 利用率主要的统计方式为:在采样周期内,GPU 上有 kernel 执行的时间百分比。可以简单理解为GPU计算单元的使用率。
【五】神经网络的显存占用分析
Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。
在整个神经网络训练周期中,在GPU上的显存占用主要包括:数据,模型参数,模型输出等。
数据侧:举个🌰,一个323128128的四维矩阵,其占用的显存 = 323128128*4 /1000 / 1000 = 6.3M
模型侧:占用显存的层包括卷积层,全连接层,BN层,梯度,优化器的参数等。
输出侧:占用的显存包括网络每一层计算出来的feature map以及对应的梯度等。
【六】算法模型部署逻辑?
我在之前专门沉淀了一篇关于算法模型部署逻辑的文章,大家可以直接进行阅读取用:
【七】影响模型inference速度的因素?
- FLOPs(模型总的加乘运算)
- MAC(内存访问成本)
- 并行度(模型inference时操作的并行度越高,速度越快)
- 计算平台(GPU,AI协处理器,CPU等)
【八】为何在AI端侧设备一般不使用传统图像算法?
AI端侧设备多聚焦于深度学习算法模型的加速与赋能,而传统图像算法在没有加速算子赋能的情况下,在AI端侧设备无法发挥最优的性能。
【九】减小模型内存占用有哪些办法?
- 模型剪枝
- 模型蒸馏
- 模型量化
- 模型结构调整
【十】有哪些经典的轻量化网络?
- SqueezeNet
- MobileNet
- ShuffleNet
- Xception
- GhostNet
【十一】模型参数计算?
首先,假设卷积核的尺寸是 K × K K \times K K×K,有 C C C个特征图作为输入,每个输出的特征图大小为 H × W H \times W H×W,输出为 M M M个特征图。
由于模型参数量主要由卷积,全连接层,BatchNorm层等部分组成,我们以卷积的参数量为例进行参数量的计算分析:
卷积核参数量:
M × C × K × K M\times C\times K\times K M×C×K×K
偏置参数量:
M M M
总体参数量:
M × C × K × K + M M\times C\times K\times K + M M×C×K×K+M
【十二】模型FLOPs怎么算?
同样,我们假设卷积核的尺寸是 K × K K\times K K×K,有 C C C个特征图作为输入,每个输出的特征图大小为 H × W H \times W H×W,输出为 M M M个特征图。
由于在模型中卷积一般占计算量的比重是最高的,我们依旧以卷积的计算量为例进行分析:
FLOPS(全大写):是floating point operations per second的缩写,意指每秒浮点运算次数,理解为计算速度。是一个衡量硬件性能的指标。
FLOPs(s小写):是floating point operations的缩写(s表示复数),意指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。
针对模型的计算量应该指的是FLOPs。
在上述情况下,卷积神经网络一次前向传播需要的乘法运算次数为:
H × W × M × C × K × K H\times W\times M\times C\times K\times K H×W×M×C×K×K
同时,所要进行的加法计算次数分为考虑偏置和不考虑偏置:
(1)考虑偏置的情况:
为了得到输出的特征图的一个未知的像素,我们需要进行
( C × K × K − 1 ) + ( C − 1 ) + 1 = C × K × K (C\times K\times K - 1) + (C - 1) + 1 = C \times K \times K (C×K×K−1)+(C−1)+1=C×K×K
次加法操作,其中 K × K K\times K K×K大小的卷积操作需要 K × K − 1 K\times K - 1 K×K−1次加法,由于有C个通道,所以需要将结果乘以C,每个通道间的数要相加,所以需要C - 1次加法,最后再加上偏置的1次加法。所以总的加法计算量如下:
H × W × M × C × K × K H\times W\times M\times C\times K\times K H×W×M×C×K×K
所以总的卷积运算计算量(乘法+加法):
2 × H × W × M × C × K × K 2 \times H\times W\times M\times C\times K\times K 2×H×W×M×C×K×K
(2)不考虑偏置的情况:
总的卷积计算量:
H × W × M × ( 2 × C × K × K − 1 ) H\times W\times M\times (2\times C\times K\times K - 1) H×W×M×(2×C×K×K−1)

----【图像处理基础】---- 【一】图像二值化的相关概念
图像二值化( Image Binarization)是将图像像素点的灰度值设置为0或255,也就是将整个图像呈现出明显的黑白效果的过程。二值图像每个像素只有两种取值:要么纯黑,要么纯白。
通过二值图像,将感兴趣目标和背景分离,能更好地分析物体的形状和轮廓。
图像二值化的方法有很多,其中最经典的就是采用阈值法(Thresholding)进行二值化。阈值法是指选取一个数字,大于它就设为白色,小于它就设为黑色。根据阈值选取方式的不同,又可以分为全局阈值和局部阈值。全局阈值(Global Method),指的是对整个图像中的每一个像素都选用相同的阈值。局部阈值(Local Method)又称自适应阈值(Adaptive Thresholding)。局部阈值法假定图像在一定区域内受到的光照比较接近。它用一个滑窗扫描图像,并取滑窗中心点亮度与滑窗内其他区域(称为邻域, neighborhood area)的亮度进行比较。如果中心点亮度高于邻域亮度,则将中心点设为白色,否则设为黑色。

【二】图像膨胀腐蚀的相关概念
图像的膨胀(dilation)和腐蚀(erosion)是两种基本的形态学运算,主要用来寻找图像中的极大区域和极小区域。
膨胀类似于“领域扩张”,将图像的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大。
腐蚀类似于“领域被蚕食”,将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小。
【三】高斯滤波的相关概念
图像为什么要滤波呢?一是为了消除图像在数字化过程中产生或者混入的噪声。二是为了提取图片对象的特征作为图像识别的特征模式。
什么是高斯噪声?首先,噪声在图像当中常表现为引起较强视觉效果的孤立像素点或像素块。简单来说,噪声的出现会给图像带来干扰,让图像变得不清楚。 高斯噪声就是它的概率密度函数服从高斯分布(即正态分布)的一类噪声。如果一个噪声,它的幅度分布服从高斯分布,而它的功率谱密度又是均匀分布的,则称它为高斯白噪声。
高斯滤波是一种线性平滑滤波,可以用来消除高斯噪声。其公式如下所示

高斯滤波过程:
假设高斯核:
那么高斯滤波计算过程就如下所示:

将这9个值加起来,就是中心点的高斯滤波的值。对所有点重复这个过程,就得到了高斯模糊后的图像。
二维高斯滤波能否分解为一维操作?可以进行分解,二维高斯滤波分解为两次一维高斯滤波,高斯二维公式可以推导为X轴与Y轴上的一维高斯公式。即使用一维高斯核先对图像逐行滤波,再对中间结果逐列滤波。
【四】边缘检测的相关概念
图像边缘是图像最基本的特征,指图像局部特征的不连续性。图像特征信息的突变处称之为边缘,例如灰度级的突变,颜色的突变,纹理结构的突变等。边缘是一个区域的结束,也是另一个区域的开始,利用该特征可以分割图像。

当我们看到一个有边缘的物体时,首先感受到的就是边缘。
上图(a)是一个理想的边缘所具备的特性。每个灰度级跃变到一个垂直的台阶上。而实际上,在图像采集系统的性能、采样率和获取图像的照明条件等因素的影响,得到的边缘往往是模糊的,边缘被模拟成具有“斜坡面”的剖面,如上图(b)所示,在这个模型中,模糊的边缘变得“宽”了,而清晰的边缘变得“窄”了。
图像的边缘有方向和幅度两种属性。边缘通常可以通过一阶导数或二阶导数检测得到。一阶导数是以最大值作为对应的边缘的位置,而二阶导数则以过零点作为对应边缘的位置。
常用的一阶导数边缘算子:Roberts算子、Sobel算子和Prewitt算子。
常用的二阶导数边缘算子:Laplacian 算子,此类算子对噪声敏感。
其他边缘算子:前面两类均是通过微分算子来检测图像边缘,还有一种就是Canny算子,其是在满足一定约束条件下推导出来的边缘检测最优化算子。
【五】图像高/低通滤波的相关概念
滤波操作是一种非常实用的图像数据预处理方法。滤波是一个信号处理领域的概念,而图像本身也可以看成是一个二维的信号,其中像素点数值的高低代表信号的强弱。
其中图像信息可以分为高频和低频两个维度:
高频:图像中灰度变化剧烈的点,一般是图像轮廓或者是噪声。
低频:图像中平坦的、变化不大的点,也就是图像中的大部分区域。
根据图像的高频与低频的特征,我们可以设计相应的高通与低通滤波器,高通滤波器可以检测保留图像中尖锐的、变化明显的地方。而低通滤波器可以让图像变得更光滑,去除图像中的噪声。
常见的低通滤波器有:线性的均值滤波器、高斯滤波器、非线性的双边滤波器、中值滤波器。
常见的高通滤波器有:Canny算子、Sobel算子、拉普拉斯算子等边缘滤波算子。
【六】图像中低频信息和高频信息的定义
低频信息(低频分量):表示图像中灰度值变化缓慢的区域,对应着图像中大块平坦的区域。
高频信息(高频分量):表示图像中灰度值变化剧烈的区域,对应着图像的边缘(轮廓)、噪声(之所以说噪声也是高频分量,是因为图像噪声在大部分情况下都是高频的)以及细节部分。
低频分量主要对整幅图像强度的综合度量。高频分量主要对图像边缘和轮廓的度量(人眼对高频分量比较敏感)。
傅立叶变换角度理解:从傅立叶变换的角度,我们可以将图像从灰度分布转化为频率分布。图像进行傅立叶变换之后得到的频谱图,就是图像梯度的分布图。具体来说,傅立叶频谱图上我们能看到明暗不一的亮点,实际上就是图像上某一点与领域点差异的强弱,即梯度的大小。如果一幅图像的各个位置的强度大小相等,则图像只存在低频分量。从图像的频谱图上看,只有一个主峰,且位于频率为零的位置。如果一幅图像的各个位置的强度变化剧烈,则图像不仅存在低频分量,同时也存在多种高频分量。从图像的频谱上看,不仅有一个主峰,同时也存在多个旁峰。图像中的低频分量就是图像中梯度较小的部分,高频分量则相反。
【七】色深的概念
色深(Color Depth)指的是色彩的深度,即精细度。在数字图像中,最小的单元是像素,在RGB三通道图像中,每个像素都由R,G,B三个通道组成,通常是24位的二进制位格式来表示。这表示颜色的2进制位数,就代表了色深。
【八】常用空间平滑技术
空间平滑(模糊)技术是广泛应用于图像处理以降低图像噪声的技术。
空间平滑技术可以分为两大类:局部平滑(Local Smoothing)和非局部平滑(Non-local Smoothing)
局部平滑方法利用附近的像素来平滑每个像素。通过设计不同的加权机制,产生了很多经典的局部平滑方法,例如高斯Smoothing,中值Smoothing,均值Smooyhing等。而非局部平滑方法不限于附近的像素,而是使用图像全局中普遍存在的冗余信息进行去噪。具体来说,以较大的图像块为单位在图像中寻找相似区域,再对这些区域求平均,并对中心图像块进行替换,能够较好地去掉图像中的噪声。在平均操作中,可以使用高斯,中位数以及均值等对相似图像块进行加权。
【九】RAW图像和RGB图像的区别?
RAW格式: 从相机传感器端获取的原始数字格式的数据, 又称为Bayer格式. 每个像素信息只有RGB中的某个颜色信息, 且每4个像素中有2个像素为G信息,1个R信息,1个B信息, 即GRBG格式。
RGB格式: RGB格式是由RAW数据插值计算后获取的、每个像素均包含了RGB三种颜色的信息。
【十】常用的色彩空间格式
深度学习中常用的色彩空间格式:RGB,RGBA,HSV,HLS,Lab,YCbCr,YUV等。

RGB色彩空间以Red(红)、Green(绿)、Blue(蓝)三种基本色为基础,进行不同程度的叠加,产生丰富而广泛的颜色,所以俗称三基色模式。
RGBA是代表Red(红)、Green(绿)、Blue(蓝)和Alpha(透明度)的色彩空间。
HSV色彩空间(Hue-色调、Saturation-饱和度、Value-亮度)将亮度从色彩中分解出来,在图像增强算法中用途很广。
HLS色彩空间,三个分量分别是色相(H)、亮度(L)、饱和度(S)。
Lab色彩空间是由CIE(国际照明委员会)制定的一种色彩模式。自然界中任何一点色都可以在Lab空间中表达出来,它的色彩空间比RGB空间还要大。
YCbCr进行了图像子采样,是视频图像和数字图像中常用的色彩空间。在通用的图像压缩算法中(如JPEG算法),首要的步骤就是将图像的颜色空间转换为YCbCr空间。
YUV色彩空间与RGB编码方式(色域)不同。RGB使用红、绿、蓝三原色来表示颜色。而YUV使用亮度、色度来表示颜色。
【十一】模型训练时常用的插值算法?
模型训练时Resize图像常用的插值算法有:最近邻插值,双线性插值以及双三次插值等。
最近邻插值:没考虑其他相邻像素点的影响,因而重新采样后灰度值有明显的不连续性,图像质量损失较大,存在马赛克和锯齿现象。
双线性插值:也叫一阶插值,它是利用了待求像素点在源图像中4个最近邻像素之间的相关性,通过两次线性插值得到待求像素点的值。
双三次插值:也叫立方卷积插值,它是利用了待求像素点在源图像中相邻的16个像素点的值,即这16个像素点的加权平均。
【十二】常用图像预处理操作?
一般先对数据进行归一化(Normalization)处理【0,1】,再进行标准化(Standardization)操作,用大数定理将数据转化为一个标准正态分布,最后再进行一些数据增强处理。
归一化后,可以提升模型精度。不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
标准化后,可以加速模型收敛。最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
----【计算机基础】---- 【一】深度学习中常用的Linux命令汇总
1.man:man command,可以查看某个命令的帮助文档,按q退出帮助文档 2.cd:用于切换目录,cd - 可以在最近两次目录之间来回切换 3.touch:touch file创建文件。 4.ls:ls -lh可以列出当前目录下文件的详细信息。 5.pwd:pwd命令以绝对路径的方式显示用户当前的工作目录 6.cat:cat file显示文件内容。 7.mkdir:mkdir dir可以创建一个目录;mkdir -p dir/xxx/xxx可以递归创建目录。 8.cat:cat file显示文件内容,按q退出。 9.more:more file显示文件内容,按q退出。 10.grep:筛选命令,比如我想查找当前目录下的py文件(ls -lh | grep .py) 11.whereis:可以查找含有制定关键字的文件,如whereis python3 重定向 > 和 >>:Linux 允许将命令执行结果重定向到一个文件,将本应显示在终端上的内容输出/追加到指定文件中。其中>表示输出,会覆盖原有文件;>>表示追加,会将内容追加到已有文件的末尾。 12.cp:cp dst1 dst2复制文件;cp -r dst1 dst2复制文件夹。 13.mv:mv dst1 dst2可以移动文件、目录,也可以给文件或目录重命名。 14.zip:zip file.zip file压缩文件;zip dir.zip -r dir压缩文件夹。 15.unzip:unzip file.zip解压由zip命令压缩的.zip文件。 16.tar: tar -cvf file.tar dir打包文件夹 tar -xvf file.tar解包 tar -czvf file.tar.gz dir压缩文件夹 tar -zxvf file.tar.gz解压 17.chmod:chmod -R 777 data将整个data文件夹修改为任何人可读写。 18.ps:ps aux列出所有进程的详细信息。 19.kill:kill PID根据PID杀死进程。 20.df:df -h 查看磁盘空间。 21.du:du -h dir查看文件夹大小。 22.top:实时查看系统的运行状态,如 CPU、内存、进程的信息。 23wget:wget url从指定url下载文件。 24.ln:ln -s dst1 dst2建立文件的软链接,类似于windows的快捷方式;ln dst1 dst2建立文件的硬链接。无论哪种链接,dst1都最好使用绝对路径。 25.top:我们可以使用top命令实时的对系统处理器的状态进行监视。 26.apt-get:用于安装,升级和清理包。 27.vim:对文件内容进行编辑。 28.nvidia-smi:对GPU使用情况进行查看。 29.nohup sh test.sh &:程序后台运行且不挂断。 30.find:这个命令用于查找文件,功能强大。find . -name "*.c"表示查找当前目录及其子目录下所有扩展名是.c的文件。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
【二】计算机多线程和多进程的区别?
进程和线程的基本概念:
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态的概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内的调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
一个程序至少一个进程,一个进程至少一个线程。
线程的意义:
每个进程都有自己的地址空间,即进程空间,在网络环境下,一个服务器通常需要接收不确定数量用户的并发请求,为每一个请求都创建一个进程显然行不通(系统开销大响应用户请求效率低),因此操作系统中线程概念被引进。线程的执行过程是线性的,尽管中间会发生中断或者暂停,但是进程所拥有的资源只为该线状执行过程服务,一旦发生线程切换,这些资源需要被保护起来。进程分为单线程进程和多线程进程,单线程进程宏观来看也是线性执行过程,微观上只有单一的执行过程。多线程进程宏观是线性的,微观上多个执行操作。
进程和线程的区别:
地址空间:同一进程中的线程共享本进程的地址空间,而进程之间则是独立的地址空间。
资源拥有:同一进程内的线程共享进程的资源如内存、I/O、CPU等,但是进程之间的资源是独立的。(一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃可能导致整个进程都死掉。所以多进程比多线程健壮。进程切换时,消耗的资源大、效率差。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程。)
执行过程:每个独立的线程都有一个程序运行的入口、顺序执行序列和程序出口。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。(线程是基于进程的)
线程是处理器调度的基本单元,但进程不是。
两者均可并发执行。
进程和线程的优缺点:
线程执行开销小,但是不利于资源的管理和保护。
进程执行开销大,但是能够很好的进行资源管理和保护。
何时使用多进程,何时使用多线程:
对资源的管理和保护要求高,不限制开销和效率时,使用多进程。(CPU密集型任务)
要求效率高,频繁切换时,资源的保护管理要求不是很高时,使用多线程。(I/O密集型任务)
【三】TCP/IP四层模型的相关概念
TCP/IP四层模型:
-
应用层:负责各种不同应用之间的协议,如文件传输协议(FTP),远程登陆协议(Telnet),电子邮件协议(SMTP),网络文件服务协议(NFS),网络管理协议(SNMP)等。
-
传输层:负责可靠传输的TCP协议、高效传输的UDP协议。
-
网络层:负责寻址(准确找到对方设备)的IP,ICMP,ARP,RARP等协议。
-
数据链路层:负责将数字信号在物理通道(网线)中准确传输。
四层模型逻辑:
发送端是由上至下,把上层来的数据在头部加上各层协议的数据(部首)再下发给下层。
接受端则由下而上,把从下层接收到的数据进行解密和去掉头部的部首后再发送给上层。
层层加密和解密后,应用层最终拿到了需要的数据。
【四】OSI七层模型的相关概念

----【开放性问题】---- 这些问题基于我的思考提出,希望除了能给大家带来面试的思考,也能给大家带来面试以外的思考。这些问题没有标准答案,我相信每个人心中都有自己灵光一现的创造,你的呢?
【一】如何给一个完全没有接触过机器学习的人介绍机器学习?
这个问题受启发于最近遇到的一个事件,让我觉得这个问题也蛮重要的,如何用通俗易懂的语言,阐述深沉的思考。
【二】Transformer会完全替代CNN吗?
Transformer是近年比较火热的算法模型,我也相信其会逐步推广产生更多价值。我觉得这个问题依然可以从我经常提到的业务侧,竞赛侧,研究侧三个维度去考虑,会有一个比较踏实的思考。
【三】AI算法如何赋能电商业务?
我觉得这是电商互联网公司都会问的问题,也是一个非常有价值的问题。电商业务作为现金流业务,是需要AI去赋能提效的,AI与电商业务的结合,也会让算法侧更踏实的去沉淀。
【四】AI算法如何赋能传统工业?
传统工业的数字化,智能化,降本增效是大势所趋。需要我们不断深入挖掘传统工业面临的提效痛点,再反推出使用合适的AI算法进行赋能,我觉得这是非常值得去关注思考的点。
【五】黑盒系统如何去强约束与强优化?
毫无疑问,现在的AI技术建立在黑盒系统上,而黑盒系统难免会引入随机性与不确定性。这种情况下如何让算法模型安全可控,并不断提升性能是一个非常值得思考的问题。
【六】非标场景如何沉淀?
CV算法在实际应用中的非标场景非常多样,可能不同场景很多东西要推倒重来,要从头顶到尾重新搭建整个解决方案,这无疑会增加整个解决方案的成本,如何从非标场景中沉淀共性,优化解决方案的实施,打造更好的产品,这是一个非常值得去探索的问题。
【七】如何对已有业务进行优化?
我觉得这个优化是多方面的,我们可以优化已有业务的整个开发流程,也可以优化我们在这个业务逻辑里的效率,也可以基于这个业务进行新的拓展与探索。
【八】工作中业务侧/竞赛侧/研究侧的配比
算法工程师在工作中主要面对业务侧/竞赛侧/研究侧三方面的事务,如何进行合理的项目配比,时间分配,投入产出评估等,都是非常值得去思考的问题。
【九】你能想到哪些新的AI产品形式?
AI赋能各行各业的探索还在持续推进,并且有很多实际可行的解决方案产出,我觉得保持对AI产品形式的创新思考是非常有价值的,这是一个增量方向。
【十】如何提高AI业务中各部门之间的沟通/合作的效率?
这是工业界中一个非常现实的问题,那就是如何优化整个AI业务开发的流程,降本增效。有时候往往最花时间的不是算法侧的开发,而是不同部门之间的信息差,沟通不畅,合作不愉快等情况导致的低效。
【十一】竞赛侧与研究侧的成果如何沉淀到业务中?
我觉得这是一个非常有价值的问题,不管是现在大的经济环境还是AI发展的现状,AI业务深耕与扩展来获取利润是重中之重。只做研究和竞赛是远远不够的。
【十二】如何扩展已有业务?
在已有业务中跟随是很安全的事,但是如何开拓新的增长点是非常有价值的事。除了技术角度,还要从产品角度,成本角度,客户角度去把握。
精致的结尾
最后,感谢大家读完这篇文章,希望能给大家带来帮助~后续我会持续撰写“三年面试五年模拟”之独孤九剑的系列文章,大家敬请期待!

-
-
相关阅读:
总抱怨Mac运行速度又卡又慢?这些方法你用得上
企业文化对于营造积极向上的工作氛围有多大影响?
buuctf刷题9 (反序列化逃逸&shtml-SSI远程命令执行&idna与utf-8编码漏洞)
React 脚手架
根据代码获取properties对应信息
jenkins的安装配置并集成jdk、git
IDEA中没有Web Application的问题
逐字稿 | ViT论文逐段精读【论文精读】
PAT 乙级1096大美数
【iOS】引用计数与autorelease
- 原文地址:https://blog.csdn.net/Rocky6688/article/details/125953962
