-
十三、聚簇索引和非聚簇索引
一、题目
聚簇索引和非聚簇索引的区别
二、聚簇索引
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。具体细节依赖于其实现方式;对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页
注意:数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的,如果主键不是自增id,那么可以想象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引,如果没有定义主键,Innodb 会选择非空的唯一索引代替。如果没有这样的索引,Innodb 会隐式的定义一个主键来作为聚簇索引
优点
- 数据访问更快,因为聚簇索引将索引和数据保存在同一个 B+ 树中,因此从聚簇索引中获取数据比非聚簇索引更快
- 聚簇索引对于主键的排序查找和范围查找速度非常快
缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于 InnoDB 表,我们一般都会定义一个自增的 ID 列为主键
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于 InnoDB 表,我们一般定义主键为不可更新。

三、非聚簇索引
在 Innodb 中,在聚簇索引之上创建的索引称之为辅助索引,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。辅助索引叶子节点存储的不再是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找,非聚簇索引索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据
非聚簇索引索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是数据具体的物理地址
四、InnoDB索引实现
4.1、主键索引
InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引

4.2、辅助索引
InnoDB 的所有辅助索引都引用主键作为 data 域。例如,下图为定义在 Col3 上的一个辅助索引:
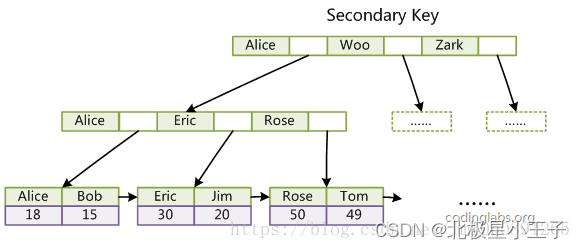
InnoDB 表是基于聚簇索引建立的。因此 InnoDB 的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些
五、MyISAM索引实现
MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
5.1、主键索引
MyISAM 引擎使用 B+Tree 作为索引结构,叶节点的 data 域存放的是数据记录的地址。下图是 MyISAM 主键索引的原理图

这里设表一共有三列,假设我们以 Col1 为主键,图为一个 MyISAM 表的主索引(Primary key)示意。可以看出 MyISAM 的索引文件仅仅保存数据记录的地址
5.2、辅助索引
在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示

同样也是一颗 B+Tree,data 域保存数据记录的地址。因此,MyISAM 中索引检索的算法为首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址,读取相应数据记录MyISM 使用的是非聚簇索引,非聚簇索引的两棵 B+ 树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引 B+ 树的节点存储了主键,辅助键索引 B+ 树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树
转载请标明出处,原文地址:https://blog.csdn.net/weixin_41835916 如果觉得本文对您有帮助,请点击赞支持一下,您的支持是我写作最大的动力,谢谢。

-
相关阅读:
Linux ls命令:查看目录下文件
Linux 搭建NFS
vim 显示行号
python in excel 如何尝鲜 有手就行
OPenSSL-生成证书
SpringCloud之Hystrix、Resilience4j、GateWay、Sentinel、Config、Bus、Stream
MATLAB切片
音视频技术开发周刊 | 258
文件包含漏洞培训
PING命令中的-r参数的原理分析
- 原文地址:https://blog.csdn.net/weixin_41835916/article/details/125916402