-
考研 | 数据结构【第八章】排序
考研 | 数据结构【第八章】排序
I. 基本概念
- 评价指标
- 时间复杂度
- 空间复杂度
- 稳定性: 关键字相同的元素经过排序后相对顺序会不会发生改变
- 分类
- 内部排序
- 外部排序
II. 插入排序
a. 直接插入排序

- 算法思想:: 将序列分类两部分, 绿色部分为已排序序列, 蓝色部分为未排序序列. 初始时将第一个数字变绿, 然后从第二个数字开始, 依次将数字插到前面的绿色部分, 并且保持绿色部分有序, 直至全部插入完成.
- 代码实现::
#- 1
- 效率分析::
- 时间复杂度:
最好情况 O ( n ) O(n) O(n), 原本就顺序了, 共走 n − 1 n-1 n−1 趟, 每趟只需对比 1 次关键字, 不用移动元素
最坏情况 O ( n 2 ) O(n^2) O(n2), 原本是逆序的情况
平均情况 O ( n 2 ) O(n^2) O(n2) - 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 稳定
- 时间复杂度:
b. 折半插入排序

- 算法思路: 由于直接插入每次需要将当前关键字插入到前面绿色部分且保持有序, 所以可以利用 折半查找法先找到应该插入的位置, 再移动元素.
- 代码实现:
#- 1
- 效率分析:
- 时间复杂度: 仍然是 O ( n 2 ) O(n^2) O(n2), 比较关键字的次数减少了, 但是移动元素次数没变
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 稳定
- Notes:
- 折半查找法仅适用于顺序表
- 注意: 一直到 Iow>high 时才停止折半查找. 当mid所指元素等于当前元素时, 应继续令low=mid+1, 以保证“稳定性”。最终应将当前元素插入到Iow所指位置(即high+1)
c. 对链表插入排序

- 效率分析:
- 时间复杂度: 仍然是 O ( n 2 ) O(n^2) O(n2), 移动元素次数减少, 但是关键字对比次数仍然是 O ( n 2 ) O(n^2) O(n2) 的数量级
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 稳定
d. 希尔排序

-
算法思想:
先将待排序列表分割成几个 “等步长” 的几个列表, 然后对每个 “等步长” 的列表进行 “直接插入排序”; 完成后重新合并回一个列表.
然后缩小 “步长” , 然后将列表再次分割成几个 “等步长” 的列表, 重复上述步骤
直至 步长为1 为止 -
代码实现:

-
效率分析:
- 时间复杂度: 未知, 优于直接插入排序
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 不稳定
-
Notes:

III. 交换排序
a. 冒泡排序

- 算法思想: 从后往前或者从前往后, 相邻元素两两对比, 如果逆序, 则交换他们, 直至排好顺序为止
- 代码实现:
#- 1
- 效率分析:
- 时间复杂度:
最好情况: O ( n ) O(n) O(n), 即本来有序
最坏情况: O ( n 2 ) O(n^2) O(n2)
平均情况: O ( n 2 ) O(n^2) O(n2) - 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 稳定
- 时间复杂度:
b. 快速排序

-
算法思想: (通常)先取首元素作为 “枢轴”, 然后在后面的序列中用 “low” 和 “high” 两个指针向中间扫描, 将小于 “枢轴” 的元素放到左边, 大于 "枢轴"的元素放到右边, 这样最终就确定了 “首元素” 的 “最终” 位置. 确定了最终位置后, 同样的, 对 “枢轴” 两边的序列重复上述步骤.
-
代码实现:
#- 1
-
效率分析:

- 时间复杂度:
最好情况: O ( n log 2 n ) O(n\log_2n) O(nlog2n), 每一次选中的 “枢轴” 都能将待排序列比较 “均匀地” 分成两部分, 递归树的深度最小, 算法效率最高
最坏情况: O ( n 2 ) O(n^2) O(n2), 初始序列本来就有序或者逆序, 性能最差, 因为每次选的 “枢轴” 都是最靠边的元素
平均情况: O ( n log 2 n ) O(n\log_2n) O(nlog2n) - 空间复杂度:
O
(
递归深度
)
O(递归深度)
O(递归深度)
最好情况: O ( log 2 n ) O(\log_2n) O(log2n)
最坏情况: O ( n ) O(n) O(n) - 稳定性: 不稳定
- 时间复杂度:
IV. 选择排序
a. 简单选择排序

- 算法思路: 每一趟都从 “右边” 待排序序列中挑出一个最小的元素, 与待排序序列的第一个元素进行交换, 形成 “已排序” 序列末尾.
- 代码实现:
#- 1
- 效率分析:
- 时间复杂度: O ( n 2 ) O(n^2) O(n2), 无论有序无序, 都要走 n − 1 n-1 n−1 趟, 总共需要对比次数 1 + ⋯ + ( n − 1 ) = n ( n − 1 ) 2 1+\cdots+(n-1)=\frac{n(n-1)}{2} 1+⋯+(n−1)=2n(n−1)
- 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 不稳定
- Notes: 既适用于顺序表. 也适用于链表
b. 堆排序
1. 什么是大根堆和小根堆
大根堆和小根堆都是一棵 “完全二叉树”, 其中:
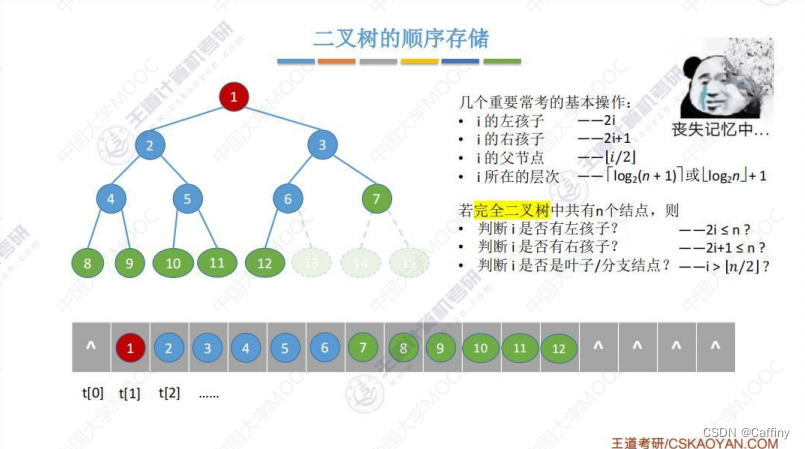
- 大根堆:
若满足 L ( i ) ≥ L ( 2 i ) 且 L ( i ) ≥ L ( 2 i + 1 ( 1 ≤ i ≤ n / 2 ) L(i) \geq L(2i)且L(i) \geq L(2i+1\quad (1\leq i\leq n/2) L(i)≥L(2i)且L(i)≥L(2i+1(1≤i≤n/2), 说人话就是, 每一个 分支节点 都要大于其 左右孩子 节点 - 小根堆:
满足 L ( i ) ≤ L ( 2 i ) 且 L ( i ) ≤ L ( 2 i + 1 ( 1 ≤ i ≤ n / 2 ) L(i) \leq L(2i)且L(i) \leq L(2i+1\quad (1\leq i\leq n/2) L(i)≤L(2i)且L(i)≤L(2i+1(1≤i≤n/2), 每一个 分支节点 都要小于其 左右孩子 节点
2. 怎么建立大根堆
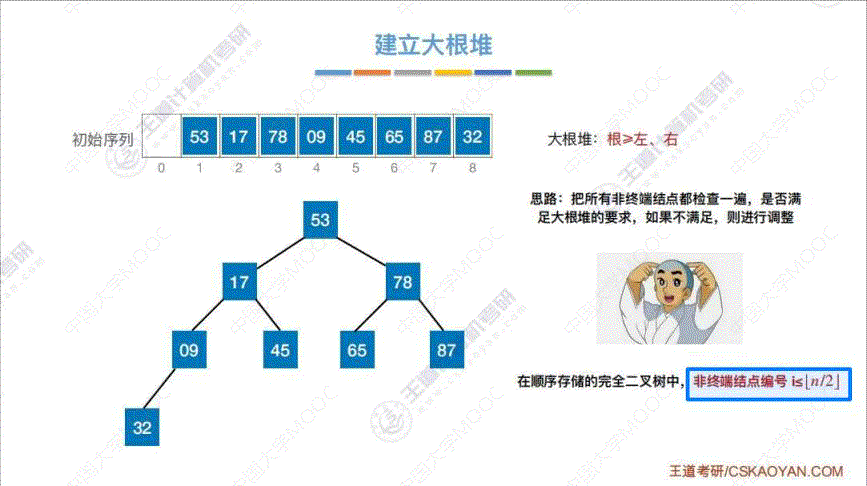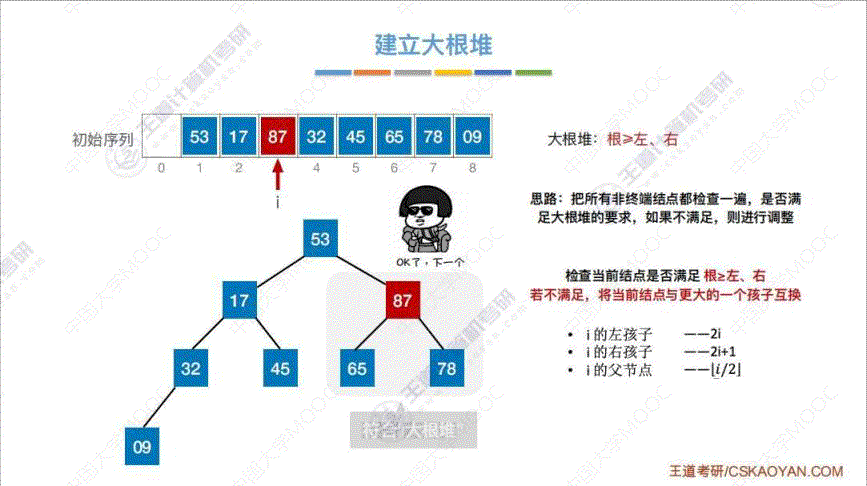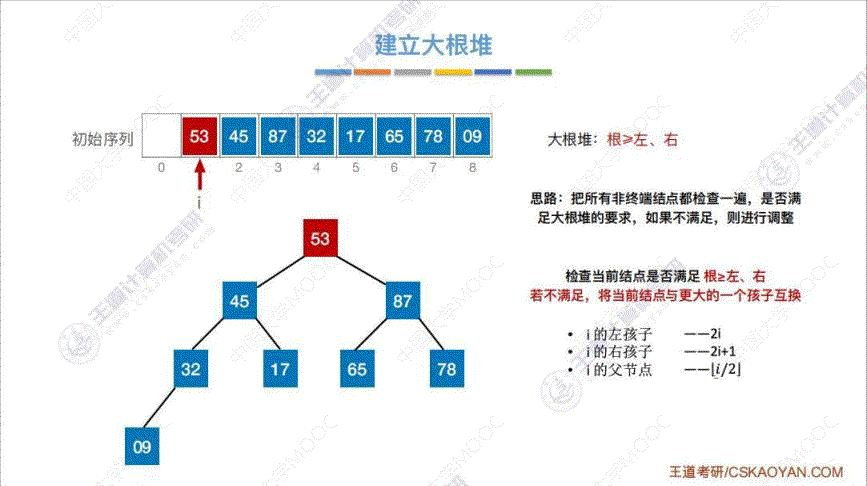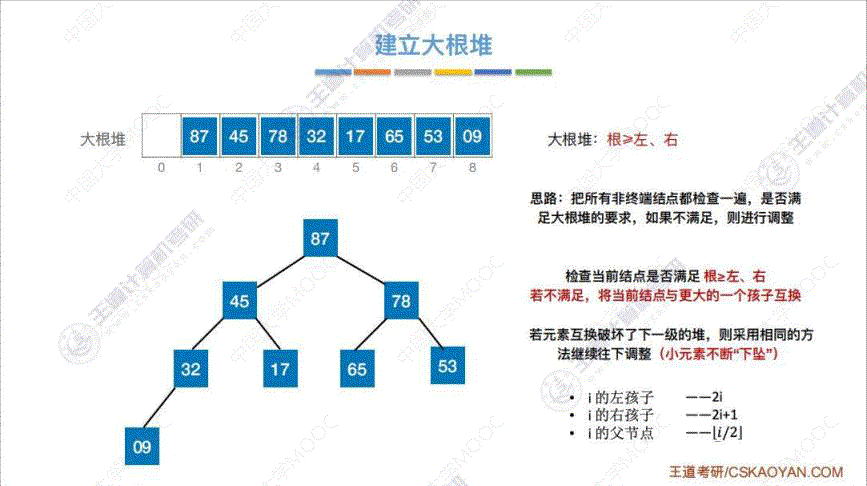
- 算法思想:
- 先将初始序列按照 树的"层次遍历" 建立一棵二叉树
- 依次扫描 “非终端结点”, 即在序列中编号 i ≤ ⌊ n / 2 ⌋ i \leq \lfloor n/2 \rfloor i≤⌊n/2⌋ 的结点
- 把所有 “非终端结点” 都检查一遍, 是否满足 “大根堆” 的要求, 如果不满足, 则进行调整
- 如果某一次调整后, 导致下一级的 “大根堆”, 则采用相同的方法继续往下调整
- 代码实现: 这里以调整 53 这个结点作为例子

3. 怎么基于大根堆排序

- 算法思路: 每一趟都将 “堆顶” 元素与 "蓝色部分"待排序列的最后一个元素进行交换, 并将 "蓝色部分"待排部分再次调整为大根堆.
- 代码实现:
#- 1
- 效率分析:
- 时间复杂度:
建"堆"时间: O ( n ) O(n) O(n)
"堆"排序时间: O ( n log 2 n ) O(n\log_2n) O(nlog2n)
总的时间复杂度: O ( n ) + O ( n log 2 n ) = O ( n log 2 n ) O(n)+O(n\log_2n)=O(n\log_2n) O(n)+O(nlog2n)=O(nlog2n) - 空间复杂度: O ( 1 ) O(1) O(1)
- 稳定性: 不稳定
- 时间复杂度:
4. 堆的插入 (小根堆为例)
算法思路: 将 “插入元素” 插入到表尾, 然后与 “父节点” 相比, 不断重新调整至小根堆
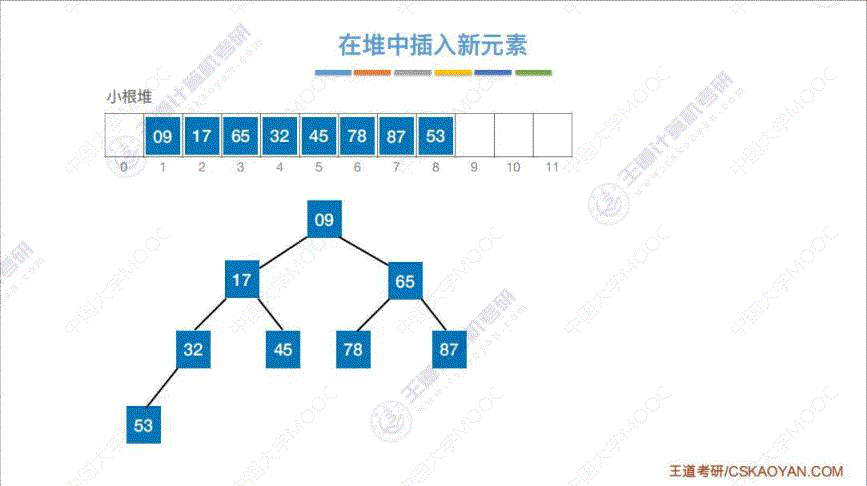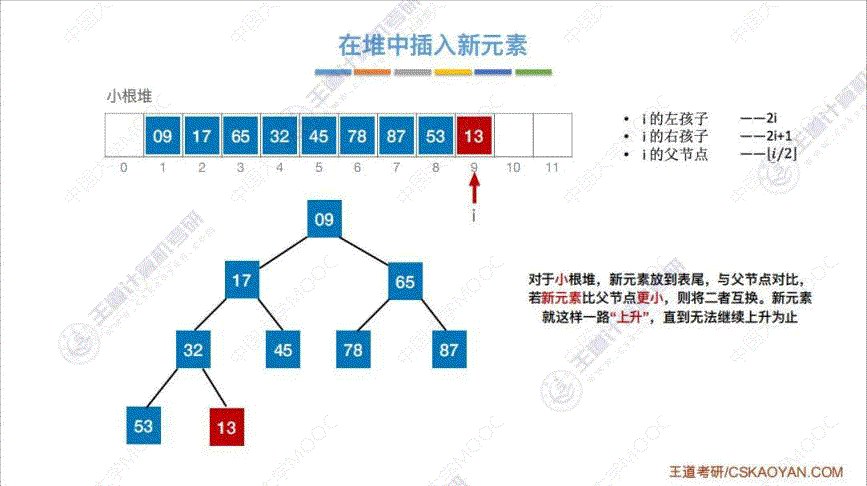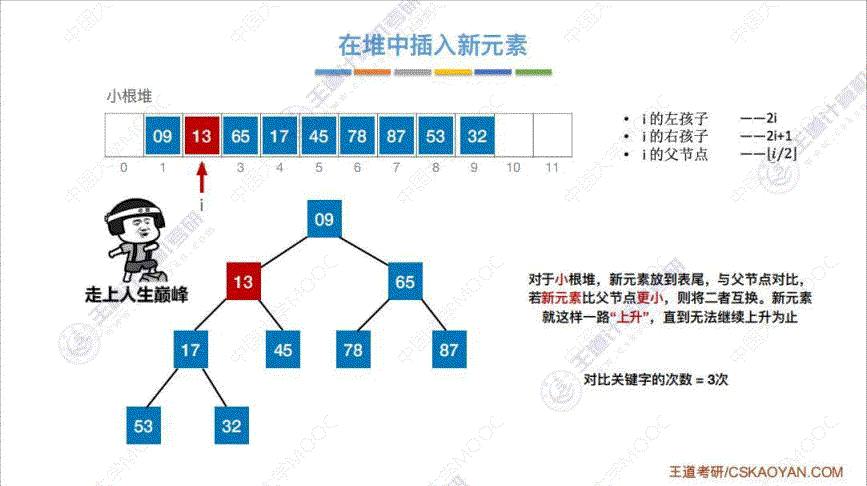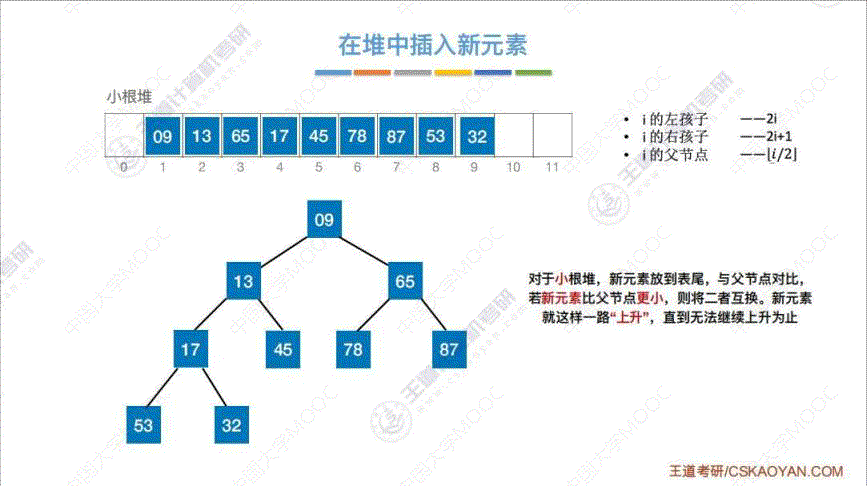
5. 堆的删除
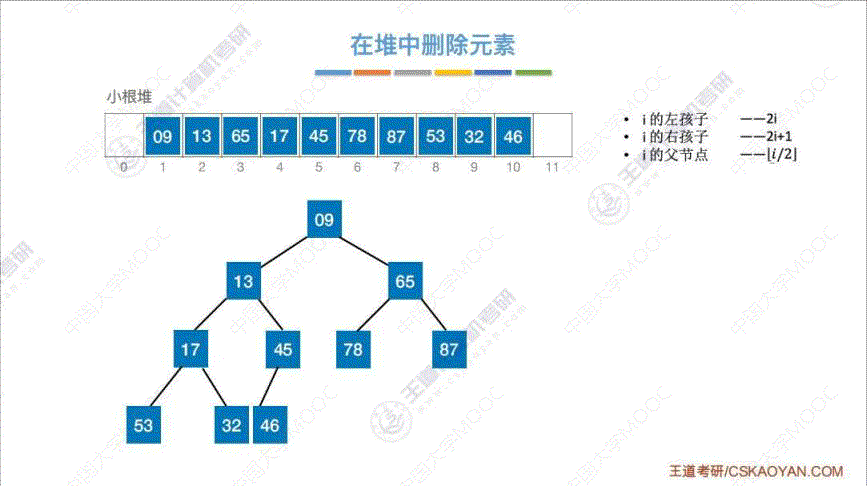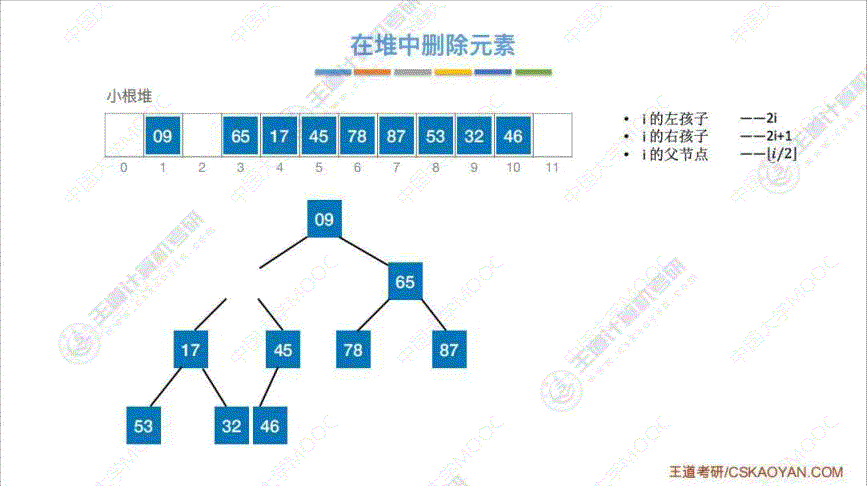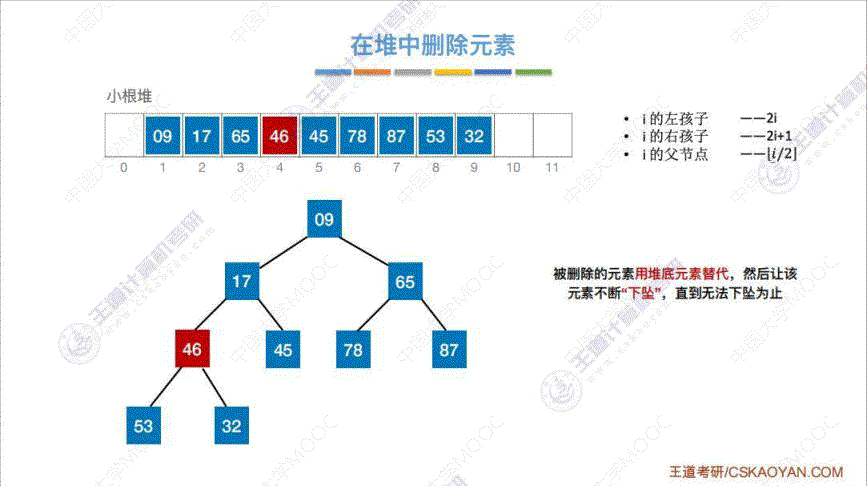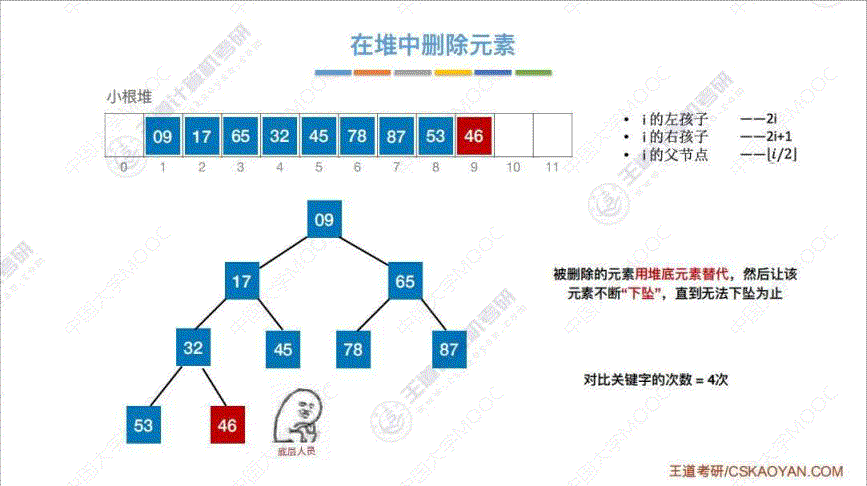
算法思路: 将 “删除元素” 用 “表尾元素” 替代, 然后与 “孩子结点” 相比, 不断重新调整至小根堆
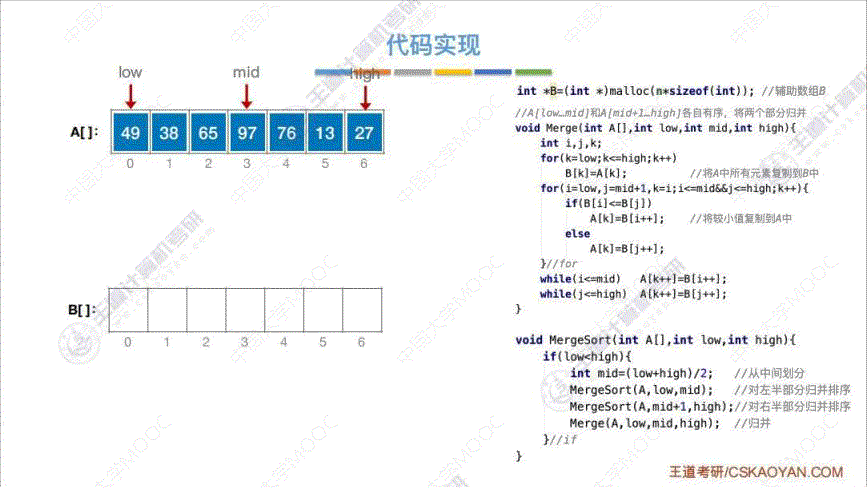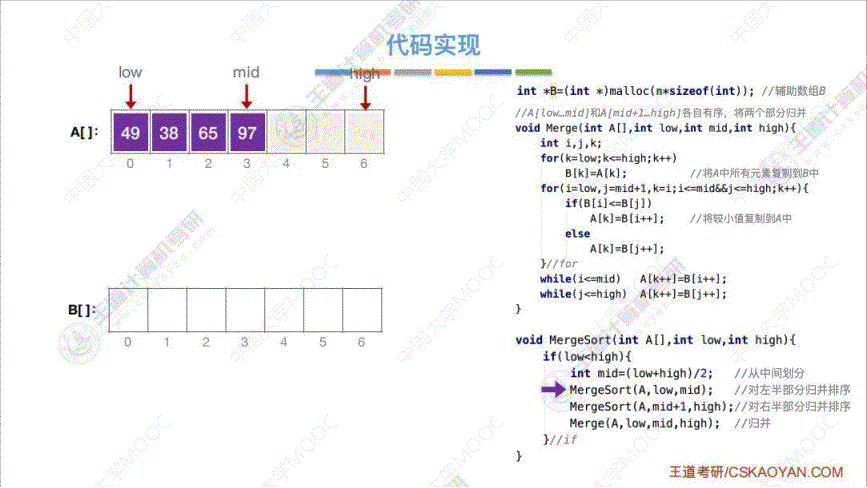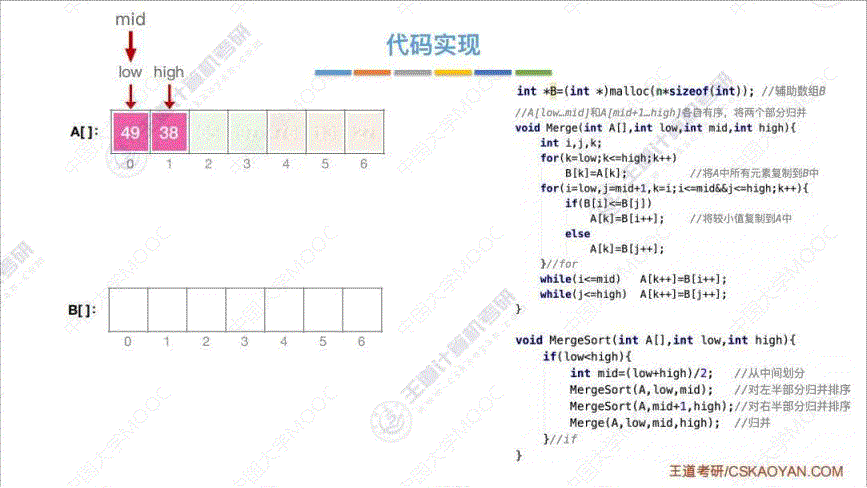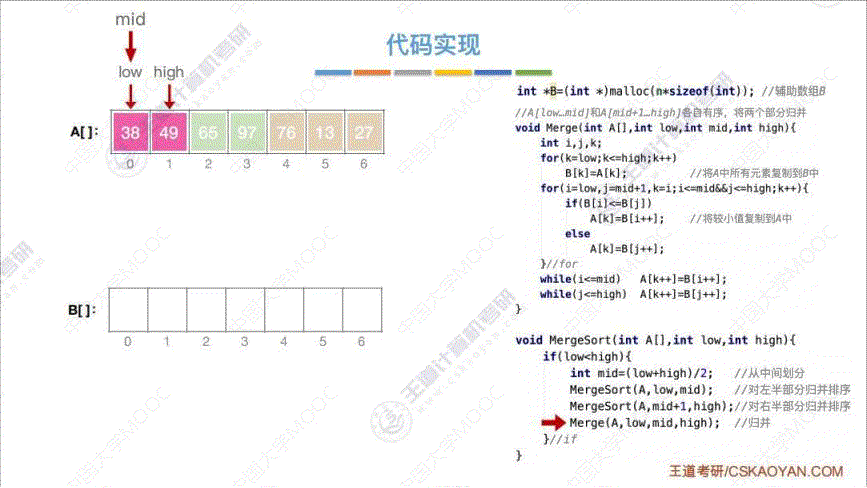
V. 归并排序

- 算法思路: 将两个 “有序的待排序列” 从头到尾依次扫描, 每一次都进行两两对比, 把小的或者大的 那一个放进 “已排序序列” 中, 直至全部扫描完
- 代码实现:
- 效率分析:
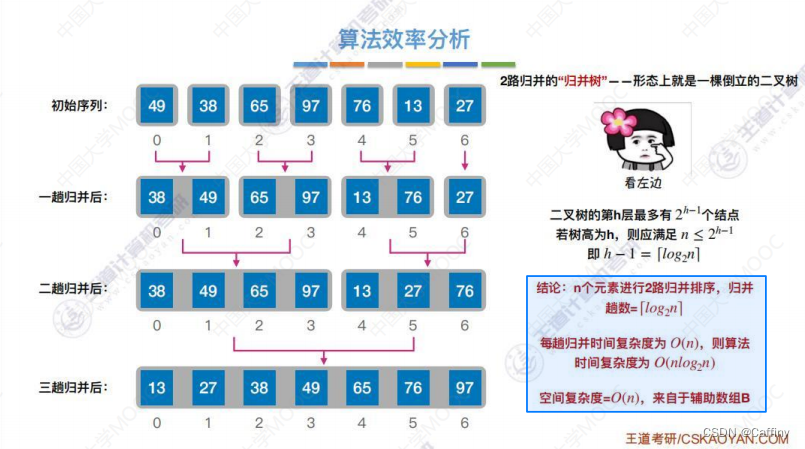
- 时间复杂度: O ( n log 2 n ) O(n\log_2n) O(nlog2n)
- 空间复杂度: O ( n ) O(n) O(n)
- 稳定性: 稳定
VI. 基数排序

- 算法思想:: 每次按照一个 “指标” 来进行排序; 先排 “权重小的指标” 再排 “权重大的指标”; 每次按照 “某个指标排完序后” 进行依次收集, 然后进行下一次排序, 直至 “指标” 排完.
- 效率分析::
- 空间复杂度: O ( r ) O(r) O(r) 其中 r r r 是辅助队列的长度, 比如上面gif图里的粉色表就是辅助队列.
- 空间复杂度:
O
(
d
(
n
+
r
)
)
O(d(n+r))
O(d(n+r))
一趟分配 O ( n ) O(n) O(n), n n n 为元素个数
一趟收集 O ( r ) O(r) O(r), r r r 为辅助队列长度
共 d d d 个"指标", 则需要走 d d d 趟. - 稳定性: 稳定
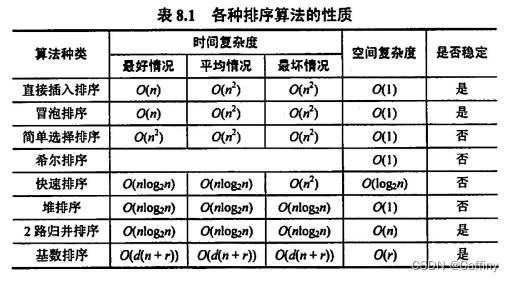
VII. 各种内部排序算法的比较及应用
VIII. 外部排序
a. 简单外部排序
由于过程太杂了, 具体过程就不具体记录了, 简单记录一些要点
- 时间开销
外部排序时间开销 = 读写外存时间 + 内部排序时间 + 内部归并时间- 读写外存时间: 从磁盘(外存) 读到内存, 从内存写进磁盘(外存) 所耗费的时间
- 内部排序时间: 将磁盘内的一个块, 比如一个块有4个数字, 将这一块放进内存, 进行排序, 最终结果得到一个有序的块, 即块内的4个数字都是有序的.
- 内部归并时间: 将磁盘里的 n n n 个有序的块, 进行归并排序, 最终得到这 n n n 个块里的 4 n 4n 4n 个数字(假设一个块有4个数字)有序
- 优化1: 多路归并
- 理论: 采用多路归并可以减少归并的 “趟数”, 从而减少在磁盘来回读写的次数;
对 r r r 个初始归并段, 做 k k k 路归并, 则归并树可以用 k 叉树 k叉树 k叉树 来表示;
磁盘来回读写 I/O 的次数 = 树高 h − 1 h-1 h−1 = ⌈ log k r ⌉ \lceil \log_kr \rceil ⌈logkr⌉, k k k 越大, r r r 越小, 读写次数就越小 - 代价1: 内存开销增加
- 代价2: k k k路归并, 每挑选一个关键字就要比较 k − 1 k-1 k−1 次, 内部归并所需时间增加
- 理论: 采用多路归并可以减少归并的 “趟数”, 从而减少在磁盘来回读写的次数;
- 优化2: 减少初始归并段数量
上面提到, 来回读写 I/O 次数 = h − 1 h-1 h−1 = ⌈ log k r ⌉ \lceil \log_kr\rceil ⌈logkr⌉, r r r 代表了初始归并段数量; 如果在 “内部排序” 阶段, 增加内存的 “输入缓冲区” 则可以生成更大的 “初始归并段”, 从而减少 “初始归并段数量”
b. 败者树
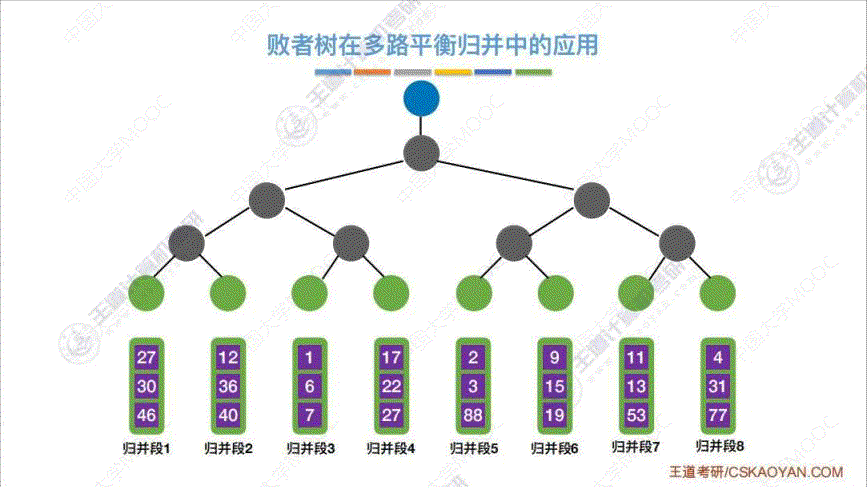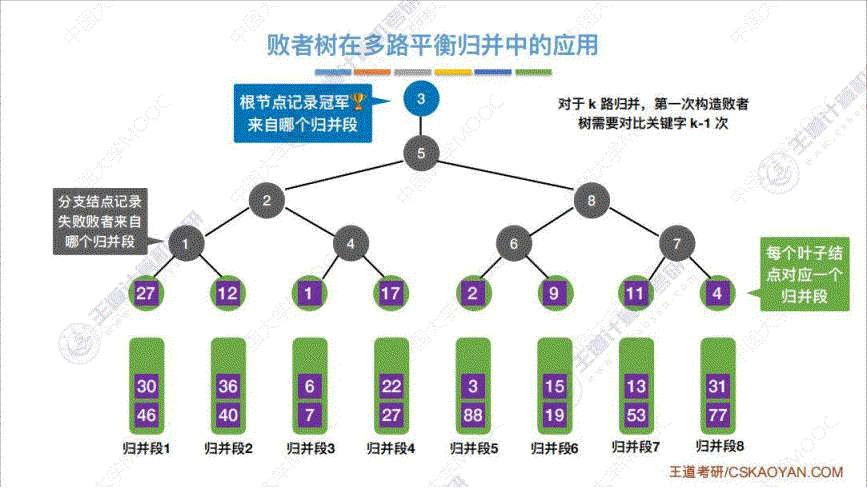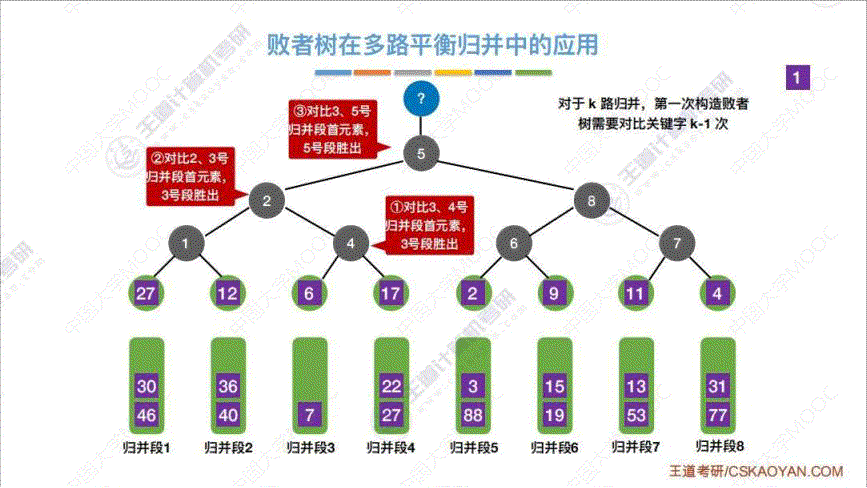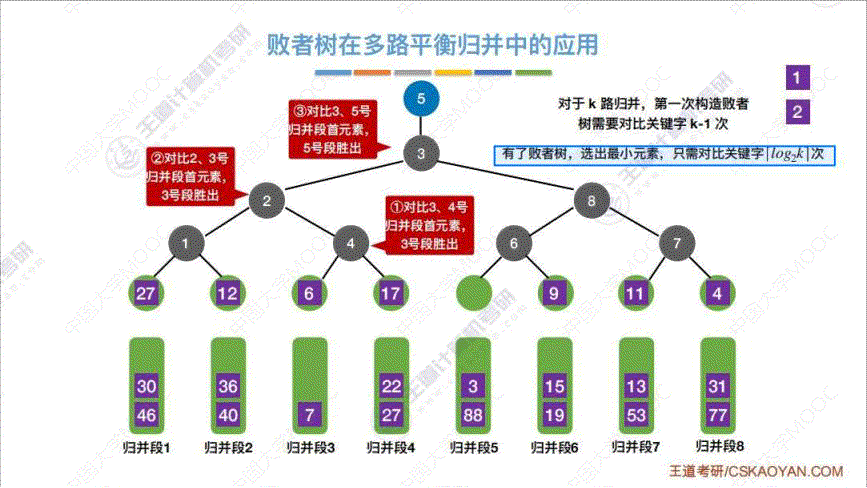
算法思想: 为了解决上述 “优化1中的代价1” 的问题, 增加 k k k 路合并回导致内部排序时间比较次数 k − 1 k-1 k−1 增大, 所以通过建立 “败者树” 来解决. “败者树” 是一棵 “完全二叉树”, 将 k k k 个初始归并段当作叶子节点, 每次传入归并段中的一个关键字, 然后两两 “PK”, 进行决斗, 最终得出这一轮的 “优胜者” 即最小/最大 的那个数字. 然后从优胜者的那个归并段重新补充一个数字进叶子结点, 然后让它依次从下到上依次 “PK”, 值得注意的是, 实际上, 这里第二轮的"PK" 不需要达到 “ k − 1 k-1 k−1” 次那么多.c. 置换选择排序

算法思想: 用小的内存空间得到大的初始归并段; 不断从磁盘中读取一个个数字, 放到内存中, 然后将 “内存中最小的数” 并且 “比上一个移出去的数字大的数” 移出去, 然后移入新的数字. 当内存中, 所有的数字都比 “上一个移出去的数字” 都要小, 那就新开一个初始归并段.
d. 最佳归并树

算法思想: 现有 5 5 5 个初始归并段, 每个初始归并段所占的块数各不相同, 如果要进行二路归并, 我们可以发现, 不同的 “组合” 导致最终的这棵 “归并树” 的 “带权路径长度” 会不同,
恰巧 “归并树的带权路径长度” = “读磁盘的次数” = “写磁盘的次数”. 所以我们可以构造哈夫曼树的方法来构造这棵 “最佳归并树”

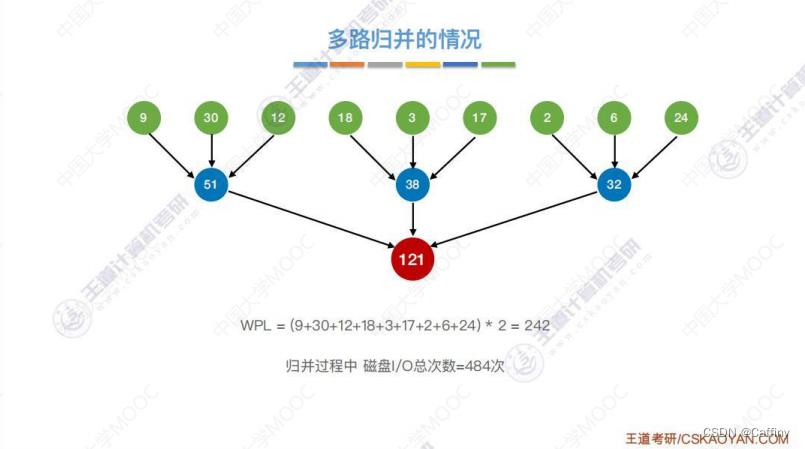
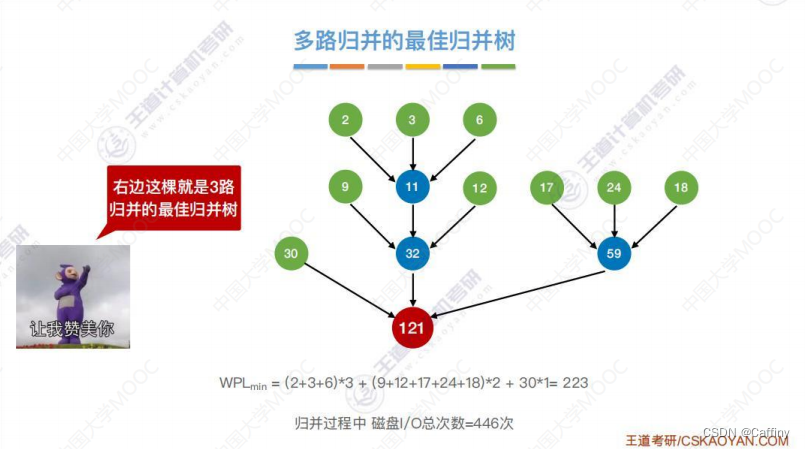
Notes: 对于 k k k 叉归并,若初始归并段的数量无法构成严格的 k k k 叉归并树,则需要补充几个长度为 0 0 0 的“虚段”,再进行k叉哈夫曼树的构造。下左图为错误做法, 右图为正确做法.


对于添加多少个虚段:

- 评价指标
-
相关阅读:
【JavaScript】JS语法入门到实战
gcc和g++区别
Nodejs 应用编译构建提速建议
java毕业设计基于VUE电脑城摊位出租系统mybatis+源码+调试部署+系统+数据库+lw
MySQL的UPDATE及SELECT...FOR UPDATE语句关于锁的一些简单验证
java语法复习:注解
网络安全与基础设施安全局(CISA):两国将在网络安全方面扩大合作
CDA Level1——3.数据库
基于springboot的疫情防控管理系统
OpenAI 现已开始考虑自研 AI 芯片战略
- 原文地址:https://blog.csdn.net/JackyAce6880/article/details/125977875