-
3W 字详解 Java 集合
数据结构作为每一个开发者不可回避的问题,而 Java 对于不同的数据结构提供了非常成熟的实现,这一个又一个实现既是面试中的难点,也是工作中必不可少的工具,在此,笔者经历漫长的剖析,将其抽丝剥茧的呈现出来,在此仅作抛砖引玉,望得诸君高见,若君能有所获则在下甚是不亦乐乎,若有疑惑亦愿与诸君共求之!
本文一共 3.5 W字,25 张图,预计阅读 2h。可以收藏这篇文章,用的时候防止找不到,这可能是你能看到的最详细的一篇文章了。
学习更多JAVA知识与技巧,关注博主学习JAVA 课件,源码,安装包,还有最新大厂面试资料等等等
1. 集合框架
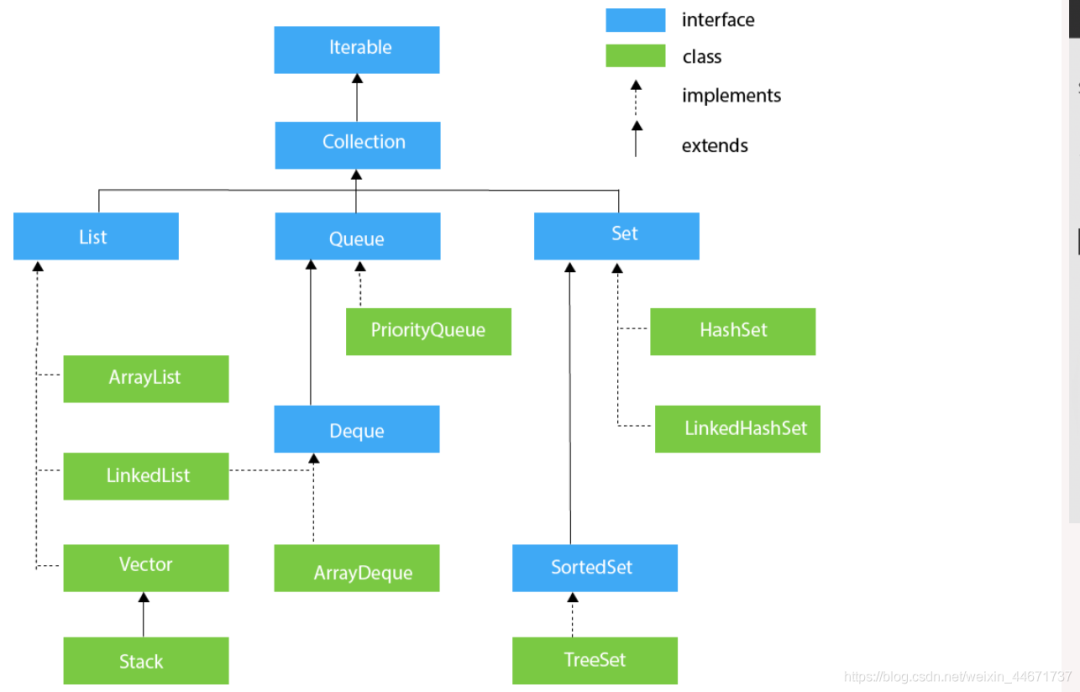
Java整个集合框架如上图所示(这儿不包括Map,Map的结构将放在集合后边进行讲述),可见所有集合实现类的最顶层接口为Iterable和Collection接口,再向下Collection分为了三种不同的形式,分别是List,Queue和Set接口,然后就是对应的不同的实现方式。
1.1 顶层接口Iterable
- //支持lambda函数接口
- import java.util.function.Consumer;
- public interface Iterable
{ - //iterator()方法
- Iterator
iterator(); - default void forEach(Consumersuper T> action) {
- Objects.requireNonNull(action);
- for (T t : this) {
- action.accept(t);
- }
- }
- default Spliterator
spliterator() { - return Spliterators.spliteratorUnknownSize(iterator(), 0);
- }
- }
Iterable接口中只有iterator()一个接口方法,Iterator也是一个接口,其主要有如下两个方法hasNext()和next()方法。
- package java.util;
- import java.util.function.Predicate;
- import java.util.stream.Stream;
- import java.util.stream.StreamSupport;
- public interface Collection
extends Iterable { - int size();
- boolean isEmpty();
- boolean contains(Object o);
- Iterator
iterator(); - Object[] toArray();
- boolean add(E e);
- boolean remove(Object o);
- boolean containsAll(Collection c);
- boolean removeAll(Collection c);
- default boolean removeIf(Predicatesuper E> filter) {
- Objects.requireNonNull(filter);
- boolean removed = false;
- final Iterator
each = iterator(); - while (each.hasNext()) {
- if (filter.test(each.next())) {
- each.remove();
- removed = true;
- }
- }
- return removed;
- }
- boolean retainAll(Collection c);
- void clear();
- int hashCode();
- @Override
- default Spliterator
spliterator() { - return Spliterators.spliterator(this, 0);
- }
- default Stream
stream() { - return StreamSupport.stream(spliterator(), false);
- }
- default Stream
parallelStream() { - return StreamSupport.stream(spliterator(), true);
- }
- }
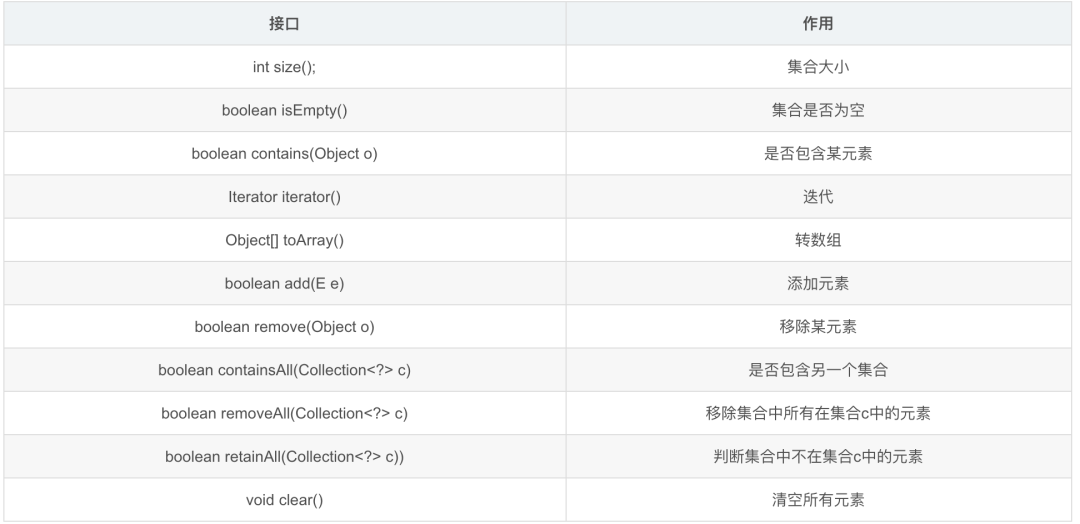
可见Collection的主要接口方法有:
2. List
List表示一串有序的集合,和Collection接口含义不同的是List突出有序的含义。
2.1 List接口
- package java.util;
- import java.util.function.UnaryOperator;
- public interface List
extends Collection { T[] toArray(T[] a); - boolean addAll(Collection c);
- boolean addAll(int index, Collection c);
- default void replaceAll(UnaryOperator
operator) { - Objects.requireNonNull(operator);
- final ListIterator
li = this.listIterator(); - while (li.hasNext()) {
- li.set(operator.apply(li.next()));
- }
- }
- default void sort(Comparatorsuper E> c) {
- Object[] a = this.toArray();
- Arrays.sort(a, (Comparator) c);
- ListIterator
i = this.listIterator(); - for (Object e : a) {
- i.next();
- i.set((E) e);
- }
- }
- boolean equals(Object o);
- E get(int index);
- E set(int index, E element);
- void add(int index, E element);
- int indexOf(Object o);
- int lastIndexOf(Object o);
- ListIterator
listIterator(); - List
subList(int fromIndex, int toIndex); - @Override
- default Spliterator
spliterator() { - return Spliterators.spliterator(this, Spliterator.ORDERED);
- }
- }
可见List其实比Collection多了添加方法add和addAll查找方法get,indexOf,set等方法,并且支持index下标操作。
Collection 与 List 的区别?
a. 从上边可以看出Collection和List最大的区别就是Collection是无序的,不支持索引操作,而List是有序的。Collection没有顺序的概念。
b. List中Iterator为ListIterator。
c. 由a推导List可以进行排序,所以List接口支持使用sort方法。
d. 二者的Spliterator操作方式不一样。
为什么子类接口里重复申明父类接口呢?
官方解释: 在子接口中重复声明父接口是为了方便看文档。比如在 java doc 文档里,在 List 接口里也能看到 Collecion 声明的相关接口。
2.2 List实现ArrayList
ArrayList是List接口最常用的一个实现类,支持List接口的一些列操作。
2.2.1 ArrayList继承关系
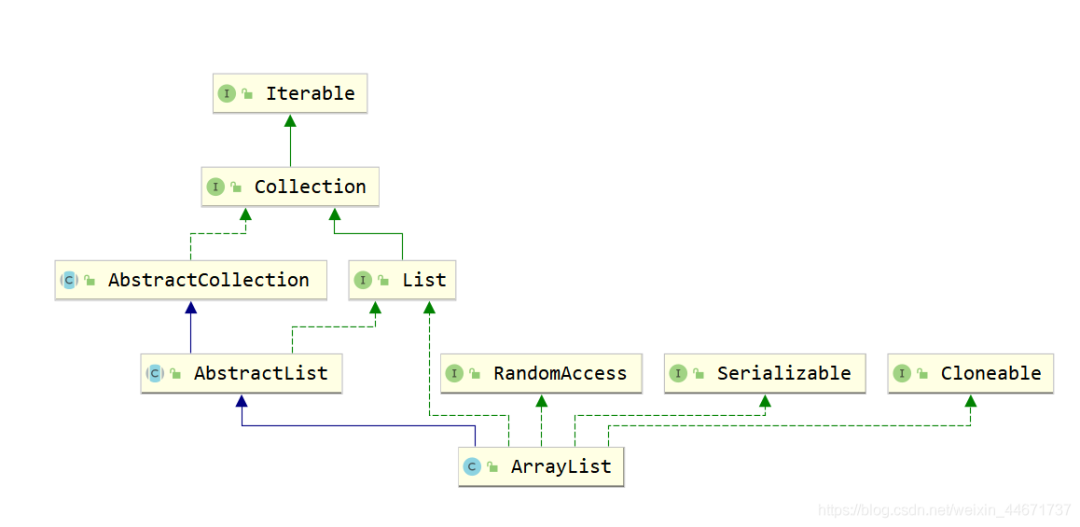
2.2.2 ArrayList组成
- private static final Object[] EMPTY_ELEMENTDATA = {};
- private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}
- //真正存放元素的数组
- transient Object[] elementData; // non-private to simplify nested class access
- private int size;
一定要记住ArrayList中的transient Object[] elementData,该elementData是真正存放元素的容器,可见ArrayList是基于数组实现的。
2.2.3 ArrayList构造函数
- public ArrayList(int initialCapacity) {
- if (initialCapacity > 0) {
- this.elementData = new Object[initialCapacity];
- } else if (initialCapacity == 0) {
- this.elementData = EMPTY_ELEMENTDATA;
- } else {
- throw new IllegalArgumentException("Illegal Capacity: "+
- initialCapacity);
- }
- }
- public ArrayList() {
- this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
- }
1. Object[] elementData 是ArrayList真正存放数据的数组。
2. ArrayList支持默认大小构造,和空构造,当空构造的时候存放数据的Object[] elementData是一个空数组{}。
2.2.4 ArrayList中添加元素
- public boolean add(E e) {
- ensureCapacityInternal(size + 1); // Increments modCount!!
- elementData[size++] = e;
- return true;
- }
注意ArrayList中有一个modCount的属性,表示该实例修改的次数。(所有集合中都有modCount这样一个记录修改次数的属性),每次增改添加都会增加一次该ArrayList修改次数,而上边的add(E e)方法是将新元素添加到list尾部。
2.2.4 ArrayList扩容
- private static int calculateCapacity(Object[] elementData, int minCapacity) {
- if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
- //DEFAULT_CAPACITY是10
- return Math.max(DEFAULT_CAPACITY, minCapacity);
- }
- return minCapacity;
- }
可见当初始化的list是一个空ArrayList的时候,会直接扩容到DEFAULT_CAPACITY,该值大小是一个默认值10。而当添加进ArrayList中的元素超过了数组能存放的最大值就会进行扩容。
注意到这一行代码
int newCapacity = oldCapacity + (oldCapacity >> 1);采用右移运算,就是原来的一般,所以是扩容1.5倍。
比如10的二进制是1010,右移后变成101就是5。
- private void grow(int minCapacity) {
- // overflow-conscious code
- int oldCapacity = elementData.length;
- int newCapacity = oldCapacity + (oldCapacity >> 1);
- if (newCapacity - minCapacity < 0)
- newCapacity = minCapacity;
- if (newCapacity - MAX_ARRAY_SIZE > 0)
- newCapacity = hugeCapacity(minCapacity);
- // minCapacity is usually close to size, so this is a win:
- elementData = Arrays.copyOf(elementData, newCapacity);
- }
2.2.5 数组copy
Java 是无法自己分配空间的,是底层C和C++的实现。以 C 为例,我们知道 C 中数组是一个指向首部的指针,比如我们 C 语言对数组进行分配内存。Java 就是通过 arraycopy 这个 native 方法实现的数组的复制。
- public static native void arraycopy(Object src, int srcPos,
- Object dest, int destPos,
- int length);
p = (int *)malloc(len*sizeof(int));这样的好处何在呢?
Java里内存是由jvm管理的,而数组是分配的连续内存,而arrayList不一定是连续内存,当然jvm会帮我们做这样的事,jvm会有内部的优化,会在后续的例子中结合问题来说明。
2.2.6 why?elementData用transient修饰?
1. transient的作用是该属性不参与序列化。
2. ArrayList继承了标示序列化的Serializable接口
3. 对arrayList序列化的过程中进行了读写安全控制。
是如何实现序列化安全的呢?
- private void writeObject(java.io.ObjectOutputStream s)
- throws java.io.IOException{
- // Write out element count, and any hidden stuff
- int expectedModCount = modCount;
- s.defaultWriteObject();
- // Write out size as capacity for behavioural compatibility with clone()
- s.writeInt(size);
- // Write out all elements in the proper order.
- for (int i=0; is.writeObject(elementData[i]);}if (modCount != expectedModCount) {throw new ConcurrentModificationException();}}/*** Reconstitute the ArrayList instance from a stream (that is,* deserialize it).*/private void readObject(java.io.ObjectInputStream s)throws java.io.IOException, ClassNotFoundException {elementData = EMPTY_ELEMENTDATA;// Read in size, and any hidden stuffs.defaultReadObject();// Read in capacitys.readInt(); // ignoredif (size > 0) {// be like clone(), allocate array based upon size not capacityint capacity = calculateCapacity(elementData, size);SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);ensureCapacityInternal(size);Object[] a = elementData;// Read in all elements in the proper order.for (int i=0; ia[i] = s.readObject();}}}
在序列化方法writeObject()方法中可以看到,先用默认写方法,然后将size写出,最后遍历写出elementData,因为该变量是transient修饰的,所有进行手动写出,这样它也会被序列化了。那是不是多此一举呢?
protected transient int modCount = 0;当然不是,其中有一个关键的modCount, 该变量是记录list修改的次数的,当写入完之后如果发现修改次数和开始序列化前不一致就会抛出异常,序列化失败。这样就保证了序列化过程中是未经修改的数据,保证了序列化安全。(java集合中都是这样实现)
2.3 LinkedList
众所周知LinkedList是一种链表结构,那么Java里LinkedList是如何实现的呢?
2.3.1 LinkedList继承关系
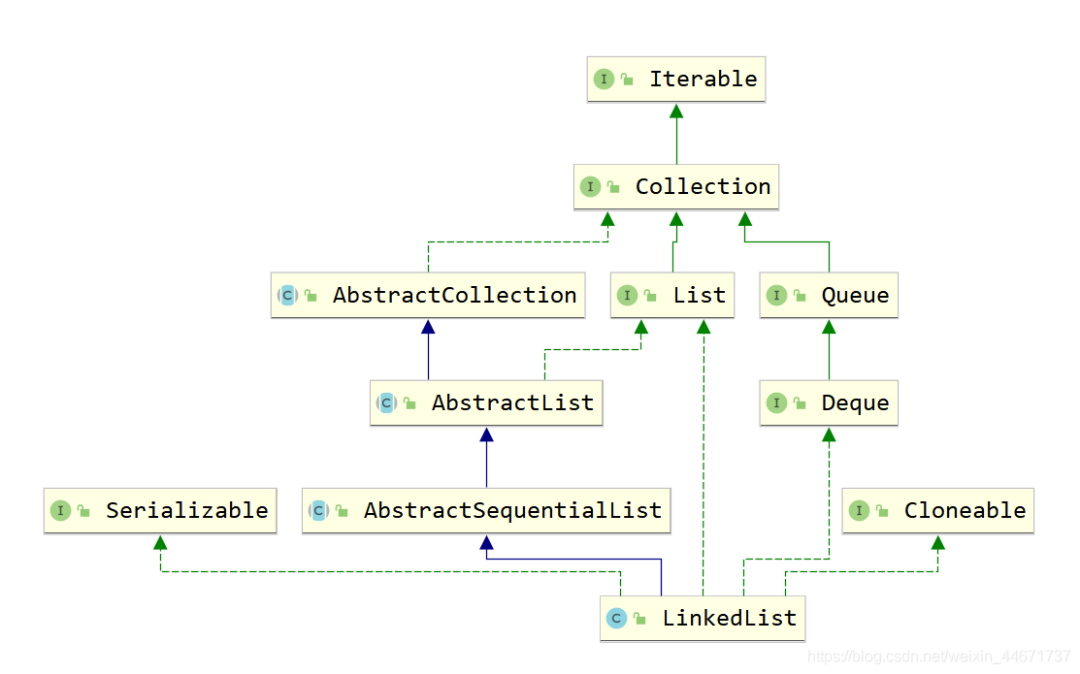
可见LinkedList既是List接口的实现也是Queue的实现(Deque),故其和ArrayList相比LinkedList支持的功能更多,其可视作队列来使用,当然下文中不强调其队列的实现。
2.3.2 LinkedList的结构
- transient Node
first; - /**
- * Pointer to last node.
- * Invariant: (first == null && last == null) ||
- * (last.next == null && last.item != null)
- */
- transient Node
last;
LinkedList由一个头节点和一个尾节点组成,分别指向链表的头部和尾部。
LinkedList中Node源码如下,由当前值item,和指向上一个节点prev和指向下个节点next的指针组成。并且只含有一个构造方法,按照(prev, item, next)这样的参数顺序构造。
- private static class Node<E> {
- E item;
- Node
next; - Node
prev; - Node(Node
prev, E element, Node next) { - this.item = element;
- this.next = next;
- this.prev = prev;
- }
- }
那LinkedList里节点Node是什么结构呢?
LinkedList由一个头节点,一个尾节点和一个默认为0的size构成,可见其是双向链表。
- transient int size = 0;
- transient Node
first; - transient Node
last; - public LinkedList() {
- }
数据结构中链表的头插法linkFirst和尾插法linkLast
- /**
- * Links e as first element. 头插法
- */
- private void linkFirst(E e) {
- final Node
f = first; - final Node
newNode = new Node<>(null, e, f); - first = newNode;
- if (f == null)
- last = newNode;
- else
- f.prev = newNode;
- size++;
- modCount++;
- }
- /**
- * Links e as last element. 尾插法
- */
- void linkLast(E e) {
- final Node
l = last; - final Node
newNode = new Node<>(l, e, null); - last = newNode;
- if (l == null)
- first = newNode;
- else
- l.next = newNode;
- size++;
- modCount++;
- }
2.3.3 LinkedList查询方法
按照下标获取某一个节点:get方法,获取第index个节点。
- public E get(int index) {
- checkElementIndex(index);
- return node(index).item;
- }
node(index)方法是怎么实现的呢?
判断index是更靠近头部还是尾部,靠近哪段从哪段遍历获取值。
- Node
node(int index) { - // assert isElementIndex(index);
- //判断index更靠近头部还是尾部
- if (index < (size >> 1)) {
- Node
x = first; - for (int i = 0; i < index; i++)
- x = x.next;
- return x;
- } else {
- Node
x = last; - for (int i = size - 1; i > index; i--)
- x = x.prev;
- return x;
- }
- }
查询索引修改方法,先找到对应节点,将新的值替换掉老的值。
- public E set(int index, E element) {
- checkElementIndex(index);
- Node
x = node(index); - E oldVal = x.item;
- x.item = element;
- return oldVal;
- }
这个也是为什么ArrayList随机访问比LinkedList快的原因,LinkedList要遍历找到该位置才能进行修改,而ArrayList是内部数组操作会更快。
2.4.3 LinkedList修改方法
新增一个节点,可以看到是采用尾插法将新节点放入尾部。
- public boolean add(E e) {
- linkLast(e);
- return true;
- }
2.5 Vector
和ArrayList一样,Vector也是List接口的一个实现类。其中List接口主要实现类有ArrayLIst,LinkedList,Vector,Stack,其中后两者用的特别少。
2.5.1 vector组成
和ArrayList基本一样。
- //存放元素的数组
- protected Object[] elementData;
- //有效元素数量,小于等于数组长度
- protected int elementCount;
- //容量增加量,和扩容相关
- protected int capacityIncrement;
2.5.2 vector线程安全性
vector是线程安全的,synchronized修饰的操作方法。
2.5.3 vector扩容
- private void grow(int minCapacity) {
- // overflow-conscious code
- int oldCapacity = elementData.length;
- //扩容大小
- int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
- capacityIncrement : oldCapacity);
- if (newCapacity - minCapacity < 0)
- newCapacity = minCapacity;
- if (newCapacity - MAX_ARRAY_SIZE > 0)
- newCapacity = hugeCapacity(minCapacity);
- elementData = Arrays.copyOf(elementData, newCapacity);
- }
看源码可知,扩容当构造没有capacityIncrement时,一次扩容数组变成原来两倍,否则每次增加capacityIncrement。
2.5.4 vector方法经典示例
移除某一元素
- public synchronized E remove(int index) {
- modCount++;
- if (index >= elementCount)
- throw new ArrayIndexOutOfBoundsException(index);
- E oldValue = elementData(index);
- int numMoved = elementCount - index - 1;
- if (numMoved > 0)
- //复制数组,假设数组移除了中间某元素,后边有效值前移1位
- System.arraycopy(elementData, index+1, elementData, index,
- numMoved);
- //引用null ,gc会处理
- elementData[--elementCount] = null; // Let gc do its work
- return oldValue;
- }
这儿主要有一个两行代码需要注意,笔者在代码中有注释。
数组移除某一元素并且移动后,一定要将原来末尾设为null,且有效长度减1。
总体上vector实现是比较简单粗暴的,也很少用到,随便看看即可。
2.6 Stack
Stack也是List接口的实现类之一,和Vector一样,因为性能原因,更主要在开发过程中很少用到栈这种数据结构,不过栈在计算机底层是一种非常重要的数据结构,下边将探讨下Java中Stack。
2.6.1 Stack的继承关系
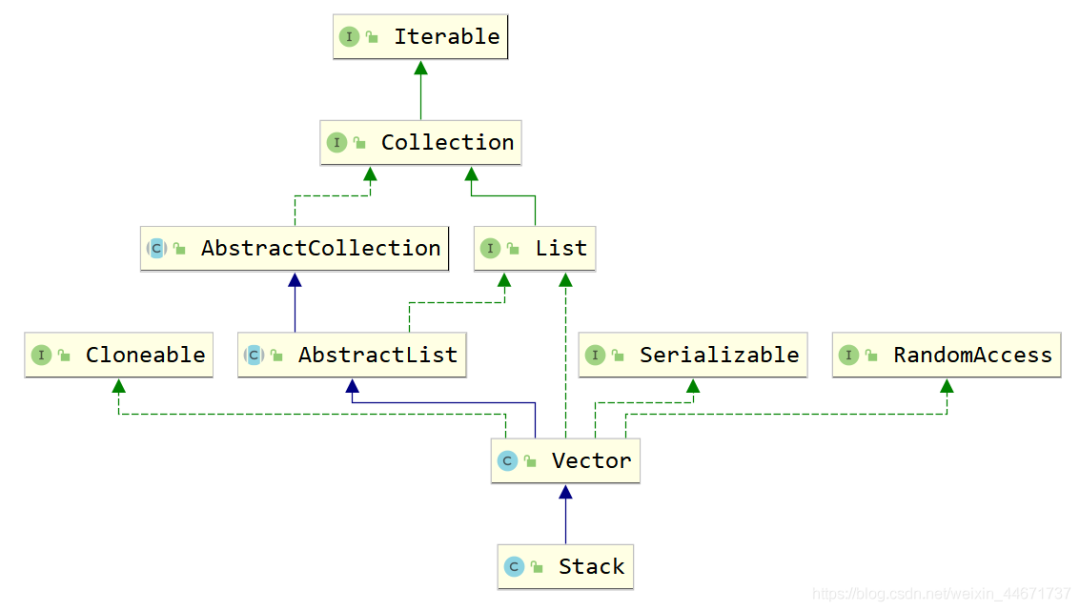
Stack继承于Vector,其也是List接口的实现类。之前提到过Vector是线程安全的,因为其方法都是synchronized修饰的,故此处Stack从父类Vector继承而来的操作也是线程安全的。
2.6.2 Stack的使用
正如Stack是栈的实现,故其主要操作为push入栈和pop出栈,而栈最大的特点就是LIFO(Last In First Out)。
- Stack<String> strings = new Stack<>();
- strings.push("aaa");
- strings.push("bbb");
- strings.push("ccc");
- System.err.println(strings.pop());

上边代码可以看到,最后push入栈的字符串"ccc"也最先出栈。
2.6.3 Stack源码
- /**
- * Stack源码(Jdk8)
- */
- public
- class Stack<E> extends Vector<E> {
- public Stack() {
- }
- //入栈,使用的是Vector的addElement方法。
- public E push(E item) {
- addElement(item);
- return item;
- }
- //出栈,找到数组最后一个元素,移除并返回。
- public synchronized E pop() {
- E obj;
- int len = size();
- obj = peek();
- removeElementAt(len - 1);
- return obj;
- }
- public synchronized E peek() {
- int len = size();
- if (len == 0)
- throw new EmptyStackException();
- return elementAt(len - 1);
- }
- public boolean empty() {
- return size() == 0;
- }
- public synchronized int search(Object o) {
- int i = lastIndexOf(o);
- if (i >= 0) {
- return size() - i;
- }
- return -1;
- }
- private static final long serialVersionUID = 1224463164541339165L;
- }
从Stack的源码中可见,其用的push方法用的是Vector的addElement(E e)方法,该方法是将元素放在集合的尾部,而其pop方法使用的是Vector的removeElementAt(Index x)方法,移除并获取集合的尾部元素,可见Stack的操作就是基于线性表的尾部进行操作的。
3. Queue
正如数据结构中描述,queue是一种先进先出的数据结构,也就是first in first out。可以将queue看作一个只可以从某一段放元素进去的一个容器,取元素只能从另一端取,整个机制如下图所示,不过需要注意的是,队列并没有规定是从哪一端插入,从哪一段取出。

3.1 什么是Deque
Deque英文全称是Double ended queue,也就是俗称的双端队列。就是说对于这个队列容器,既可以从头部插入也可以从尾部插入,既可以从头部获取,也可以从尾部获取,其机制如下图所示。

3.1.1 Java中的Queue接口
此处需要注意,Java中的队列明确有从尾部插入,头部取出,所以Java中queue的实现都是从头部取出。
- package java.util;
- public interface Queue<E> extends Collection<E> {
- //集合中插入元素
- boolean add(E e);
- //队列中插入元素
- boolean offer(E e);
- //移除元素,当集合为空,抛出异常
- E remove();
- //移除队列头部元素并返回,如果为空,返回null
- E poll();
- //查询集合第一个元素,如果为空,抛出异常
- E element();
- //查询队列中第一个元素,如果为空,返回null
- E peek();
- }

Java queue常常使用的方法如表格所示,对于表格中接口和表格中没有的接口方法区别为:队列的操作不会因为队列为空抛出异常,而集合的操作是队列为空抛出异常。
3.1.2 Deque接口
- package java.util;
- public interface Deque<E> extends Queue<E> {
- //deque的操作方法
- void addFirst(E e);
- void addLast(E e);
- boolean offerFirst(E e);
- boolean offerLast(E e);
- E removeFirst();
- E removeLast();
- E pollFirst();
- E pollLast();
- E getFirst();
- E getLast();
- E peekFirst();
- E peekLast();
- boolean removeFirstOccurrence(Object o);
- boolean removeLastOccurrence(Object o);
- // *** Queue methods ***
- boolean add(E e);
- boolean offer(E e);
- E remove();
- E poll();
- E element();
- E peek();
- // 省略一堆stack接口方法和collection接口方法
- }
和Queue中的方法一样,方法名多了First或者Last,First结尾的方法即从头部进行操作,Last即从尾部进行操作。
3.1.3 Queue,Deque的实现类
Java中关于Queue的实现主要用的是双端队列,毕竟操作更加方便自由,Queue的实现有PriorityQueue,Deque在java.util中主要有ArrayDeque和LinkedList两个实现类,两者一个是基于数组的实现,一个是基于链表的实现。在之前LinkedList文章中也提到过其是一个双向链表,在此基础之上实现了Deque接口。
3.2 PriorityQueue
PriorityQueue是Java中唯一一个Queue接口的直接实现,如其名字所示,优先队列,其内部支持按照一定的规则对内部元素进行排序。
3.2.1 PriorityQueue继承关系
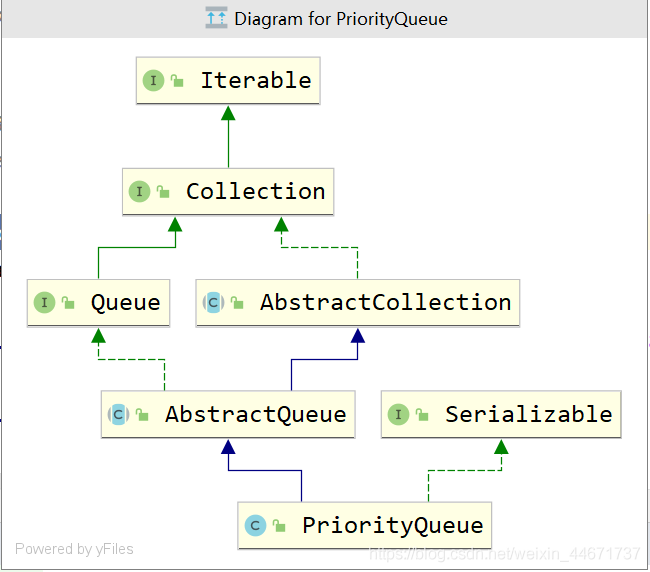
先看下PriorityQueue的继承实现关系,可知其是Queue的实现类,主要使用方式是队列的基本操作,而之前讲到过Queue的基本原理,其核心是FIFO(First In First Out)原理。
Java中的PriorityQueue的实现也是符合队列的方式,不过又略有不同,却别就在于PriorityQueue的priority上,其是一个支持优先级的队列,当使用了其priority的特性的时候,则并非FIFO。
3.2.2 PriorityQueue的使用
案列1:
- PriorityQueue
queue = new PriorityQueue<>(); - queue.add(20);queue.add(14);queue.add(21);queue.add(8);queue.add(9);
- queue.add(11);queue.add(13);queue.add(10);queue.add(12);queue.add(15);
- while (queue.size()>0){
- Integer poll = queue.poll();
- System.err.print(poll+"->");
- }

上述代码做的事为往队列中放入10个int值,然后使用Queue的poll()方法依次取出,最后结果为每次取出来都是队列中最小的值,说明
了PriorityQueue内部确实是有一定顺序规则的。
案例2:
- // 必须实现Comparable方法,想String,数值本身即可比较
- private static class Test implements Comparable<Test>{
- private int a;
- public Test(int a) {
- this.a = a;
- }
- public int getA() {
- return a;
- }
- public void setA(int a) {
- this.a = a;
- }
- @Override
- public String toString() {
- return "Test{" +
- "a=" + a +
- '}';
- }
- @Override
- public int compareTo(Test o) {
- return 0;
- }
- }
- public static void main(String[] args) {
- PriorityQueue
queue = new PriorityQueue<>(); - queue.add(new Test(20));queue.add(new Test(14));queue.add(new Test(21));queue.add(new Test(8));queue.add(new Test(9));
- queue.add(new Test(11));queue.add(new Test(13));queue.add(new Test(10));queue.add(new Test(12));queue.add(new Test(15));
- while (queue.size()>0){
- Test poll = queue.poll();
- System.err.print(poll+"->");
- }
- }

上述代码重写了compareTo方法都返回0,即不做优先级排序。发现我们返回的顺序为Test{a=20}->Test{a=15}->Test{a=12}->Test{a=10}->Test{a=13}->Test{a=11}->Test{a=9}->Test{a=8}->Test{a=21}->Test{a=14},和放入的顺序还是不同,所以这儿需要注意在实现Comparable接口的时候一定要按照一定的规则进行优先级排序,关于为什么取出来的顺序和放入的顺序不一致后边将从源码来分析。
3.2.3 PriorityQueue组成
- /**
- * 默认容量大小,数组大小
- */
- private static final int DEFAULT_INITIAL_CAPACITY = 11;
- /**
- * 存放元素的数组
- */
- transient Object[] queue; // non-private to simplify nested class access
- /**
- * 队列中存放了多少元素
- */
- private int size = 0;
- /**
- * 自定义的比较规则,有该规则时优先使用,否则使用元素实现的Comparable接口方法。
- */
- private final Comparator super E> comparator;
- /**
- * 队列修改次数,每次存取都算一次修改
- */
- transient int modCount = 0; // non-private to simplify nested class access
可以看到PriorityQueue的组成很简单,主要记住一个存放元素的数组,和一个Comparator比较器即可。
3.2.4 PriorityQueue操作方法
offer方法
- public boolean offer(E e) {
- if (e == null)
- throw new NullPointerException();
- modCount++;
- int i = size;
- if (i >= queue.length)
- grow(i + 1);
- size = i + 1;
- //i=size,当queue为空的时候
- if (i == 0)
- queue[0] = e;
- else
- siftUp(i, e);
- return true;
- }
首先可以看到当Queue中为空的时候,第一次放入的元素直接放在了数组的第一位,那么上边案例二中第一个放入的20就在数组的第一位。而当queue中不为空时,又使用siftUp(i, e)方法,传入的参数是队列中已有元素数量和即将要放入的新元素,现在就来看下究竟siftUp(i, e)做了什么事。
- private void siftUp(int k, E x) {
- if (comparator != null)
- siftUpUsingComparator(k, x);
- else
- siftUpComparable(k, x);
- }
还记得上边提到PriorityQueue的组成,是一个存放元素的数组,和一个Comparator比较器。这儿是指当没有Comparator是使用元素类实现compareTo方法进行比较。其含义为优先使用自定义的比较规则Comparator,否则使用元素所在类实现的Comparable接口方法。
- private void siftUpComparable(int k, E x) {
- Comparable key = (Comparable) x;
- while (k > 0) {
- //为什么-1, 思考数组位置0,1,2。0是1和2的父节点
- int parent = (k - 1) >>> 1;
- //父节点
- Object e = queue[parent];
- //当传入的新节点大于父节点则不做处理,否则二者交换
- if (key.compareTo((E) e) >= 0)
- break;
- queue[k] = e;
- k = parent;
- }
- queue[k] = key;
- }
可以看到,当PriorityQueue不为空时插入一个新元素,会对其新元素进行堆排序处理(对于堆排序此处不做描述),这样每次进来都会对该元素进行堆排序运算,这样也就保证了Queue中第一个元素永远是最小的(默认规则排序)。
pool方法
- public E poll() {
- if (size == 0)
- return null;
- int s = --size;
- modCount++;
- E result = (E) queue[0];
- //s = --size,即原来数组的最后一个元素
- E x = (E) queue[s];
- queue[s] = null;
- if (s != 0)
- siftDown(0, x);
- return result;
- }
此处可知,当取出一个值进行了siftDown操作,传入的参数为索引0和队列中的最后一个元素。
- private void siftDownComparable(int k, E x) {
- Comparable key = (Comparable)x;
- int half = size >>> 1; // loop while a non-leaf
- while (k < half) {
- int child = (k << 1) + 1; // assume left child is least
- Object c = queue[child];
- int right = child + 1;
- if (right < size &&
- //c和right是parent的两个子节点,找出小的那个成为新的c。
- ((Comparable) c).compareTo((E) queue[right]) > 0)
- c = queue[child = right];
- if (key.compareTo((E) c) <= 0)
- break;
- //小的变成了新的父节点
- queue[k] = c;
- k = child;
- }
- queue[k] = key;
- }
当没有Comparator比较器是采用的siftDown方法如上,因为索引0位置取出了,找索引0的子节点比它小的作为新的父节点并在循环内递归。PriorityQueue是不是很简单呢,其他细节就不再详解,待诸君深入。
3.3 ArrayDeque
ArrayDeque是Java中基于数组实现的双端队列,在Java中Deque的实现有LinkedList和ArrayDeque,正如它两的名字就标志了它们的不同,LinkedList是基于双向链表实现的,而ArrayDeque是基于数组实现的。
3.3.1 ArrayDeque的继承关系
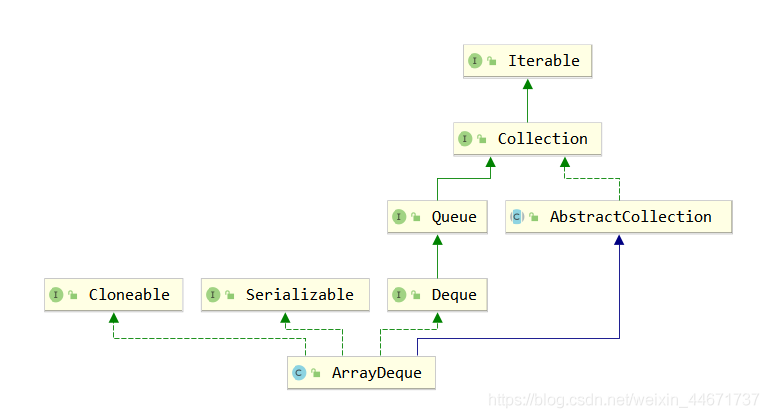
可见ArrayDeque是Deque接口的实现,和LinkedList不同的是,LinkedList既是List接口也是Deque接口的实现。
3.3.2 ArrayDeque使用
案列
- ArrayDeque
deque = new ArrayDeque<>(); - deque.offer("aaa");
- deque.offer("bbb");
- deque.offer("ccc");
- deque.offer("ddd");
- //peek方法只获取不移除
- System.err.println(deque.peekFirst());
- System.err.println(deque.peekLast());

案例二:
- ArrayDeque
deque = new ArrayDeque<>(); - deque.offerFirst("aaa");
- deque.offerLast("bbb");
- deque.offerFirst("ccc");
- deque.offerLast("ddd");
- String a;
- while((a = deque.pollLast())!=null){
- System.err.print(a+"->");
- }

上述程序最后得到队列中排列结果为ccc,aaa,bbb,ddd所以循环使用pollLast(),结果ddd,bbb,aaa,ccc,图示案列二的插入逻辑如下:
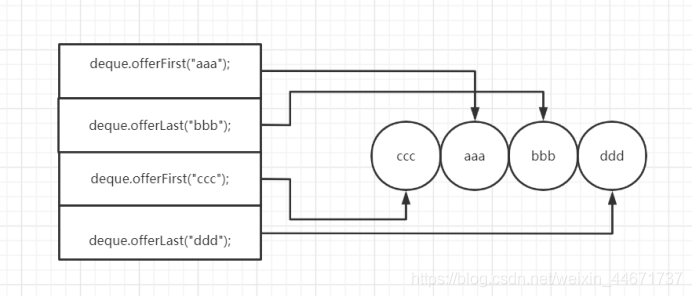
3.3.4 ArrayDeque内部组成
- //具体存放元素的数组,数组大小一定是2的幂次方
- transient Object[] elements; // non-private to
- //队列头索引
- transient int head;
- //队列尾索引
- transient int tail;
- //默认的最小初始化容量,即传入的容量小于8容量为8,而默认容量是16
- private static final int MIN_INITIAL_CAPACITY = 8;
3.3.5 数组elements长度
此处elements数组的长度永远是2的幂次方,此处的实现方法和hashMap中基本一样,即保证长度的二进制全部由1组成,然后再加1,则变成了100…,故一定是2的幂次方。
- private static int calculateSize(int numElements) {
- int initialCapacity = MIN_INITIAL_CAPACITY;
- // Find the best power of two to hold elements.
- // Tests "<=" because arrays aren't kept full.
- if (numElements >= initialCapacity) {
- initialCapacity = numElements;
- initialCapacity |= (initialCapacity >>> 1);
- initialCapacity |= (initialCapacity >>> 2);
- initialCapacity |= (initialCapacity >>> 4);
- initialCapacity |= (initialCapacity >>> 8);
- initialCapacity |= (initialCapacity >>> 16);
- initialCapacity++;
- if (initialCapacity < 0) // Too many elements, must back off
- initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
- }
- return initialCapacity;
- }
3.3.6 ArrayDeque实现机制
如下图所示:
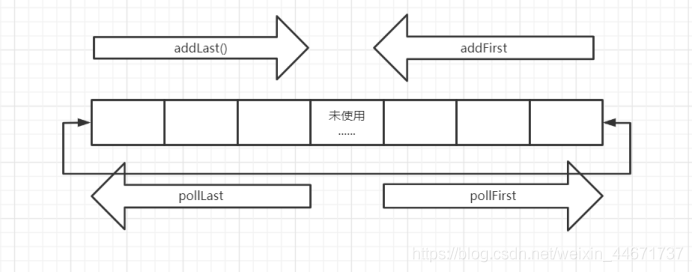
此处应将数组视作首尾相连的,最初头部和尾部索引都是0,addLast方向往右,addFirst方向往左,所以数组中间可能是空的,当头指针和尾指针相遇的时候对数组进行扩容,并对元素位置进行调整。
源码:- public void addFirst(E e) {
- if (e == null)
- throw new NullPointerException();
- elements[head = (head - 1) & (elements.length - 1)] = e;
- if (head == tail)
- doubleCapacity();
- }
注意下边这行代码,表示当head-1大于等于0时,head=head-1,否则head=elements.length - 1。
head = (head - 1) & (elements.length - 1)换一种写法就是下边这样,是不是就是上边addFirst的指针移动方向?
head = head-1>=0?head-1:elements.length-1这个就是位运算的神奇操作了,因为任何数与大于它的一个全是二进制1做&运算时等于它自身,如1010&1111 = 1010,此处不赘述。
再看addLast方法:
- public void addLast(E e) {
- if (e == null)
- throw new NullPointerException();
- elements[tail] = e;
- if ( (tail = (tail + 1) & (elements.length - 1)) == head)
- doubleCapacity();
- }
同样的注意有一串神奇代码。
(tail = (tail + 1) & (elements.length - 1))该表达式等于
tail = tail+1>element-1?0:tail+1,是不是很神奇的写法,其原理是一个二进制数全部由1组成和一个大于它的数做&运算结果为0,如10000&1111 = 0。poll方法和add方法逻辑是相反的,此处就不再赘述,诸君共求之!4. Set
如果说List对集合加了有序性的化,那么Set就是对集合加上了唯一性。
4.1 Set接口
java中的Set接口和Colletion是完全一样的定义。
- package java.util;
- public interface Set<E> extends Collection<E> {
- // Query Operations
- int size();
- boolean isEmpty();
- Object[] toArray();
T[] toArray(T[] a); - // Modification Operations
- boolean add(E e);
- boolean remove(Object o);
- boolean containsAll(Collection c);
- boolean addAll(Collection c);
- boolean retainAll(Collection c);
- boolean removeAll(Collection c);
- void clear();
- boolean equals(Object o);
- int hashCode();
- //此处和Collection接口由区别
- Spliterator
spliterator() { - return Spliterators.spliterator(this, Spliterator.DISTINCT);
- }
- }
4.2 HashSet
Java中的HashSet如其名字所示,其是一种Hash实现的集合,使用的底层结构是HashMap。
4.2.1 HashSet继承关系

4.2.3 HashSet源码
- public class HashSet
- extends AbstractSet
- implements Set
, Cloneable, java.io.Serializable - {
- static final long serialVersionUID = -5024744406713321676L;
- private transient HashMap
- private static final Object PRESENT = new Object();
- public HashSet() {
- map = new HashMap<>();
- }
- public HashSet(Collection c) {
- map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
- addAll(c);
- }
- public HashSet(int initialCapacity, float loadFactor) {
- map = new HashMap<>(initialCapacity, loadFactor);
- }
- public HashSet(int initialCapacity) {
- map = new HashMap<>(initialCapacity);
- }
- HashSet(int initialCapacity, float loadFactor, boolean dummy) {
- map = new LinkedHashMap<>(initialCapacity, loadFactor);
- }
- public Iterator
iterator() { - return map.keySet().iterator();
- }
- public int size() {
- return map.size();
- }
- public boolean isEmpty() {
- return map.isEmpty();
- }
- public boolean contains(Object o) {
- return map.containsKey(o);
- }
- public boolean add(E e) {
- return map.put(e, PRESENT)==null;
- }
- public boolean remove(Object o) {
- return map.remove(o)==PRESENT;
- }
- public void clear() {
- map.clear();
- }
- }
可以看到HashSet内部其实是一个HashMap。
4.2.4 HashSet是如何保证不重复的呢?
可见HashSet的add方法,插入的值会作为HashMap的key,所以是HashMap保证了不重复。map的put方法新增一个原来不存在的值会返回null,如果原来存在的话会返回原来存在的值。
关于HashMap是如何实现的,见后续!
4.3 LinkedHashSet
LinkedHashSet用的也比较少,其也是基于Set的实现。
4.3.1 LinkedHashSet继承关系
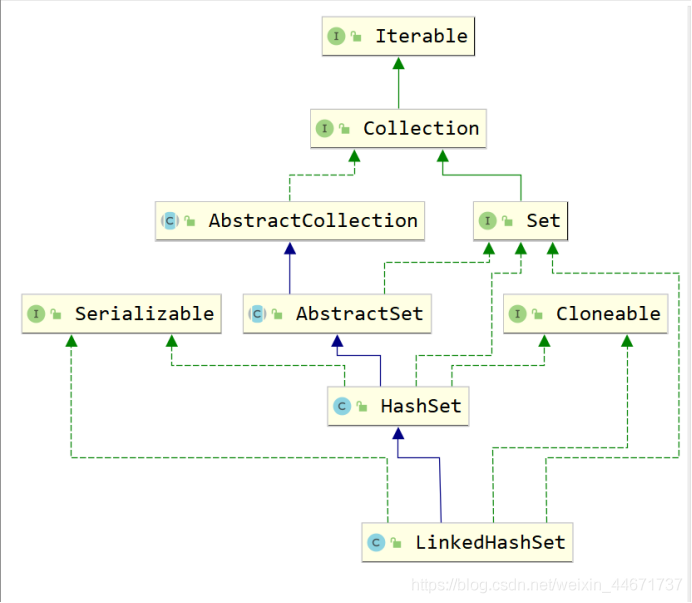
和HashSet一样,其也是Set接口的实现类,并且是HashSet的子类。
4.3.2 LinkedHashSet源码
- package java.util;
- public class LinkedHashSet
- extends HashSet
- implements Set
, Cloneable, java.io.Serializable { - private static final long serialVersionUID = -2851667679971038690L;
- public LinkedHashSet(int initialCapacity, float loadFactor) {
- //调用HashSet的构造方法
- super(initialCapacity, loadFactor, true);
- }
- public LinkedHashSet(int initialCapacity) {
- super(initialCapacity, .75f, true);
- }
- public LinkedHashSet() {
- super(16, .75f, true);
- }
- public LinkedHashSet(Collection c) {
- super(Math.max(2*c.size(), 11), .75f, true);
- addAll(c);
- }
- @Override
- public Spliterator
spliterator() { - return Spliterators.spliterator(this, Spliterator.DISTINCT |
- Spliterator.ORDERED);
- }
- }
其操作方法和HashSet完全一样,那么二者区别是什么呢?
1.首先LinkedHashSet是HashSet的子类。
2.LinkedHashSet中用于存储值的实现LinkedHashMap,而HashSet使用的是HashMap。LinkedHashSet中调用的父类构造器,可以看到其实列是一个LinkedHashMap。- HashSet(int initialCapacity, float loadFactor, boolean dummy) {
- map = new LinkedHashMap<>(initialCapacity, loadFactor);
- }
LinkedHashSet的实现很简单,更深入的了解需要去看LinkedHashMap的实现,对LinkedHashMap的解析将单独提出。
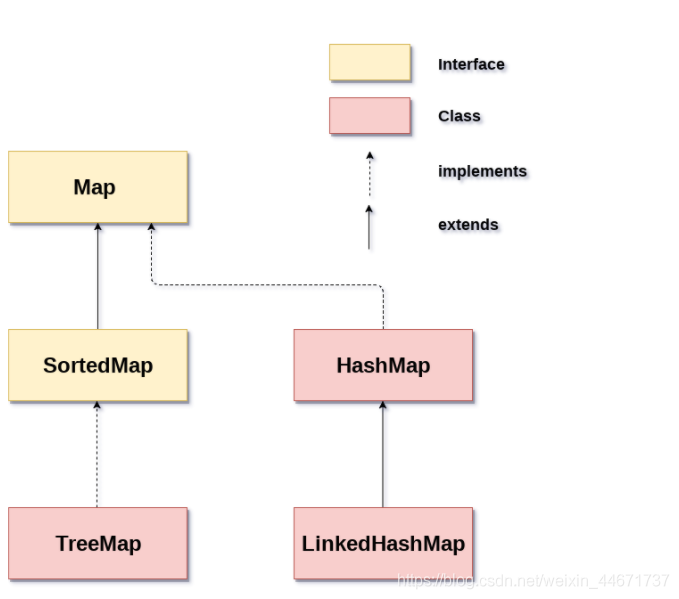
5. Map
Map是一种键值对的结构,就是常说的Key-Value结构,一个Map就是很多这样K-V键值对组成的,一个K-V结构我们将其称作Entry,在Java里,Map是用的非常多的一种数据结构。上图展示了Map家族最基础的一个结构(只是指java.util中)。
5.1 Map接口
- package java.util;
- import java.util.function.BiConsumer;
- import java.util.function.BiFunction;
- import java.util.function.Function;
- import java.io.Serializable;
- public interface Map
- // Query Operations
- int size();
- boolean isEmpty();
- boolean containsKey(Object key);
- boolean containsValue(Object value);
- V get(Object key);
- // Modification Operations
- V put(K key, V value);
- V remove(Object key);
- // Bulk Operations
- void putAll(Mapextends K, ? extends V> m);
- void clear();
- Set
keySet(); - Collection
values(); - Set<Map.Entry
- interface Entry
- K getKey();
- V getValue();
- V setValue(V value);
- boolean equals(Object o);
- int hashCode();
- public static
- return (Comparator<Map.Entry
- (c1, c2) -> c1.getKey().compareTo(c2.getKey());
- }
- public static
- return (Comparator<Map.Entry
- (c1, c2) -> c1.getValue().compareTo(c2.getValue());
- }
- public static
- Objects.requireNonNull(cmp);
- return (Comparator<Map.Entry
- (c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
- }
- public static
- Objects.requireNonNull(cmp);
- return (Comparator<Map.Entry
- (c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
- }
- }
- // Comparison and hashing
- boolean equals(Object o);
- int hashCode();
- default V getOrDefault(Object key, V defaultValue) {
- V v;
- return (((v = get(key)) != null) || containsKey(key))
- ? v
- : defaultValue;
- }
- default void forEach(BiConsumersuper K, ? super V> action) {
- Objects.requireNonNull(action);
- for (Map.Entry
- K k;
- V v;
- try {
- k = entry.getKey();
- v = entry.getValue();
- } catch(IllegalStateException ise) {
- // this usually means the entry is no longer in the map.
- throw new ConcurrentModificationException(ise);
- }
- action.accept(k, v);
- }
- }
- default void replaceAll(BiFunctionsuper K, ? super V, ? extends V> function) {
- Objects.requireNonNull(function);
- for (Map.Entry
- K k;
- V v;
- try {
- k = entry.getKey();
- v = entry.getValue();
- } catch(IllegalStateException ise) {
- // this usually means the entry is no longer in the map.
- throw new ConcurrentModificationException(ise);
- }
- // ise thrown from function is not a cme.
- v = function.apply(k, v);
- try {
- entry.setValue(v);
- } catch(IllegalStateException ise) {
- // this usually means the entry is no longer in the map.
- throw new ConcurrentModificationException(ise);
- }
- }
- }
- default V putIfAbsent(K key, V value) {
- V v = get(key);
- if (v == null) {
- v = put(key, value);
- }
- return v;
- }
- default boolean remove(Object key, Object value) {
- Object curValue = get(key);
- if (!Objects.equals(curValue, value) ||
- (curValue == null && !containsKey(key))) {
- return false;
- }
- remove(key);
- return true;
- }
- default boolean replace(K key, V oldValue, V newValue) {
- Object curValue = get(key);
- if (!Objects.equals(curValue, oldValue) ||
- (curValue == null && !containsKey(key))) {
- return false;
- }
- put(key, newValue);
- return true;
- }
- default V replace(K key, V value) {
- V curValue;
- if (((curValue = get(key)) != null) || containsKey(key)) {
- curValue = put(key, value);
- }
- return curValue;
- }
- default V computeIfAbsent(K key,
- Functionsuper K, ? extends V> mappingFunction) {
- Objects.requireNonNull(mappingFunction);
- V v;
- if ((v = get(key)) == null) {
- V newValue;
- if ((newValue = mappingFunction.apply(key)) != null) {
- put(key, newValue);
- return newValue;
- }
- }
- return v;
- }
- default V computeIfPresent(K key,
- BiFunctionsuper K, ? super V, ? extends V> remappingFunction) {
- Objects.requireNonNull(remappingFunction);
- V oldValue;
- if ((oldValue = get(key)) != null) {
- V newValue = remappingFunction.apply(key, oldValue);
- if (newValue != null) {
- put(key, newValue);
- return newValue;
- } else {
- remove(key);
- return null;
- }
- } else {
- return null;
- }
- }
- default V compute(K key,
- BiFunctionsuper K, ? super V, ? extends V> remappingFunction) {
- Objects.requireNonNull(remappingFunction);
- V oldValue = get(key);
- V newValue = remappingFunction.apply(key, oldValue);
- if (newValue == null) {
- // delete mapping
- if (oldValue != null || containsKey(key)) {
- // something to remove
- remove(key);
- return null;
- } else {
- // nothing to do. Leave things as they were.
- return null;
- }
- } else {
- // add or replace old mapping
- put(key, newValue);
- return newValue;
- }
- }
- default V merge(K key, V value,
- BiFunctionsuper V, ? super V, ? extends V> remappingFunction) {
- Objects.requireNonNull(remappingFunction);
- Objects.requireNonNull(value);
- V oldValue = get(key);
- V newValue = (oldValue == null) ? value :
- remappingFunction.apply(oldValue, value);
- if(newValue == null) {
- remove(key);
- } else {
- put(key, newValue);
- }
- return newValue;
- }
- }
Map接口本身就是一个顶层接口,由一堆Map自身接口方法和一个Entry接口组成,Entry接口定义了主要是关于Key-Value自身的一些操作,Map接口定义的是一些属性和关于属性查找修改的一些接口方法。
5.2 HashMap
HashMap是Java中最常用K-V容器,采用了哈希的方式进行实现,HashMap中存储的是一个又一个Key-Value的键值对,我们将其称作Entry,HashMap对Entry进行了扩展(称作Node),使其成为链表或者树的结构使其存储在HashMap的容器里(是一个数组)。
5.2.1 HashMap继承关系
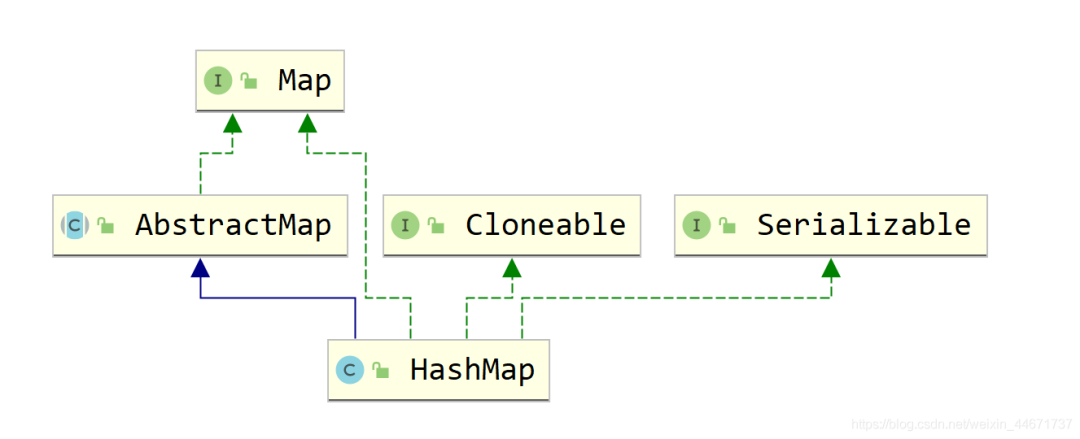
5.2.2 HashMap存储的数据
Map接口中有一个Entry接口,在HashMap中对其进行了实现,Entry的实现是HashMap存放的数据的类型。其中Entry在HashMap的实现是Node,Node是一个单链表的结构,TreeNode是其子类,是一个红黑树的类型,其继承结构图如下:
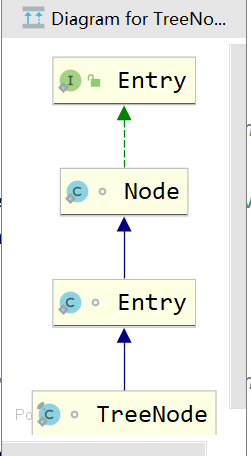
HashMap存放数据的数据是什么呢?代码中存放数据的容器如下:
transient Node说明了该容器中是一个又一个node组成,而node有三种实现,所以hashMap中存放的node的形式既可以是Node也可以是TreeNode。

5.2.3 HashMap的组成
有了上边的概念之后来看一下HashMap里有哪些组成吧!
- //是hashMap的最小容量16,容量就是数组的大小也就是变量,transient Node
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- //最大数量,该数组最大值为2^31一次方。
- static final int MAXIMUM_CAPACITY = 1 << 30;
- //默认的加载因子,如果构造的时候不传则为0.75
- static final float DEFAULT_LOAD_FACTOR = 0.75f;
- //一个位置里存放的节点转化成树的阈值,也就是8,比如数组里有一个node,这个
- // node链表的长度达到该值才会转化为红黑树。
- static final int TREEIFY_THRESHOLD = 8;
- //当一个反树化的阈值,当这个node长度减少到该值就会从树转化成链表
- static final int UNTREEIFY_THRESHOLD = 6;
- //满足节点变成树的另一个条件,就是存放node的数组长度要达到64
- static final int MIN_TREEIFY_CAPACITY = 64;
- //具体存放数据的数组
- transient Node
- //entrySet,一个存放k-v缓冲区
- transient Set
- //size是指hashMap中存放了多少个键值对
- transient int size;
- //对map的修改次数
- transient int modCount;
- //加载因子
- final float loadFactor;
这儿要说两个概念,table是指的存放数据的数组,bin是指的table中某一个位置的node,一个node可以理解成一批/一盒数据。
5.2.4 HashMap中的构造函数
- //只有容量,initialCapacity
- public HashMap(int initialCapacity) {
- this(initialCapacity, DEFAULT_LOAD_FACTOR);
- }
- public HashMap() {
- this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
- }
- public HashMap(Map m) {
- this.loadFactor = DEFAULT_LOAD_FACTOR;
- putMapEntries(m, false);
- }
- final void putMapEntries(Map m, boolean evict) {
- int s = m.size();
- if (s > 0) {
- if (table == null) { // pre-size
- float ft = ((float)s / loadFactor) + 1.0F;
- int t = ((ft < (float)MAXIMUM_CAPACITY) ?
- (int)ft : MAXIMUM_CAPACITY);
- if (t > threshold)
- threshold = tableSizeFor(t);
- }
- else if (s > threshold)
- resize();
- for (Map.Entryextends K, ? extends V> e : m.entrySet()) {
- K key = e.getKey();
- V value = e.getValue();
- putVal(hash(key), key, value, false, evict);
- }
- }
- }
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0) // 容量不能为负数
- throw new IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- //当容量大于2^31就取最大值1<<31;
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- this.loadFactor = loadFactor;
- //当前数组table的大小,一定是是2的幂次方
- // tableSizeFor保证了数组一定是是2的幂次方,是大于initialCapacity最结进的值。
- this.threshold = tableSizeFor(initialCapacity);
- }
tableSizeFor()方法保证了数组大小一定是是2的幂次方,是如何实现的呢?
- static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- }
该方法将一个二进制数第一位1后边的数字全部变成1,然后再加1,这样这个二进制数就一定是100…这样的形式。此处实现在ArrayDeque的实现中也用到了类似的方法来保证数组长度一定是2的幂次方。
5.2.5 put方法
开发人员使用的put方法:
- public V put(K key, V value) {
- return putVal(hash(key), key, value, false, true);
- }
真正HashMap内部使用的put值的方法:
- final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
- boolean evict) {
- Node
- if ((tab = table) == null || (n = tab.length) == 0)
- n = (tab = resize()).length;
- //当hash到的位置,该位置为null的时候,存放一个新node放入
- // 这儿p赋值成了table该位置的node值
- if ((p = tab[i = (n - 1) & hash]) == null)
- tab[i] = newNode(hash, key, value, null);
- else {
- Node
- //该位置第一个就是查找到的值,将p赋给e
- if (p.hash == hash &&
- ((k = p.key) == key || (key != null && key.equals(k))))
- e = p;
- //如果是红黑树,调用红黑树的putTreeVal方法
- else if (p instanceof TreeNode)
- e = ((TreeNode
- else {
- //是链表,遍历,注意e = p.next这个一直将下一节点赋值给e,直到尾部,注意开头是++binCount
- for (int binCount = 0; ; ++binCount) {
- if ((e = p.next) == null) {
- p.next = newNode(hash, key, value, null);
- //当链表长度大于等于7,插入第8位,树化
- if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
- treeifyBin(tab, hash);
- break;
- }
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- break;
- p = e;
- }
- }
- if (e != null) { // existing mapping for key
- V oldValue = e.value;
- if (!onlyIfAbsent || oldValue == null)
- e.value = value;
- afterNodeAccess(e);
- return oldValue;
- }
- }
- ++modCount;
- if (++size > threshold)
- resize();
- afterNodeInsertion(evict);
- return null;
- }
5.2.6 查找方法
- final Node
- Node
- //先判断表不为空
- if ((tab = table) != null && (n = tab.length) > 0 &&
- //这一行是找到要查询的Key在table中的位置,table是存放HashMap中每一个Node的数组。
- (first = tab[(n - 1) & hash]) != null) {
- //Node可能是一个链表或者树,先判断根节点是否是要查询的key,就是根节点,方便后续遍历Node写法并且
- //对于只有根节点的Node直接判断
- if (first.hash == hash && // always check first node
- ((k = first.key) == key || (key != null && key.equals(k))))
- return first;
- //有子节点
- if ((e = first.next) != null) {
- //红黑树查找
- if (first instanceof TreeNode)
- return ((TreeNode
- do {
- //链表查找
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- return e;
- }
- //遍历链表,当链表后续为null则推出循环
- while ((e = e.next) != null);
- }
- }
- return null;
- }
5.3 HashTable
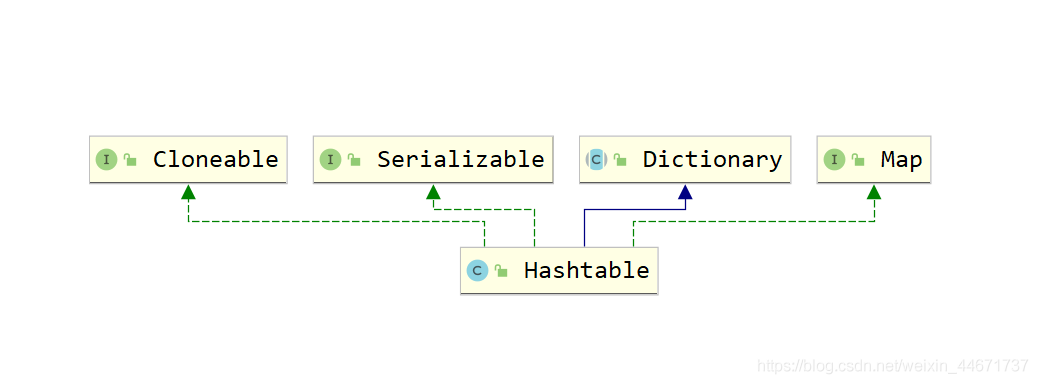
和HashMap不同,HashTable的实现方式完全不同,这点从二者的类继承关系就可以看出端倪来,HashTable和HashMap虽然都实现了Map接口,但是HashTable继承了DIctionary抽象类,而HashMap继承了AbstractMap抽象类。
5.3.1 HashTable的类继承关系图
HashTable
HashMap
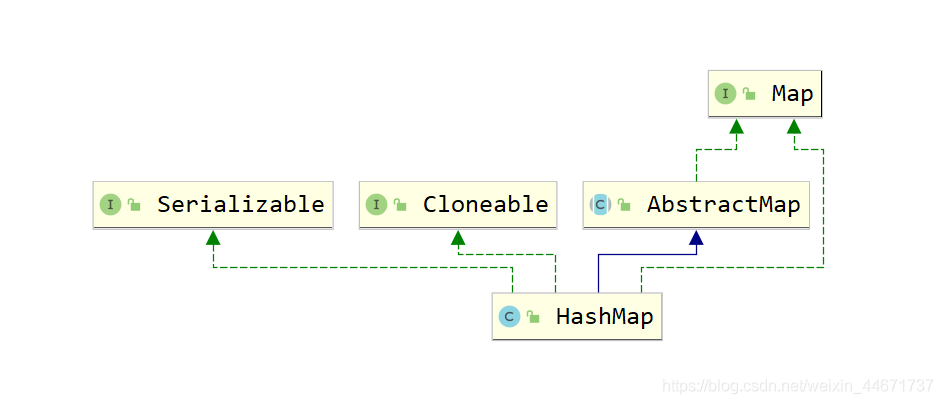
5.3.2 Dictionary接口
- public abstract
- class Dictionary<K,V> {
- public Dictionary() {
- }
- public abstract int size();
- public abstract boolean isEmpty();
- public abstract Enumeration
keys() ; - public abstract Enumeration
elements() ; - public abstract V get(Object key);
- public abstract V put(K key, V value);
- public abstract V remove(Object key);
- }
Dictionary类中有这样一行注释,当key为null时会抛出空指针NullPointerException,这也说明了HashTabel是不允许Key为null的。
//throws NullPointerException if the {@code key} is {@code null}.5.3.3 HashTable组成
- /**
- * The hash table data.
- * 真正存放数据的数组
- */
- private transient Entry,?>[] table;
- /**
- * The total number of entries in the hash table.
- */
- private transient int count;
- /**
- * The table is rehashed when its size exceeds this threshold. (The
- * value of this field is (int)(capacity * loadFactor).)
- * 重新hash的阈值
- * @serial
- */
- private int threshold;
- /**
- * The load factor for the hashtable.
- * @serial
- */
- private float loadFactor;
HashTable中的元素存在Entry[] table中,是一个Entry数组,Entry是存放的节点,每一个Entry是一个链表。
5.3.4 HashTable中的Entry
- final int hash;
- final K key;
- V value;
- Entry
知道Entry是一个单链表即可,和HashMap中的Node结构相同,但是HashMap中还有Node的子类TreeNode。
5.3.5 put方法
- public synchronized V put(K key, V value) {
- // Make sure the value is not null
- if (value == null) {
- throw new NullPointerException();
- }
- // Makes sure the key is not already in the hashtable.
- Entry tab[] = table;
- int hash = key.hashCode();
- //在数组中的位置 0x7fffffff 是31位二进制1
- int index = (hash & 0x7FFFFFFF) % tab.length;
- @SuppressWarnings("unchecked")
- Entry
- for(; entry != null ; entry = entry.next) {
- //如果遍历链表找到了则替换旧值并返回
- if ((entry.hash == hash) && entry.key.equals(key)) {
- V old = entry.value;
- entry.value = value;
- return old;
- }
- }
- addEntry(hash, key, value, index);
- return null;
- }
本质上就是先hash求索引,遍历该索引Entry链表,如果找到hash值和key都和put的key一样的时候就替换旧值,否则使用addEntry方法添加新值进入table,因为添加新元素就涉及到修改元素大小,还可能需要扩容等,具体看下边的addEntry方法可知。
- private void addEntry(int hash, K key, V value, int index) {
- Entry,?> tab[] = table;
- //如果扩容需要重新计算hash,所以index和table都会被修改
- if (count >= threshold) {
- // Rehash the table if the threshold is exceeded
- rehash();
- tab = table;
- hash = key.hashCode();
- index = (hash & 0x7FFFFFFF) % tab.length;
- }
- // Creates the new entry.
- @SuppressWarnings("unchecked")
- Entry
- //插入新元素
- tab[index] = new Entry<>(hash, key, value, e);
- count++;
- modCount++;
- }
tab[index] = new Entry<>(hash, key, value, e);这行代码是真正插入新元素的方法,采用头插法,单链表一般都用头插法(快)。
5.3.6 get方法
- @SuppressWarnings("unchecked")
- public synchronized V get(Object key) {
- Entry,?> tab[] = table;
- int hash = key.hashCode();
- int index = (hash & 0x7FFFFFFF) % tab.length;
- for (Entry,?> e = tab[index] ; e != null ; e = e.next) {
- if ((e.hash == hash) && e.key.equals(key)) {
- return (V)e.value;
- }
- }
- return null;
- }
get方法就简单很多就是hash,找到索引,遍历链表找到对应的value,没有则返回null。相比诸君都已经看到,HashTable中方法是用synchronized修饰的,所以其操作是线程安全的,但是效率会受影响。
如果本文对你有帮助,别忘记给我个3连 ,点赞,转发,评论,
学习更多JAVA知识与技巧,关注博主学习JAVA 课件,源码,安装包,还有最新大厂面试资料等等等
咱们下期见。
收藏 等于白嫖,点赞才是真情。

-
相关阅读:
java线程池详解
[HDLBits] Count15
Mysql8.x版本主从加读写分离(一) mysql8.x读写分离
在 Nuxt.js 和 Vue.js 项目中引入第三方字体或艺术字
Maven小问题集-No.1
【无标题】
如何解决跨境传输常见的安全及效率问题?
SpringBoot+Vue项目投稿和稿件处理系统
linux升级glibc-2.28
springboot基础篇(快速入门 + 完整项目案例)
- 原文地址:https://blog.csdn.net/uuqaz/article/details/126002596
