-
【通道注意力机制】SENet
概述
作者发言:链接
SENet的核心是提出了应用了通道注意力机制的SE Block,显式地建模特征通道之间的相互依赖关系,让网络自动学习每个通道的重要程度,然后按照这个重要程度提升有用的特征,抑制无用的特征(特征重标定策略)。类似于之前学习到的attention-unet中的attention-gate,也是一种即插即用的结构。细节
SE Block
CNN的核心是卷积操作,它将空间上(spatial)的信息和特征维度上(channel-wise)的信息进行聚合,过往的研究尝试从空间维度上来提升网络的性能,本文尝试从特征维度进行考虑,提出了SE Block,如下图所示:
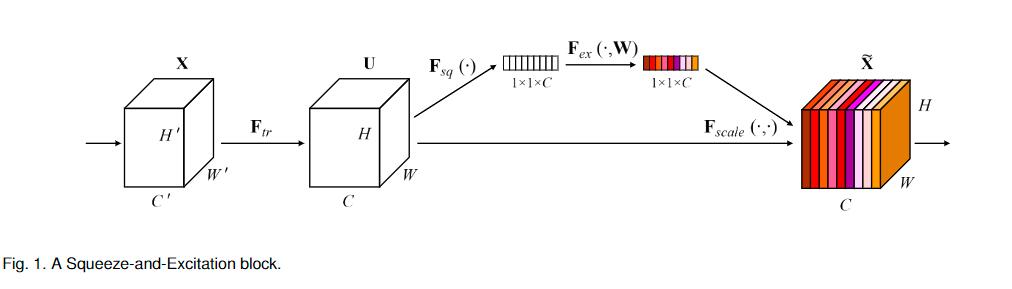
首先是 Squeeze 操作,顺着channel维度来进行特征压缩,将每个二维的特征图压缩成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。
其次是 Excitation 操作,为每个二维的特征图生成一个权重,这个权重用来显示的声明当前通道的重要性。
最后是一个 Reweight 的操作,我们将 Excitation 的输出的权重通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。以将SE Block嵌入ResNet中为例:
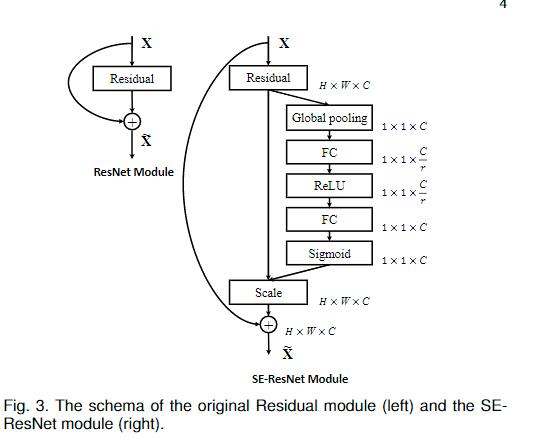
实际Squeeze 操作就是全局平均池化,Excitation 操作就是两个全连接层,一层将通道数降下来,另一层负责恢复原状,最后的激活函数使用sigmod,得到权重系数,然后将系数与输入相乘,得到考虑了重要性之后的新特征图。使用两层全连接而不是一层:
1)具有更多的非线性,可以更好地拟合通道间复杂的相关性;
2)极大地减少了参数量和计算量。代码实现
实现1
import paddle import paddle.nn as nn # 使用全连接层,因为Linear是对最后一个维度处理的,所以需要tensor维度的额外处理 class SELayer1(nn.Layer): def __init__(self,in_channels,reduction=16): super(SELayer1, self).__init__() self.avg_pool=nn.AdaptiveAvgPool2D(1) self.fc=nn.Sequential( nn.Linear(in_channels,in_channels // reduction), nn.ReLU(), nn.Linear(in_channels // reduction, in_channels), nn.Sigmoid() ) def forward(self,x): # x:[n,c,h,w] # 我们不需要w,h 因为池化操作之后就是 1*1了 n, c, _, _=x.shape y=self.avg_pool(x).flatten(1) # y:[n,c*h*w]=[n,c] y=self.fc(y).reshape([n,c,1,1]) # y:[n,c,1,1] # 这步不做也行 框架会自动进行广播 y=y.expand_as(x) # y:[n,c,h,q] out=x*y return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
实现2
# 使用1*1的卷积代替全连接层 避免了tensor维度的额外处理 class SELayer2(nn.Layer): def __init__(self,in_channels,reduction=16): super(SELayer2, self).__init__() self.squeeze =nn.AdaptiveAvgPool2D(1) self.excitation=nn.Sequential( nn.Conv2D(in_channels, in_channels // reduction, 1, 1, 0), nn.ReLU(), nn.Conv2D(in_channels // reduction, in_channels, 1, 1, 0), nn.Sigmoid() ) def forward(self,x): # x:[n,c,h,w] y=self.squeeze(x) y=self.excitation(x) out=x*y return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
相关阅读:
【快速阅读二】从OpenCv的代码中扣取泊松融合算子(Poisson Image Editing)并稍作优化
第十六章总结:反射和注解
RabbitMQ如何保证消息不丢
[MQ] 延迟队列/延迟插件下载
Mac 执行报错 -bash: mono: command not found 解决方式
JZ6 从尾到头打印链表
LeetCode-重新安排行程(C++)
力扣刷题记录103.1-----518. 零钱兑换 II
设计模式之模版方法(TemplateMethod)
计算机毕业设计Java酒店预约及管理系统(源码+系统+mysql数据库+lw文档)
- 原文地址:https://blog.csdn.net/qq_44173974/article/details/126016859
