-
【讲座笔记】如何在稀烂的数据中做深度学习?
intro:深度学习取得的成果不仅是强大模型的功能,更是因为有海量的优质数据做支撑。但当训练可用的数据很差、存在各种各样的问题时该怎么办?
本讲座介绍了几种不完美的数据情形,例如联邦学习、长尾学习、噪声标签学习、持续学习等,并介绍如何使深度学习方法应对这些情形,依然保持强大。Success of Deep Learning
好的数据集是怎样的?
Large-scaled labeled data
Good training data should have the following traits:- Accessible
- Large-scaled
- Balanced
- Clean
如果你的数据不满足上面的 完美数据集 特点,如何让深度学习仍可以有效进行?
- Data is locally stored (当数据不在手中,如何利用别人的数据来训练自己的模型):联邦学习,
Federated Learning - Class distribution is imbalanced (当数据类别不均衡):长尾学习,
Long-tail Learning - Label is not accurate(当数据较脏):
Noisy Label Learning - Partial data is available(当数据仅部分可得):持续学习,
Continual Learning
联邦学习
Federated Learning Framework
联邦学习,不传数据,传模型参数。
- 适用场景:很多数据不可得,是隐私数据。
- 联邦学习由Google于2016年提出。目标是 learn a model without centralized training.
- 数据私有地存储在每个客户机中。
- 模型分别进行训练,并在服务器上聚合。
- We send model parameters, other than data.
主要难点:Data heterogeneity (数据异构)
- Number of training data on each client is different.
- Classes for training on each client is different.
- Imbalance ratio on each client is different.
其他难点:
- personalized FL,个性化联邦学习
- Communication and Compression,需要传输和压缩
- Preserving Privacy,保护隐私(有的能通过模型反推数据)
- Fairness,公平(模型要一样好)
- Data Poisoning Attacks,数据投毒攻击(有人想用坏数据来破坏模型)
- Incentive,奖励机制(有人想白嫖,需要量化对模型的贡献)
- Vertical Federated Learning
- …
长尾学习
- 适用场景:类别不平衡问题。
一个类别的数据量远超过另一个类别的数据量。
majority class & minority class
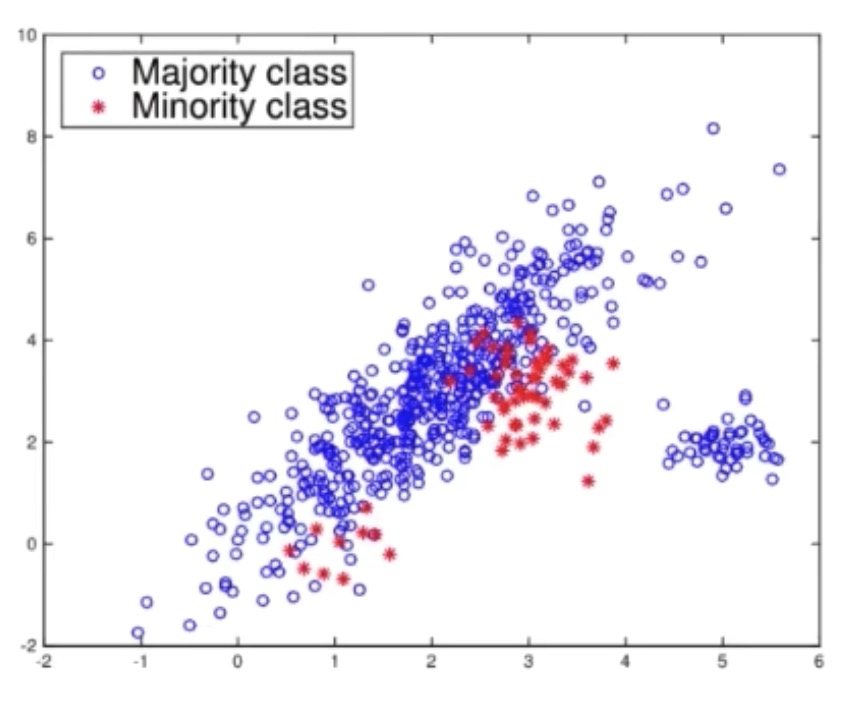
针对数据不平衡问题,在深度学习流行以前,主要有两类常用的方法:
- 重采样,re-sampling method(使数据更平衡)
- 重加权,re-weighting method (比如让某类惩罚更严重)
在深度学习问题面前,又有了新的挑战:
- 分类任务的类别更多了,比如有上千类。不平衡问题变得很复杂,比如有一半很多一半很少?还是有大部分类很多,几个类很少?
- 多数深度学习模型是端到端的。
于是,在2019年提出了一个新的概念:长尾学习。
和传统的不平衡学习相比,长尾学习具有以下特点:
- 类别很多
- 每个类别的样本数服从 power-law distribution
- focus on deep learning models(most for CV tasks)
方法 Methodology:
- Re-weighting,少的类如果分错了,则给予更严重的惩罚
- Augmentation,数据增强
- Decoupling,RS or RW may damage feature representation. They only help build the classifier.
- Ensemble Learning,集成学习,训练多个模型然后投票
噪声标签学习
适用场景:标签存在一定的错误率。
方法:
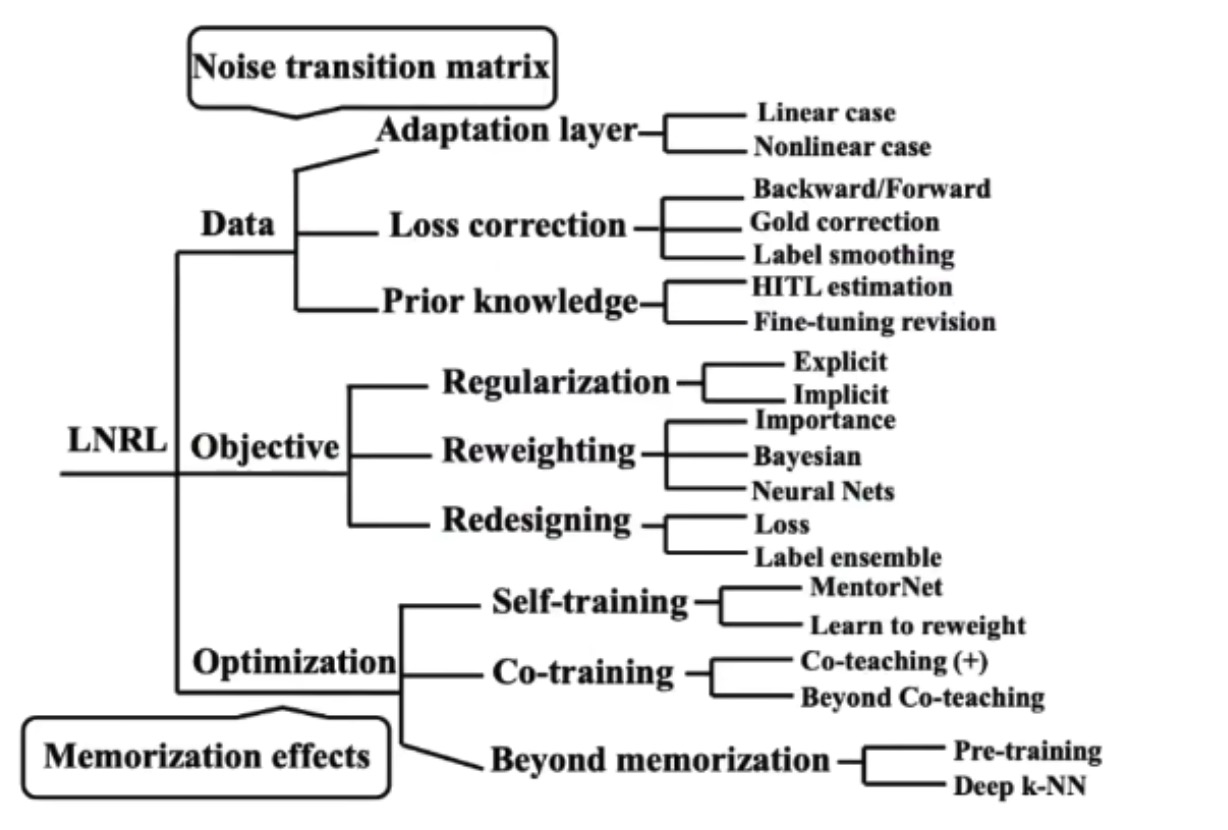
Image source: B. Han et al., “A Survey of label-noise Representation Learning: Past, Present and Future”, 2020.
例如:
估计噪声转移矩阵,即估计某一类的样本会有多大的概率分成另一类。Co-Teaching:

Future Direction: OOD Noise
Clean, ID noise, OOD Noise(out of distribution)持续学习
(终生学习、增量学习、数据流学习)
Data comes as time goes on.存在的问题:
- 内存有限,以往的样本会被丢弃
- 数据分布可能会变
- 以往的东西不能忘
trade-off:模型既要稳定,又要可塑。stability & plasticity
深度学习模型的可塑性是较容易的,但也很容易忘记以前学会的东西,这个现象即灾难性遗忘(catastrophic forgetting)。
Replay methods:
在旧样本里挑一些具有代表性的,在新的训练中也加进来。
Select and keep a few representative samples in each task. Incorporate them into the training process of future tasks.怎么用? 例如 GEM,加入了限制条件,新的模型在老的样本上的表现不能变差。
怎么选? 例如数据集压缩,Dataset Condensation。回放模型的缺点:
- 不能满足终生学习的要求,总要扔掉很多数据。
- 有些数据是不能存的。
但SOTA 的方法仍是基于 Dataset Condensation 的。
regularization-based method 基于正则的方法
此类方法不存过往的数据,可以把模型存下来。在优化的过程中,要求新学的模型不能和老模型相差太多。
elastic weight consolidationparameter isolation methods 参数隔离方法
为每个任务指定不同的模型参数,以防止可能的遗忘。dedicate different model parameters to each task, to prevent any possible forgetting.
Generally, the important parameters of the past tasks are fixed.模型很大,不是所有的参数都有用,所以大的模型可以压缩成小的模型,保持其功能。所以在每次学习后,将模型进行压缩,下一次再利用空出来的参数空间来学习下一个任务。

Conclusion
以上讨论了深度学习模型训练时的四种不完美数据:
- federated learning: data is not centralized.
- Long-tail learning: data is class imbalanced.
- Noisy label learning: data is mislabeled.
- Continual learning: data is gradually coming.
Reference:
厦门大学 卢杨 信息技术前沿讲座
A u t h o r : C h i e r Author: Chier Author:Chier
-
相关阅读:
面试突击--Java基础面试题(至尊典藏版)
5G工业互联阶段二:5G产线工控网
Matlab绘图
VirtualLab教程特辑
Nginx反向代理和负载均衡
2.5A强驱动能力,舞台灯光驱动TMI8263锻造“中国芯”
【附源码】Python计算机毕业设计木几画室管理系统
Transformer-深度学习-台湾大学李宏毅-课程笔记
交换奇偶位
css
- 原文地址:https://blog.csdn.net/m0_38068229/article/details/126010332