-
【手撕STL】bitset(位图)、布隆过滤器
位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用来判断某个数据存不存在的。
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
- 方案一:排序+二分查找
- 方案二:将40亿多的数据放进set或unordered_set中,在进行查找
这两个方案存在一个致命的缺陷——40亿个数据量太大内存存不下
- 方案三:数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果二进制比特位为1,代表存在,为0代表不存在。这样就可以节省内存消耗,用比特位的位图来进行映射
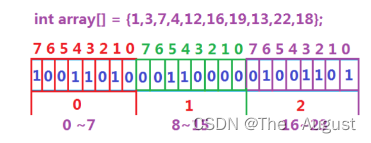
- 方案四:利用除留余数法将40亿的数据放在0.txt、1.txt……这样的文件里(可以放在内存里),这样给一个数,就可以根据除留余数法找到相应的文件,从而用set、unordered_set对文件中的数据进行插入,最后用该数判断是否存在40亿数据中
补充:
1G=1024MB
1MB=1024KB
1KB=1024byte
1byte=8bit
1G大约是10亿个字节位图的实现
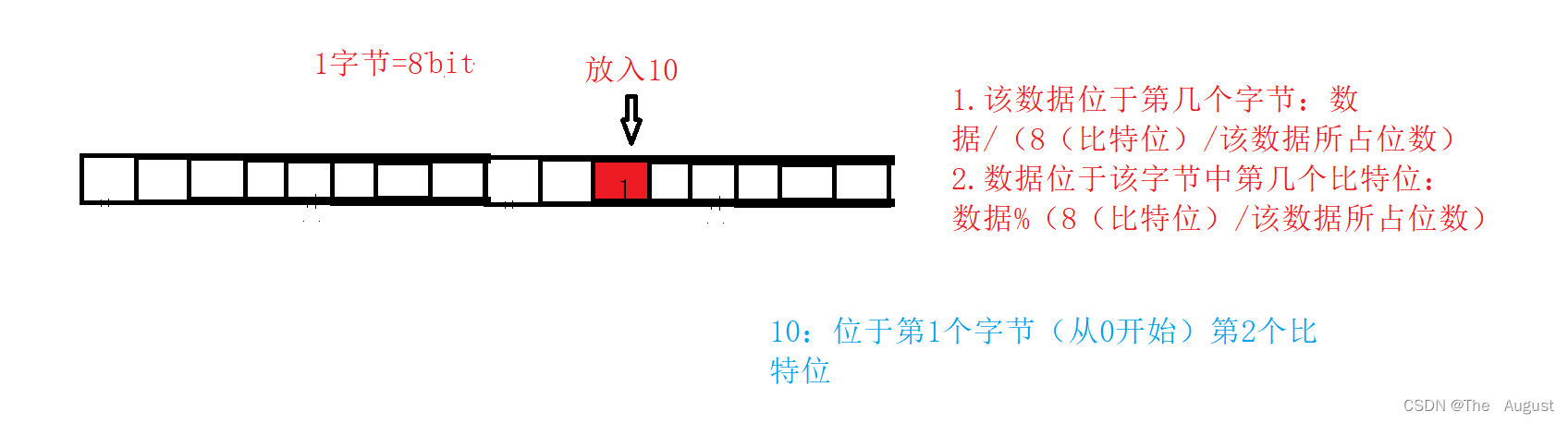
template<size_t N> class bitset { public: bitset() { _bits.resize(N / 8 + 1, 0); } bool test(size_t x) { size_t i = x / 8; size_t j = x % 8; //return _bits[i] & (1 << j); return ((_bits[i] & (1 << j)) == 0) ? false : true; } void set(size_t x) { size_t i = x / 8; size_t j = x % 8; _bits[i] |= (1 << j); } void reset(size_t x) { size_t i = x / 8; size_t j = x % 8; _bits[i] &= (~(1 << j)); } private: vector<char> _bits; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
位图的应用
- 快速查找某个数据是否在一个集合中
- 排序
- 求两个集合的交集、并集等
- 操作系统中磁盘块标记
- 给定100亿个整数,设计算法找到只出现一次的整数?
这道题跟上面的题类似,利用位图解决:找出只出现一次的整数(无非有三种情况:0次、1次、2次及以上)

template<size_t N> class FindOnceValSet { public: void set(size_t x) { if (_bs1.test(x) == false && _bs2.test(x) == true) { _bs1.set(x); _bs2.reset(x); } else if(_bs1.test(x) == false && _bs2.test(x) == false) _bs2.set(x); } void print_once_num() { for (size_t i = 0;i < N;i++) { if (_bs1.test(i) == false && _bs2.test(i) == true) cout << i << " "; } } private: bitset<N> _bs1; bitset<N> _bs2; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
就是把同一个数据在两个为位图都是11的找出来
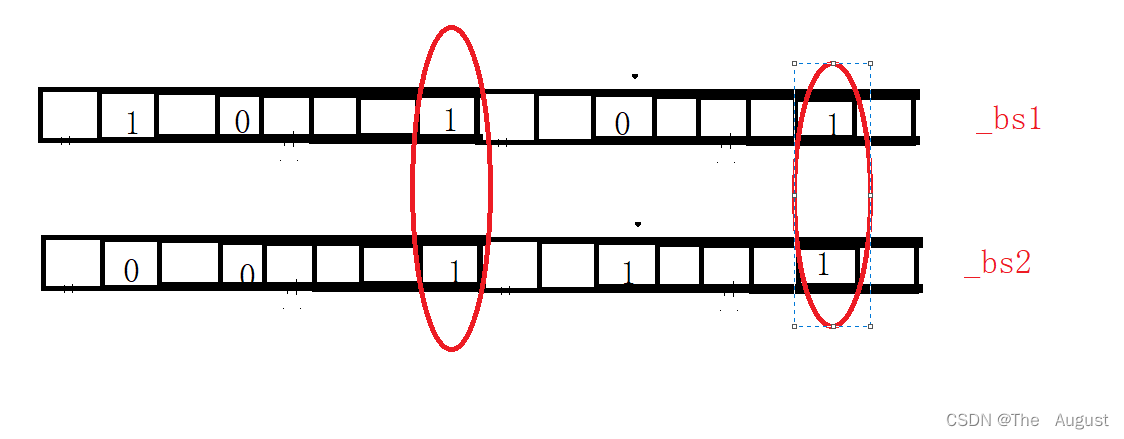
- 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
跟第一道题类似(无非有四种情况:0次、1次、2次、3次及以上)
template<size_t N> class FindValSet { public: void set(size_t x) { if (_bs1.test(x) == false && _bs2.test(x) == true) { _bs1.set(x); _bs2.reset(x); } else if (_bs1.test(x) == false && _bs2.test(x) == false) _bs2.set(x); else if (_bs1.test(x) == true && _bs2.test(x) == false) _bs2.set(x); } void print_num() { for (size_t i = 0;i < N;i++) { if (_bs1.test(i) == true && _bs2.test(i) == true|| _bs1.test(i) == false && _bs2.test(i) == false) continue; else cout << i << " "; } } private: bitset<N> _bs1; bitset<N> _bs2; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
注意:这三道题也可以用哈希切割来解决
哈希切割
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址? 与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?
这里大文件不能统计次数,要想办法切分成小文件,但是不能平均切分,平均切分统计不出次数。先创建100个小文件,分别叫0.txt 1.txt …99.txt。然后读取100G long file,依次获取每个ip用一个字符串哈希算法,把ip转换成整形。比如使用BKDR size_t num = BKDRHash(ip)% 100(相同的ip,一定会进入编号相同的小文件。),然后这个ip就进行num.txt号小文件,依次对所有ip,进行处理,进入对应的小文件。依次读取每个小文件,比如先读取0.txt中ip,map
ps∶极端情况如果某个小文件过大,可以考虑再次对他切分,可以换一个字符串哈希算法。(用递归)
Linux命令,假设top 10:sort log_file | uniq -c | sort -nr k1,1 | head -10布隆过滤器
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:不能处理哈希冲突
- 将哈希与位图结合,即布隆过滤器
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”,它是用多个哈希函数,将一个数据映射到位图结构中。此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
1亿个ip字符串,现在给你一个ip,需要快速判断这个ip在不在上面的1亿ip中?
- 这时,首先想到的就是位图,可是位图只能记录该数是否存在,不能记录字符串类型,需要将字符串转化成整形映射到位图中一个位进行标记。问题是两个不同的字符串,映射的同一个位置,存在冲突,存在误判(这些是不可避免的),布隆想了一下,无法解决冲突,但是可以缓解冲突降低误判概率。一个值映射多个位,运用布隆过滤器就可以降低冲突。
注意:布隆过滤器存在的问题(不可避免)
- 判断一个值在不准确的,可能存在误判。
- 判断一个值不在是准确的。
布隆过滤器优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无关
- 哈希函数相互之间没有关系,方便硬件并行运算
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算
- 速度快,节省空间
布隆过滤器缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中(补救方法:再建立一个白名单,存储可能会误判的数据)
- 不能获取元素本身
- 一般情况下不能从布隆过滤器中删除元素
- 如果采用计数方式删除,可能会存在计数回绕问题
布隆过滤器的应用场景
-
像一些登录系统,注册的时候需要每个用户取一个昵称,要求昵称不能重复。那么注册时候,输入一个昵称以后,就要判断一下这个昵称是否被注册。这时可以使用一个布隆过滤器存储所有昵称,快速判断一个昵称是否使用过–容许误判,因为当判断为注册,但昵称不一定用过(但是系统可以判定为用过,这样用户也不知道这个昵称没用过(只是不让用罢了));判断为未注册,昵称一定未用过,可以使用。从而快速判断出结果
-
判断一个手机号是否注册当前系统,,判断手机号在不在布隆过滤器,如果不在,则返回未注册;如果在,则需要在服务器数据库中查找是否存在,存在则返回注册过,不存在则返回未注册
布隆过滤器实现
- 插入——布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。
- 查找——布隆过滤器的思想是将一个元素用多个哈希函数映射到一个位图中,因此被映射到的位置的比特位一定为1。所以可以按照以下方式进行查找:分别计算每个哈希值对应的比特位置存储的是否为零,只要有一个为零,代表该元素一定不在哈希表中,否则可能在哈希表中。
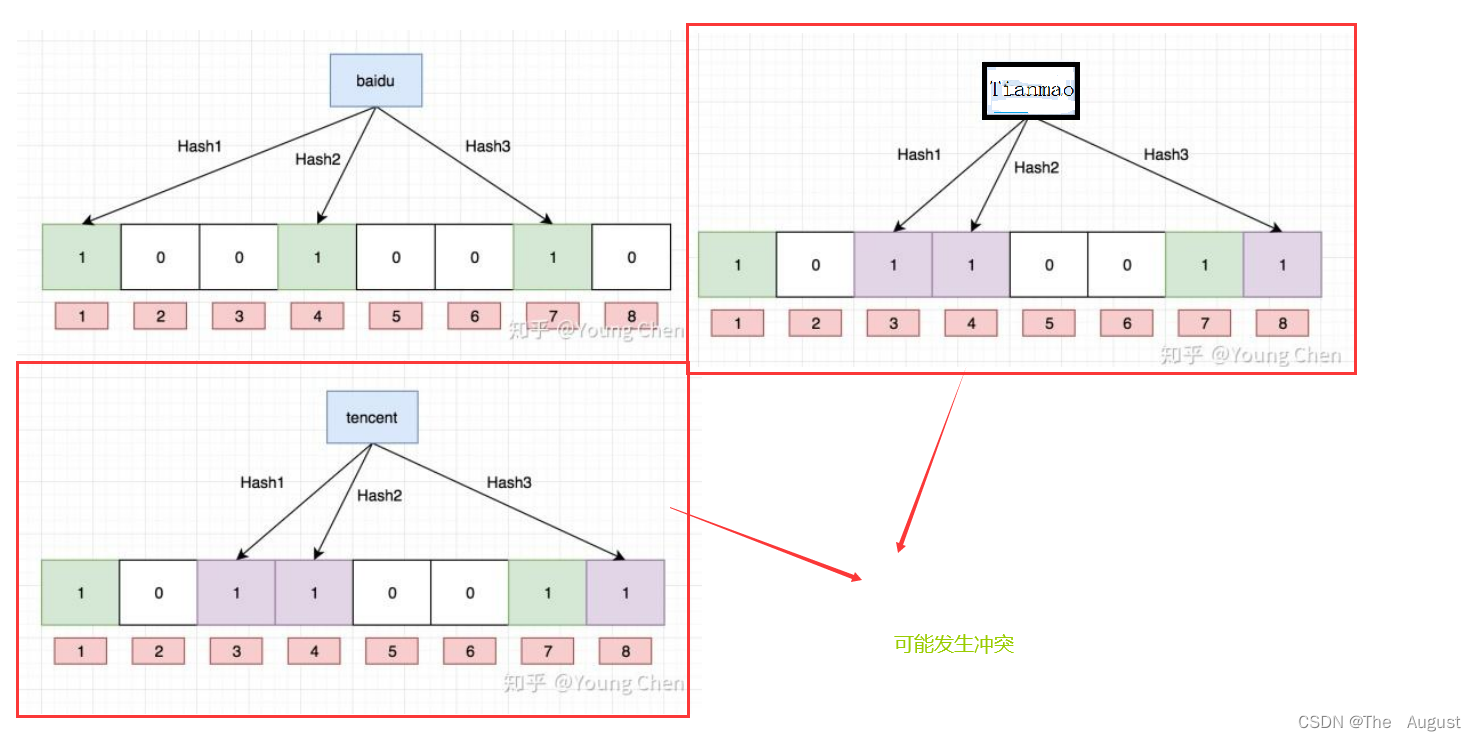
注意:布隆过滤器如果说某个元素不存在时,该元素一定不存在,如果该元素存在时,该元素可能存在,因为有些哈希函数存在一定的误判。 比如:在布隆过滤器中查找"alibaba"时,假设3个哈希函数计算的哈希值为:1、3、7,刚好和其他元素的比特位重叠,此时布隆过滤器告诉该元素存在,但实该元素是不存在的。
布隆过滤器删除
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
比如:删除上图中"tencent"元素,如果直接将该元素所对应的二进制比特位置0,“baidu”元素也被删除了,因为这两个元素在多个哈希函数计算出的比特位上刚好有重叠。
一种支持删除的方法:将布隆过滤器中的每个比特位扩展成一个小的计数器,插入元素时给k个计数器(k个哈希函数计算出的哈希地址)加一,删除元素时,给k个计数器减一,通过多占用几倍存储空间的代价来增加删除操作。缺陷:
- 无法确认元素是否真正在布隆过滤器中
- 存在计数回绕
总结: 一般情况不支持删除,多个值可能会标记一个位,删除可能会影响其他key。 如果非要支持删除的话,标记不再使用一个比特位,可以使用多个比特位,进行计数多少个值映射到这个比特位, 但是这种方法是杀敌一千,自损八百的做法,因为消耗的更多的空间。
如何选择哈希函数个数和布隆过滤器长度
很显然,过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
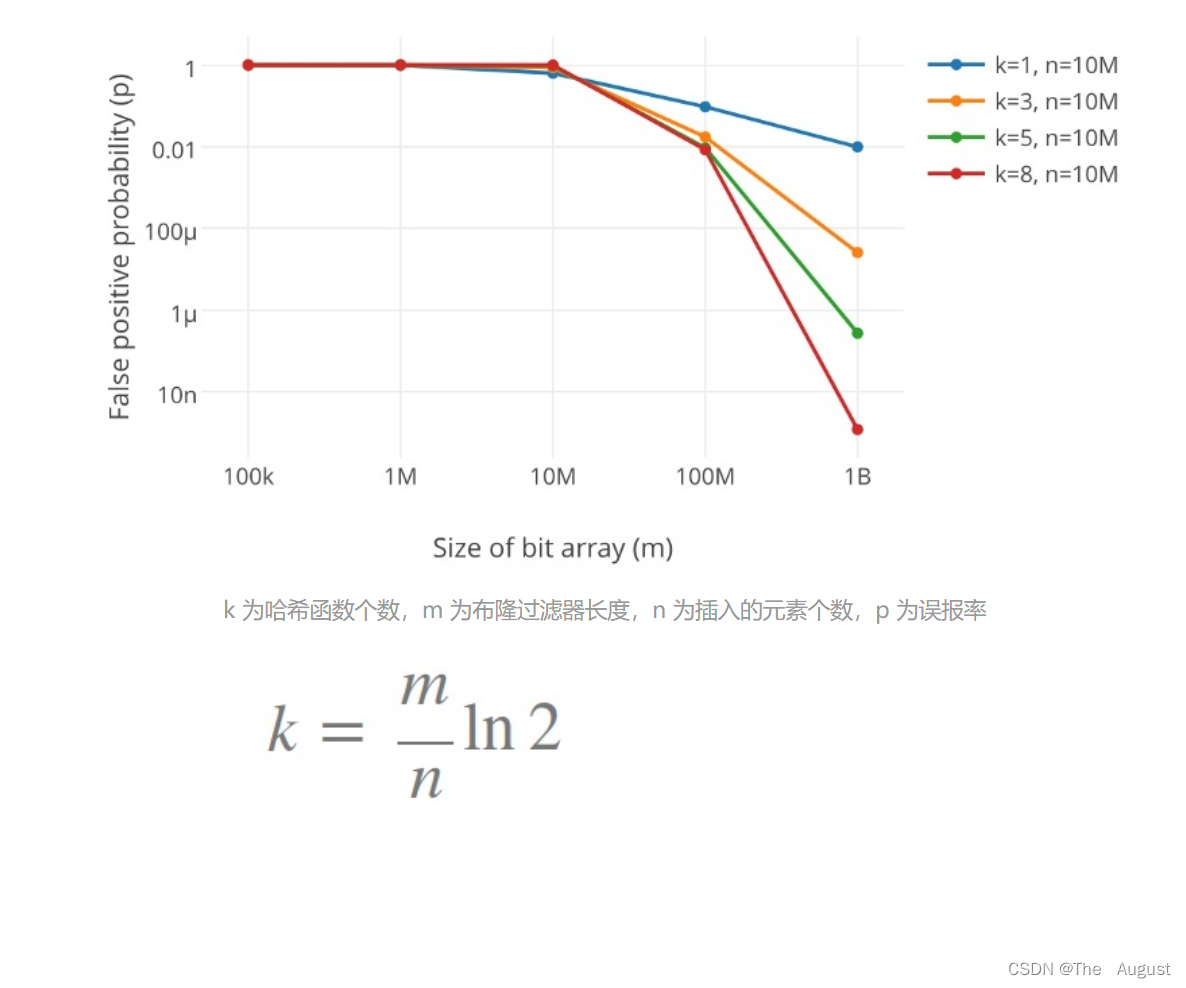
代码实现:
struct HashStr1 { size_t operator()(const string& s) { size_t hash = 0; // BKDR for (size_t i = 0; i < s.size(); ++i) { hash *= 131; hash += s[i]; } return hash; } }; struct HashStr2 { size_t operator()(const string& s) { size_t hash = 0; // SDBMHash for (size_t i = 0; i < s.size(); ++i) { hash *= 65599; hash += s[i]; } return hash; } }; struct HashStr3 { size_t operator()(const string& s) { size_t hash = 0; // RSHash size_t magic = 63689; for (size_t i = 0; i < s.size(); ++i) { hash *= magic; hash += s[i]; magic *= 378551; } return hash; } }; template<size_t N,class K=string, class Hash1 = HashStr1,class Hash2 = HashStr2,class Hash3 = HashStr3> class BloomFilter { public: bool Test(const K& key) { size_t index1 = HashStr1()(key) % _len; if (_bs.test(index1) == false) return false; size_t index2 = HashStr2()(key) % _len; if (_bs.test(index2) == false) return false; size_t index3 = HashStr3()(key) % _len; if (_bs.test(index3) == false) return false; return true; } void Set(const K& key) { size_t index1 = HashStr1()(key) % _len; _bs.set(index1); size_t index2 = HashStr2()(key) % _len; _bs.set(index2); size_t index3 = HashStr3()(key) % _len; _bs.set(index3); } // 一般情况不支持删除,why?->多个值可能会标记一个位,删除可能会影响其他key // 如果非要支持删除的话,标记不再使用一个比特位,可以使用多个比特位,进行计数多少个值映射的这个比特位 // 但是这种方法是杀敌一千,自损八百的做法,因为消耗的更多的空间。 private: bitset<5 * N> _bs; size_t _len = 5 * N; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
相关面试题
1. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法(这道题跟哈希切割那道题类似)
假设一个query平均20byte,100亿个query大概是2000亿Byte,大概200G。依次读取A的文件中query,然后使用字符串哈希算法转成整形,size_t val = HashStr(query);size_t i = val%200;该query算出的结果进入Ai.txt号小文件.依次读取B的文件中query,然后使用字符串哈希算法转成整形,size_t val = HashStr(query);size_t i = val%200;该query算出的结果进入Bi.txt号小文件. A和B中,相同的query进入编号相同的小文件,只需要编号相同的小文件找交集即可。Ai.txt读进一个setA,Bi.txt读一个setB,setA和setB相同的query就是交集,依次遍历i的值最终得到交集的结果
2. 如何扩展BloomFilter使得它支持删除元素的操作
标记多个比特位(这些比特位不作为标记位),进行计数多少个值映射到这个比特位
-
相关阅读:
【scala】类的属性
Linux中,查看Tomcat版本、如何查看Tomcat版本
人工智能与开源机器学习框架
用核心AI资产打造稀缺电竞体验,顺网灵悉背后有一盘大棋
Matlab在同一张图中如何加入多个图例
毫米波V2I网络的链路层仿真研究(Matlab代码实现)
Linux文件系统结构
2022 年最新【Java 经典面试 800 题】面试必备,查漏补缺;多线程 +spring+JVM 调优 + 分布式 +redis+ 算法
C# HttpClient使用和注意事项,.NET Framework连接池并发限制
毫米波雷达技术在自动驾驶中的关键作用:安全、精准、无可替代
- 原文地址:https://blog.csdn.net/AI_ELF/article/details/125720285
