-
[C语言刷题篇]链表运用讲解
目录
给大家推荐一款神器牛客网以下题型及方法牛客都有,及企业面试高频题

NC25 删除有序链表中重复的元素-I
描述
删除给出链表中的重复元素(链表中元素从小到大有序),使链表中的所有元素都只出现一次
例如:
给出的链表为1→1→2,返回1→2.
给出的链表为1→1→2→3→3,返回1→2→3.数据范围:链表长度满足0≤n≤100,链表中任意节点的值满足val∣≤100
进阶:空间复杂度 O(1)O(1),时间复杂度 O(n)O(n)

我们可以在题目得到这样的信息:
- 给定一个从小到大排好序的链表
- 删去链表中重复的元素,每个值只留下一个节点
方法一:遍历删除(推荐使用)
思路:
既然连续相同的元素只留下一个,我们留下哪一个最好呢?当然是遇到的第一个元素了!
- if(cur->val==cut->next->val)
- cur->var=cur->next->next;
因为第一个元素直接就与前面的链表节点连接好了,前面就不用管了,只需要跳过后面重复的元素,连接第一个不重复的元素就可以了,在链表中连接后面的元素总比连接前面的元素更方便嘛,因为不能逆序访问。
具体做法:
- step 1:判断链表是否为空链表,空链表不处理直接返回。
- step 2:使用一个指针遍历链表,如果指针当前节点与下一个节点的值相同,我们就跳过下一个节点,当前节点直接连接下个节点的后一位。
- step 3:如果当前节点与下一个节点值不同,继续往后遍历。
- step 4:循环过程中每次用到了两个节点值,要检查连续两个节点是否为空。

动图展示:

核心代码
- struct ListNode* deleteDuplicates(struct ListNode* head ) {
- if(head == NULL || head->next == NULL) return head;
- struct ListNode *p=head,*pn = head->next;
- while(p){
- if(p->val == pn->val){
- while(pn&&pn->val == p->val) //判断
- pn = pn->next;
- p->next = pn;//删除
- }
- p = p->next;
- }
- return head;
- // write code here
- }
复杂度分析:
- 时间复杂度:O(n)O(n)O(n),其中nnn为链表长度,遍历一次链表
- 空间复杂度:O(1)O(1)O(1),常数级指针变量使用,没有使用额外的辅助空间
方法二:递归求解
核心思想:
采用递归的思想求解。每次递归则需要比较并删除重复的元素。本次的思想跟递归逆置链表很像,唯一的不同就是处理逻辑不同。删除重复链表的处理逻辑是每次都要删除当前节点(如果当前节点与下一个节点相同时候)核心代码:
- ListNode* deleteDuplicates(ListNode* head) {
- if (head == nullptr || head->next == nullptr) //节点不存在或者只有一个节点时,递归结束
- return head;
- head->next = deleteDuplicates(head->next); //递归体,每次递归从下一个节点开始
- if (head->val == head->next->val) //比较当前元素和下一个元素的值是否相等,相等则直接删除当前节点
- head = head->next; //head指针指向下一个节点,表明当前节点丢失,已经不再属于这个链表
- return head; //返回本次递归的结果
- }
复杂度分析:
递归n次,因此时间复杂度为O(N)。而每次递归都需要一个额外的变量保存,因此空间复杂度为O(N),时间复杂度O(n)
反转链表
描述
给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。
数据范围:0≤n≤1000
要求:空间复杂度 O(1)O(1) ,时间复杂度 O(n)O(n) 。
如当输入链表{1,2,3}时,
经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。
以上转换过程如下图所示:


解法:迭代
- 在遍历链表时,将当前节点的next 指针改为指向前一个节点。由于节点没有引用其前一个节点,因此必须事先存储其前一个节点。在更改引用之前,还需要存储后一个节点。最后返回新的头引用。
- 图解:
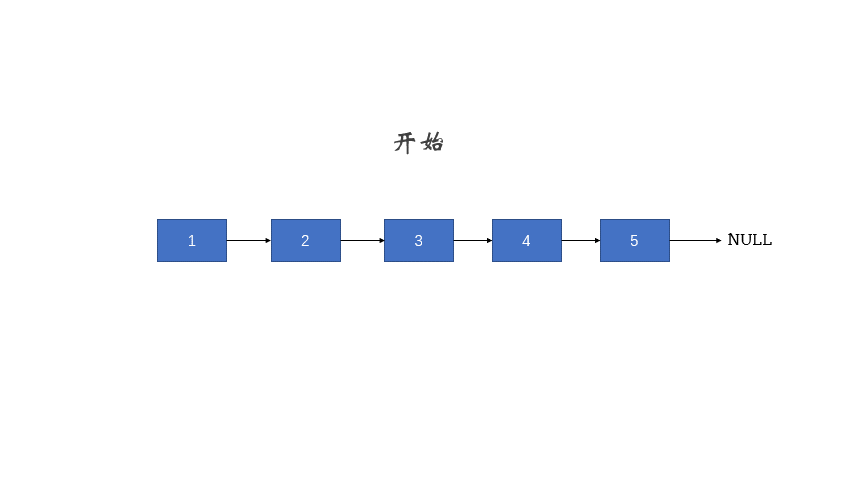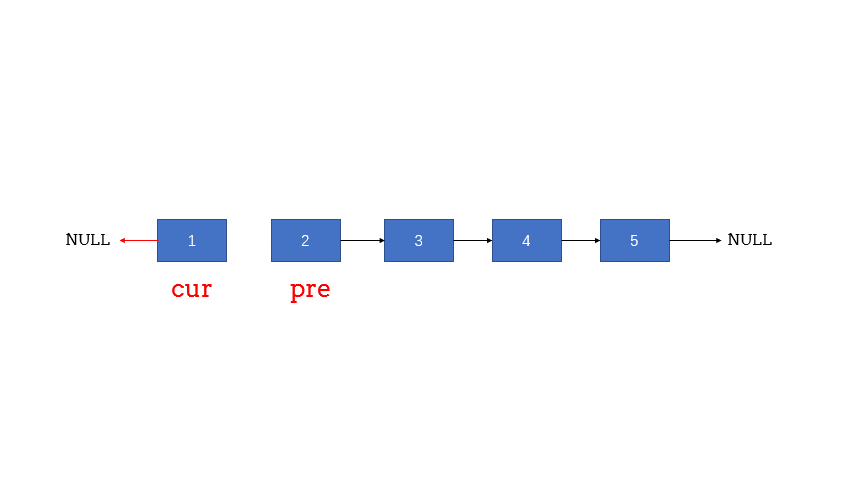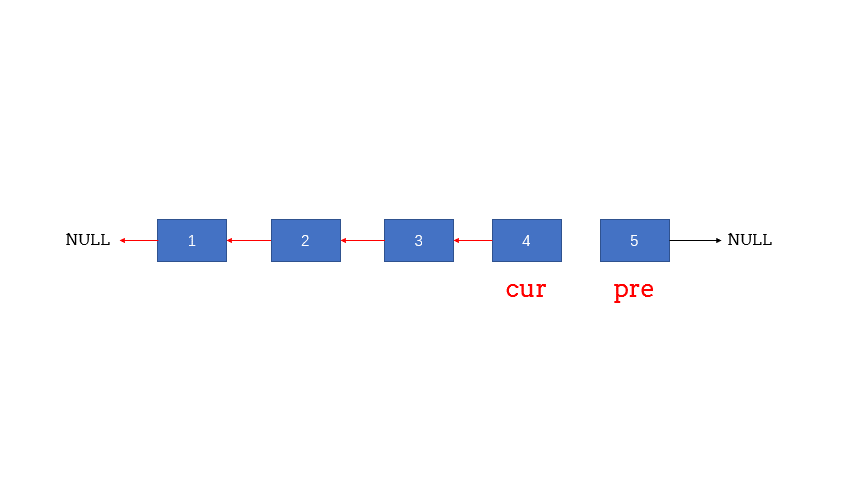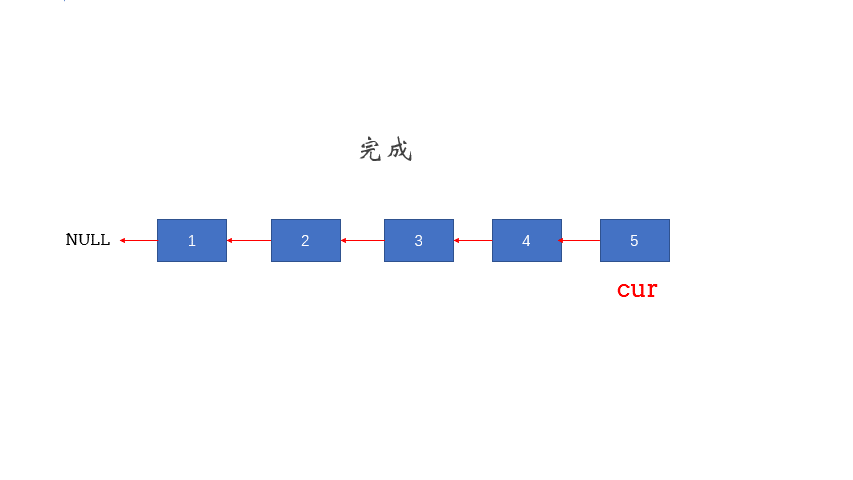
复杂度分析:
时间复杂度:O(N),其中 N 是链表的长度。需要遍历链表一次。
空间复杂度:O(1),常数空间复杂度
代码展示:
- ```/**
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- *
- * C语言声明定义全局变量请加上static,防止重复定义
- */
- struct ListNode* ReverseList(struct ListNode* pHead ) {
- if(!pHead)return NULL;
- if(pHead->next==NULL)return pHead;
- struct ListNode *p,*t;
- t=pHead->next;
- p=pHead;p->next=NULL;
- while(t){
- p=t;
- t=t->next;
- p->next=pHead;
- pHead=p;
- }
- return p;
- }
点击右边链接牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网

-
相关阅读:
【数据结构算法】小结
python爬虫代理ip关于设置proxies的问题
java EE初阶 — 线程的状态
基于多通道PCIe-DMA的JESD204B AD/DA、CameraLink/SDI采集显示、SRIO/光纤采集回放
Win32-hash算法-ALG_ID详解
第六十二 CSP的常见问题 - CSP进程是否消耗许可证?,我如何编译CSP页面
挖矿病毒分析(centos7)
约会怎么走到目的地最近呢?一文讲清所有最短路算法问题
Vue2组件传值(通信)的方式
数据库基本增删改查语法和多表联查的方式
- 原文地址:https://blog.csdn.net/weixin_51568389/article/details/126002076
