-
4、敏感词过滤(前缀树)

前缀树根节点为空,其他节点只包含一个字符。
从根节点到某节点,连起来的每个路径,就是当前节点的字符串。例如:敏感词构成一个前缀树
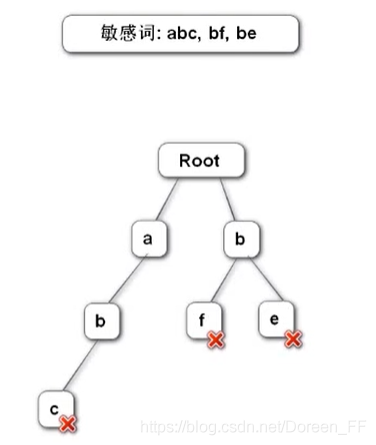
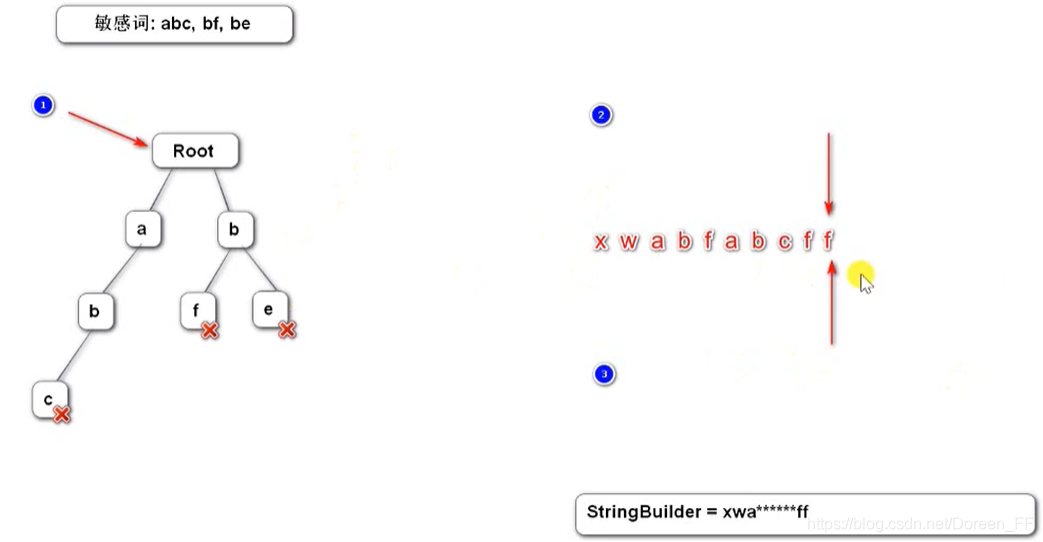
3个指针:1指针指向根节点,2指针一直往前走,3指针往返
1、定义前缀树
前缀树的数据结构,util包下的SensitiveFilter.java。
主要有两个成员变量,关键词结束标志和子节点,在节点的数据结构中建立hashmap用于存储结构。private class TrieNode { // 关键词结束标志 private boolean isKeywordEnd = false; // 子节点(key是下级字符,value是下级节点) private Map<Character, TrieNode> subNodes = new HashMap<>(16); public boolean isKeywordEnd() { return isKeywordEnd; } public void setKeywordEnd(boolean keywordEnd) { isKeywordEnd = keywordEnd; } /** * 添加子节点 * * @param c 字符 * @param node 前缀树节点 */ public void addSubNode(Character c, TrieNode node) { subNodes.put(c, node); } /** * 获取子节点 * * @param c 字符 * @return 子节点的引用 */ public TrieNode getSubNode(Character c) { return subNodes.get(c); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2、根据敏感词初始化前缀树
读取敏感词文件中的所有敏感词,构造敏感词构成的前缀树。每读取到一个敏感词,就加到前缀树中。
其中将一个敏感词加入到前缀树的操作:先新建一个子节点,然后再通过本节点hashmap的put操作,将子节点添加到本节点的map中。例如,添加abc就需要新建a节点,根节点put(a,a节点),新建b节点…,新建c节点…;添加完abc敏感词后,再添加abd时,只需要一直循环到b节点后,新建c节点,map对应关系即可。@Component public class SensitiveFilter { private static final Logger LOGGER = LoggerFactory.getLogger(SensitiveFilter.class); /** * 替换符 */ private static final String REPLACEMENT = "***"; /** * 根节点 */ private TrieNode rootNode = new TrieNode(); /** * 程序启动时,或初次调用时初始化好,只需要初始化一次, * 容器实例化以后,调用构造器,这个方法就会被调用, * 这个bean在服务启动时候初始化,所以这个方法在服务启动时候 * 就会被调用。 */ @PostConstruct public void init() { long start = System.currentTimeMillis(); try ( InputStream is = this.getClass().getClassLoader() .getResourceAsStream("sensitive-words.txt"); BufferedReader reader = new BufferedReader(new InputStreamReader(is)) ) { String keyword; while ((keyword = reader.readLine()) != null) { // 添加到前缀树 this.addKeyword(keyword); } } catch (IOException e) { LOGGER.error("加载敏感词文件失败:" + e.getMessage()); e.printStackTrace(); } LOGGER.info("构建前缀树时间:" + String.valueOf(System.currentTimeMillis() - start) + "ms"); } /** * 将一个敏感词添加到前缀树中 * * @param keyword */ private void addKeyword(String keyword) { TrieNode tempNode = rootNode; for (int i = 0; i < keyword.length(); i++) { char c = keyword.charAt(i); TrieNode subNode = tempNode.getSubNode(c); if (subNode == null) { subNode = new TrieNode(); tempNode.addSubNode(c, subNode); } // 指向子节点,进入下一轮循环 tempNode = subNode; // 设置结束标志 if (i == keyword.length() - 1) { tempNode.setKeywordEnd(true); } } } private boolean isSymbol(char c) { // 0x2E80 到 0x9FFF为东亚文字 return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
3、过滤敏感词
过滤某个字符串的敏感词,如果有,则转化为***。这里新建一个字符串,不是敏感词的,直接append,是敏感词的,append()。
指针1为根节点,指针2一直往前走,指针3往返,新建一个字符串。
如果遇到符号,符号再begin位置,则指针2、3都加一,否则指针3加一。
begin不动,position不断增加。
如果遇到了完整的敏感词(即标志位为真),将position-begin替换为*,添加到新字符串,然后begin = position+1。
如果没有敏感词,将该字符添加到新字符串中,begin = position + 1。/** * 过滤敏感词 ** 对于敏感词中有符号的先去除符号 * * @param text 待过滤的文本 * @return 过滤后的文本 */
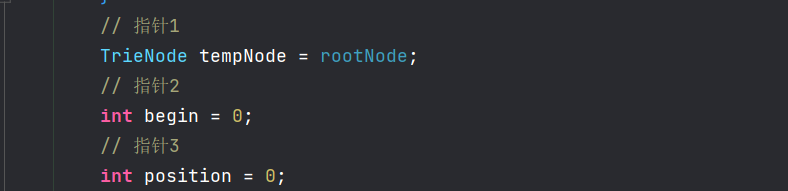
public String filter(String text) { if (StringUtils.isBlank(text)) { return null; } // 指针1 TrieNode tempNode = rootNode; // 指针2 int begin = 0; // 指针3 int position = 0; // 结果 StringBuilder sb = new StringBuilder(); while (begin < text.length()) { if (position < text.length()) { char c = text.charAt(position); // 跳过符号 if (isSymbol(c)) { // 若指针1处于根节点,将此符号计入结果,让指针2向下走一步 if (tempNode == rootNode) { sb.append(c); begin++; } // 无论符号在开头或者中间,指针3都向下走一步 position++; continue; } // 检查下级节点 tempNode = tempNode.getSubNode(c); if (tempNode == null) { // 以begin开头的字符串不是敏感词 sb.append(text.charAt(begin)); // 进入下一个位置 position = ++begin; // 重新指向根节点 tempNode = rootNode; } else if (tempNode.isKeywordEnd()) { // 发现敏感词,将begin- position字符串替换掉 sb.append(REPLACEMENT); // 进入下一个位置 begin = ++position; // 重新指向根节点 tempNode = rootNode; } else { // 检查下一个字符 position++; } } // position遍历越界仍未匹配到敏感词 else { sb.append(text.charAt(begin)); position = ++begin; tempNode = rootNode; } } return sb.toString(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
4、难点
遇到敏感词为fabcd和abc,要检测的字符串最后一段为fabc
原来以指针3position作为循环判断条件,此时指针2为f,循环之后指针3为c,c不是fabcd的敏感词标志位节点,所以直接跳出了,没有检测f之后的字符作为begin的情况。
所以要以指针2begin作为循环条件。 -
相关阅读:
安全机密管理:Asp.Net Core中的本地敏感数据保护技巧
程序开机自启动(基于linux)
DayDayUp:计算机技术与软件专业技术资格证书之《系统集成项目管理工程师》课程讲解之十大知识领域之4辅助—项目人力资源管理
C++11的lambda表达式
ARM裸板调试之串口打印及栈初步分析
Dreamweaver网页设计与制作100例:用DIV+CSS技术设计的书法主题网站(web前端网页制作课作业)
ElasticSearch(二):Docker 部署ES
计算机学院改考后,网络空间安全学院也改考了!南京理工大学计算机考研
负载均衡集群
yum和vim须掌握的常用操作
- 原文地址:https://blog.csdn.net/nice___amusin/article/details/125992684
