-
工作流编排引擎-Temporal
Concepts introduction
Modern problems
您是否曾经开发过需要响应多个异步事件、与不可靠的外部资源通信或跟踪非常复杂事物状态的应用程序?
如果是这样,您可能熟悉无状态服务、数据库、cron作业和排队系统的混合,这是构建此类应用程序的现代方法。
然而,这些类型的系统通常会带来一些问题。维护每个单独组件的运行状况可能非常困难。此外,通常需要在基础设施上进行大量投资,以可视化整个系统的运行状况、定义超时和协调重试。扩展和维护这些系统是一项具有挑战性且成本高昂的工作。
Modern solution
编程框架(Temporal SDK)+ 后端服务(Temporal Server)的分布式系统
- Temporal Server提供了一个持久的虚拟内存,它不链接到任何特定的进程。它在各种托管和软件相关故障中保留完整的应用程序状态(包括带有局部变量的函数堆栈)。
- Temporal SDK使能够使用编程语言的全部功能编写应用程序代码,Temporal Server处理应用程序的持久性、可用性和可伸缩性。
核心概念
- Workflow:作为应用程序入口点和基础的函数或对象方法。
- Activities:处理非确定性业务逻辑的函数或对象方法。
- Workers:在物理或虚拟机上运行的进程,执行工作流和活动代码。
- Signals:仅写入对可以更新变量值和工作流状态的工作流的调用。
- Quires:对可以检索函数返回值和工作流状态的工作流的只读调用。
- Task Queue:一种支持负载平衡的路由机制。
Temporal
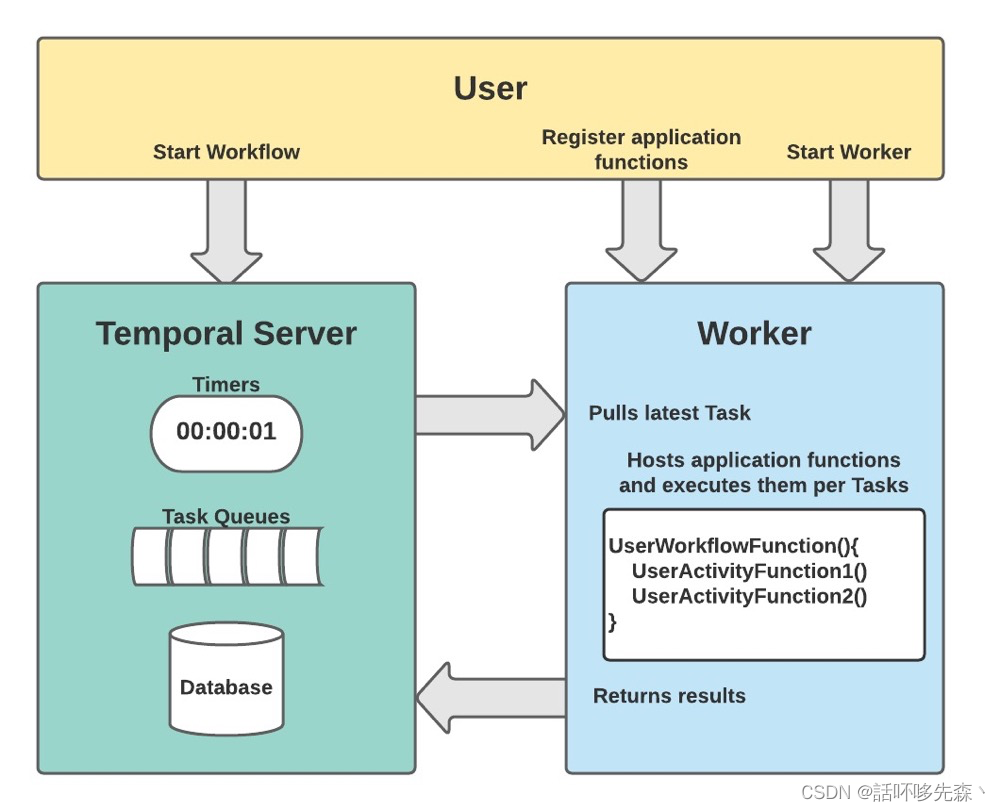
原理
在业务模块当中按规则编写Workflow流程以及其具体的Activity, 注册到worker当中, 启动worker 外部⽤户触发Workflow, Temporal编排workflow形成⼀系列的task送到队列中, worker去队列取 任务, 执⾏后将结果返回给Temporal
举一个银行的流程示例:
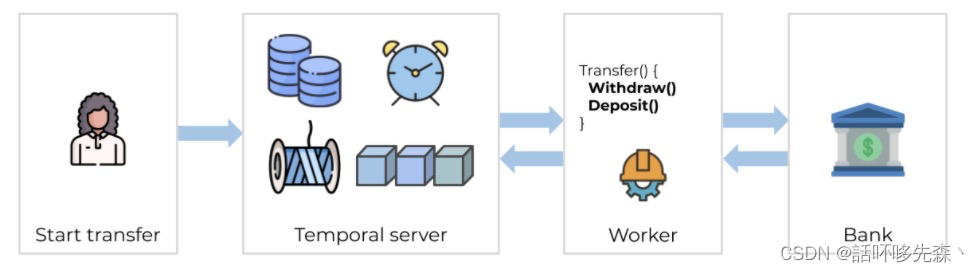
Workflow
1、工作流的参数
- 第一个参数workflow.Context是所有工作流函数的必须参数,Go SDK使用它来传递执行上下文
- 类似Go提供的标准context.Context。唯一的区别是workflow.Context提供的Done()函数返回workflow.Channel,而不是标准的Go chan
- 第二个参数是一个自定义参数,可用于在工作流启动时将数据传递到工作流中。新参数建议使用结构类型的单个参数来支持向后兼容性
- 参数不能是通道、函数、变量或不安全的指针
2、如何编写工作流
- 工作流代码必须是“确定性的”。这个需求源于临时服务器如何跟踪代码执行的状态,以及它需要能够重播执行
3、启动工作流
-
使用Go SDK客户端从Go流程启动工作流,如下所述。
从已运行的工作流(称为子工作流)启动工作流。
注:启动工作流与执行工作流不同。启动工作流意味着您正在通知服务器开始跟踪工作流执行的状态。在临时应用程序中,您不直接运行工作流代码,而是由工作人员托管和执行工作流代码。
-
支持同步或异步启动工作流
4、重试策略
启动工作流时不需要重试策略。如果未提供,则会为工作流生成默认值。但是,如果提供了,唯一需要的选项是初始间隔 Initial interval
详细见 Activity and Workflow Retries
5、查询工作流状态
we = client.GetWorkflow(workflowID)var result stringwe.Get(ctx, &result)Workflow Id
工作流由其命名空间、工作流ID和运行ID唯一标识。
- 仅允许重复失败策略#
- 描述:指定此项意味着仅当先前执行的具有相同Id的工作流失败时,才允许启动工作流。
- 用例:当需要重新执行失败的工作流并保证成功完成的工作流不会重新执行时,使用此策略。
- 允许重复策略#
- 描述:指定此项意味着允许工作流独立于具有相同Id的前一个工作流启动,而不管其完成状态如何。这是默认策略(如果未指定)。
- 用例:当可以再次使用相同的工作流Id执行工作流时,使用此选项。
- 拒绝重复策略#
- 描述:指定此项意味着不允许任何其他工作流开始使用相同的工作流Id。
- 用例:当命名空间保留期内每个工作流Id只能执行一次工作流时,使用此选项。
Child Workflows
子工作流执行是从另一个工作流中派生的工作流执行。
工作流执行既可以是父工作流执行,也可以是子工作流执行,因为任何工作流都可以生成另一个工作流。
- 父工作流执行必须等待子工作流执行才能生成。父工作流可以选择等待子工作流执行的结果。如果父进程不等待子对象的结果,则考虑该子对象的父关闭策略,该策略包括父进程的任何新的使用。
- 当父工作流执行达到关闭状态时,服务器会根据子工作流的父关闭策略将取消请求或终止传播到子工作流执行。
- 如果子工作流执行使用Continue As New,则从父工作流执行的角度来看,整个运行链将被视为单个执行。
使用子工作流
- 考虑工作流执行事件历史大小限制(建议从使用活动的单个工作流实现开始,直到明确需要子工作流为止)
- 子工作流执行有自己的事件历史记录
- 父工作流执行事件历史记录包含与子工作流执行状态相对应的事件
- 通常子工作流执行会导致事件历史记录中记录的总体事件多于活动。因为事件历史记录中的每个条目都是计算资源的“成本”,所以这可能成为非常大的工作负载的一个因素
- 将每个子工作流执行视为单独的服务
- 由于子工作流执行可以由一组与父工作流执行完全不同的工作人员来处理,因此它可以充当一个完全独立的服务。但是,这也意味着父工作流执行和子工作流执行不共享任何本地状态。与所有工作流执行一样,它们只能通过异步信号进行通信
- 考虑单个子工作流执行可以表示单个资源
- 与所有工作流执行一样,子工作流执行可以创建与资源的1:1映射。例如,管理主机升级的工作流可以为每个主机生成子工作流执行。
关闭父子策略
- ABANDON-放弃:当父工作流停止时,不要对子工作流执行执行任何操作
- TERMINATE-终止:当父工作流停止时,立即终止子工作流执行
- REQUEST_CANCEL-请求\取消:当父工作流停止时,对子工作流执行请求取消
可以为每个子级设置策略,这意味着您可以在每个子级的基础上选择不传播终止/取消
Activity
Lifecycle of an Activity
Step 1 - Workflow Worker
活动SimpleActivity首先在任务队列sampleTaskQueue上的工作流工作进程内调用,会将options参数发送到TemporalServer
ao := workflow.ActivityOptions{TaskQueue:"sampleTaskQueue",ScheduleToCloseTimeout: time.Second *500,// ScheduleToStartTimeout: time.Second * 60, //建议不选StartToCloseTimeout: time.Second *60,//必选HeartbeatTimeout: time.Second *10,WaitForCancellation:false,}ctx = workflow.WithActivityOptions(ctx, ao)var result stringerr := workflow.ExecuteActivity(ctx, SimpleActivity, value).Get(ctx, &result)iferr != nil {returnerr}Step 2 - Temporal Server
收到第一步的命令后,TemporalServer将活动任务添加到*Queue活动任务队列
Step 3 - Activity Worker
轮询Queue活动任务队列的活动任务并开始执行
Step 4 - Temporal Server
一旦活动执行成功完成,活动工作人员将向临时服务器发送CompleteActivityTask消息(以及活动执行的结果),临时服务器现在将控制权交还给工作流工作人员,以继续执行下一行代码并重复该过程
Timeouts
Start-To-Close Timeout:处理任务所需的最长时间
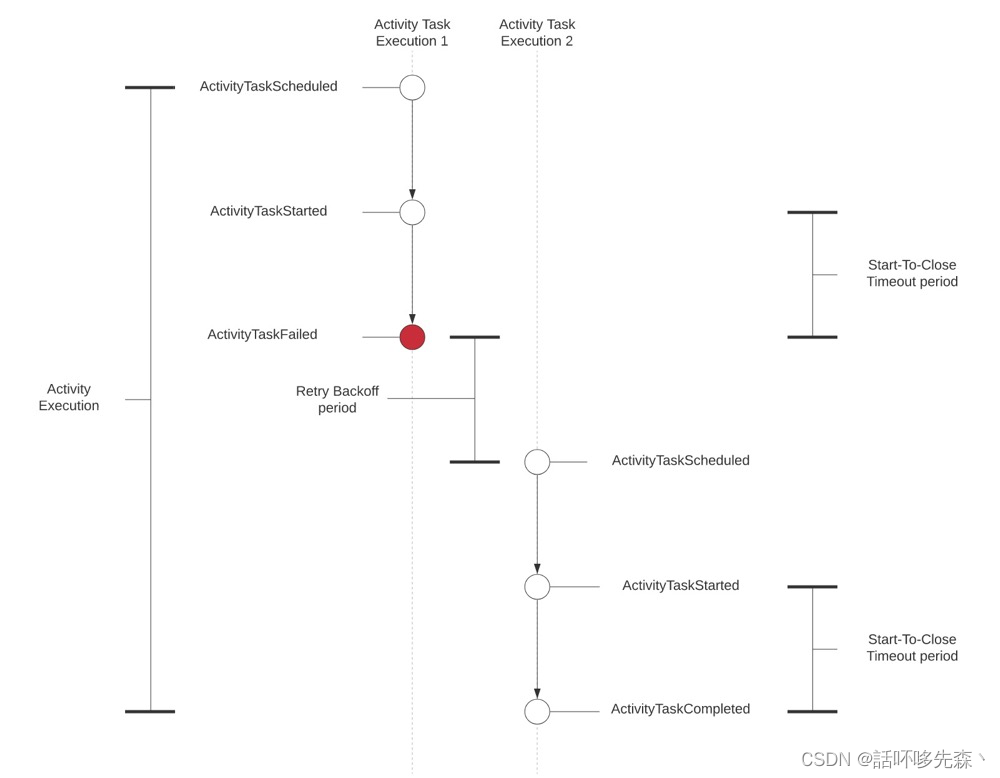
内容:从活动任务队列(启动状态)中提取了活动任务后何时会崩溃
影响:没有配置的话,Temporal将永远不会主动超时此活动执行以启动重试。活动执行变得“停滞”,最终用户将在没有反馈的情况下体验其工作流执行的无限期延迟。
配置后,Temporal在内部注册ActivityTaskTimedOut事件,该事件触发服务器根据活动执行的RetryPolicy尝试重试:
-
服务器再次将活动任务添加到活动任务队列中
-
服务器在工作流执行的可变状态下增加尝试次数
-
活动事件将可再次拾取活动任务
- 启动关闭计时器被重置,如果第二次尝试失败,它将再次启动
- 会应用到各个活动任务中
需要将其设置为比最大可能活动执行时间更长的时间。比如活动执行可能需要5分钟到5小时的时间,则需要将“开始关闭”设置为5小时以上
Schedule-To-Start Timeout:任务等待调度的时间,指定时间任务没被处理则超时
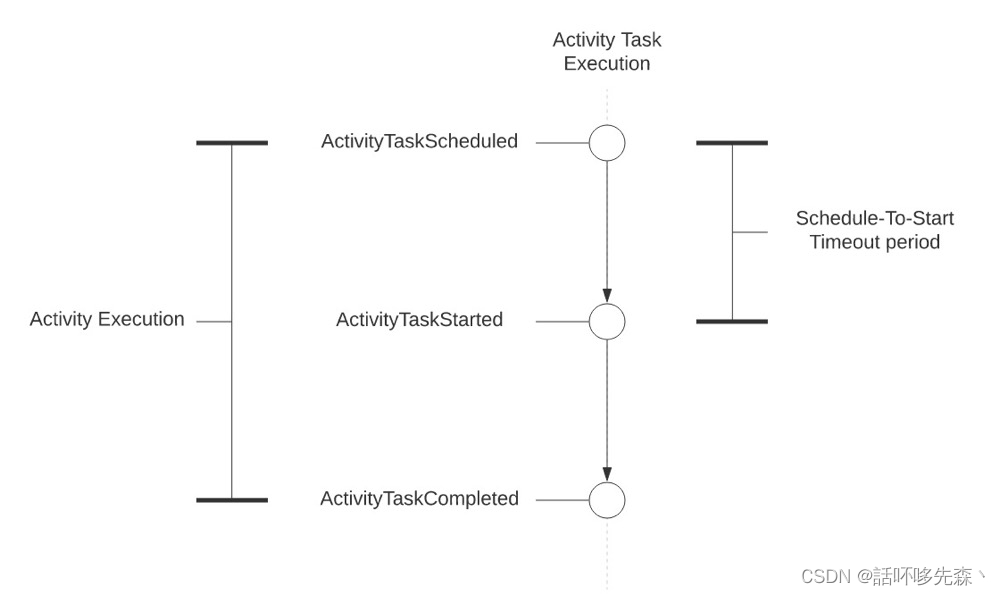
内容:显示的设置活动事件在任务队列中的时间(不建议),默认无穷大
影响:检查单个worker是否崩溃、轮询任务队列的工作组是否无法跟上活动任务的速率,还可以看到该队列中各部分的调度时间,从而报警,便于优化
注意:不会超时重试(重试会将活动任务放回同一任务队列)
如果给定的任务队列未按预期速率排空,则当您有将活动任务重新路由到其他任务队列的具体计划时,基于此超时执行其他补偿逻辑。
Schedule-To-Close Timeout:任务完成所需要的时间,通常大于StartClose和ScheduleToStart超时的总和

内容:用于控制活动执行所允许的总最大时间量,包括所有重试。(RetryPolicy.MaximumAttempts>1)
注意:虽然可以在RetryPolicy中控制重试间隔和最大重试次数,但关闭超时计划是基于所用总时间控制重试的最佳方法。我们建议使用Schedule-To-Close Timeout来限制重试次数,而不是调整最大尝试次数,因为在大多数情况下,这更符合所需的用户体验。
Heartbeat Timeout:心跳探活时间
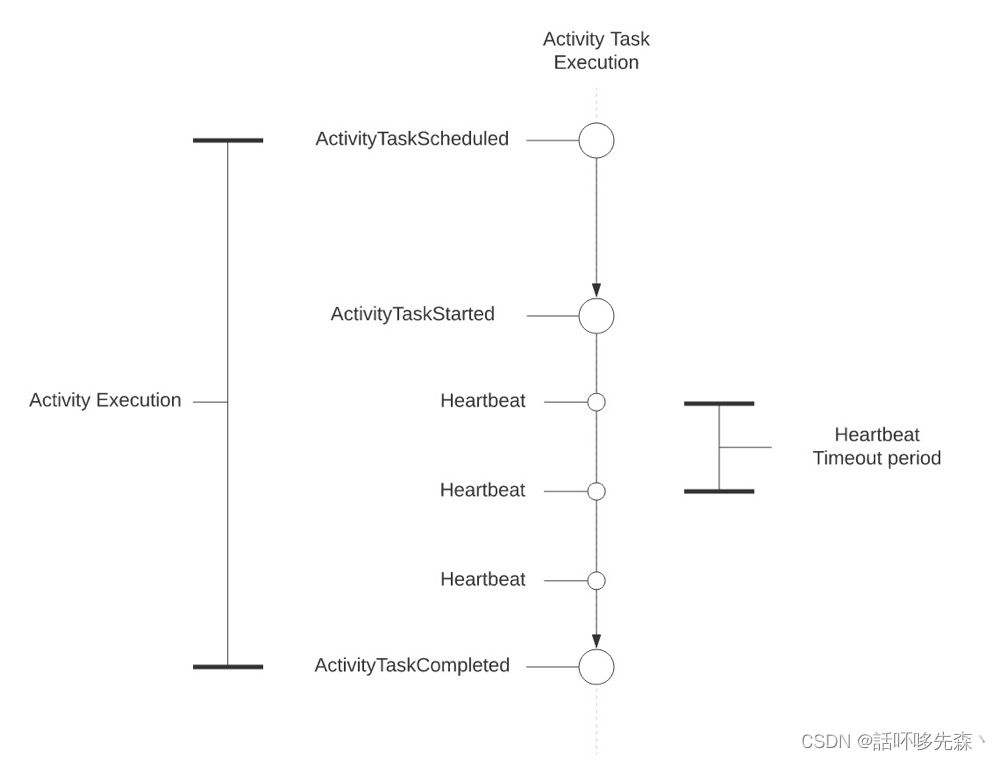
内容:用于检测两个活动任务间的最长时间,能够更快的重试活动
建议:对于长时间运行的活动,建议指定一个相对较短的心跳超时和持续的心跳
Worker
1、可执行工作流和/或活动代码。(可以独立托管其中一个)
2、worker轮询任务队列里的任务,以响应任务,然后将结果回传到临时服务器
3、只负责编排状态转换并将消息分派给下一个可用的工作进程
4、RegisterWorkflow和RegisterActivity调用实质上是在工作进程内创建完全限定函数名与其实现之间的内存映射。
ps:
- 如果Worker执行不知道的工作流或活动,则该任务将失败。但是,任务失败不会导致关联工作流失败。
- 通过调用ExecuteWorkflow启动工作流时,临时服务器将向工作流的任务队列添加一个新任务,任何轮询该任务队列的Worker都可以执行该任务。
TaskQueue
1、任何给定的工作者都知道下一步执行哪段代码。
2、它是任务的“先进先出”队列,其中任务是执行改变工作流“状态”的代码块所需的上下文。
3、任务队列由Temporal Server维护。服务器将任务放入任务队列中,以安排、启动、取消和完成工作流和/或活动的某些部分。
4、任务队列在代码中以名称表示为字符串。
5、不需要显式注册,而是根据需要创建的。任务队列非常轻量级,系统可以处理的任务队列总数没有限制。
6、使用任务队列将任务交付给工作者,而不是通过同步RPC调用操作,有多个优点。
- Worker不需要有任何开放的端口,这样更安全。
- Worker不需要通过DNS或任何其他网络发现机制宣传自己。
- 当所有Worker都停止工作时,消息只会保留在任务队列中,等待Worker恢复。
- Worker仅在消息具有空闲容量时轮询消息,以避免自身过载。
- 任务队列可以在大量Worker之间实现某种自动负载平衡。
- 任务队列支持服务器端节流,这使您能够将任务分派速率限制在工作池中,同时在出现峰值时仍支持以更高的速率分派任务。
- 任务队列支持我们称之为“任务路由”的功能,即将特定任务路由到特定工作人员甚至特定流程。
使用场景
- 启动工作流时,必须在StaskWorkFooStices选项中提供任务队列名称。
- 创建Worker时作为参数传入。
- 工作流调用活动时,可以在ActivityOptions中提供任务队列的名称。
- 调用子工作流时,可以在ChildWorkflowOptions中提供任务队列的名称。
- 如果在ChildWorkflowOptions中未提供任务队列名称,则子工作流任务将与父工作流任务队列放置在同一任务队列中。
Signals
1、信号是一种完全异步且持久的机制,用于将数据发送到正在运行的工作流中(而不是在启动工作流或轮询活动中的外部数据时将数据作为参数传递)。
2、工作流可以使用SignalExternalWorkflow向其他工作流发送信号。
ps:
- 通过工作流的信号,Temporal会将信号事件和有效负载保存在工作流历史记录中。然后,工作流可以在之后的任何时间处理该信号,而不会有丢失信息的风险。
- 工作流还可以通过阻塞信号通道来暂停,直到收到信号为止。
- 如果您不知道工作流当前是否正在运行,则可以使用SignalWithStart,并在需要时启动新的工作流运行以接收信号。
使用场景
- 不考虑当前工作流的运行状态
- 可以传送带结构体的信号
- 工作流可以使用SignalExternalWorkflow向其他工作流发送信号,包括跨命名空间边界发送信号。
Queries
1、查询堆栈
tctl --namespace samples-namespace workflow query -w my_workflow_id -r my_run_id -qt __stack_trace2、查询工作流当前状态
tctl --namespace samples-namespace workflow query -w my_workflow_id -r my_run_id -qt current_state3、一致性查询:最终一致性、强一致性
tctl --namespace samples-namespace workflow signal -w my_workflow_id -r my_run_id -n signal_name -if./input.json#强一致性tctl --namespace samples-namespace workflow query -w my_workflow_id -r my_run_id -qt current_state --qcl strongActivity and Workflow Retries
# 重试策略RetryPolicy struct {// Backoff interval for the first retry. If coefficient is 1.0 then it is used for all retries.// Required, no default value.InitialInterval time.Duration//初始间隔。第一次重试前必须经过的时间量。没有默认值,如果提供了重试策略,则必须提供默认值。// Coefficient used to calculate the next retry backoff interval.// The next retry interval is previous interval multiplied by this coefficient.// Must be 1 or larger. Default is 2.0.BackoffCoefficient float64//退避系数。重试次数可以是指数级的。退避系数指定重试间隔的增长速度。默认值设置为2.0。退避系数为1.0意味着重试间隔将始终等于初始间隔。通过使用退避系数,最初的几次重试相对较快地克服了间歇性故障,但随后的重试间隔会越来越远,从而导致持续时间更长的停机。// Maximum backoff interval between retries. Exponential backoff leads to interval increase.// This value is the cap of the interval. Default is 100x of initial interval.MaximumInterval time.Duration//最大间隔持续时间。指定重试之间的最大间隔。默认值为初始间隔的100倍。对于大于1.0的系数很有用,因为它可以防止间隔以指数形式无限增长。// Maximum number of attempts. When exceeded the retries stop even if not expired yet.// If not set or set to 0, it means unlimitedMaximumAttempts int32//最大尝试次数。指定出现故障时可尝试执行工作流的最大次数。如果超过此限制,工作流将失败,而不会重试。默认值是无限的。将其设置为0意味着不受限制。用来确保重试不会无限期地继续。// Non-Retriable errors. This is optional. Temporal server will stop retry if error type matches this list.// Note:// - cancellation is not a failure, so it won't be retried,// - only StartToClose or Heartbeat timeouts are retryable.NonRetryableErrorTypes []string//不可重试的错误,可选。指定不应重试的错误,以便在它们出现时,不会重试工作流。}Selectors
类似Go的select,允许goroutine等待多个通信。一个select块直到它的一个case可以运行,然后执行。如果多个已准备就绪,则随机选择一个。但是,由于随机性,正常的Go select语句不能直接在工作流内部使用。不同的是Temporal的Go SDK选择器可阻止channel的发送和接收,但可以监听未来推迟的工作。
func SampleWorkflow(ctx workflow.Context) error {// standard Workflow setup code omitted...// API Example: declare a new selectorselector := workflow.NewSelector(ctx)// API Example: defer code execution until the Future that represents Activity result is readywork := workflow.ExecuteActivity(ctx, ExampleActivity)selector.AddFuture(work, func(f workflow.Future) {// deferred code omitted...})// more parallel timers and activities initiated...// API Example: receive information from a Channelvar signalVal stringchannel := workflow.GetSignalChannel(ctx, channelName)selector.AddReceive(channel, func(c workflow.ReceiveChannel, more bool) {// matching on the channel doesn't consume the message.// So it has to be explicitly consumed herec.Receive(ctx, &signalVal)// do something with received information})// API Example: block until the next Future is ready to run// important! none of the deferred code runs until you call selector.Selectselector.Select(ctx)// Todo: document selector.HasPending}可多次调用Select,只会为每个Selector选择器实例匹配一次。如果有多个项目可用,则不定义匹配顺序
Using Selectors with Timers
在计时器和挂起的活动之间建立竞争
例如,计时器示例显示如何编写长时间运行的订单处理操作,其中:如果处理时间过长,我们会向用户发送一封关于延迟的通知电子邮件,但我们不会取消操作。如果操作在计时器触发之前完成,那么我们要取消计时器。
var processingDone boolf := workflow.ExecuteActivity(ctx, OrderProcessingActivity)selector.AddFuture(f, func(f workflow.Future) {processingDone =true// cancel timerFuturecancelHandler()})// use timer future to send notification email if processing takes too longtimerFuture := workflow.NewTimer(childCtx, processingTimeThreshold)//workflow.NewTimer 方法创建计时器selector.AddFuture(timerFuture, func(f workflow.Future) {if!processingDone {// processing is not done yet when timer fires, send notification email_ = workflow.ExecuteActivity(ctx, SendEmailActivity).Get(ctx, nil)}})// wait the timer or the order processing to finishselector.Select(ctx)Using Selectors with Channels
// API Example: receive information from a Channelvar signalVal stringchannel := workflow.GetSignalChannel(ctx, channelName)selector.AddReceive(channel, func(c workflow.ReceiveChannel, more bool) {c.Receive(ctx, &signalVal)// do something with received information})匹配消息不会消费,只有在c.Receive后才会消费message
Querying Selector State
可以使用selector.HasPending确保信号不会丢失用法参考:Go SDK Selectors | Temporal Documentation
SideEffect
- 适合一些简短的、不确定的函数,如生成uuid。
- 执行一次后将结果记录到工作流历史记录中,不会在重播时重新执行,而是返回记录的结果。
- 某些故障下可能会多次执行,不能确保只执行一次
- 失败后会触发Panic,导致任务执行失败
- 超时后,会重新执行
Distributed CRON
两种方式可启动定时工作流
- 使用CTL命令:–cron参数
- 使用CronSchedule启动定时工作流(推荐)
workflowOptions := client.StartWorkflowOptions{ID: workflowID,TaskQueue:"cron",CronSchedule:"* * * * *",}we, err := c.ExecuteWorkflow(context.Background(), workflowOptions, cron.SampleCronWorkflow)注意点:
- UTC时区,CronSchedule基于UTC时间
- 无重叠:临时服务器仅在当前执行完成后安排下一个工作流执行。如果下一次执行将在工作流当前正在执行(包括重试)时发生,则将跳过下一次执行
-
重试策略:如果工作流执行失败,并且向StartWorkflowOptions提供了RetryPolicy,则将根据RetryPolicy重试工作流执行。当工作流执行正在重试时,服务器将不会计划下一个工作流执行
-
取消工作流:终止或取消工作流执行也将停止Cron调度。Cron工作流在终止或取消之前不会停止
获取以前运行成功的进度
func CronWorkflow(ctx workflow.Context) (CronResult, error) {startTimestamp := time.Time{}// By default start from 0 time.ifworkflow.HasLastCompletionResult(ctx) {var progress CronResultiferr := workflow.GetLastCompletionResult(ctx, &progress); err == nil {startTimestamp = progress.LastSyncTimestamp}}endTimestamp := workflow.Now(ctx)// Process work between startTimestamp (exclusive), endTimestamp (inclusive).// Business logic implementation goes here.result := CronResult{LastSyncTimestamp: endTimestamp}returnresult, nil}ps:第一天成功了,第二天失败了,第三天还会获得第一天成功的结果
Tracing and Context Propagation
通过在客户端实例化期间在ClientOptions中提供opentracing.Tracer实现来配置跟踪
Temporal支持传播自定义的上下文(类似go的ctx)
Using Custom Searchable Attributes in Go
- 支持自定义属性搜索Web UI查询
- 可随着工作流的进展动态更新属性。UpsertSearchAttributes将属性合并到工作流中的现有地图
- 不支持删除查询属性字段
- 可指定查询某字段的属性
- 可在工作流中查询属性
参考资料
workflow
Workflows in Go | Temporal Documentation
超时
The 4 Types of Activity timeouts | Temporal Documentation
https://docs.temporal.io/docs/content/how-to-set-activityoptions-in-go/#scheduletostarttimeout
docker安装 Install Docker Engine on CentOS | Docker Documentation
What is tctl? | Temporal Documentation
docker-compose/README.md at main · temporalio/docker-compose · GitHub
-
相关阅读:
139 单词拆分 140 单词拆分II
kubernetes摘要
使用训练工具
Curve 文件存储随着存量数据增长
杂题——1097: 蛇行矩阵
解析Spring中的循环依赖问题:初探三级缓存
SpringBoot整合Junit
嵌入式面试:大疆 2023 春招
PXE解决uefi安装centos6黑屏问题
ICPC 2019-2020 North-Western Russia Regional Contest | JorbanS
- 原文地址:https://blog.csdn.net/spirit_8023/article/details/125999263