-
【数据结构】二叉搜索树

1.二叉搜索树的概念
二叉搜索树是一种特殊的二叉树,也叫二叉排序树。二叉搜索树有以下的性质:
- 若左子树不为空,那么左子树上所有节点的值都小于根节点
- 若右子树不为空,那么右子树上所有节点的值都大于根节点
- 左子树和右子树都为二叉搜索树
- 中序遍历的结果是升序
- 二叉搜索树中不会存放重复的数据
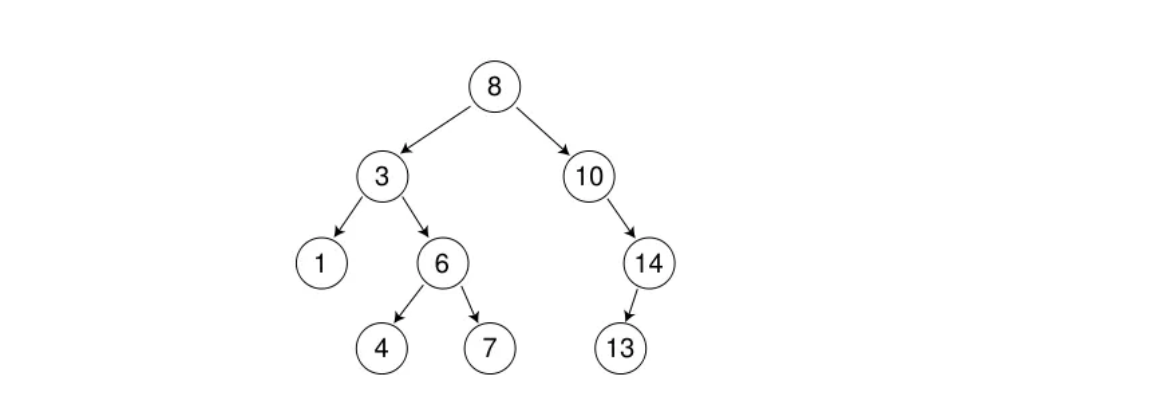
2.二叉搜索树的接口实现
2.1定义节点和二叉搜索树的成员变量
//定义节点 template<class K> struct BSTreeNode { BSTreeNode<K>* _left; //左子树指针 BSTreeNode<K>* _right;//右子树指针 K _key; //构造函数 BSTreeNode(const K&key) :_left(nullptr),_right(nullptr),_key(key) {} } //声明二叉搜索树 template<class K> class BSTree { typedef BSTreeNode<K> Node; //类外接口 private: //类内接口 Node* _root; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.2构造函数
二叉搜索树BSTree成员变量只有一个根节点的指针,属于是内置类型。所以可以使用默认生成的构造函数。但是需要显示的写出来,否则拷贝构造函数会重载构造函数,导致无法正常的调用构造函数。
//在C++11中有default关键字,下面的写法可以强制编译器生成默认的构造函数 BSTree()=default; //也可以自己定义构造函数 BSTree() :_root(nullptr) {}- 1
- 2
- 3
- 4
- 5
- 6
2.3拷贝构造
Node* copytree(Node* root) { if(root==nullptr) return nullptr; Node* sroot=new Node(root->_key); sroot->_left=copytree(root->_left); sroot->_right=copytree(root->_right); return sroot; } BSTree(BSTree<K>& tree) { /* 使用递归进行拷贝;因为拷贝构造无法传递结点指针参数,无法调用递归。 因此需要定义一个类内的递归函数Node* copytree(Node* root) */ _root=copytree(tree._root); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2.3 operator=()
重载=最简单的写法就是使用现代写法
//传参需要调用拷贝构造,属于是临时变量,函数调用结束就会销毁,所以很适合现代写法 BSTree<K>& operator=(BSTree<K> tree) { //复用拷贝构造 std::swap(_root,tree._root); return *this; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.4析构函数
//递归式的进行销毁结点,需要定义类内的递归函数 void destory(Node* root) { if(root==nullptr) return ; destory(root->_left); //销毁左子树 destory(root->_right); //销毁右子树 delete root; //销毁当前的节点 } ~BSTree() { destory(_root); _root=nullptr; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.5查找接口find
因为左子树所有节点的值都小于根节点,右子树所有的节点值都大于根节点。所以可以比较当前节点的值与需要查找的值进行比较,可以判断出需要查找的值所在的子树,如果为nullptr,说明没有该值。
//循环实现find接口 bool find(const K&key) { Node* cur=_root; while(cur) { if(cur->_key==key) { return true; } else if(cur->_key>key) { cur=cur->_left; } else { cur=cur->_right; } } return false; } //递归的方式 bool _find(Node* root,const K&key) { if (root == nullptr) return false; if (root->_key < key) { return _find(root->_right, key); } else if (root->_key > key) { return _find(root->_left, key); } else { return true; } } bool Find(const K&key) { return _find(_root,key); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
2.6中序遍历
void _Inorder(Node* root) { if(root==nullptr) return ; _Inorder(root->_left); cout<<root->_key<<" "; _Inorder(root->_right); } void Inorder() { _Inorder(_root); cout<<endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

2.7插入接口insert()
- 树为空,则直接新增节点,赋值给root指针
- 树不空,按二叉搜索树性质查找插入位置,插入新节点
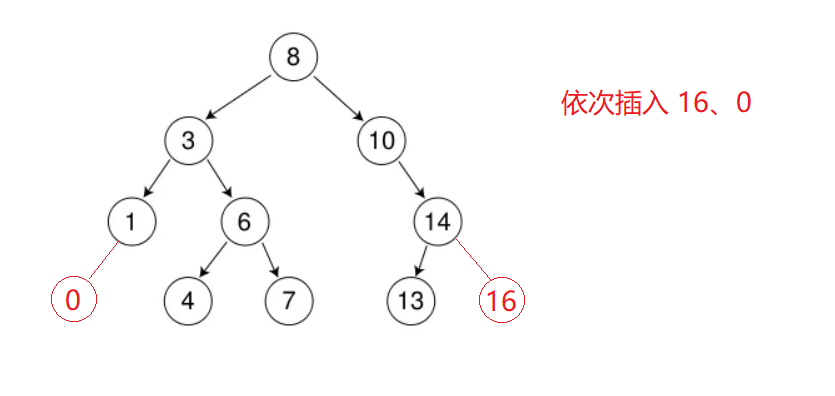
使用循环的写法
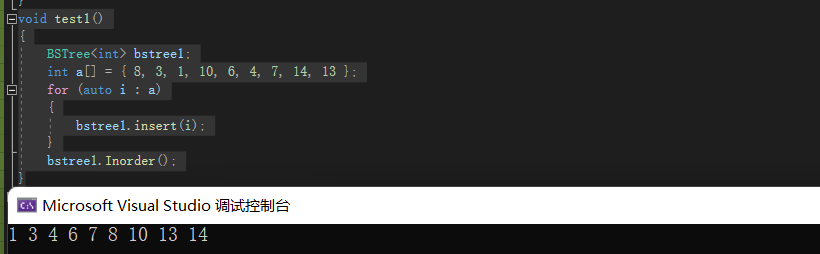
//循环的写法 bool insert(const K& k) { //如果是一棵空树,就在这个位置插入数据。 if (_root == nullptr) { _root = new Node(k); return true; } //因为需要将父节点和插入的结点连接在一起,所以需要一个结点记录父节点的位置。 Node* parent = _root; Node* cur = _root; while (cur) { parent = cur; if (cur->_key < k) { cur = cur->_right; } else if (cur->_key > k) { cur = cur->_left; } else { return false; } } cur = new Node(k); //判断插入的位置是在父节点的左子树还是右子树 if (k < parent->_key) { parent->_left = cur; } else { parent->_right = cur; } return true; } //测试接口 void test1() { BSTree<int> bstree1; int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 }; for (auto i : a) { bstree1.insert(i); } bstree1.Inorder(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
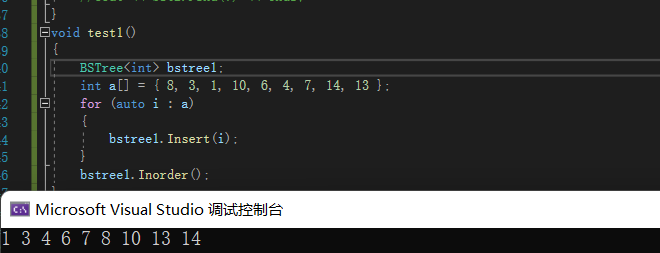
递归的方式
//使用引用,这样root就是父结点的_left或者_right的引用。这样就不用去连接父节点和子节点。 bool _insert(Node*&root, const K& key) { if (root == nullptr) { root = new Node(key); return true; } if (root->_key == key) { return false; } else if (root->_key > key) { _insert(root->_left, key); } else { _insert(root->_right, key); } } bool Insert(const K&key) { return _insert(_root,key); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
同样对接口进行测试
2.8删除接口erase()
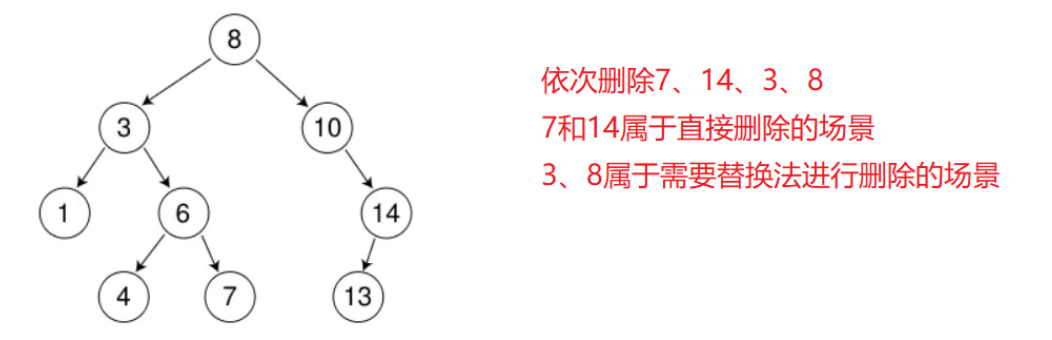
删除节点的情况一共有四种:
- 删除的节点为无孩子节点
- 删除的节点无有孩子节点
- 删除的节点无左孩子节点
- 删除的节点左右孩子节点都有。
第一种情况可以和第二或者第三情况进行合并,使用直接删除的方法。
对与第四种情况,可以使用替换法。找到需要删除节点的右子树的最小,或者是左子树的最大。
比如要删除8,就可以用左子树的最大7,两者交换值。并且可以看出左子树是一棵二叉搜索树(此时整棵树不是二叉搜索树)
也可以用右子树的最小10交换值。此时右子树也是一棵二叉搜索树。
所以如果要使用递归,,就可以在替换后删除左子树或者右子树的目标值。
非递归接口
bool erase(const K& key) { if (_root == nullptr) return false; //删除后需要连接父子节点,所以需要记录父节点的位置 //这里我们使用目标节点右子树的最小值进行替换的方式 Node* cur = _root; Node* parent = _root; //这一步是寻找目标节点。 while (cur) { if (cur->_key < key) { parent = cur; cur = cur->_right; } else if (cur->_key > key) { parent = cur; cur = cur->_left; } //如果找到了需要删除的节点,分三种情况进行讨论 else { //如果目标节点的右子树为空,使用直接删除的方式 if (cur->_right == nullptr) { //如果需要删除的是头结点,需要进行特殊的处理 if (cur == _root) { _root = cur->_left; } else { if (cur == parent->_left) { parent->_left = cur->_left; } else { parent->_right = cur->_left; } } delete cur; } //如果目标节点的左子树为空,使用直接删除的方式 else if (cur->_left == nullptr) { //如果需要删除的是头结点,进行特殊处理 if (cur == _root) { _root = cur->_right; } else { if (cur == parent->_left) { parent->_left = cur->_right; } else { parent->_right = cur->_right; } } delete cur; } //如果有两个孩子节点 else { //minnode是目标节点右子树的最小节点 //minparent是右子树最小节点的父节点 Node* minparent = cur; Node* minnode = cur->_right; while (minnode->_left) { minparent = minnode; minnode = minnode->_left; } //交换节点的值 std::swap(minnode->_key, cur->_key); if (minparent->_left == minnode) { minparent->_left = minnode->_right; } else { minparent->_right = minnode->_right; } delete minnode; } return true; } } return false; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
递归的写法
//使用引用,就不需要去找父节点 bool _erase(Node*&root, const K& key) { if (root == nullptr) return false; //如果找到了需要删除的节点 if (root->_key == key) { //记录一下当前的结点,方便后续删除该结点。 Node* del = root; //分三种情况进行讨论 //如果右孩子为空 if (root->_left == nullptr) { root = root->_right; delete del; return true; } //如果左孩子为空 else if (root->_right == nullptr) { root = root->_left; delete del; return true; } //如果两个都不是空,使用替换法,找目标节点右子树的最小 else { //minnode是右子树的最小结点 Node* minnode = root->_right; while (minnode->_left) { minnode = minnode->_left; } std::swap(root->_key, minnode->_key); //上文提过,使用替换法后,目标结点的右子树或者左子树依然是一棵二叉搜索树。使用递归删除,递归的出口为目标结点无左孩子 //(如果是用左子树的最大,那么递归出口就是目标节点无右孩子) return _erase(root->_right, key); } return false; } else if (root->_key > key) { _erase(root->_left, key); } else { _erase(root->_right, key); } } bool Erase(const K& key) { return _erase(_root, key); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
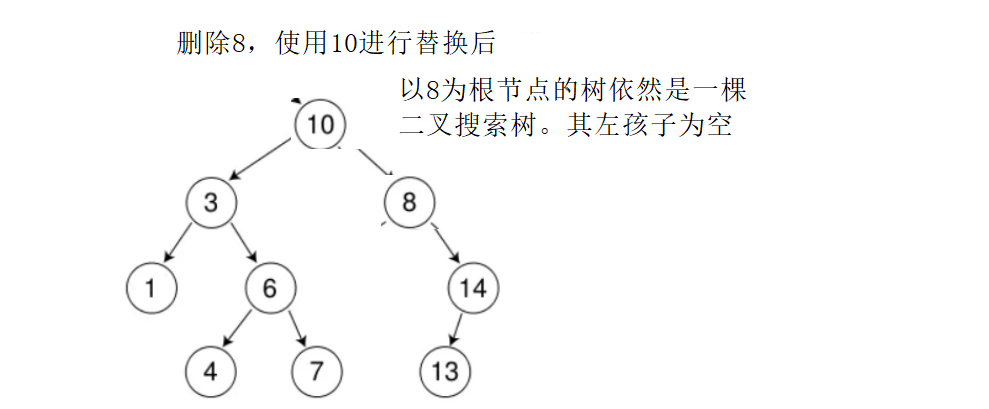
测试接口
void test1() { BSTree<int> bstree1; int a[] = { 8, 3, 1, 10, 6, 4, 7, 14, 13 }; for (auto i : a) { bstree1.Insert(i); } bstree1.Inorder(); bstree1.Erase(7); bstree1.erase(14); bstree1.Erase(3); bstree1.erase(8); bstree1.Inorder(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

3.二叉搜索树的应用
**1.K模型:**K模型只有key作为关键字,二叉搜索树中只需要存储key即可。
比如:给一个单词,判断单词拼写是否正确。方法:
- 将词典中所有单词集合的每个单词作为key,构建一棵二叉搜索树。
- 搜索二叉搜索树中是否有该单词,存在就拼写正确,否则拼写错误。
**2.KV模型:**即每一个关键字key都有与之对应的value。即
比如:查询单词的中文意思。
- 二叉搜索树中,存储键值对。
- 按照关键字进行构建二叉搜索树
3.1实现KV模型
template<class K,class V> struct BSTreeNode { BSTreeNode<K>* _left; //左子树指针 BSTreeNode<K>* _right;//右子树指针 K _key; V _val; //构造函数 BSTreeNode(const K&key,const V&val) :_left(nullptr),_right(nullptr),_key(key),_val(val) {} } //实现KV模型的二叉搜索树 template<class K, class V > class BSTree { public: typedef BSTreeNode<K, V> Node; bool Insert(const K& key,const V& value) { return _insert(_root, key,value); } bool Erase(const K& key) { return _erase(_root, key); } void Inorder() { _Inorder(_root); cout << endl; } Node* Find(const K& key) { return _find(_root,key); } private: Node* _root=nullptr; Node* _find(Node* root, const K& key) { if (root == nullptr) return nullptr; if (root->_key < key) { return _find(root->_right, key); } else if (root->_key > key) { return _find(root->_left, key); } else { return root; } } void _Inorder(Node* root) { if (root == nullptr) return; _Inorder(root->_left); cout << root->_key << ": "<<root->_value<<" "; _Inorder(root->_right); } bool _insert(Node*& root, const K& key,const V& value) { if (root == nullptr) { root = new Node(key,value); return true; } if (root->_key == key) { return false; } else if (root->_key > key) { _insert(root->_left, key,value); } else { _insert(root->_right, key,value); } } bool _erase(Node*& root, const K& key) { if (root == nullptr) return false; //如果找到了需要删除的节点 if (root->_key == key) { //记录一下当前的结点,方便后续删除该结点。 Node* del = root; //分三种情况进行讨论 //如果右孩子为空 if (root->_left == nullptr) { root = root->_right; delete del; return true; } //如果左孩子为空 else if (root->_right == nullptr) { root = root->_left; delete del; return true; } //如果两个都不是空,使用替换法,找目标节点右子树的最小 else { //minnode是右子树的最小结点 Node* minnode = root->_right; while (minnode->_left) { minnode = minnode->_left; } std::swap(root->_key, minnode->_key); //上文提过,使用替换法后,目标结点的右子树或者左子树依然是一棵二叉搜索树。使用递归删除,递归的出口为目标结点无左孩子 //(如果是用左子树的最大,那么递归出口就是目标节点无右孩子) return _erase(root->_right, key); } return false; } else if (root->_key > key) { _erase(root->_left, key); } else { _erase(root->_right, key); } } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
3.2KV模型案例实现
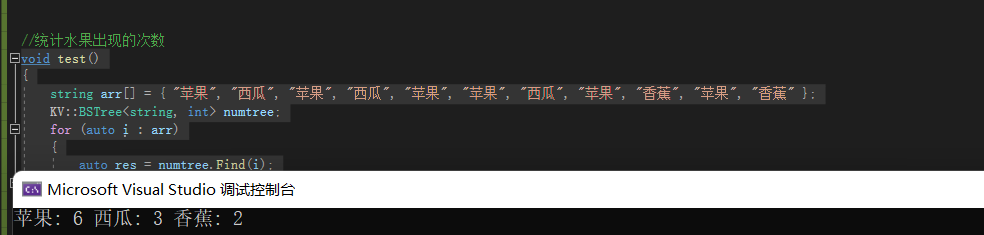
统计水果出现的次数:“苹果”, “西瓜”, “苹果”, “西瓜”, “苹果”, “苹果”, “西瓜”, “苹果”, “香蕉”, “苹果”, “香蕉”
思路:
-
将水果名作为关键字存入二叉搜索树,出现的次数作为value。
-
当在二叉搜索树中找到水果名时,对应的value+1
-
当没有找到时,在二叉搜索树中插入该水果,对应的value设为1
void test() { string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" }; KV::BSTree<string, int> numtree; for (auto i : arr) { auto res = numtree.Find(i); if (res==nullptr) { numtree.Insert(i, 1); } else { res->_value++; } } numtree.Inorder(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.3剖析while(cin>>str)的原理
当我们需要连续的输入字符串时,就出现了这种写法。
while(表达式):循环结束的标志里面的表达式为false。 而while(表达式)判断这一步其实隐含了一步,**将表达式的返回值强制类型转化为bool类型。**相当于bool(表达式返回值)。
cin>>str的返回值是cin,而cin重载了一个特殊的运算符bool

因此cin>>str表达式的返会值可以强制类型转化为一个bool值。当流插入成功时,类型转换为true;而流插入失败时类型转化为false
3.4自定义类型与内置类型的相互转化
3.4.1单参数的隐士类型转化
内置类型的参数可以转化为单参数类型的类
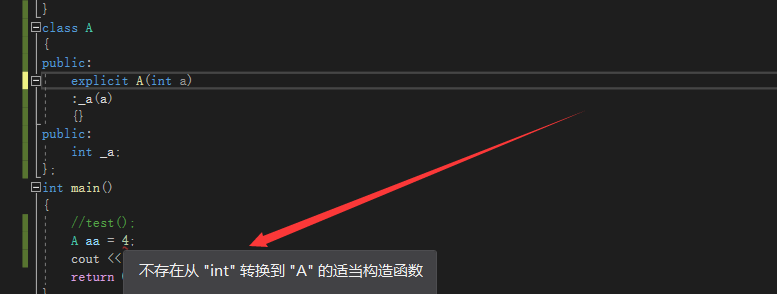
class A { public: A(int a) :_a(a) {} public: int _a; }; int main() { //test(); A aa = 4; cout << aa._a << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
A aa=4这一步发生了隐士类型的转化。int 4通过沟造函数了一个A类型的临时变量,然后再赋值给了aa。
如果我们在构造函数前面加上explicit,就可以防止隐士类型的转化。
3.4.2第一个参数无默认值其余均有默认值的构造函数
构造函数第一个参数无默认值,其余均有默认值的类型也可以进行隐士类型的转化。
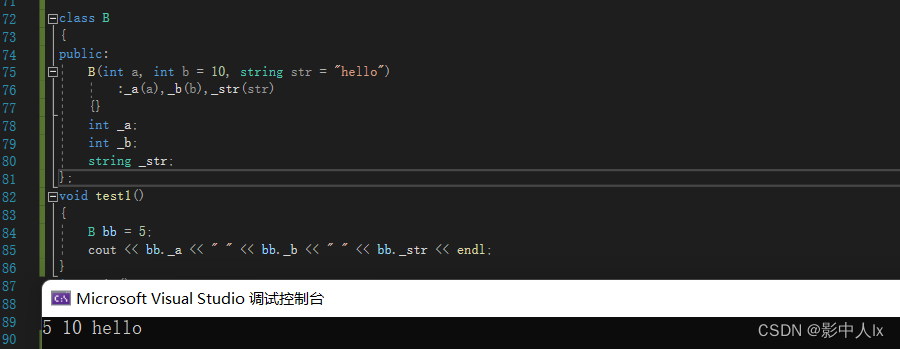
class B { public: B(int a, int b = 10, string str = "hello") :_a(a),_b(b),_str(str) {} int _a; int _b; string _str; }; void test1() { B bb = 5; cout << bb._a << " " << bb._b << " " << bb._str << endl; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.4.3自定义类型转化为内置类型
自定义类型同样可以转化为内置类型,只需要对强制类型转化函数就行重载。
如:cin>>str就对bool类型进行了重载。 当然还可以operator int,operator double…这些都是强制类型转化函数
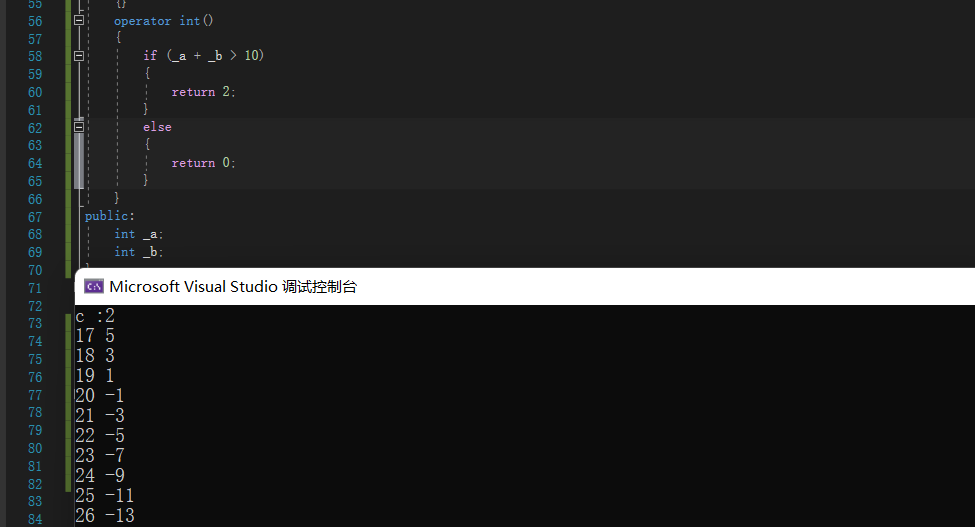
class A { public: explicit A(int a,int b) :_a(a),_b(b) {} operator int() { if (_a + _b > 10) { return 2; } else { return 0; } } public: int _a; int _b; }; int main() { //test(); A aa(17, 5); int c = aa; cout << "c :" <<c<< endl; while (aa) { cout << aa._a<<" " << aa._b << endl; aa._a++; aa._b -= 2; } return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
通过类型转化函数重载,自定义类型可以转化为一个内置类型。
感谢阅读!

-
相关阅读:
Spring(一)Spring配置、构造注入、bean作用域、bean自动装配
黄金代理前景如何,有得搞吗?
Haiku OS 在 osx 上的编译与运行
拼多多API批量获取商品详情信息
程序员不得不知道的 API 接口常识
四旋翼电调驱动程序(STM32F1)
shiro的过滤器和权限控制
博客摘录「 dubbo默认超时设置容易引发的问题(默认1秒)」2023年9月23日
HFS报告:流程智能是应对宏观经济挑战的第一方法
C++类与对象常考知识
- 原文地址:https://blog.csdn.net/qq_53893431/article/details/125998300
