-
深入浅出详解Knative云函数框架!

导语 | 业界开源的云函数框架比较多,像knative、openfaas都是比较成熟且优秀的。本文主要介绍一个云原生的云函数框架:knative。希望更多开发者对它有更深的了解~
引言
云函数现在已经是老生常谈了,之前用腾讯云函数SCF搭建过一些正式的服务。在使用过程中,对云函数的伸缩,复用和冷启动机制都比较好奇,也拉着腾讯云助手做了相关的请教。不过毕竟不是面对面,所以了解的程度比较有限。业界开源的云函数框架比较多,像knative、openfaas都是比较成熟且优秀的。knative目前已经是CNCF的一员,可以说是云原生的亲儿子。
为了能对云函数有更深入的认识,我对knative做了一些实践性的了解。
读完这篇较为简略的小结之后,应该能对knative有个整体的了解,比如它的组织方式还有性能。此外也能够了解到knative是云原生的一部分,这是很大的一个优势。
为了达到以上目的,这篇文章会简单的介绍一些关键的概念,这些概念我也还在进一步的学习中,有些表达可能不太准确,望指出和谅解。
一、Knative是什么
knative是一个云原生的云函数框架。他在kubernetes之上,通过kubernetes提供的能力以及相关的扩展,对pod中的流量进行监控,从而做到对pod进行更加灵敏地伸缩。他是serverless的事实标准,除了自动伸缩之外,还提供了源码构建以及事件机制。
接下来我们了解一下上方提到的一些概念。
二、什么是云原生
“云原生”的本质,不是简单对Kubernetes生态体系的一个指代。“云原生” 刻画出的,是一个使用户能低心智负担的、敏捷的,以可扩展、可复制的方式,最大化利用“云”的能力、发挥“云”的价值的一条最佳路径。
而这其中,“不可变基础设施” 是“云原生”的实践基础(这也是容器技术的核心价值);而Kubernetes、Prometheus、Envoy等CNCF核心项目,则可以认为是这个路径落地的最佳实践。
---- 张磊《深入剖析kubernetes》
三、关于Kubernetes
上面的引用中,提到了kubernetes,它是一个容器编排工具,可以根据开发者的意愿自动地处理容器之间的各种关系。
此外,kubernetes还提供了服务发现,负载均衡,存储编排,自动部署,自我修复,监控,备份,密钥与配置管理等功能。
关于kubernetes,大家感兴趣的话可以在《Kubernetes概述》中进行了解。
四、关于容器
容器的本质是一个进程,但为什么容器看起来是一个被隔离的完整操作系统呢? 比如在容器中看不到宿主机的其它进程,容器可以限制CPU和内存的上限,容器也会有自己完整的操作系统文件。这些功能的实现,离不开linux的进程特性,它是这么被约束起来的:
容器通过linux的Namespace做隔离,比如隔离进程,让进程内的程序只看到本进程 (1号进程,以及自己衍生出来的进程),其它宿主机上的进程隔离开来,是看不见的。除了进程,像Network,User,IPC等也可以通过 namespace隔离。
容器通过linux的Cgroups做限制,比如限制容器进程只能使用0.5个CPU,64MB内存等。
容器通过linux的rootfs做文件系统,容器镜像是分层的,比如from tlinux之后,再做一些sh的改动,这些改动并不会改到tlinux这个层的文件,而是通过rootfs的能力做了文件的覆盖。所以当tlinux镜像没有变化的情况下,只更新了业务代码,整体镜像的更新是很快的,因为docker会帮你做缓存。
另外,这里简单说下镜像和容器的关系: 镜像是包含所有操作系统文件以及代码文件的一个包,这个包还会有一些配置的声明,比如环境变量,启动命令等,在docker中会有镜像源,这个包会从本地推送到镜像源,再拉取到对应的运行时环境。当这个镜像启动之后,它就是一个容器了,容器是镜像的实例。
五、关于pod
前面提到,knative是通过监听pod的中流量的情况,对pod进行更加灵敏伸缩的一个框架,那这里的pod是什么呢? 有了容器为什么还要pod?
pod在我的感性认识中,扮演着原始基础设施里的"虚拟机"的角色。pod中运行的服务,是以容器为基础的,一个pod内可以有一个或多个容器。这些容器一般是存在紧密关系的,比如文件,网络的共享。pod是kubernetes调度的基本单位,是kubernetes中的一等公民。
我们原始的服务,要迁移上云的话,是不是就是将整个虚拟机内的服务都构建成一个镜像,在pod中运行起来就可以了呢? 确实有很多团队都是这么做了。很多情况下这是迁移上云的第一个步骤。但这是最基本的。这种方式很可能不是最佳实践。因为pod还承载着一个很重要的功能,就是容器的设计模式。
容器设计模式中,我们听得最多的,也许是sidecar了,这里举两个例子简单介绍一下:
日志上报,调用链追踪等可观测性相关的基础逻辑与业务代码,可以通过 pod的能力,在网络的这个维度做组织,流量先经过调用链追踪的容器,再经过业务代码容器。而业务代码容器与日志上报容器,通过共享pod内的文件, 日志收集的操作完全和业务逻辑解耦。这种pod内解耦的方式,可以最大化提升生产效率,各司其职,完全没有了程序语言上的耦合要求。在这里,日志上报,链路追踪,业务代码以不同的容器进行组织。
有一个tomcat基础包与java业务代码组织成的war包,假如是两个业务团队在维护,通过kubernetes提供的文件挂载方式做文件共享,在pod中以两个容器的方式组织起来,可以做到维护上的解耦,也可以很好地利用docker镜像层复用带来的构建性能上的提升。
以上的这种上云方式。利用kubernetes的pod能力,做到了最大化的解耦,使得不同语言之间可以无缝衔接,也让开发之间的依赖维护变得更加优雅。
我们后面可以看到,knative的pod中,也有这种sidecar的容器设计模式。
六、knative的历史与目标
knative是谷歌2018年开源的serverless架构方案,主要参与贡献的公司有 Google、Pivotal、IBM、Red Hat。knative于2021年11月2日正式发布 1.0版本,2022年3月2日加入到CNCF,处于孵化项目成熟阶段。到现在为止 (2022年06月26日),knative版本已经升至1.5。knative是云原生领域 serverless方案的事实标准。
Knative的目标是在基于Kubernetes之上为整个开发生命周期提供帮助。它的具体实现方式是: 首先使你作为开发人员能够以你想要的语言和以你想要的方式来编写代码,其次帮助你构建和打包应用程序,最后帮助你运行和伸缩应用程序。----《knative入门, 译于Getting Started with Knative - Building Modern Serverless Workloads on Kubernetes》
七、knative的架构
基于knative的目标,主要分为以下三个部分:
(一)Build
将业务代码构建成容器,这个部分目前还没有过多的实践,其实单从构建成容器来看,业务代码到镜像,这部分公司内部的OCI,蓝盾等都可以覆盖,但从镜像到容器,就要依赖于tke的部署api。knative运行在tke之上,需要将镜像部署为knative pod,这个就要依赖于knative的Build系统。
(二)Eventing
在实践过程中,这块只是完成了部署,因为还在证明knative的可用性,所以基于事件触发knative运行还没有进一步深入。从云函数的角度,Eventing是很有必要的,他可以解耦我们的业务,这里列举几个应用场景:
COS+云函数: 图片上传到COS,由COS触发云函数做图片安全扫描,压缩和转存CDN。
消息队列+云函数: 通过设置云函数的消息队列触发器,感兴趣的业务就可以通过云函数来处理消息。
(三)Serving
这里先从总体来了解一下它分为哪些部分:
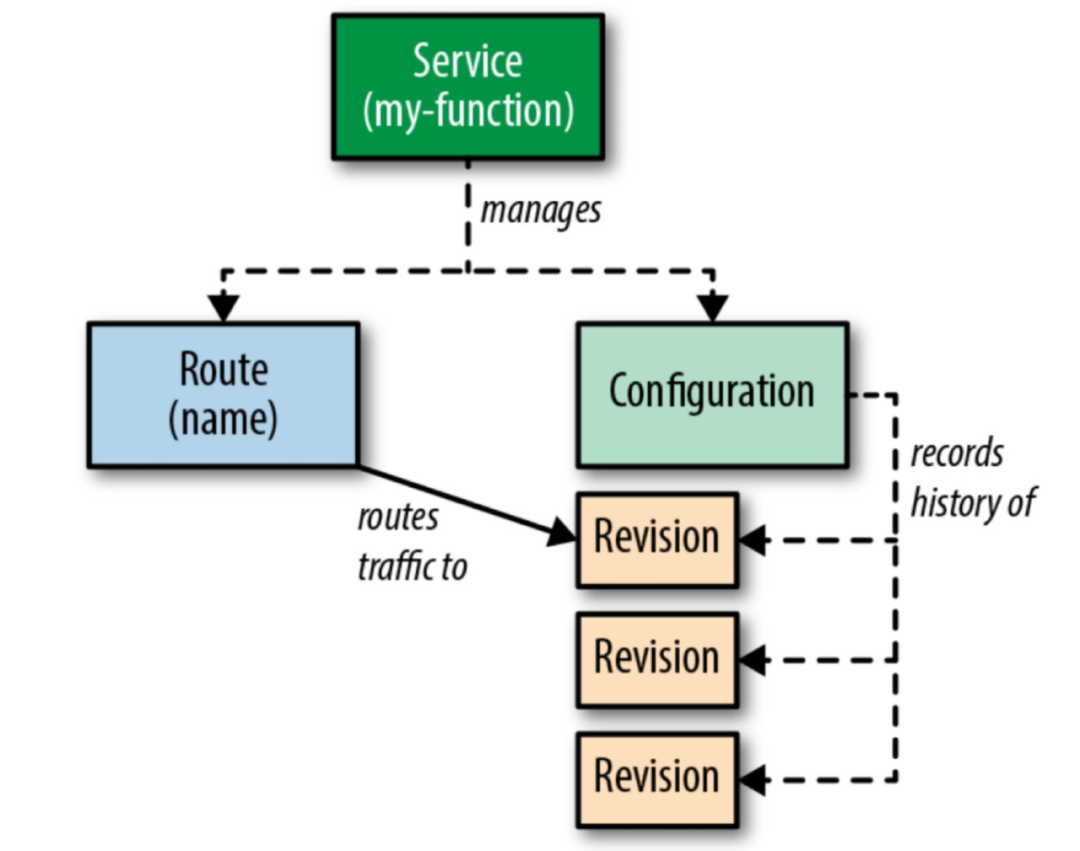
这里的service管理着Route和Configuration,Route在kubernetes中起着nginx反向代理的作用。
而Configuration就是我们的pod yaml配置文件:
它描述了这个pod用了哪个镜像,暴露了什么端口,以及在一些流量激增的场景下的行为表现,比如单个pod的cpu和内存限制,单个pod最大的并发,超过这个并发就会及时扩容。
因为knative是基于kubernetes的,所以类似于sidecar的模式也可以在这个yaml中配置。
还有节点调度层面的,调度到哪些节点(比如需要GPU,这个通过 kubernetes的亲和性配置即可实现),不调度哪些节点,比如某些节点配置不适合当前业务(这个通过设置节点的污点即可实现)
Revision是我们的业务程序的修订版,比如我们发布了3个版本,就会有3个修订版,通过knative的Route能力,可以将流量按比例地导向到不同的修订版来做测试或灰度。
上面讲到了流量大小与pod的伸缩,我们进一步来了解一下:
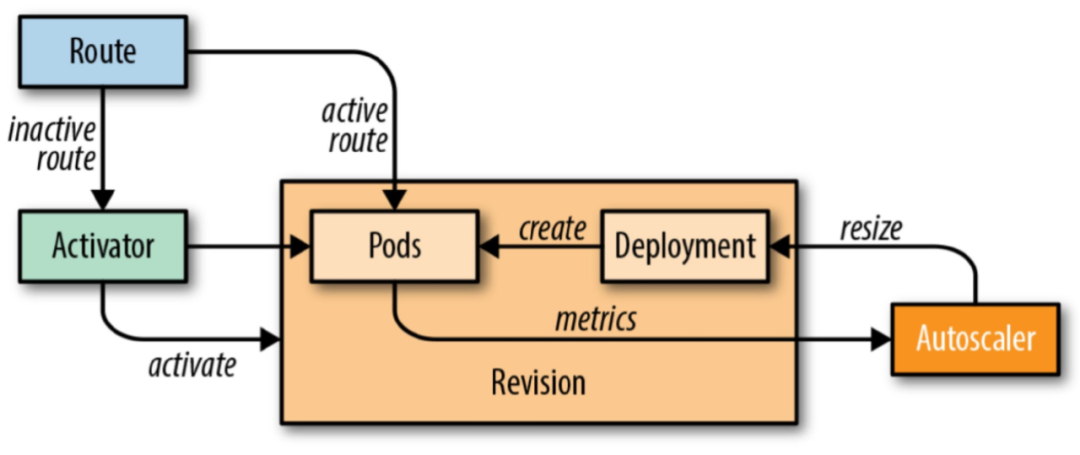
Revision里面就是我们的pod了,pod里默认运行着两个容器 (用到了前面提到的sidecar容器设计模式):
queue-proxy
user-container
如上图,queue-proxy负责收集流量,并将流量情况告知给Autoscaler,目前knative默认一个pod处理100个请求,达到了这个阈值,这个pod会继续承载流量 (单pod的cpu负载会变高),Autoscaler会通过kubernetes的Depoyment创建新的pod用于承载服务。
如果持续30s没有流量,Autoscaler会将pods缩容至0。
如果在没有pod实例的情况下,route会将流量保持在Activator,Activator 创建pod来承载。这里就会涉及到冷启动的问题,我们后面再展开。
可以看到,这一套pod伸缩的策略及其灵敏,更深入的,knative还会有恐慌模式和稳定模式,这里就不展开了,感兴趣的同学可以在这里查看。
(https://knative.dev/docs/serving/autoscaling/kpa-specific/)
以上这种流量调度策略,叫做KPA(Knative Pod Autoscaler),kubernetes有一个默认的调度策略,叫HPA (Horizontal Pod Autoscaler),它是基于CPU和内存的维度,达到一定阈值会扩容。
HPA对比与KPA会更加保守,因为CPU的变化比较频繁,为了更准确做出判断,他是每30s检测一次指标,默认在5分钟内没有扩缩容的情况下才会触发扩缩容,这种模式在流量激增时,扩容较慢,可能会对服务造成抖动。另外HPA的方式,在流量分配上没有KPA均匀,因为前者是基于CPU和内存来做判断,后者是基于流量本身。
八、knative性能
可以缩容至零,又可以在流量激增时快速伸缩,真是这么美好吗? 如你所想,没有银弹。
(一)冷启动
这是云函数最著名的问题,pod在缩容至零后,再次拉起受限于pod的大小,如果业务特别大,冷启动拉起可能需要几十秒甚至几分钟。这种特性在一些时间不敏感的业务,比如AI模型训练,消息队列慢消费等场景是没有问题的,但如果想让用户等一个页面几秒钟,用户已经离开了。

----《Knative In Action》,Jacques Chester,knative的维护者之一
正如大家所想,缩容至零不适合时间敏感的业务,我们需要将服务设置为至少一个pod。得益于docker的镜像分层,pod的横向扩容时间受镜像大小影响很小,在压测时,一个12G的镜像,从1个pod扩容至10个pod,pod拉起时间为10s左右 (它们是并行的)。
这里大家可能会有疑问,这种预置一个pod的方式,在大量云函数的情况下,不也是浪费资源吗? 我认为答案是否定的。一个pod在设置CPU/内存的 request时,可以设置得足够小,比如0.1核,这样他只需要0.1个核就能运行起来 (knative默认request是0.03个核,实测nodejs业务运行起来是ok的),这样我们有较多云函数时,所需要的资源也是比较少的。
(二)与传统上云方式对比
这里对比了传统的上云方式。knative虽然足够灵活,但这里的灵活是有性能损耗的。
上面提到的架构中,相比于HPA的pure pod方式,knative架构主要多了 Route,Activator,queue-proxy,autoscaler。其中Activator在预置pod后是不起作用的,Autoscaler压测时占用资源较少。这里的资源消耗主要在于Route和queue-proxy。
介绍一下压测背景:
用于测试的knative版本是1.1,这受限于腾讯云的kubernetes版本只有1.20 (最新版已经更新到1.22)。knative1.5的版本相比于1.1在性能上有所优化。
压测语言用了nodejs,16核32G的机器。node的特点是单核单进程的,所以一般在运行nodejs程序时,会采用主从结构来尽可能利用CPU: 一个主进程master fork出cpu.length-1个子进程,master负责流量调度,子进程负责承载服务。
对比基于HPA的pure pod形式,如果我们先单纯看Route和queue-proxy的影响,那么就先需要控制其它变量,这里使用一个knative pod,pod里面运行一个queue-proxy,并且保持主从结构,即一个master调度15个cpu核用于服务。这样就可以看出加入Route和queue-proxy对性能的影响:
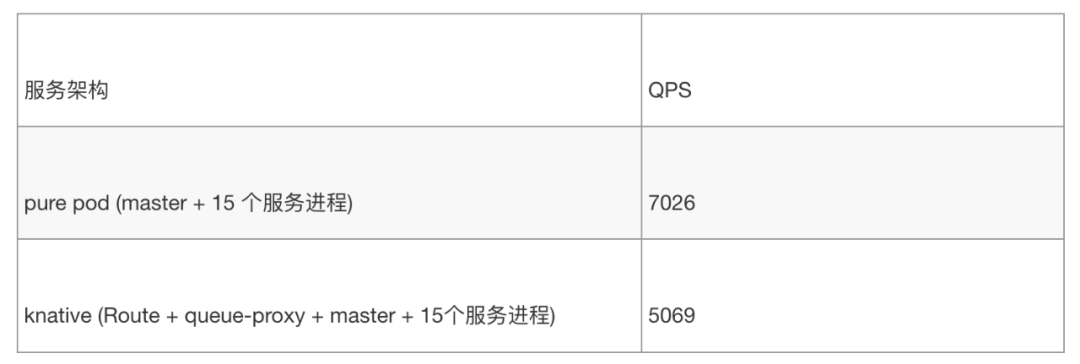
以上对比,可以发现,knative的性能是pure pod的71%,但有个点需要明确,Route承载着流量分发,灰度的能力,这对标现有业务的nginx层,这一层是真实存在的。所以有必要看看排除Route后,性能情况如何: 这里对 kubernetes的节点调度做了些配置,将Route调度到其它节点压测后,去除Route的影响,性能如下:

基于此,单纯看queue-proxy的影响,knative是pure pod性能的85%。
但以上的架构并不是knative最终运行的架构,我们在跑一个云函数时,不太可能用一个16核32G的pod来承载。一个函数,在处理较小并发时,用不到16核32G,我们考虑另一个极端,将云函数的pod调整为单服务进程,即一个pod内只有一个queue-proxy进程和一个服务进程。那么调度出16个pod来承载服务,看看性能又是什么情况:

这种组织方式,knative的性能只有pure pod的40%!
这里通过柱形图来做一下对比:

最后这种组织方式性能低很多,这似乎不是knative导致的,可能和 kubernetes在pod上的调度以及CPU分片有关。剔除knative框架,单纯使用nodejs官方最简demo看多个pod的运行方式,随着pod个数的递增,QPS如下:
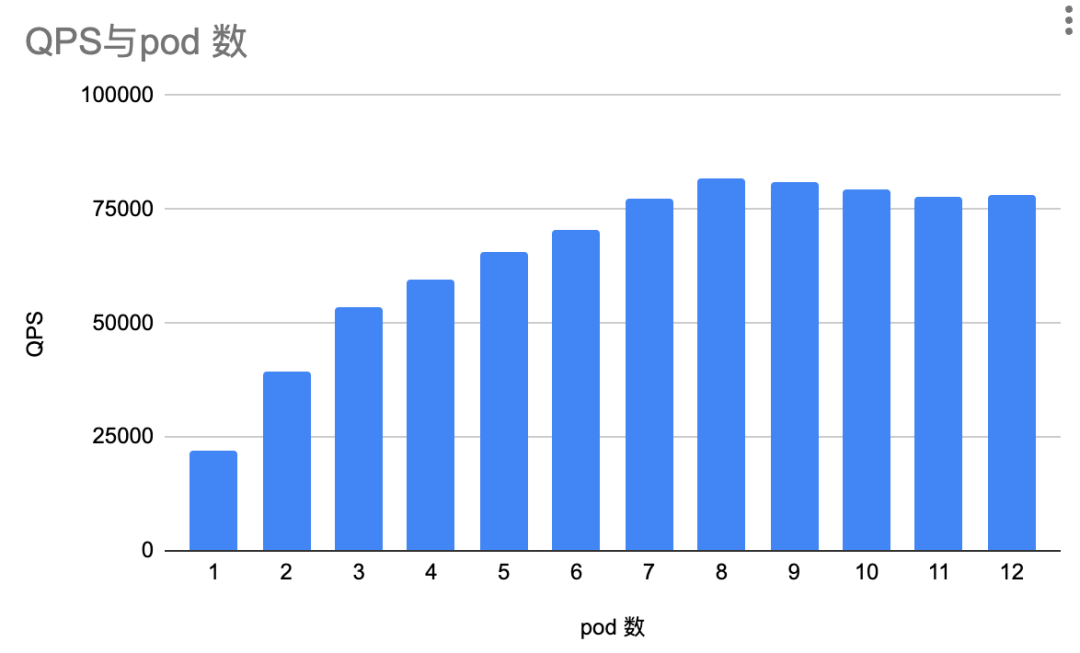
可以看到,即使剔除knative以及业务代码的影响,随着pod个数的递增,QPS并没有成正相关递增。这里面的原因还在分析,已经控制了较多变量,如果有相关经验的同学还请不吝赐教啊。
九、关于整体最优
到目前为止,我们已经对knative的架构还有性能有了一个整体的认识。knative在性能上是有损耗的,但他能够成为CNCF的一部分,作为云函数的事实标准,还是有他的可取之处。这里我从资源利用率,应对流量激增,项目维护和开发效率来展开说明,它在这些部分做到了整体最优。
(一)资源利用率
对于传统的部署方式,很多业务会把告警水位调整得很低,我们目前是30%。也就是说,一个模块日常会有70%的资源在空跑。假设有10个模块,每个模块有10台机器。那每个模块浪费了7台机器,一共浪费了70台。
假如我们通过knative的组织方式,平时在跑的仍然会有38台机器 (30/0.8)。这里需要看业务的历史负载,如果历史上同时并发最高需要60台机器,那么knative的部署方式需要冗余的机器为: 75。这种部署方式节省了25%的资源 (100-75)/100。
此外,我们还可以将一些流量曲线互补的业务进行混部,比如业务A流量集中在上午,业务B流量集中在晚上,我们将A,B两个业务进行混部,通过云函数的缩容能力,可以提升资源利用率。
(二)应对流量激增
我们的业务中,存在着部分业务,可能一两个星期都没有太多量,一旦有量,会几倍甚至十几倍地激增,激增时间又持续不到一天。这种流量分布,使用传统cvm的部署方式。目前是将机器水位调整到30%以下,以确保能够承载激增的流量。
如果我们用传统的上云方式,将服务部署到pod中,基于HPA来伸缩,基本上可以解决这个问题,但HPA响应不是很灵敏,偶尔还是会造成服务抖动,导致用户访问失败。
这种流量分布,Knative就是一个比较好的解决方案,平时基本没量,可以缩容成1个最小配置的pod,有量时,可以灵敏扩容。
(三)项目维护
我们有较多不同业务部署在同一个服务的场景,这和项目历史有关系,项目开始时比较小,不同页面都放在同一个仓库下一起部署,随着项目的发展,这个仓库越变越大,各种业务耦合在一起,容易改出问题,而且业务的流量激增还会相互影响。想要把这些不同的业务拆出来以新模块部署,因为新增模块需要结合内部运维系统做各种配置,开发心智负担较高。这种场景用云函数就可以很好地解决,将不同的页面拆分成为不同的云函数维护,开发只需要关注单个业务的逻辑,很好地解决了业务耦合还有流量互相影响的问题。
(四)开发效率
云函数的方式,开发同学只需要写业务的代码逻辑,不需要关注服务器,部署环境,运维配置,不需要关注扩缩容和裁撤。云函数对于业务开发同学很友善,解放了开发在服务运维,新增模块时的生产力。
十、小结
我们来回顾一下开篇的描述:
knative是一个云原生的云函数框架。他在kubernetes之上,通过kubernetes提供的能力以及相关的扩展,对pod中的流量进行监控,从而做到对pod进行更加灵敏地伸缩。他是serverless的事实标准,除了自动伸缩之外,还提供了源码构建以及事件机制。
现在对于这段描述应该会更清晰了。
knative作为云原生的一部分,最大化地利用了“云”的能力、发挥了“云”的价值,它以性能换取了灵敏度,以低心智负担的方式,做到了整体最优。
作者简介

赖智辉
腾讯前端开发工程师
腾讯前端开发工程师,毕业于华南农业大学。目前在支持企业微信web相关的工作,对低代码平台,跨端性能优化和云原生有一定的了解。
推荐阅读

温馨提示:因公众号平台更改了推送规则,公众号推送的文章文末需要点一下“赞”和“在看”,新的文章才会第一时间出现在你的订阅列表里噢~
-
相关阅读:
git常见命令和操作
JavaScript对象、函数、作用域、字符串
【无标题】
[plugin:vite:css] variable @base-color is undefined
【Linux】文件系统中inode与软硬链接以及读写权限问题
docker 实战
(龙霸区块链)公链开发学习笔记
Spring Expression Language (SpEL) 介绍与使用方法
Git操作
五十二.PPO算法原理和实战
- 原文地址:https://blog.csdn.net/QcloudCommunity/article/details/126006157