-
Hive-基本概念
目录
什么是Hive
- Hive是建立在Hadoop之上的开源数据仓库,将存储在Hadoop文件中的结构化、半结构化的数据文件映射为一张数据表,基于表提供类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
- Hive的核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群执行,并YARN进行资源管理。
为什么使用Hive
Q:Hive的底层存数据用HDFS存,计算用MapReduce来计算 ,可以发现Hive是基于Hadoop来使用的,那么为什么不干脆使用Hadoop呢?
A:Hive为我们提供了可以编写SQL的功能,而不是编写程序,SQL的学习成本低,使用简单,Hive将对应的SQL转换成为MapReduce程序完成对数据的分析,有了Hive的加持,我们可以在Hadoop上写SQL来进行数据的搜索。
Hive的工作过程

案例:在HDFS文件系统上有一个user.txt文件,现在需求是查询来自上海且年龄大于25的用户数量

Step1:用户编写查询该文件数据的SQL语句
Step2:Hive将SQL进行语法解析,检查是否存在语法错误
Step3:元数据之前已经在数据库中存储好了,即文件和数据表已经形成映射,当写SQL查询时,去数据库中找到对应的元数据信息,Hive将SQLMapReduce程序,将元数据传入该程序,根据元数据信息找到具体的HDFS文件进行查找。
Step4:将执行计划转换成MapReduce程序来执行,将执行结果封装返回给用户
提到的几个概念
元数据-MetaData
也就是HDFS中的文件和数据库中表的映射关系,元数据记录着所存储数据的一些属性,比如表对应着哪个文件,表的列对应文件哪一个字段,文件字段之间的分隔符是什么。
元数据存在mysql或Hive自带的derby中,分析的那些文件数据在HDFS上。
元数据服务-MetaStore
元数据服务用来管理元数据,对外暴露服务地址,让各种客户通过连接metastore,由metastore再去连接MySQL数据库来存取数据,这些客户可以同时连接,且不需要知道MySQL数据库的用户名和密码,在某种程度上也保证了元数据的安全。

Hive的架构和组件
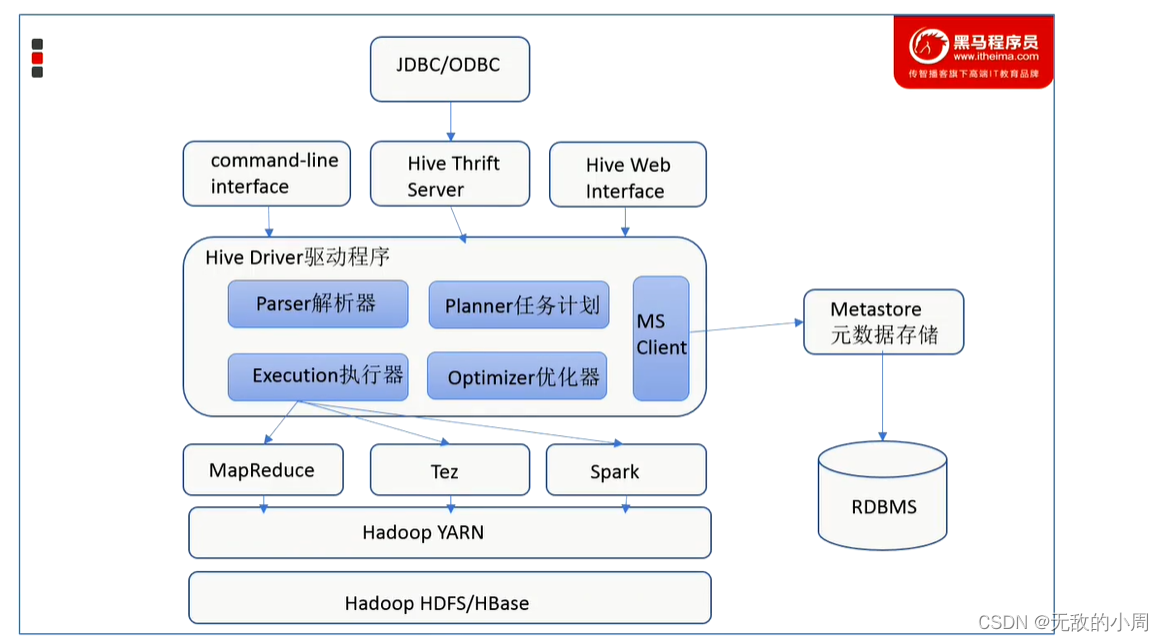
- 用户接口
CLI(command line interface)是shell命令行,JDBC/ODBC也就是通过编译程序来访问,Hive Web interface 是通过网页来访问
- Hive Driver驱动程序
完成HQL查询语句从语法分析,编译,优化及查询计划的生成,生成的查询计划存储在HDFS中,并在随后由执行引擎(如MapReduce,Spark,Tez)调用执行
-
相关阅读:
Minio多节点多驱动分布式部署官网文档翻译
机器学习算法——集成学习4(Bagging)
前端基础自学整理|HTML + JavaScript + DOM事件
链表之删除单链表中的重复节点
电脑为什么会蓝屏的原因
python项目开发常用的目录结构
jmeter 正则表达式提取返回报文data里面的\“id\“:312254,的值
ThingsBoard教程(二八):详细讲解在tb平台下 mqtt协议下的 rpc 遥测,客户端rpc,服务的rpc的使用 ,与node-red联动
Linux下编译MySQL++及简单使用
对一个即将上线的网站,如何做一个较完整的Web应用/网站测试?
- 原文地址:https://blog.csdn.net/weixin_52972575/article/details/125983094