-
使用match-lstm和答案指针进行机器理解

使用match-lstm和答案指针进行机器理解
Abstract
阅读理解任务发布了一个新的数据集斯坦福问答数据集(SQuAD),该数据集提供了大量真实的问题及其答案,这些问题及其答案是人类通过众包创建的,该答案的长度时可变的。本文基于Match-LSTM和指针网络提出了一个模型用于解决以上问题。
1. Instruction
在一些数据集中,问题不提供候选答案,预计机器将使用给定文本中的任何token或token序列来回答问题。显然,没有给定候选答案的问题更具有挑战性,因为候选答案集合基本上包括文本中所有可能的token或token序列,因此要大得多。此外,答案跨越多个token的问题比答案只有一个token的问题更具有挑战性。Table 1 显示了一段样本文本及其相关的三个问题。

本文提出一种新的端到端神经体系结构来解决SQuAD中定义的机器阅读理解问题:提出了两种端到端的机器阅读理解神经网络模型,将Match-LSTM和指针网络相结合来处理数据集的特殊属性。
在未知测试数据集上取得了59.%的匹配准确率和70.3%的F1匹配率。
2.Model
2.1 Match-LSTM
作者在之前提出了一个预测文本蕴含的Match-LSTM模型。
- 在语篇蕴含中,给出两个句子,其中一个是前提,一个是假设。
- 为了预测前提是否包含假设,Match-LSTM模型顺序的检测假设的token。在假设的每个位置,使用注意力获得前提的加权向量表征。
- 然后,将该加权前提和假设的当前token的向量表示相结合,并将其馈送到LSTM中,作者称之为math-LSTM。
- match-LSTM基本上顺序地将注意力加权前提与假设的每个token的匹配聚集在一起,并使用聚集的匹配结果来做出最终预测。

2.2 Pointer-Net
指针网络解决了一类特殊的问题:想要生成一个输出序列,其中的单词必须来自输入序列。与固定词汇表选择输出token不同,pt-net使用attention机制作为pointer,从输入序列中选择一个位置,并将这个位置所指的单词作为输出。
受到指针网络的启发,本文采用了它来构造答案。
2.3 Method
本文要解决的问题可以表述为以下形式:
-
获得一段文本,称之为段落,以及与该段落有关的问题。
- 段落用矩阵 P ∈ R d × p P\in R^{d\times p} P∈Rd×p表示,其中P是段落的tokens长度,d是单词嵌入的维度。
- 问题由矩阵 Q ∈ R d × Q Q\in R^{d\times Q} Q∈Rd×Q表示,其中Q是问题的长度。
-
目标是从段落中确定一个子序列作为问题的答案。
具体来说,将答案表示为整数序列 a = a 1 , . . . , a={a_1,...,} a=a1,...,,其中每个 a i a_i ai介于1到P之间。利用pt-net选择答案的开始和结束,将要预测的答案表示为两个整数 a = ( a s , a e ) a=(a_s,a_e) a=(as,ae)。

2.3.1 LSTM Preprocessing Layer
使用单向LSTM对passage和question进行预处理,将上下文我信息合并到文章和问题中每个token的表示中。
H p = L S T M ⟶ ( P ) H^p=\overset{\longrightarrow}{LSTM}(P) Hp=LSTM⟶(P)
H q = L S T M ⟶ ( Q ) H^q=\overset{\longrightarrow}{LSTM}(Q) Hq=LSTM⟶(Q)
其中 H p H^p Hp是passage的向量表示, H q H^q Hq是question的向量表示。
2.3.2 Match-LSTM Layer
本文将文本蕴含的match-LSTM模型应用到MC问题。question当做premise,将passage当做hypothesis,match-LSTM按顺序遍历该passage。在passage的第i个位置,用标准的word-by-word attention得到attention向量 α → i ∈ R Q \overset{\rightarrow}{\alpha}_i\in R^Q α→i∈RQ。

其中 h → i − 1 r ∈ R l \overset{\rightarrow}{h}^r_{i-1}\in R^l h→i−1r∈Rl表示第i-1处的match-LSTM的隐藏向量。 ⊗ e Q \otimes e_Q ⊗eQ表示将左侧的向量或标量重复复制Q词,来生成矩阵或行向量(在列方向上扩展Q列,在新的维度上进行堆叠)。然后用注意力权重 α → i , j \overset{\rightarrow}{\alpha}_{i,j} α→i,j 对questions的隐藏层输出进行加权,并将其跟passage的隐层输出进行拼接,得到一个新的向量 z → i \overset{\rightarrow}{z}_i z→i:

将其馈送到LSTM:

本文又在反方向构建了一个match-LSTM,为了获得一个表示形式,用于对段落中的每个tokens从两个方向进行上下文编码:

再用相似的方法获得 z ← i \overset{\leftarrow}{z}_i z←i。

2.4 Answer Pointer Layer
2.4.1 The Sequence Model
为了生成用 a k a_k ak表示的第k个答案span。首先使用注意力机制获取注意力权重向量 β k ∈ R ( P + 1 ) \beta _k \in R^{(P+1)} βk∈R(P+1),其中 β k , j ( i ≤ j ≤ P + 1 ) \beta_{k,j}(i\le j\le P+1) βk,j(i≤j≤P+1)是从段落中选择第j个token作为答案中的第k个token的概率。



将生成的答案序列建模为:

损失函数:

2.4.2 The Boundary Model
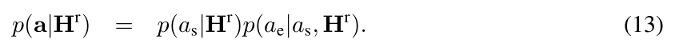
边界模型的工作方式和序列模型相似,不同之处是只需要预测两个索引 a s , a e a_s,a_e as,ae.3. Example
3.1 Results

4. 启示
- 比较早期的MC模型,但是引用指针网络进行边界预测是一个很大的创新点。
- 文本蕴含和MC模型都可以移植到其他NLP领域。
- 欢迎关注微信公众号:自然语言处理CS,一起来交流NLP。
-
相关阅读:
编程大师-分布式
CCITT 标准的CRC-16检验算法
SpringBoot项目实战:笔记记录分享网站-计算机毕业设计选题推荐
数据结构 桶排序 基数排序
服务端业务设计及源码
sklearn混淆矩阵的计算和seaborn可视化
线程安全问题
【通用设计方法】之接收异常保护
七大员证书继续教育怎么弄?需要几年继续教育一次呢?甘建二
TypeScript学习笔记
- 原文地址:https://blog.csdn.net/Jeaksun/article/details/126015659