-
【MYSQL】-【子查询】
子查询
一、子查询指一个查询语句嵌套在另一个查询语句内部的查询
二、很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
三、需求:谁的工资比Abel的高?- 方法一:先查询Abel的工资,为11000,然后查询谁的工资比11000高
SELECT salary FROM employees WHERE last_name = 'Abel'; SELECT last_name,salary FROM employees WHERE salary > 11000;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 方法2:自连接
SELECT e2.last_name,e2.salary FROM employees e1,employees e2 WHERE e2.`salary` > e1.`salary` #多表的连接条件 AND e1.last_name = 'Abel';- 1
- 2
- 3
- 4
- 子查询:把方法一查询Abel工资那一步放在括号里
SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
四、称谓的规范:外查询(或主查询)、内查询(或子查询)
五、子查询(内查询)在主查询之前一次执行完成。
六、子查询的结果被主查询(外查询)使用 。
七、注意:- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
八、子查询的分类
- 角度1:从内查询返回的结果的条目数可分为:
(1)单行子查询:查询出来的内容只有一个,就像上面括号里的内容查询出来就只有一个结果,所以是单行子查询
(2)多行子查询:查询出来的结果有多个,如查询工资大于6000的员工 - 角度2:内查询是否被执行多次
(1)相关子查询:内外查询比较的东西有关联。
相关子查询的需求:查询工资大于本部门平均工资的员工信息。外查询获得所有员工的信息,假如第一条信息是张三,他是部门1,那么将张三和部门1的平均工资进行比较,第二条数据是李四,他是部门2,那么将李四和部门2的平均工资进行比较……内查询每次查询结果都不一样,因为外查询的结果和内查询有关系,这就是相关子查询
(2)不相关子查询:像上面的查询,括号里查出来的是11000,外查询的结果都是和11000比较,内外查询比较双方没有任何关联,即不相关子查询
不相关子查询的需求:查询工资大于本公司平均工资的员工信息。内查询的结果是固定值,外查询的结果都和相同的固定值比较,二者没有联系
单行子查询
一、单行比较操作符
操作符 含义 = equal to > greater than >= greater than or equal to < less than <= less than or equal to <> not equal to 二、案例
- 查询工资大于149号员工工资的员工的信息
SELECT employee_id,last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE employee_id = 149 );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT last_name,job_id,salary FROM employees WHERE job_id = ( SELECT job_id FROM employees WHERE employee_id = 141 ) AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 返回公司工资最少的员工的last_name,job_id和salary
select last_name, job_id, salary from employees where- 1
- 2
- 3
- 查询与141号员工的manager_id和department_id相同的其他员工的employee_id,manager_id,department_id。
#方式1: SELECT employee_id,manager_id,department_id FROM employees WHERE manager_id = ( SELECT manager_id FROM employees WHERE employee_id = 141 ) AND department_id = ( SELECT department_id FROM employees WHERE employee_id = 141 ) AND employee_id <> 141; #方式2:了解 # where后面的两个约束条件除了查询条件不一样其余都一样,那我们可以同时查询department_id、manager_id # 注意查询内容(manager_id,department_id) = (SELECT manager_id,department_id……顺序要一致 SELECT employee_id,manager_id,department_id FROM employees WHERE (manager_id,department_id) = ( SELECT manager_id,department_id FROM employees WHERE employee_id = 141 ) AND employee_id <> 141;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
三、HAVING中的子查询:首先执行子查询,然后向主查询中的HAVING子句返回结果。例:查询最低工资大于110号部门最低工资的部门id和其最低工资
SELECT department_id,MIN(salary) FROM employees WHERE department_id IS NOT NULL GROUP BY department_id HAVING MIN(salary) > ( SELECT MIN(salary) FROM employees WHERE department_id = 110 );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
四、CASE中的子查询:显式员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’。
SELECT employee_id,last_name,CASE department_id WHEN (SELECT department_id FROM departments WHERE location_id = 1800) THEN 'Canada' ELSE 'USA' END "location" FROM employees;- 1
- 2
- 3
五、子查询中的空值问题:内查询啥也没查到,返回空值,不会报错,只是查询没有结果
SELECT last_name, job_id FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE last_name = 'Haas');- 1
- 2
- 3
- 4
- 5
- 6
返回结果:
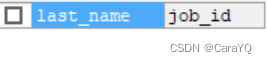
单独查询子查询返回的结果:

六、非法使用子查询SELECT employee_id, last_name FROM employees WHERE salary = (SELECT MIN(salary) FROM employees GROUP BY department_id);- 1
- 2
- 3
- 4
- 5
- 6
=是单行比较操作符,=右边只能是一个数据,但是子查询的结果有很多数据:
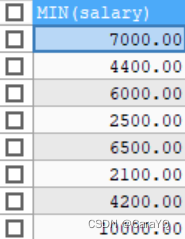
所以执行执行上述语句会报错:Subquery returns more than 1 row多行子查询
一、多行子查询:内查询返回多行
二、多行比较操作符操作符 含义 IN 等于列表中的任意一个 ANY 需要和单行比较操作符一起使用,和子查询返回的某一个值比较 ALL 需要和单行比较操作符一起使用,和子查询返回的所有值比较 SOME 实际上是ANY的别名,作用相同,一般常使用ANY 三、案例
- 非法使用子查询的正确写法:
SELECT employee_id, last_name FROM employees WHERE salary IN (SELECT MIN(salary) FROM employees GROUP BY department_id);- 1
- 2
- 3
- 4
- 5
- 6
- 返回其它job_id中比job_id为‘IT_PROG’部门任一工资低的员工的员工号、姓名、job_id以及salary
SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id <> 'IT_PROG' AND salary < ANY ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 返回其它job_id中比job_id为‘IT_PROG’部门所有工资低的员工的员工号、姓名、job_id以及salary
SELECT employee_id,last_name,job_id,salary FROM employees WHERE job_id <> 'IT_PROG' AND salary < ALL ( SELECT salary FROM employees WHERE job_id = 'IT_PROG' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 查询平均工资最低的部门id,MySQL中聚合函数是不能嵌套使用的。
(1)方法一:首先我们查询每个部门的平均工资:
SELECT AVG(salary) FROM employees GROUP BY department_id- 1
- 2
- 3
然后从这些平均工资中找出最低的,由于MySQL中聚合函数是不能嵌套使用的,所以
SELECT min(AVG(salary))这种写法是错误的,但是我们可以把上述查询结果看成一张表,并将查询结果(每个部门的平均工资)命名为avg_sal
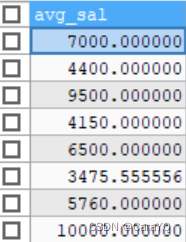
那么我们接下来就可以查询上表中最低的工资,注意:将查询结果当作表时需要给这张表(查询结果)起个别名,否则会报错,此处我们命名为t_dept_avg_salSELECT MIN(avg_sal) FROM( SELECT AVG(salary) avg_sal FROM employees GROUP BY department_id ) t_dept_avg_sal );- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面我们已经获得了最低平均工资,现在查询该部门的id,先查询每个部门的平均工资,然后查询平均工资等于最低平均工资的部门id
SELECT department_id FROM employees GROUP BY department_id HAVING AVG(salary) = ( SELECT MIN(avg_sal) FROM( SELECT AVG(salary) avg_sal FROM employees GROUP BY department_id ) t_dept_avg_sal );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(2)方法二:首先我们查询每个部门的平均工资:
SELECT AVG(salary) FROM employees GROUP BY department_id- 1
- 2
- 3
然后查询平均工资等于最低平均工资的部门id,即查询平均工资等于上述部门最小值的部门id,那么我们让平均工资≤上述查询的所有结果即可,因为这个所有结果中肯定包含最小值,且平均工资也包含在这个所有结果中,那么就可以找到平均工资等于最低平均工资的部门id
SELECT department_id FROM employees GROUP BY department_id HAVING AVG(salary) <= ALL( SELECT AVG(salary) avg_sal FROM employees GROUP BY department_id )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
四、空值问题
SELECT last_name FROM employees WHERE employee_id NOT IN ( SELECT manager_id FROM employees );- 1
- 2
- 3
- 4
- 5
- 6
查询结果:
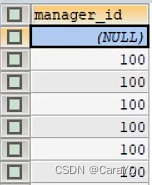
这是因为执行内查询是有一个空值
如果给内查询添加限制:SELECT last_name FROM employees WHERE employee_id NOT IN ( SELECT manager_id FROM employees WHERE manager_id IS NOT NULL );- 1
- 2
- 3
- 4
- 5
- 6
- 7
查询结果无误:
所以在内查询的结果中有NULL值是,整个查询结果为NULL相关子查询
一、相关子查询执行流程:如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询。相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
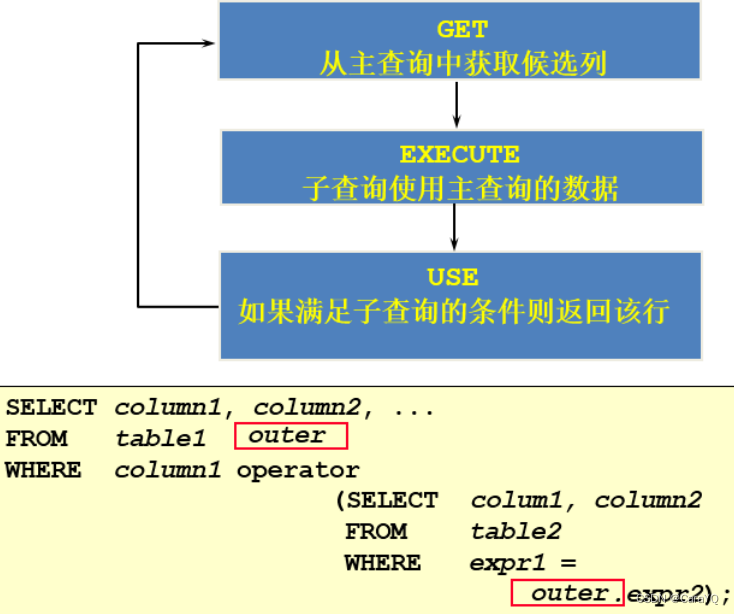
取table1中的一条数据,然后将这条数据送进内查询,执行内查询,得到内查询结果,将内查询的结果和送进去的这条数据进行比较,如果满足子查询的条件则返回该行数据
二、不相关子查询执行流程:以上述查询谁的工资比Abel的高?为例:SELECT last_name,salary FROM employees WHERE salary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
先执行内查询,得到结果为11000,遍历表中的每一条数据,取出每条数据的salary,和11000进行比较,结果为1的数据保留。
三、案例- 查询员工中工资大于公司平均工资的员工的last_name,salary和其department_id
SELECT last_name,salary,department_id FROM employees WHERE salary > ( SELECT AVG(salary) FROM employees );- 1
- 2
- 3
- 4
- 5
- 6
- 查询员工中工资大于本部门平均工资的员工的last_name,salary和其department_id
(1)子查询:给外查询的表起个别名e1,在内查询中,e1指代查询e1表得到的一条送进内查询的数据,内查询中限定条件要求department_id = e1.department_id,即内查询的department_id等于外面送进来的这条数据的department_id
SELECT last_name,salary,department_id FROM employees e1 WHERE salary > ( SELECT AVG(salary) FROM employees e2 WHERE department_id = e1.`department_id` );- 1
- 2
- 3
- 4
- 5
- 6
- 7
(2)在FROM中声明子查询:首先查询每个部门的平均工资:
SELECT department_id,AVG(salary) avg_sal FROM employees GROUP BY department_id- 1
- 2
- 3
得到结果:
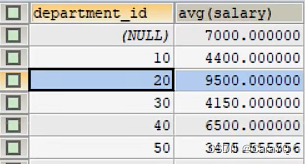
把这个结果当作一张表,然后查询员工中工资大于本部门平均工资的员工,直接将员工工资和其所在部门的最低工资(可在上表中查询得到)进行比较:SELECT e.last_name,e.salary,e.department_id FROM employees e,( SELECT department_id,AVG(salary) avg_sal FROM employees GROUP BY department_id) t_dept_avg_sal WHERE e.department_id = t_dept_avg_sal.department_id AND e.salary > t_dept_avg_sal.avg_sal- 1
- 2
- 3
- 4
- 5
- 6
- 7
有时我们想查询的表不是真实存在的,需要查询得到,那可以将查询的结果作为一张表放在from中
- 查询员工的id,salary,按照department_name排序:department_name不在employees表中,在departments表中,所以我们需要通过employees表的department_id与departments的department_id建立关联,获取department_name并据此排序
SELECT employee_id,salary FROM employees e ORDER BY ( SELECT department_name FROM departments d WHERE e.`department_id` = d.`department_id` ) ASC;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id
SELECT employee_id,last_name,job_id FROM employees e WHERE 2 <= ( SELECT COUNT(*) FROM job_history j WHERE e.`employee_id` = j.`employee_id` )- 1
- 2
- 3
- 4
- 5
- 6
- 7
EXISTS与NOT EXISTS关键字
一、如果在子查询中不存在满足条件的行:条件返回FALSE,并继续在子查询中查找
二、如果在子查询中存在满足条件的行:不在子查询中继续查找,条件返回TRUE
三、NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
四、练习:- 查询公司管理者的employee_id,last_name,job_id,department_id信息
(1)自连接:其中DISTINCT代表对查询结果去重
SELECT DISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id FROM employees emp JOIN employees mgr ON emp.manager_id = mgr.employee_id;- 1
- 2
- 3
(2)子查询:先查询所有的管理者ID,如果员工ID=管理者ID,说明这个人是管理者,取出其employee_id,last_name,job_id,department_id信息
SELECT employee_id,last_name,job_id,department_id FROM employees WHERE employee_id IN ( SELECT DISTINCT manager_id FROM employees );- 1
- 2
- 3
- 4
- 5
- 6
(3)使用EXISTS:首先查询e1表,取出一条数据,然后将该数据送进内查询,内查询从e2表中取出第一条数据,和送进来的数据进行比较,如果
e1.employee_id = e2.manager_id,这两条数据是同一条数据,显然不等于,所以从e2表中取出下一条数据,和送进来的数据进行比较,如果e1.employee_id = e2.manager_id,则退出内查询,外查询查询e1表,取出下一条数据,然后将该数据送进内查询,内查询从e2表中取出第一条数据,和送进来的数据进行比较,如果……SELECT employee_id,last_name,job_id,department_id FROM employees e1 WHERE EXISTS ( SELECT * FROM employees e2 WHERE e1.`employee_id` = e2.`manager_id` );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 查询departments表中,不存在于employees表中的部门的department_id和department_name
(1)方式一:外连接
SELECT d.department_id,d.department_name FROM employees e RIGHT JOIN departments d ON e.`department_id` = d.`department_id` WHERE e.`department_id` IS NULL;- 1
- 2
- 3
- 4
(2)方式二:首先查询d表,取出一条数据,然后将该数据送进内查询,内查询从e表中取出第一条数据,和送进来的数据进行比较,如果
department_id = e.department_id,则退出内查询,遍历d表的下一条数据送进内查询,内查询从e表中取出第一条数据,和送进来的数据进行比较,如果不满足department_id = e.department_id,则继续遍历e表的下一条数据,如果e表的所有数据都不满足department_id = e.department_id,则该条数据符合条件,保存在结果数据中SELECT department_id,department_name FROM departments d WHERE NOT EXISTS ( SELECT * FROM employees e WHERE d.`department_id` = e.`department_id` ); SELECT COUNT(*) FROM departments;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
相关阅读:
【Spring】一文带你吃透AOP面向切面编程技术(上篇)
浅谈Android输入法(IME)架构
Stable Diffusion云服务器部署完整版教程
Windows下Nacos安装
[附源码]java毕业设计在线开放课程平台
Flink Data Source
项目中用到的git命令(git tag标签全流程)
找视频剪辑素材就上这6个网站 优漫教育
嵌入式系统设计与应用---ARM处理器体系结构(学习笔记)
moke、动态图片资源打包显示
- 原文地址:https://blog.csdn.net/CaraYQ/article/details/126015778
