-
【深入】k-means和FCM的差别
这里不普及k-means和FCM的基础知识,只说差别。
FCM在k-means之后提出,改进之处在于引入了模糊度。这个引入,就导致了一些不同。
假如有两个黑帮团体,各自的老大有不同的管理理念。
k-means的老大只管内政、一视同仁。只要来到我的团队,在考虑大家需求的时候就只人数;
FCM的老大除了考虑人数外,还要考虑所有人的忠诚度(隶属度),包括对手的。对FCM来说,因为会考虑到对方的人,老大的决定就没那么纯正,聚类的精度就会受到影响;但他考虑了忠诚度,所做出的决定就会更偏向团队的主要人员,从数学上来说,就是质心会更偏向更密集的样本点,聚类的效果就更好。
从个人经验来看,FCM的效果一般会比k-means好,但也经常出现k-means的效果更好的情况,所以不能一概而论。
FCM对于离群点的影响要更小
如果一个样本点和两个簇的关系都差不多,那两个簇都不会很待见他,因为相对于其他隶属度更大的点,质心会没有什么心情去光顾他。
FCM还有一点小优势
因为有一个专门的隶属度矩阵,所以我们可以把隶属度并不明确的样本单独提出来,用业务知识进行判断。但这一点,把k-means的代码稍微改改也能实现,所以并不算很大的优势。
FCM一直被诟病会花更多时间
这个时间主要是花在了以下地方:
1.更新C的时候,FCM要去将隶属度和每个样本点相乘,相加,再平均,k-means不仅只和自己簇的样本点算平均,且没有和隶属度相乘这一步。
2.计算了每个样本点到每个质心C的距离之后,FCM要转化为隶属度,k-means不需要转化。FCM会有些比较严重的问题
在 样本数量过多 ,或者 样本维度过大 的情况下,FCM的质心会非常靠近,甚至毁掉聚类
如果样本数量过多
从比喻来理解,因为两个团队的人数变得更多,忠诚度的影响就弱了,老大会更考虑人数,而且是所有人的人数。
从实验来看,如果样本是一维的:
取[-2,2],聚类后的质心点刚好是[-2,2]。
取[-3,-2,-1, 1, 2, 3],质心点是[-1.83, 1.83],更靠近。假设现在两个簇有一些重合:
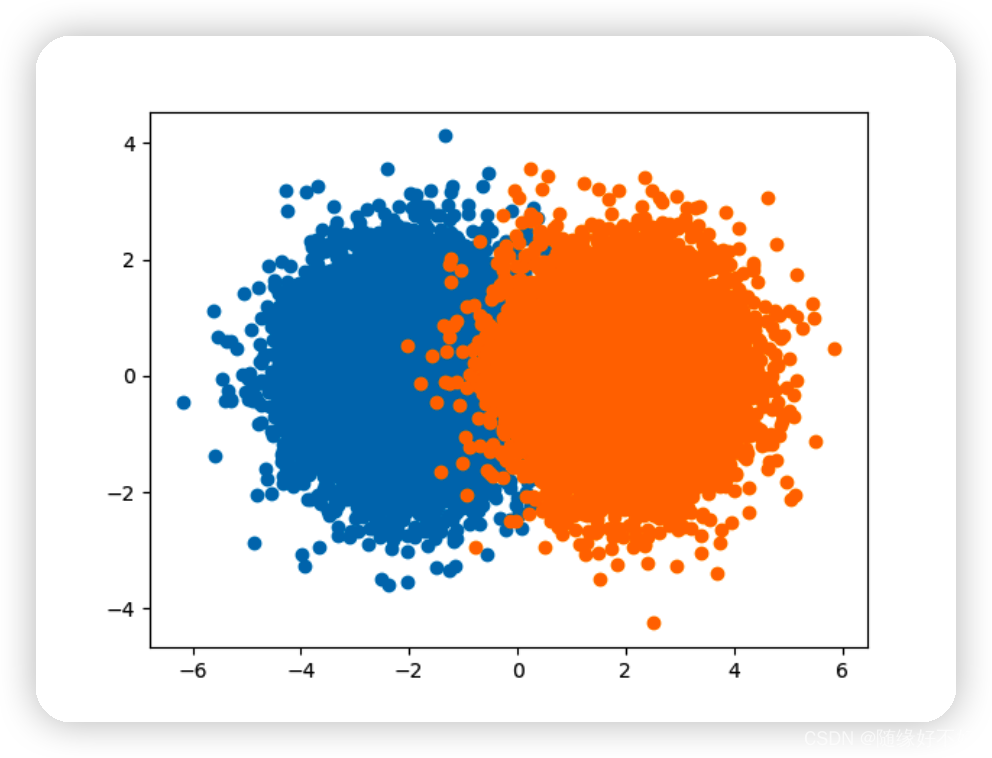
当两个分布的数据多到一定数量,重合部分的数据量会被迅速堆起来。最后就会形成三个山头,两个簇中心和正中心。这就会让FCM的质心往中间靠。
遇到这种数据,k-means的质心也会往中间靠,但不会有FCM这么快。如果两个分布的数据能够被完全分开,k-means就完全不会靠,但FCM会。
如果样本点多到一定程度,FCM的精度会迅速下降。直到超过计算机的存储精度。比如质心之间的差距在小数点后17位,但是计算机只能存储16位,质心就会完全一样,聚类就失效了。
如果样本维度过大
从比喻来理解,虽然人数没变,但每个人都很牛逼,作为团队老大,谁都惹不起,也不管什么忠诚度不忠诚度了,总之敌我都要照顾。
从实验来看:
现实世界,每当维度升高一维,空间会增加超级多,数据之间的分布也会更均衡。什么叫均衡?
如果我们有一个圆,压成一维,也就是压成一条线。在他半径为1的地方有4个点,要让这4个点分布进行平均,那势必左边两个点,右边两个点。
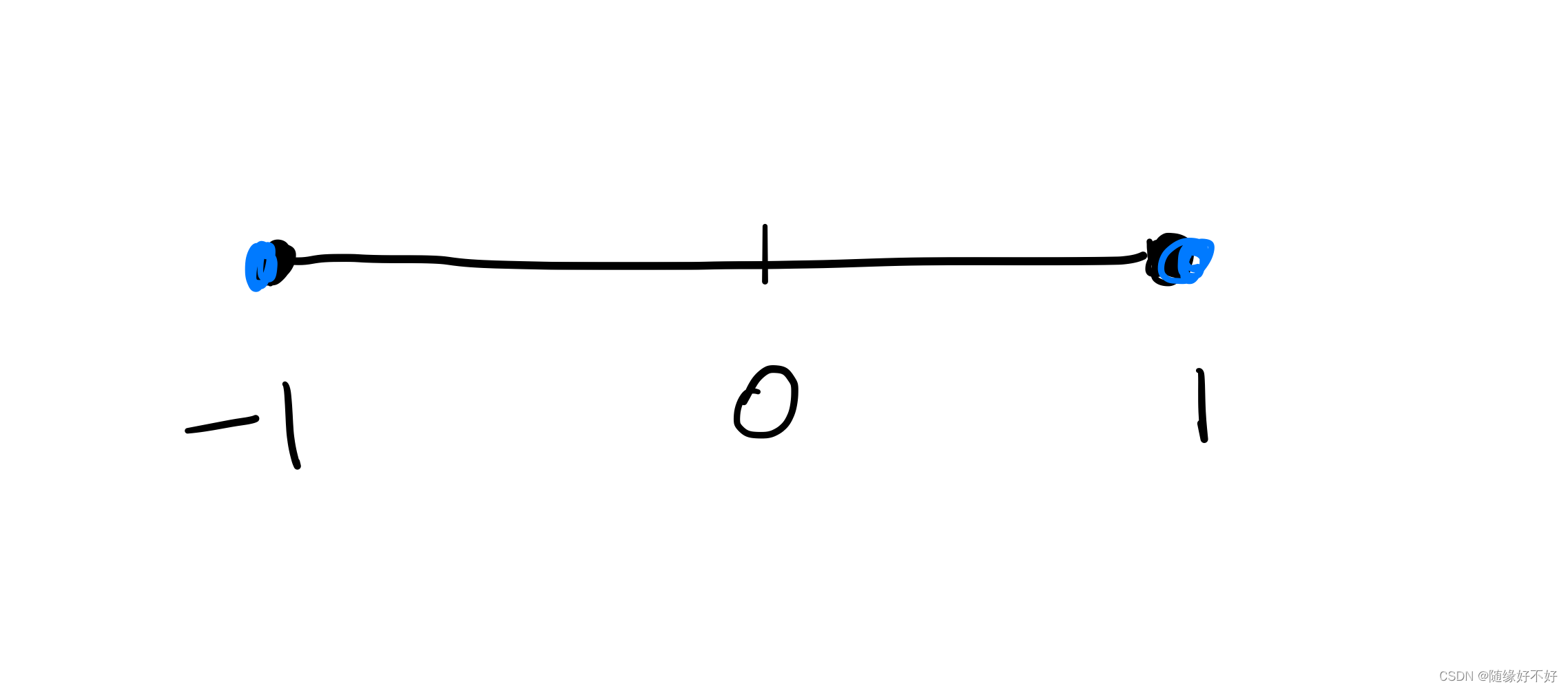
现在把空间升成二维,也就是一个真正的圆了。同样在半径为1的地方放4个点,他就可以是这样:
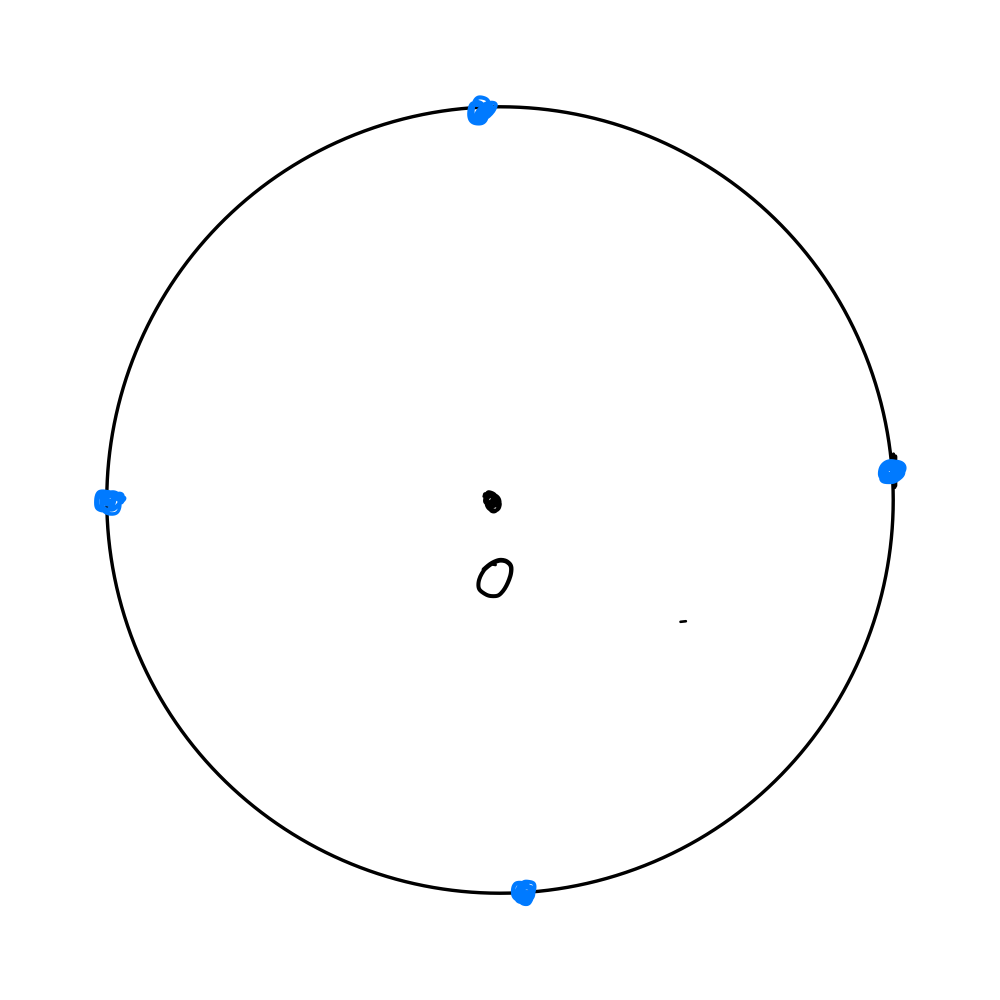
在一维有两个点只能重合,就不均衡。现在到二维上面,空间打开了,他们就可以自己占自己的位置,同时距离一样,就变得更均衡。如果到三维空间,那就更均衡。
现在要聚类,八个点分两组,每组四个点,按照上面的分布来。
先看一维:

上面八个点要聚类,很明显左边四个点和右边四个点分别为一类。
聚类中心如下:

再看二维

上面八个蓝色的点聚类,聚类中心是:
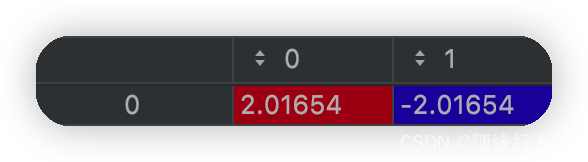
可以看到分布一样,数据一样,维度升高之后,聚类中心的确是靠近了。
其实也不难理解,维度升高之后,数据跑到同样半径的,更广阔的空间中,和两个圆心的距离比例就没那么大了。要考虑所有数据点的FCM算法的中心点,自然也就会更靠近对方的簇一些。同样,如果把维度拉高到一定程度,FCM的精度会迅速下降。直到质心点超过计算机的存储精度,聚类就失效了。
以上规律,根据数据的大小不同数据原本的质量。质量越好,簇之间离得更开,以上两个缺点就会越不敏感,聚类中心靠近的速度也会越慢。
但是!
通过调节FCM公式中的m可以缓解这个问题。m越小,隶属度U的差异性就越大,可以将中心点拉回他原本应该在的位置。所以实际运用的时候,如果数据很大,m是需要当超参数来调整的,不能默认为2。m最小不能超过1,当m无限趋向于1时,fcm就变成k-means了。
如果你要问我什么场合用哪种算法?
如果不想调整FCM的参数:小数据用FCM,大数据用k-means。
如果不介意做个调参侠:用FCM
以上讨论都是基于原始算法,现在已经有了非常多的改进。比如,如果把FCM加上特征权重,就可以一定程度上缓解他的问题。这两种算法也有原型聚类都会有的通病,就是他们只适合分布偏向圆形的数据。如果数据的分布很古怪,就得考虑别的聚类方法,例如层次聚类、密度聚类、深度聚类等。如果两个簇之间重合的部分很多,就算数据的分布是圆形的,也不会得到很好的结果,这时就得考虑高斯混合聚类这种基于EM算法的聚类方法。
-
相关阅读:
JSD-2204-JavaScript-Vue-Day05
django-vue系统报错解决记录
【K8S系列】深入解析k8s 网络插件—kube-router
HTML5期末大作业:HTML+CSS茶叶官网网页设计实例 企业网站制作
【Java】ArrayList底层源码分析
企业电子招投标采购系统源码之电子招投标的组成
RTMP协议解析
MySQL:基础架构与存储引擎
主成分分析法(数学建模)教授先生
unity 动画结束 后处理事件
- 原文地址:https://blog.csdn.net/qq_42115919/article/details/125938540