-
使用神经网络实现对天气的预测
1.神经网络原理简单理解
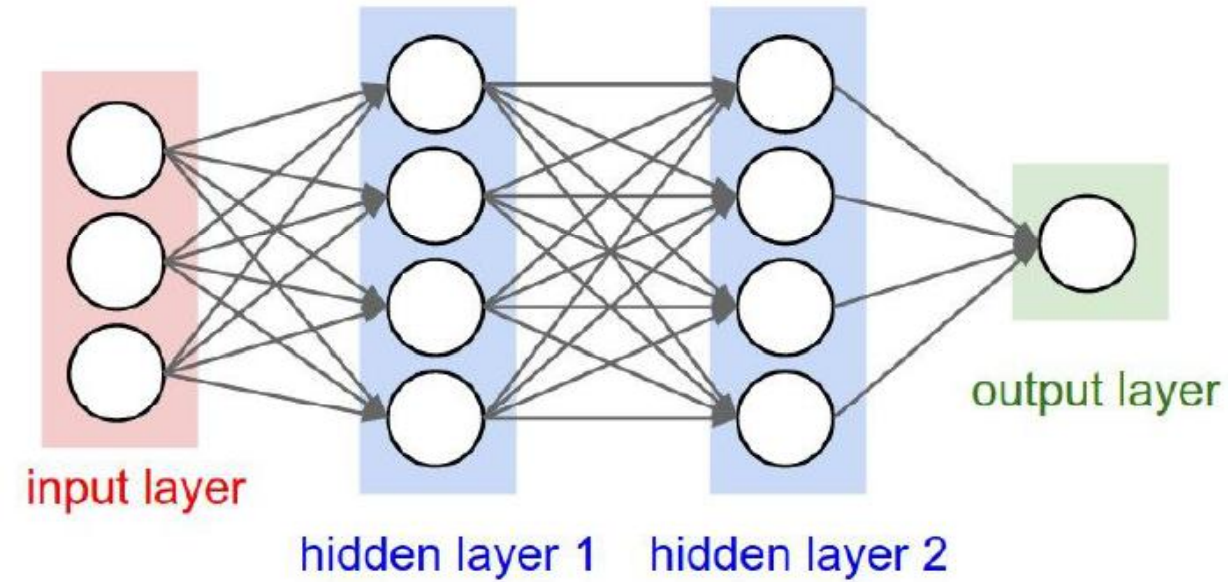
如图所示这个神经网络分为:- 输入层
其中的输入层的每一个节点代表的是一个对象的其中的一个特征,这个些特征可以用一个矩阵x表示,因为这是我们人类看的懂的东西,所以要转换成计算机看的懂的东西。
使用函数进行计算,w是权重,b是偏置。
y=w1x+b1
我们通过不断的训练这个函数,通过反向传播进行梯度下降的到最好的w和b能够拟合这些数据。
其中输如层有3个节点是一个1x3的矩阵,对应的隐藏是一个1x4的矩阵,则要乘以w1是一个3x4的矩阵,b是一个1x4的矩阵。
其中神经网络还需要一个激活函数,常用的有的sigmoid,relu,tanh,因为神经网络对应的是一个线性化的函数,我们有的时候要解决非线性化的问题,所以引入激活函数,解决线性模型不能解决的问题。-
隐藏层
-
输出层
总而言之,神经网络就是找到最合适的w和b使得其函数图形能够包含我们需要的样本点。如图所示,我们的神经网络的图形就是绿色的,正好包含了所有的正例,等我下次预测的时候,也就是把特征丢进去,他就会输入一个在绿色图像的点。
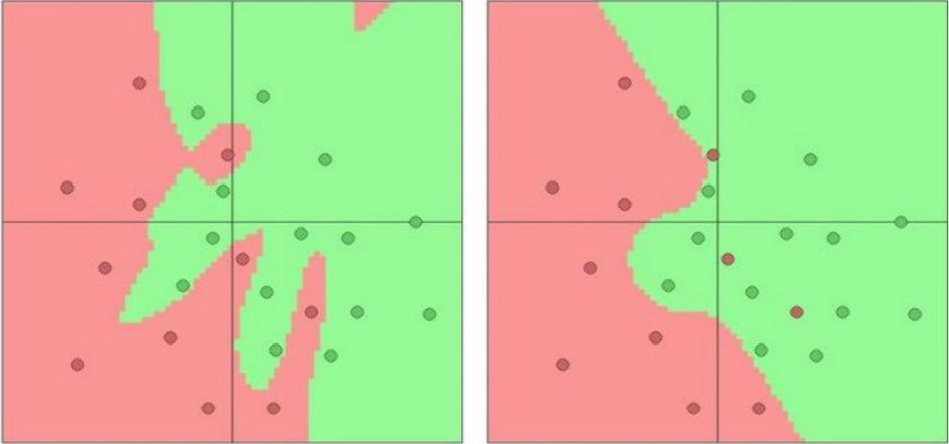
这块有点讲解的不是很清楚,大家可以参考一下其他网上的帖子。2.使用神经网络预测天气案例
为了更好的学习神经网络,我学习了一个例子。
这个例子的数据集是348天的天气情况,根据这些天气情况的特征进行预测。
数据集:链接:https://pan.baidu.com/s/1NORkTP-OFOfsbRVvyt29sw
提取码:kibn- 加载数据
import numpy as np import pandas as pd import datetime import matplotlib.pyplot as plt from sklearn import preprocessing # 加载数据 def data_load(filepath): '''数据表中 year,moth,day,week分别表示的具体的时间 temp_2:前天的最高温度值 temp_1:昨天的最高温度值 average:在历史中,每年这一天的平均最高温度值 actual:这就是我们的标签值了,当天的真实最高温度 friend:这一列可能是凑热闹的,你的朋友猜测的可能值,咱们不管它就好了''' features=pd.read_csv(filepath) # 打印数据格式 print(features.head()) print(features.shape) # 一共有348条数据 return features- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
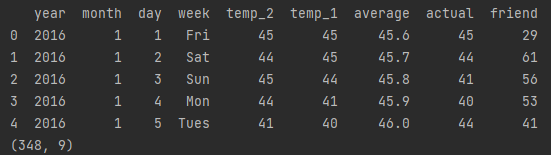
得到的数据是当前天气,前天,昨天的天气,数据如下
- 展示数据
为了让大家更好的了解数据的情况,做了一个可视化展示现在所有的数据
def showpicture(features): # 处理时间数据 years = features['year'] months = features['month'] days = features['day'] # 转换成datetime格式 dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)] # 将string格式的按照要求转换成时间格式 dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates] # print(dates[:5]) # 独热编码 # 因为我们的数据中的星期是字符串格式,所以将星期做一个独热编码就会转换成对应的数据 features = pd.get_dummies(features) # print(features.head(5)) # 将数据画成图片 # 指定默认风格 plt.style.use('fivethirtyeight') # 设置布局 fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(10, 10)) fig.autofmt_xdate(rotation=45) # 表示对图中的x轴进行45度的翻转 # 标签值(实际值) ax1.plot(dates, features['actual']) ax1.set_xlabel('day'); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp') # 昨天 ax2.plot(dates, features['temp_1']) ax2.set_xlabel('day'); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp') # 前天 ax3.plot(dates, features['temp_2']) ax3.set_xlabel('day'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp') # 我的朋友 ax4.plot(dates, features['friend']) ax4.set_xlabel('day'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate') plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
如图所示,对应的是当前最高气温、昨天最高气温、前天最高气温,其中的朋友预测的天气可以忽略不看。

- 处理数据
# 处理数据 def data_handle(features): # 独热编码 # 因为我们的数据中的星期是字符串格式,所以将星期做一个独热编码就会转换成对应的数据 features = pd.get_dummies(features) # 标签 # 在我们的数据中,除开actual是一个我们实际值y,其他的值都是x # 所以当读把他抽取出来 labels=np.array(features['actual']) # print(labels) # 在特征中去掉标签 features=features.drop('actual',axis=1) # 名单单独保存一下,以备后患 features_list=list(features.columns) print(features_list) # 将数据转换成合适的格式 features=np.array(features) # print(features) # print(features.shape) # 因为我们的原始数据中的month和day都比较小,所以我可以对features做一个标准化,这样到时候训练收敛会更快一些 input_features=preprocessing.StandardScaler().fit_transform(features) return input_features,labels- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 训练模型预测天气
这里是初学神经网络,所以就把训练集当作测试集,然后通过图像展示,更加直观的看到预测的数据的拟合程度。
import torch from data_load.preprocessdata import data_load,data_handle,showpicture from model.modeling import Neural import torch.nn as nn import numpy as np import datetime import pandas as pd import matplotlib.pyplot as plt if __name__=='__main__': # 加载数据 features=data_load('./data/temps.csv') # 将数据生成统计图 # showpicture(features) # 将真实值和预测数据分离开 input_features,labels=data_handle(features) # 使用torch.nn构建神经网络 x = torch.tensor(input_features, dtype=float) y = torch.tensor(labels, dtype=float) # 设置参数 input_size=input_features.shape[1] # (348,14),原始数据是一个348行14列的矩阵 hidden_size=128 output_size=1 batch_size=16 # 分批次训练,每次使用16个数据 my_nn=nn.Sequential( nn.Linear(input_size,hidden_size), # 输入层有14个节点,隐藏层有128个节点 nn.Sigmoid(),# 激活函数使用的是sigmoid函数 nn.Linear(hidden_size,output_size), # 输出层 ) # 定义损失函数,使用的是均方损失函数 cost=nn.MSELoss(reduction='mean') # 构造一个优化器,可以减少输入数据的噪音,使得数据更加便于训练 optimizer=torch.optim.Adam(my_nn.parameters(),lr=0.001) # 训练网路 losses=[] for i in range(1000): batch_loss=[] # 使用MINI-Batch方法来进行训练 for start in range(0,len(input_features),batch_size): end=start+batch_size if start+batch_size- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
每100次显示一次的loss:
100 37.94807 200 35.65217 300 35.278557 400 35.112137 500 34.977985 600 34.857384 700 34.736656 800 34.610817 900 34.47966- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
使用matplotlib.pyplot可视化我们预测的天气与真实天气的拟合情况:

3.总结
通过这个小实验,让我简单的理解了神经网络就是一个一个数学函数,训练这个模型就是找到最合适的参数,能够使这些函数完美的包含我们的样本点,下次预测的时候,就将特征输入进去,就能够通过函数计算出哪个y,就是我们预测值.
- 输入层

TCP三次握手四次挥手
《Vue入门到精通之vue-router路由详解》
微信小程序中生成普通二维码,并根据二维码里的参数跳转对应的页面
Harbor仓库
vue3使用pinia实现数据缓存
打印工具HandyPrint Pro Mac中文版软件特点
java计算机毕业设计教师资格考试辅导系统源码+mysql数据库+系统+lw文档+部署
C语言 ——深入理解指针(2)
【vscode编辑器插件】前端 php unity自用插件分享