-
推荐系统 学习笔记
推荐系统
一、推荐系统的基础概念
转化流程:不同的应用场景会有不同的转化流程,一般包括 曝光、点击、滑动到底、点赞和收藏等。不同的转化流程有不同模型特点。
1. 消费指标:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-unPRYqDs-1658807811714)(C:\Users\YY\AppData\Roaming\Typora\typora-user-images\1658374040489.png)]](https://1000bd.com/contentImg/2022/07/30/081340450.png)
点击率越高,说明推荐越精准。但这不是唯一指标
归一化函数:f(笔记长度),此函数与笔记长度有关。笔记越长,完成阅读的比率越低。小结:系统推荐用户喜欢的笔记,会让消费指标上涨从而推荐出更多,这会让用户失去兴趣。
改变方向踏入多样性,有利于保持用户粘性。2. 北极星指标
衡量推荐系统好坏的根本指标
- 用户规模:日活跃用户数(DAU)、月活跃用户数(MAU)
- 消费:人均使用推荐的时长、人均阅读笔记的数量
- 发布:发布渗透率、人均发布量
3. 实验流程
- 离线实验:收集历史数据,在历史数据上做实验和测试。
- 小流量AB测试:把算法部署到实际产品中,用户实际跟算法做交互。将用户分为实验组和对照组,计算指标。比较新旧策略的指标数值。
- 全流量上线:
二、推荐系统链路
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NcnKMoxe-1658807811715)(C:\Users\YY\AppData\Roaming\Typora\typora-user-images\1658375729346.png)]](https://1000bd.com/contentImg/2022/07/30/081340526.png)
召回通道:协同过滤、双塔模型、关注的作者等等。在召回中,做去重和过滤,过滤掉用户不喜欢的话题等等。
粗排:用简单模型快速打分
精排:用较大的神经网络进行打分,分数更可靠,但是参数更多,计算更复杂。
重拍:考虑多样性,用规则打散相似内容。插入广告和运营推广的内容。三、召回
1、ItemCF
(1) ItemCF的原理
用户喜欢A,A与B相似,那么可以给用户推荐B。
(2) ItemCf的具体实现原理
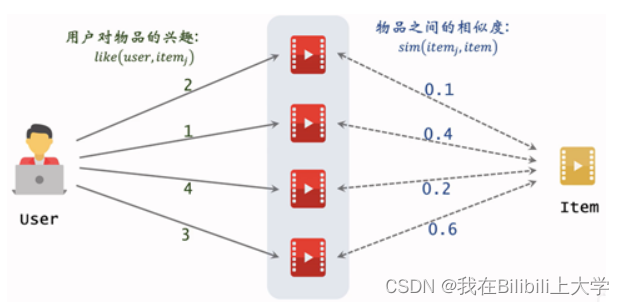
like(user,itemj):某用户对 j物品的喜欢程度
sin(itemj,item):Item和j 物品的相似度
预估用户对候选物品的兴趣:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MagRIkKv-1658807811716)(C:\Users\YY\AppData\Roaming\Typora\typora-user-images\1658456383776.png)]](https://1000bd.com/contentImg/2022/07/30/081340745.png)
(3) 物品的相似度
判断相似的基本思路:
- 两个物品的受众重合度很高,两个物品相似
例如A与B都被同一个读者使用。或A有一百个用户,B也有一百个,如果AB用户中有80人是一样的,那么可以判断AB相似。
计算相似度:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MDPsBP1r-1658807811716)(C:\Users\YY\AppData\Roaming\Typora\typora-user-images\1658456697207.png)]](https://1000bd.com/contentImg/2022/07/30/081340885.png)
此公式没有考虑用户的喜欢程度like(),如果考虑进去,那么就是:(余弦相似度)
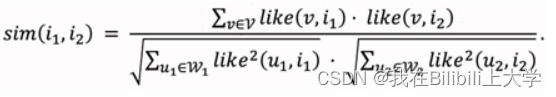
(4) ItemCF召回的完整流程
事先做离线计算
- 建立“用户–>物品”的索引:记录用户最近交互的ID;给定任意用户ID,可以找出近期感兴趣的物品列表。
- 建立“物品–>物品”的索引:计算物品两两相似度;给定任意物品,索引最相似的K个物品;给定任意ID,可以快速找到相似的K个物品。
线上召回
- 给定用户id,利用“用户–>物品”索引寻找最感兴趣的 N件商品
- 每件商品根据“物品–>物品”索引寻找最相似的K件商品
- 预估所有商品的兴趣分数(对多就是N*K个)
- 从3中取出前100个
2、Swing模型
额外考虑重合的用户是否来自同一个小圈子。
如果用户是来自小圈子,那么需要对圈子用户进行减权。用户相似度的计算:相似度越高,那么两个人来自同一个小圈子的概率越大。

物品相似度的计算:

α 是人工设置的参数,需要不断调节。
3、基于用户的协同过滤(UserCF)
(1) UserCF的原理
用户A和B是相似的,若A喜欢一篇笔记,B没有进行阅读,那么系统极可能会将此篇笔记推荐给B。
(2) 判断相似的方法
方法一:点赞、收藏、转发的笔记有很大重合。
方法二:关注的作者有很大重合。(3) UserCF的实现
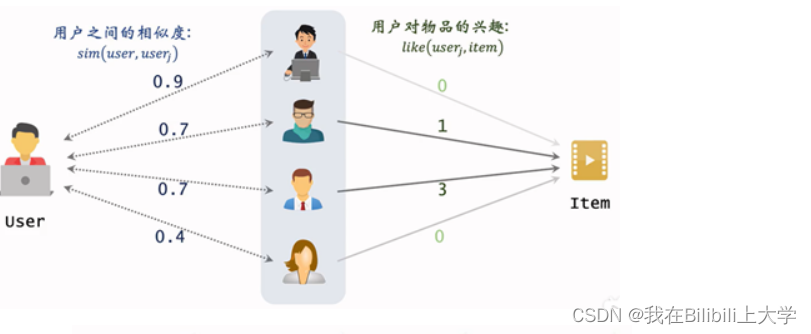
预估用户对候选物品的兴趣:
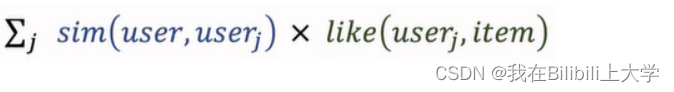
(4) 计算用户的相似度
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-351Jp2eY-1658807811719)(C:\Users\YY\AppData\Roaming\Typora\typora-user-images\1658738462187.png)]](https://1000bd.com/contentImg/2022/07/30/081341799.png)
(5) 热门物品减权
越热门的物品,越无法反映用户的独特品味。
考虑到热门物品在计算相似度时作用不大,那么相似度计算公式可以改写为:

其中
nL表示喜欢物品L的用户数量,反应热门程度。(6) UserCF召回通道
-
事先做离线计算
- 建立“用户—物品”的索引
- 建立“用户—用户”的索引
-
线上做召回
类似 ItemCF,可以自己推导
4、离散特征处理
处理步骤:
- 建立字典:把类别映射成序号
- 向量化:把序号映射成向量
- One-hot编码:把序号映射成高维稀疏向量
- Embedding:把序号映射成低维稠密向量
5、矩阵补充
(1) 基本想法
用户embedding参数矩阵记作A。第u号用户对应矩阵的第u列,记作向量au。示例如下图:
物品embedding参数矩阵记作B。第i号物品对应矩阵的第i列,记作向量bi。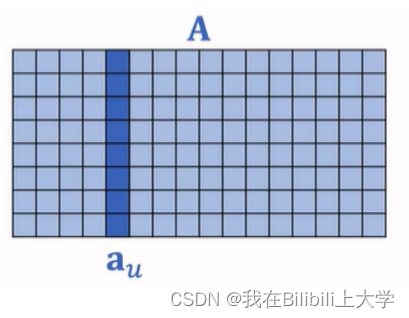
内积
数据集
(用户ID,物品ID,兴趣分数)的集合,记作
Ω = { ( u,i,y ) }训练
求解优化问题,得到参数A和B:
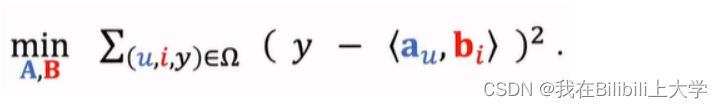
解释:任取数据集,希望 真实值y 与 预估值
(2) 矩阵补充
类似用户矩阵,矩阵的每行对应一个用户,每列对应一个物品,那么矩阵 (i,j) 表示用户 i 对物品 j 的兴趣分数。我们根据训练得出的用户向量物品向量,来补充其他未知的矩阵元素。

实践中不好用…- 仅用 ID ,没利用物品,用户属性。
- 负样本的选取方式不对。
- 做训练的方法不好
(3) 线上服务
模型存储
- 训练得到矩阵A和B
- 把矩阵A的列存储到key-value表
· key是用户ID,value是A的一列
· 给定用户ID,返回一个向量(用户的embedding)
线上服务
- 把用户ID作为key,查询key-value表,得到该用户的向量,记作a
- 最近邻查找:查找用户最有肯能感兴趣的k个物品,作为召回结果
近似最近邻查找
这个还是看视频比较好,链接在最底下。
6、双塔模型
将用户的ID、离散特征和用户离散特征映射成特征向量,整合输入到神经网络得到另外一个向量,此向量为用户的表征,用于召回。
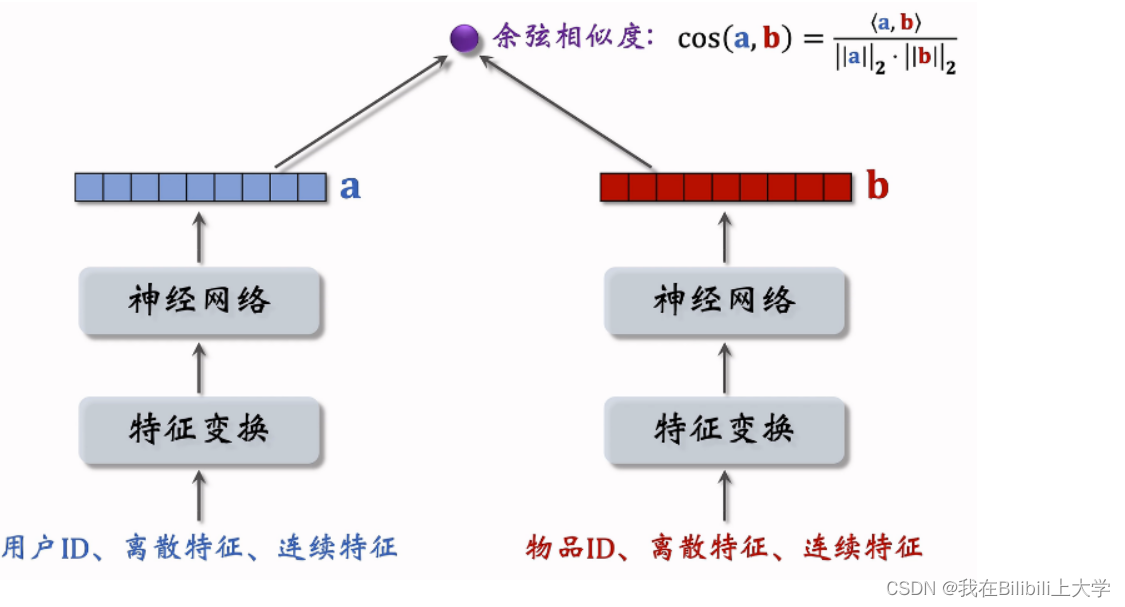
(1) 双塔模型
左右两座塔分别得到两个向量,用于计算余弦相似度。与之前模型不同,此模型不仅有用户ID,还加入了用户的其他特征。
(2) 双塔模型的训练
取正负样本进行训练,训练方法有:Pointwise,Pairwise,Listwise。
后两种方法参考论文:

Pointwise训练
- 把召回看作二元分类任务
- 对于正样本,鼓励cos(a,b) 接近+1
- 对于负样本,鼓励cos(a,b) 接近-1
- 控制正负样本数量为 1:2 或者 1:3
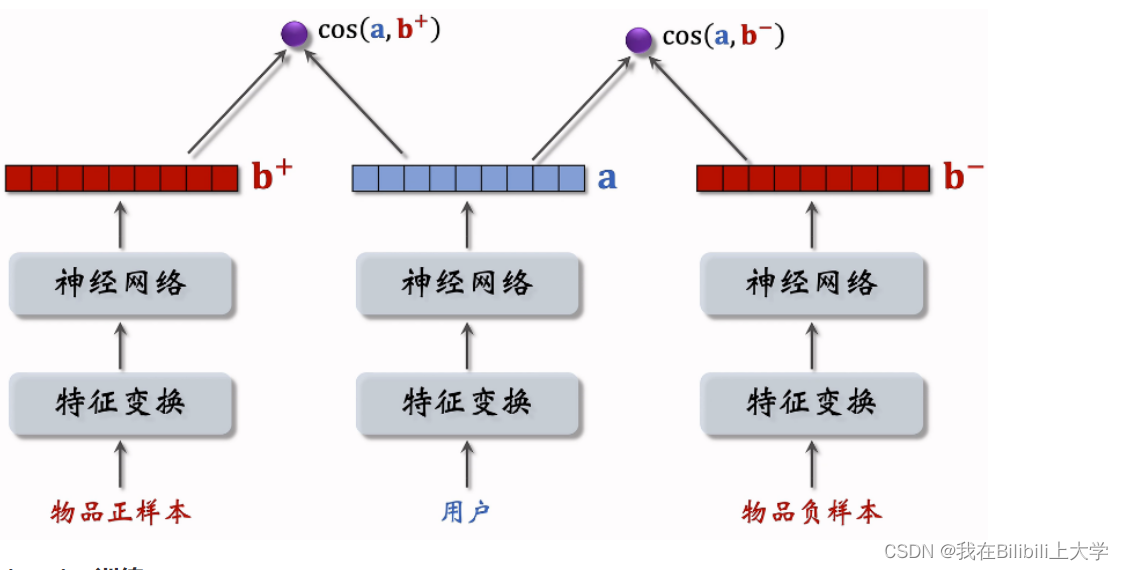
Pairwise训练
基本想法:鼓励cos(a,b+)大于cos(a,b-),两者之差越大越好
Listwise训练
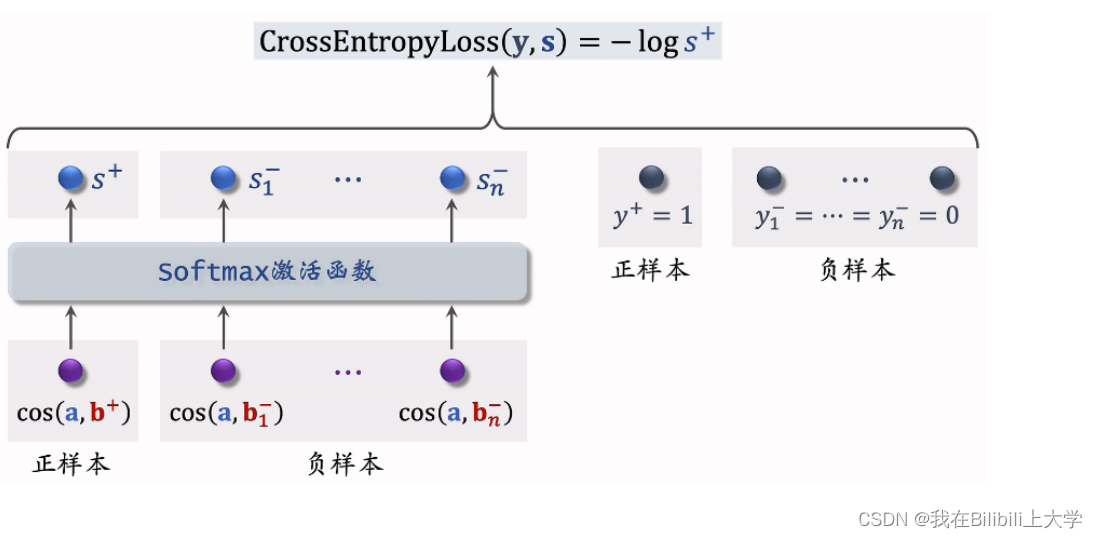
07 双塔模型—正负样本
进行双塔模型(召回模型)的训练时,需要选择正负样本,如何选择呢?
1、正样本
正样本:曝光而且有点击的 用户—物品 二元组
问题:说部分样品占据大部分点击,导致正样品大多是热门物品
解决方案:过采样冷门物品(一个样本出现多次),或降采样热门物品(一些样本被抛弃)选择训练双塔模型的负样本:
- 没有被召回
- 被召回,但是没有选中和曝光
- 被曝光,但是没有被点击
2、简单负样本:全体物品
- 均匀抽样:对冷门物品不公平
- 非均匀采样:目的是打压热门物品(0.75为经验值)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XKYACypJ-1658985737368)(C:\Users\wzk\AppData\Roaming\Typora\typora-user-images\image-20220728094916154.png)]
3、简单负样本:Batch内负样本
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kpbS8kU2-1658985737368)(C:\Users\wzk\AppData\Roaming\Typora\typora-user-images\image-20220728095107403.png)]
正样本:用户—点击—物品(一行)
负样本:非同一行(如图) ,一共有n(n-1)个负样本修正偏差:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Toao9S3y-1658985737369)(C:\Users\wzk\AppData\Roaming\Typora\typora-user-images\image-20220728095437650.png)]4、困难负样本
这类样本容易被判定为正样本:
- 被粗排淘汰的物品(比较困哪)
- 精排分数靠后的物品(非常困难)
不要用
曝光但未被点击的样本作为负样本进行模型训练5、选择负样本的原理
目标:快速找到用户可能感兴趣的物品
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xULYZy20-1658985737369)(C:\Users\wzk\AppData\Roaming\Typora\typora-user-images\image-20220728100530101.png)]
经验结论:第三点可以作为排序的负样本,不能作为召回的负样本
08 双塔模型:线上召回和更新
1、离线存储:把物品向量b存入向量数据库
- 完成训练之后,把物品塔计算每个的特征向量b
- 把几亿个物品向量b存入向量数据库
- 向量数据库建索引,以便加速最近邻查找
存储物品信息,便于算法实现
2、线上召回:查找用户最感兴趣的k个物品。
-
给定用户 ID 和画像,线上用神经网络算用户向量 a 。
-
最近邻查找:
-
把向量 a 作为 query ,调用向量数据库做最近邻查找。
-
返回余弦相似度最大的 k 个物品,作为召回结果。
-
因为用户兴趣动态变化,物品特征相对稳定,所有需要存储物品向量,实时计算用户向量。
3、模型的更新
全量更新:今天凌晨,用昨天全天的数据训练模型。
- 在昨天模型参数的基础上做训练。(不是随机初始化)
- 用昨天的数据,训练 lePoch ,即每天数据只用一遍。
- 发布新的用户塔神经网络和物品向量,供线上召回使用。
- 全量更新对数据流、系统的要求比较低。
增量更新:做 online learning 更新模型参数。
- 用户兴趣会随时发生变化。
- 实时收集线上数据,做流式处理,生成 TFRecord 文件。
- 对模型做 online learning,增量更新 ID Embedding 参数。(不更新神经网络其他部分的参数)
- 发布用户 ID Embedding ,供用户塔在线上计算用户向量。
根据用户新的兴趣,需要小时级别的增量更新。对数据流的要求很高,训练数据文件不断生成。当用户刷新时,双塔模型会根据训练的数据实时更新信息。
09:地理位置召回、作者召回、缓存召回
1、GeoHash召回
- 用户可能对附近发生的事感兴趣。
- GeoHash :对经纬度的编码,地图上一个长方形区域
- 索引: GeoHash—>优质笔记列表(按时间倒排,最新的在最前面)
- 这条召回通道没有个性化
GeoHash:
可以自行百度搜索此算法
2、作者召回
(1) 关注作者召回
-
用户对关注的作者发布的笔记感兴趣。
-
索引:
-
用户—>关注的作者
-
作者—>发布的笔记
-
-
召回:
- 用户—>关注的作者—>最新的笔记
(2) 有交互的作者召回
- 如果用户对某笔记感兴趣(点赞、收藏、转发),那么用户可能对该作者的其他笔记感兴趣
- 索引:用户—>交互的作者
- 召回:用户—>有交互的作者—>最新的笔记
(3) 相似作者召回
-
如果用户喜欢某作者,那么用户喜欢相似的作者。
-
索引:作者—>相似作者(K个相似作者)
-
召回:用户—>感兴趣的作者(N个关注作者)—>相似作者(共NK个作者)—>最新的笔记(NK篇笔记)
(4) 缓存召回
想法:复用前 n 次推荐精排的结果。
背景:
- 精排输出几百篇笔记,送入重排
- 重排做多样性抽样,选出几十篇精排
- 精排结果一大半没有曝光,被浪费。
做法:精排前 50 ,但是没有曝光的,缓存起来,作为一条召回通道”
缓存大小固定:需要退场机制。
- 一旦笔记成功曝光,就从缓存退场。
- 如果超出缓存大小,就移除最先进入缓存的笔记。
- 笔记最多被召回 10 次,达到 10 次就退场。
- 每篇笔记最多保存 3 天,达到 3 天就退场。
近似最近邻查找:11分10秒开始
本文是在观看此系列视频做出的笔记,我觉得讲的超级好,干货满满
本文仅供学习参考
-
相关阅读:
【论文笔记】基于深度学习的移动机器人自主导航实验平台
8月8日下午6:00面试总结
vue之组件传值---父传子(属性)---子传父(emit,sync,v-model)
ArcGIS教程——ArcGIS工具-按线分割面
blazor调试部署全过程
XHR level2的新功能
c# Class vs Structure
Spring MVC应该怎么学?这份教程带你快速入门,深入剖析源码!
借助Spire.Doc for Java控件,将 ODT 转换为 PDF。
【web-攻击用户】(9.1.6)查找并利用XSS漏洞--基于DOM
- 原文地址:https://blog.csdn.net/qq_43693424/article/details/125991960