-
pandas read_excel 参数及使用
pandas.read_excel(io, sheet_name…)
参数说明
- io: 文件路径
- sheet_name 列名,默认为0, 可以是数字/列名/list(数字、列名)
- header 标题行,默认第一行,可以是数字/list
- names 补充列名, names元素的个数必须和dataframe的列数一致,name=[0,1,2…]: 0,1,2将作为列名
- index_col 指定行索引, 默认None, 可以是数字/list
- usecols: 指定读取列,
usecols=[1,2,3] # 读取2-4列
usecols=None, #读取所有列 - squeeze: 如果源数据只有一列, squeeze=False为DataFrame,squeeze=True时为Series
- converters={
‘收入’ lambda x: x/100 # 收入除以100
} - skiprows: 省略指定行数据,第一行开始
- skipfooter: 省略指定行数据,最后一行开始
- dtype: dtype={
‘grade’: np.float32
} # 读取为类型数据
使用
创建一个Excel文件
import pandas as pd import numpy as np- 1
- 2
# 指定索引列 pd.read_excel('./fakeExcel.xlsx', index_col=0) # 第0列作为标题- 1
- 2

pd.read_excel('fakeExcel.xlsx', header=0) # 指定表头行- 1
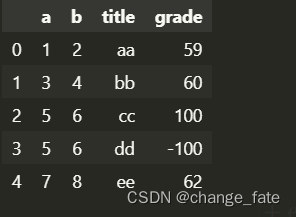
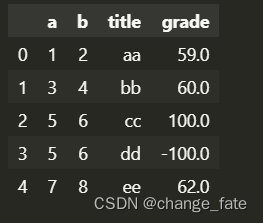
# 指定读取格式转换 # 适合数据处理精度要求比较高或者速度要求比较快的情况 pd.read_excel('fakeExcel.xlsx', dtype={ 'grade': np.float32 }) # 指定表头列- 1
- 2
- 3
- 4
- 5
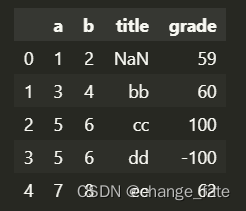
# 自定义缺失值, 如年龄为负数时,清空,显示NAN pd.read_excel('fakeExcel.xlsx', na_values={ 'title': 'aa' })- 1
- 2
- 3
- 4
# 处理注释行 pd.read_excel('fakeExcel.xlsx', sheet_name=1, comment='#')- 1
- 2
- 3
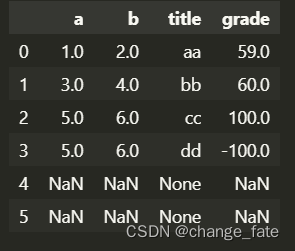
# 列操作, 列减少2 data['grade'] = data['grade'] - 2 data- 1
- 2
- 3
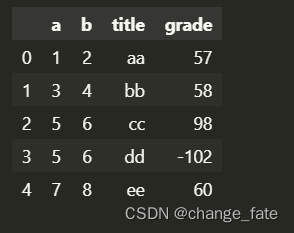
# 删除列: # 改变内存数据 # 建议使用不改变内存的函数, 通过赋值修改原数据 if True: del data["a"] # 不改变内存数据(返回新数据) else: data = data.drop('a', axis=1) data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

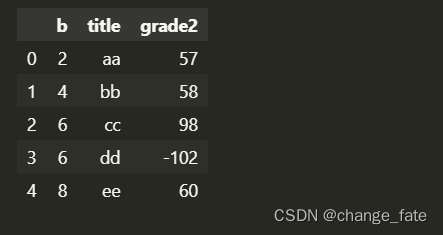
# 重命令列 data.rename(columns={ 'grade': 'grade2' }) # 或者 data.columns = ['b', 'title', 'grade2']- 1
- 2
- 3
- 4
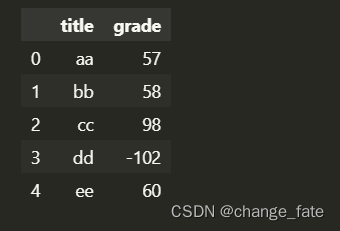
# 保留指定的列 data[['title', 'grade']]- 1
- 2
# 过滤数据 data[data['grade'] > 60]- 1
- 2
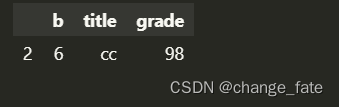
data[data['title'] == 'bb']- 1
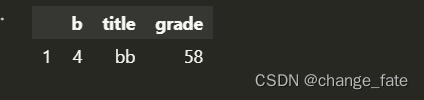
# 值排序 data.sort_values('grade', ascending = True)- 1
- 2
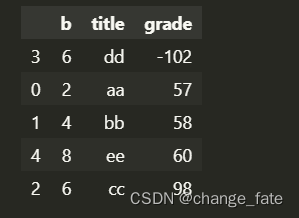
# names 参数的作用, 相当于rename pd.read_excel('fakeExcel.xlsx', header=0, names=[0,1,2])- 1
- 2

# 删除指定字符串的行 data.drop(data.index[(newData['line3'] == '--')], inplace=True) # inplace是否直接替换原数据- 1
- 2
- 3
-
相关阅读:
Zip4j使用
【AGC】崩溃服务符号表不能解析成可阅读代码问题
安科瑞电气防火限流式保护器在小型人员密集场所的应用
CSS的元素显示模式
【Linux驱动开发知识点】
【Leetcode】1444. Number of Ways of Cutting a Pizza
React之组件实例的三大属性之props
五、Spring Boot 整合持久层技术(2)
22 mysql range 查询
SuperMap GIS基础软件地图瓦片问题Q&A
- 原文地址:https://blog.csdn.net/change_fate/article/details/126012860