-
前端如何开始深度学习,那不妨试试JAX
一、简介
在深度学习方面,TensorFlow 和 PyTorch是绝对的王者。但是,但除了这两个框架之外,一些新生的框架也不容小觑,比如谷歌推出的 JAX深度学习框架。

1.1、快速发展的JAX
JAX是一个用于高性能数值计算的Python库,专门为深度学习领域的高性能计算而设计。自2018 年底谷歌的 JAX出现以来,它的受欢迎程度一直在稳步增长,并且越来越多的来自Google 大脑与其他项目也在使用 JAX。随着JAX越来越火, JAX 似乎正在成为下一代的大型深度学习框架。目前,JAX 在 GitHub 上已累积获得了超过 19.4K 的关注。
JAX 是Autograd和XLA的结合,JAX 本身不是一个深度学习的框架,他是一个高性能的数值计算库,更是结合了可组合的函数转换库,用于高性能机器学习研究。深度学习只是其中的一部分而已,但是你完全可以把自己的深度学习移植到JAX 上面。
借助Autograd的更新版本,JAX 可以自动区分原生 Python 和 NumPy 函数。它可以通过循环、分支、递归和闭包进行微分,并且可以对导数的导数进行导数。它支持反向模式微分(也称为反向传播)grad和正向模式微分,两者可以任意组合成任何顺序。
说到这,就不得不提 NumPy。NumPy 是 Python 中的一个基础数值运算库,被广泛使用的支持大量的维度数组与矩阵运算的数学函数库。不过, numpy 本身不支持 GPU 或其他硬件加速器,也没有对反向传播的内置支持,此外,Python 本身的速度限制阻碍了 NumPy 使用,所以少有研究者在生产环境下直接用 numpy 训练或部署深度学习模型。
在此情况下,出现了众多的深度学习框架,如 PyTorch、TensorFlow 等。但是 numpy 具有灵活、调试方便、API 稳定等独特的优势,而 JAX 的主要出发点就是将 numpy 的以上优势与硬件加速结合,进而支持机器学习研究。除此之外,JAX还具有如下一些优点:
- 可差分:基于梯度的优化方法在机器学习领域具有十分重要的作用。JAX 可通过grad、hessian、jacfwd 和 jacrev 等函数转换,原生支持任意数值函数的前向和反向模式的自动微分。
- 向量化:在机器学习中,通常需要在大规模的数据上运行相同的函数,例如计算整个批次的损失或每个样本的损失等。JAX 通过 vmap 变换提供了自动矢量化算法,大大简化了这种类型的计算,这使得研究人员在处理新算法时无需再去处理批量化的问题。JAX 同时还可以通过 pmap 转换支持大规模的数据并行,从而优雅地将单个处理器无法处理的大数据进行处理。
- JIT编译:XLA (Accelerated Linear Algebra, 加速线性代数) 被用于 JIT 即时编译,在 GPU 和云 TPU 加速器上执行 JAX 程序。JIT 编译与 JAX 的 API (与 Numpy 一致的数据函数) 为研发人员提供了便捷接入高性能计算的可能,无需特别的经验就能将计算运行在多个加速器上。
目前,基于 JAX 已有很多优秀的开源项目,如谷歌的神经网络库团队开发了 Haiku,这是一个面向 Jax 的深度学习代码库,通过 Haiku,用户可以在 Jax 上进行面向对象开发;又比如 RLax,这是一个基于 Jax 的强化学习库,用户使用 RLax 就能进行 Q-learning 模型的搭建和训练;此外还包括基于 JAX 的深度学习库 JAXnet,该库一行代码就能定义计算图、可进行 GPU 加速。可以说, JAX其实就是 TensorFlow 的一个简化库,支持大部分的TensorFlow 功能,而且比 TensorFlow 更加简洁易用。
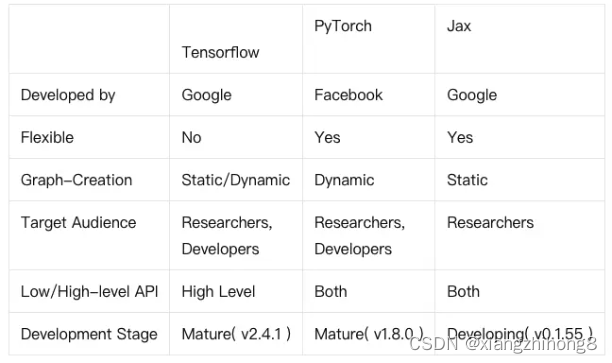
1.2、 JAX 、TensorFlow、PyTorch对比
在深度学习领域,一直都是国外的巨头公司霸占着,比如谷歌的TensorFlow、Facebook 的 PyTorch、微软的 CNTK、亚马逊 AWS 的 MXnet 等。那他们有什么特点呢?下面,我们选取JAX 、TensorFlow、PyTorch进行一下对比。
1.2.1 TensorFlow
TensorFlow 是由谷歌推出的基于数据流编程符号数学系统,被广泛应用在各类机器学习算法的实现中。具有以下特点:
- Tensoflow是一个对用户非常友好的框架。高级 API -Keras 的可用性使模型层定义、损失函数和模型创建变得非常容易。TensorFlow2.0 带有动态图类型,使得该库对用户更加友好,并且是对以前版本的重大升级。
- 由于Keras 的这种高级接口本身的缺陷,所以研究人员在使用自建的模型时自由度降低了。
- TensorFlow 提供的可视化工具包TensorBoard允许用户可视化损失函数、模型图、分析等,提升了交互体验。
因此,如果需要使用深度学习或者部署自己的模型,TensorFlow 可能是一个不错的深度学习框架框架。并且,TensorFlow提供的TensorFlow Lite 版本能将 ML 模型部署到移动和边缘设备,使得移动设备也能进行深度学习。
1.2.2 PyTorch
PyTorch是由Facebook开源的神经网络框架,专门针对 GPU 加速的深度神经网络(DNN)编程。如果说,一两年前大家谈起深度学习还只谈起TensorFlow,那么现在PyTorch也在成为越来越多的开发者的选择。PyTorch具有如下一些特性:
- 与 TensorFlow 不同,PyTorch 使用动态类型图,这意味着执行图是随时随地创建的,它允许开发者随时修改和检查图的内容。
- 除了用户友好的API 之外,PyTorch 还允许对用户的机器学习模型进行越来越多的自定义控制。这样一来,我们可以在训练期间模型的前向和后向传递期间检查和修改输出。
- PyTorch 允许扩展他们的代码,轻松添加新的损失函数和用户定义的层。PyTorch autograd 足够强大,可以通过这些用户定义的层进行区分,用户还可以选择定义梯度的计算方式。
- PyTorch 对数据并行性和 GPU 使用有广泛的支持。
- PyTorch 比 TensorFlow 更 Pythonic。PyTorch 非常适合 python 生态系统,它允许使用 Python 调试器工具来调试 PyTorch 代码。
1.2.3 JAX
JAX是一个来自 Google 的机器学习库,它更像是一个 autograd 库,可以区分每个本机 python 和 NumPy 代码。正如我们所看到的,深度学习只是 JAX 功能的一小部分:

正如官方描述的那样,JAX 能够对 Python+NumPy 程序进行可组合的转换:微分、向量化、JIT 到 GPU/TPU 等等。
下面是JAX的一些特点:
- JAX 能够对 Python+NumPy 程序进行可组合的转换,比如微分、向量化、JIT 到 GPU/TPU 等等。
- 与 PyTorch 相比,JAX 最重要的方面是梯度计算。在 Torch 中,图形是在前向传播期间创建的,而梯度是在后向传播期间计算的。另一方面,JAX的计算被表示为一个函数,使用方面更友好。
- JAX 是一个 autograd 工具,单独使用它几乎不是一个好主意。有各种基于 JAX 的 ML 库,其中值得注意的是 ObJax、Flax 和 Elegy。由于它们都使用相同的核心,并且接口只是 JAX 库的包装器,因此我们将它们放在同一个括号中。
深度学习的成功很大程度上归功于自动分化。TensorFlow和PyTorch等流行库在训练期间跟踪神经网络参数的梯度,两者都包含用于实现深度学习常用神经网络功能的高级 API。JAX是 CPU、GPU 和 TPU 上的 NumPy,对于高性能机器学习研究具有出色的自动区分能力。除了深度学习框架外,JAX 还创建了一个超级精巧的线性代数库,具有自动微分和 XLA 支持。不过,JAX目前仍处于起步阶段,不建议刚开始探索深度学习的人使用,因为它涉及很多的基础函数和理论。
二、环境搭建
2.1 Python环境
Mac上搭建Python环境最好的做法是使用Homebrew来安装,如果你还没有安装Python环境,可以使用下面的命令进行安装。brew search python@3.10 brew install python@3.10- 1
- 2
安装过程中,可能会出现错误,比如Error: No such file or directory @ rb_sysopen,如下:
Pouring sqlite-3.38.5.arm64_monterey.bottle.tar.gz Error: No such file or directory @ rb_sysopen - /Users/xzh/Library/Caches/Homebrew/downloads/062e09dc048eab6bed4b64a9ce0533b08d65775640f901d27e24fd4c1ae640d7--sqlite-3.38.5.arm64_monterey.bottle.tar.gz- 1
- 2
那么,我们只需要按照提示,使用brew install 命令单独安装sqlite即可。安装完成之后,再次运行brew install python@3.10 命令即可。安装完成之后,最好配置下环境变量。
首先,使用
open ~/.bash_profile打开终端工具,然后将下面的代码复制进去。#Setting PATH for Python 3.10 export PATH=${PATH}:/Library/Frameworks/Python.framework/Versions/3.10/bin alias python="/Library/Frameworks/Python.framework/Versions/3.10/bin/python3.10" export PATH=${PATH}:/Library/Frameworks/Python.framework/Versions/3.10/bin alias pip="/Library/Frameworks/Python.framework/Versions/3.10/bin/pip3" export PATH="$PATH:/usr/local/bin/python3.10"- 1
- 2
- 3
- 4
- 5
- 6
配置完成之后,再使用
source ~/.bash_profile命令使配置生效。输入python命令,如果输出如下信息,则说明Python环境安装成功。Python 3.10.5 (v3.10.5:f377153967, Jun 6 2022, 12:36:10) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>- 1
- 2
- 3
2.2 pip工具
pip是 Python包管理工具,提供了对Python 包的查找、下载、安装、卸载的功能。注需要说明的是,Python 2.7.9 + 或 Python 3.4+ 以上版本都自带pip工具,如果是最新的版本无需额外安装。
如果使用pip安装python插件时,提示command not found错误,可以证明你还没有安装pip工具,可以使用下面的命令进行安装。
curl https://bootstrap.pypa.io/get-pip.py | python3- 1
同时,在采用默认 pip3 安装第三方库的时候,经常会出现超时的情况。
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out.- 1
对于这种异常,可以使用国内的镜像源,比如:
- 阿里云:https://mirrors.aliyun.com/pypi/simple/
- 清华:https://pypi.tuna.tsinghua.edu.cn/simple
- 中国科技大学: https://pypi.mirrors.ustc.edu.cn/simple/
当然,我们还可以打开 ~/.pip/pip.conf文件创建自己的配置文件,比如:
mkdir -p ~/.pip cat > ~/.pip/pip.conf<- 1
- 2
- 3
- 4
- 5
- 6
- 7
然后,执行安装如果有下面的提示,则说明镜像源已被替换。
Looking in indexes: https://mirrors.aliyun.com/pypi/simple/- 1
2.3 JAX基本使用
2.3.1 JAX插件安装
经过前面的介绍,我们知道,jax其实就是一个函数库,所以我们使用之前,需要先安装一下jax插件,安装时需要使用pip命令安装,命令如下:
pip install --upgrade pip pip install --upgrade "jax[cpu]"- 1
- 2
关于如何安装,大家可以参考下官方文档的介绍。安装成功之后,会给出成功的提示,如下图。

除了CPU版本外,JAX还支持GPU和TPU,安装的命令如下:
//GPU pip install --upgrade pip pip install --upgrade "jax[cuda]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html //TPU pip install --upgrade pip pip install "jax[tpu]>=0.2.16" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html- 1
- 2
- 3
- 4
- 5
- 6
2.3.2 官方示例工程
JAX 的定位是科学计算(Scientific Computing)和函数转换(Function Transformations),具有除训练深度学习模型以外的一系列能力,具体包括:
- 即时编译(Just-in-Time Compilation)
- 自动并行化(Automatic Parallelization)
- 自动向量化(Automatic Vectorization)
- 自动微分(Automatic Differentiation)
为了方便学习,我们最好下载下官网的示例工程并运行,示例工程代码结构如下:

2.3.3 在线编程平台jupyter
Jupyter 是一款开放性的代码编写软件,最大的特点是能够实时运行代码,查看输出效果。同时该软件集成了多种插件,能够实现非常复杂的功能。对于初学者而言,因为Jupyter具有良好的交互性,方便看到每一行、每一个代码块的输出结果,Jupyter成为众多Python初学者的青睐。

同时,Jupyter提供了用 JupyterLab 和 Jupyter Notebook 等交互式编写软件的技术方式,能够更好的帮助开发者编写、运行代码。其中,安装JupyterLab命令如下:
pip3 install jupyterlab //启动命令 jupyter-lab- 1
- 2
- 3
安装完成之后,在使用jupyter-lab即可启动。如果是安装Jupyter Notebook,那么安装的命令如下:
pip3 install notebook //启动命令 jupyter notebook- 1
- 2
- 3
启动成功之后,会自动打开http://localhost:8888/tree页面,如下图。
然后,我们点击右上角的【新建】按钮新建一个运行面板,如下图。
接下来,我们就可以在上面运行一些函数。当然,Jupyter还提供了在线编辑运行平台,可以帮助开发者快速的体验Jupyter的魅力,目前支持主流的编程语言和技术。
如果要运行项目,可以使用【Ctrol】+回车即可得到运行结果。比如生成随机数据:
key = random.PRNGKey(0) x = random.normal(key, (10,)) print(x)- 1
- 2
- 3
当我们【Ctrol】+回车运行项目时,得到的结果如下:
[-0.3721109 0.26423115 -0.18252768 -0.7368197 -0.44030377 -0.1521442 -0.67135346 -0.5908641 0.73168886 0.5673026 ]- 1
- 2
其中,比较常用的快捷键有如下一些:
- Tab : 代码补全或缩进
- Shift-Tab : 提示
- Ctrl-A : 全选
- Ctrl-Z : 复原
- Ctrl-Shift-Z : 再做
- Ctrl-Y : 再做
- Ctrl-Backspace : 删除前面一个字
- Ctrl-Delete : 删除后面一个字
- Esc : 进入命令模式
- Ctrl-M : 进入命令模式
- Shift-Enter : 运行本单元,选中下一单元
- Ctrl-Enter : 运行本单元
- Alt-Enter : 运行本单元,在下面插入一单元
- Ctrl-Shift-- : 分割单元
- Ctrl-Shift-Subtract : 分割单元
- Ctrl-S : 文件存盘
- Shift : 忽略
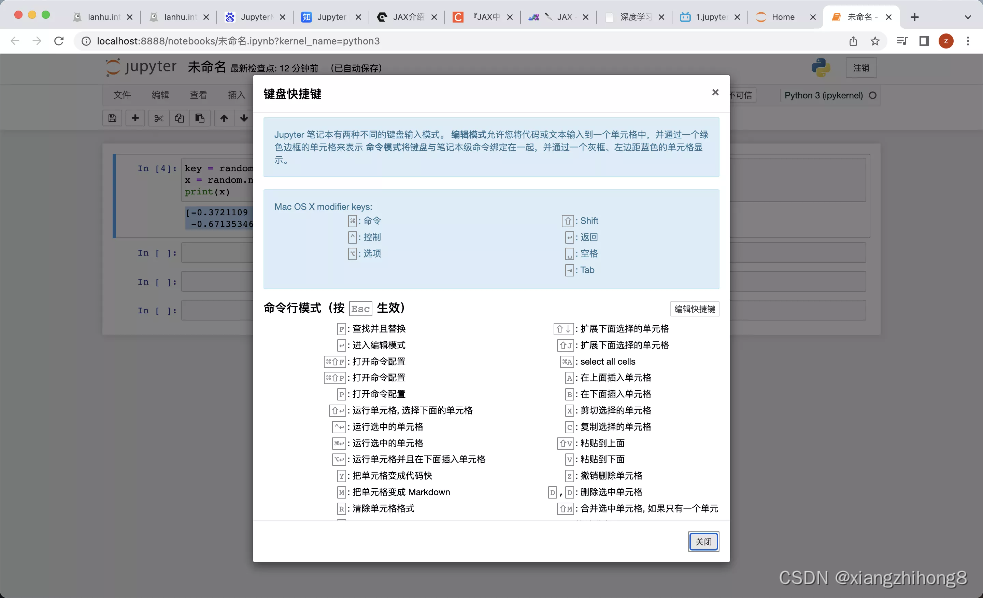
其他常用的快捷键,可以通过帮助选项来进行查看,如下图。
2.3.4 基本使用
随机函数
和编写其他python的语法一样,使用Jax之前需要导入相关的函数包。比如,我们使用NumPy执行一些基准测试,比如:
import jax import jax.numpy as jnp from jax import random from jax import grad, jit import numpy as np key = random.PRNGKey(0)- 1
- 2
- 3
- 4
- 5
- 6
当然,我们也可以
import jax.numpy as jnp并将代码中的所有 np 替换为 jnp 。与NumPy 代码风格不同,在JAX 代码中,可以直接使用import方式导入并直接使用。可以看到,JAX 中随机数的生成方式与 NumPy 不同。JAX需要创建一个 jax.random.PRNGKey 。矩阵乘法
我们在 Google Colab 上做一个简单的基准测试,这样我们就可以轻松访问 GPU 和 TPU。我们首先初始化一个包含 25M 元素的随机矩阵,然后将其乘以它的转置,使用针对 CPU 优化的 NumPy,矩阵乘法平均需要408 ms ± 35.9 ms。
size = 5000 x = np.random.normal(size=(size, size)).astype(np.float32) %timeit np.dot(x, x.T) # 408 ms ± 35.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)- 1
- 2
- 3
- 4
- 5
在 CPU 上使用 JAX 执行相同的操作平均需要大约 716 ms ± 13.7 ms。
size = 5000 x = random.normal(key, (size, size), dtype=jnp.float32) %timeit jnp.dot(x, x.T).block_until_ready() # 716 ms ± 13.7 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)- 1
- 2
- 3
- 4
- 5
在 CPU 上运行时,JAX 通常比 NumPy 慢,因为 NumPy 已针对CPU进行了非常多的优化。但是,当使用加速器时这种情况会发生变化,所以让我们尝试使用 GPU 进行矩阵乘法。
size = 5000 x = random.normal(key, (size, size), dtype=jnp.float32) %time x_jax = jax.device_put(x) %time jnp.dot(x_jax, x_jax.T).block_until_ready() %timeit jnp.dot(x_jax, x_jax.T).block_until_ready() # CPU times: user 50 µs, sys: 1 µs, total: 51 µs # Wall time: 53.9 µs # CPU times: user 5.14 s, sys: 44.9 ms, total: 5.19 s # Wall time: 732 ms # 725 ms ± 25.1 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
接下来,让我们使用 TPU 来进行矩阵乘法。
size = 5000 x = random.normal(key, (size, size), dtype=jnp.float32) %time x_jax = jax.device_put(x) %time jnp.dot(x_jax, x_jax.T).block_until_ready() %timeit jnp.dot(x_jax, x_jax.T).block_until_ready() # CPU times: user 54 µs, sys: 916 µs, total: 970 µs # Wall time: 973 µs # CPU times: user 5.25 s, sys: 34.2 ms, total: 5.28 s # Wall time: 709 ms # 715 ms ± 3.95 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,忽略设备传输时间和编译时间,每个矩阵乘法平均需要715 ms ± 3.95 毫秒,与GPU 相比,TPU快了差不多4倍。需要说明的是,当乘以不同大小的矩阵时,获得相同的加速效果也不同:相乘的矩阵越大,GPU可以优化操作的越多,加速也越大。
jit()
JAX在GPU上是透明运行的。但是,在上面的示例中,JAX一次将内核分配给GPU一次操作,如果我们有一系列操作,则可以使用@jit装饰器使用XLA一起编译多个操作。
def selu(x, alpha=1.67, lmbda=1.05): return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha) x = random.normal(key, (1000000,)) %timeit selu(x).block_until_ready() #1.64 ms ± 91 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以使用加快速度@jit,它将在第一次selu调用jit-compile并将其之后缓存。
def selu(x, alpha=1.67, lmbda=1.05): return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha) selu_jit = jit(selu) %timeit selu_jit(x).block_until_ready() #455 µs ± 151 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到,使用jit装饰器后,运行效率明显提高。
grad()
除了评估数值函数外,我们还希望对值进行转换,其中一种转变是自动微分。在JAX中,就像在Autograd中一样,可以使用grad()函数来进行梯度计算。
def sum_logistic(x): return jnp.sum(1.0 / (1.0 + jnp.exp(-x))) x_small = jnp.arange(3.) derivative_fn = grad(sum_logistic) print(derivative_fn(x_small)) # [0.25 0.19661197 0.10499357]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
接下来,让我们使用极限微分来验证我们的结果是否正确。
def first_finite_differences(f, x): eps = 1e-3 return jnp.array([(f(x + eps * v) - f(x - eps * v)) / (2 * eps) for v in jnp.eye(len(x))]) print(first_finite_differences(sum_logistic, x_small)) # [0.24998187 0.1964569 0.10502338]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
求解梯度可以通过简单调用grad()。grad()并jit()可以任意混合。在上面的示例中,我们先抖动sum_logistic然后取其派生词。
def first_finite_differences(f, x): eps = 1e-3 return jnp.array([(f(x + eps * v) - f(x - eps * v)) / (2 * eps) for v in jnp.eye(len(x))]) print(grad(jit(grad(jit(grad(sum_logistic)))))(1.0)) //-0.035325598- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
vmap()
JAX在其API中还有另一种转换,那就是vmap()向量化映射。它具有沿数组轴映射函数的熟悉语义,但不是将循环保留在外部,而是将循环推入函数的原始操作中以提高性能。当与组合时jit(),它的速度可以与手动添加批处理尺寸一样快。
mat = random.normal(key, (150, 100)) batched_x = random.normal(key, (10, 100)) def apply_matrix(v): return jnp.dot(mat, v) print(apply_matrix(100))- 1
- 2
- 3
- 4
- 5
- 6
- 7
给定功能apply_matrix,然后在Python中循环执行批处理维度,但是这样做的性能通常很差。
def naively_batched_apply_matrix(v_batched): return jnp.stack([apply_matrix(v) for v in v_batched]) print('Naively batched') %timeit naively_batched_apply_matrix(batched_x).block_until_ready() #Naively batched # 433 µs ± 2.02 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果,我们使用vmap()自动添加批处理支持,那效率就提高不少。
@jit def vmap_batched_apply_matrix(v_batched): return vmap(apply_matrix)(v_batched) print('Auto-vectorized with vmap') %timeit vmap_batched_apply_matrix(batched_x).block_until_ready() # Auto-vectorized with vmap # 13.5 µs ± 19.4 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
事实上,vmap()可以与任意组成jit(),grad()和任何其它JAX变换。当然,JAX的函数还有很多,大家可以查看官方资料进行学习。
三、XLA架构
XLA 是 JAX(和其他库,例如 TensorFlow,TPU的Pytorch)使用的线性代数的编译器,它通过创建自定义优化内核来保证最快的在程序中运行线性代数运算。XLA 最大的好处是可以让我们在应用中自定义内核,该部分使用线性代数运算,以便它可以进行最多的优化。
在TensorFlow中,XLA给TensorFlow带来了如下提升:
- 提高执行速度。编译子计算图以减少短暂运算的执行时间,从而消除 TensorFlow 运行时的开销;融合流水线运算以降低内存开销;并针对已知张量形状执行专门优化以支持更积极的常量传播。
- 提高内存使用率。分析和安排内存使用量,原则上需要消除许多中间存储缓冲区。
- 降低对自定义运算的依赖。通过提高自动融合的低级运算的性能,使之达到手动融合的自定义运算的性能水平,从而消除对多种自定义运算的需求。
- 减少移动资源占用量。通过提前编译子计算图并发出可以直接链接到其他应用的对象/头文件对,消除 TensorFlow 运行时。这样,移动推断的资源占用量可降低几个数量级。
- 提高便携性。使针对新颖硬件编写新后端的工作变得相对容易,在新硬件上运行时,大部分 TensorFlow 程序都能够以未经修改的方式运行。与针对新硬件专门设计各个整体运算的方式相比,这种模式不必重新编写 TensorFlow 程序即可有效利用这些运算。
不过,XLA 最重要的优化是融合,即可以在同一个内核中进行多个线性代数运算,将中间输出保存到 GPU 寄存器中,而不将它们具体化到内存中。这可以显着增加我们的“计算强度”,即所做的工作量与负载和存储数量的比例。融合还可以让我们完全省略仅在内存中shuffle 的操作(例如reshape)。
下面我们看看如何使用 XLA 和 jax.jit 手动触发 JIT 编译。
使用 jax.jit 进行即时编译
这里有一些新的基准来测试 jax.jit 的性能。我们定义了两个实现 SELU(Scaled Exponential Linear Unit)的函数:一个使用 NumPy,一个使用 JAX。
def selu_np(x, alpha=1.67, lmbda=1.05): return lmbda * np.where(x > 0, x, alpha * np.exp(x) - alpha) def selu_jax(x, alpha=1.67, lmbda=1.05): return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha) x = np.random.normal(size=(1000000,)).astype(np.float32) %timeit selu_np(x) # 7.56 ms ± 18.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以看到,NumPy平均需要 7.6 毫秒。接下来,让我们在 CPU 上使用 JAX运行,如下。
def selu_np(x, alpha=1.67, lmbda=1.05): return lmbda * np.where(x > 0, x, alpha * np.exp(x) - alpha) def selu_jax(x, alpha=1.67, lmbda=1.05): return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha) x = random.normal(key, (1000000,)) %time selu_jax(x).block_until_ready() %timeit selu_jax(x).block_until_ready() # CPU times: user 5.27 ms, sys: 2.7 ms, total: 7.97 ms # Wall time: 3.57 ms # 1.7 ms ± 94.6 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
可以看到,这种情况下,JAX明显要比 NumPy 快。下一个测试是在 GPU 上使用 JAX。
x = random.normal(key, (1000000,)) %time x_jax = jax.device_put(x) %time selu_jax(x_jax).block_until_ready() %timeit selu_jax(x_jax).block_until_ready() # CPU times: user 54 µs, sys: 39 µs, total: 93 µs # Wall time: 96.1 µs # CPU times: user 2.27 ms, sys: 1.3 ms, total: 3.57 ms # Wall time: 1.71 ms # 1.63 ms ± 45.9 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
可以看到,函数运行时间为1.63毫秒。下面我们用 jax.jit 测试它,触发 JIT 编译器使用 XLA 将 SELU 函数编译到优化的 GPU 内核中,同时优化函数内部的所有操作。
x = random.normal(key, (1000000,)) selu_jax_jit = jit(selu_jax) %time x_jax = jax.device_put(x) %time selu_jax_jit(x_jax).block_until_ready() %timeit selu_jax_jit(x_jax).block_until_ready() # CPU times: user 114 µs, sys: 305 µs, total: 419 µs # Wall time: 426 µs # CPU times: user 30.2 ms, sys: 7.86 ms, total: 38.1 ms # Wall time: 36.5 ms # 361 µs ± 10.1 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,使用编译内核,函数运行时间为0.36毫秒。之所以能带来如此大的性能提升,是因为使用 JIT 编译避免从 GPU 寄存器中移动数据,从未带来了非常大的加速。一般来说在不同类型的内存之间移动数据与代码执行相比非常慢,因此在实际使用时应该尽量避免。
将 SELU 函数应用于不同大小的向量时,您可能会获得不同的结果。矢量越大,加速器越能优化操作,加速也越大。除了执行 selu_jax_jit = jit(selu_jax) 之外,还可以使用 @jit 装饰器对函数进行 JIT 编译,如下所示。
@jit def selu_jax_jit(x, alpha=1.67, lmbda=1.05): return lmbda * jnp.where(x > 0, x, alpha * jnp.exp(x) - alpha)- 1
- 2
- 3
JIT 编译可以加速,为什么我们不能全部都这样做呢?因为并非所有代码都可以 JIT 编译,JIT要求数组形状是静态的并且在编译时已知。另外就是引入jax.jit 也会带来一些开销。因此通常只有编译的函数比较复杂并且需要多次运行才能节省时间。
参考链接:
https://jax.readthedocs.io/en/latest/installation.html
https://github.com/google/jax
8月3日第壹简报,星期三,农历七月初六
2024版彩虹晴天全能知识付费源码+虚拟商城解决方案 含一键搭建视频教程 无授权限制
⑦【MySQL】什么是约束?如何使用约束条件?主键、自增、外键、非空....
PostgreSQL的扩展(extensions)-常用的扩展之pg_stat_statements
【CSS3入门指北】基础篇
软件工程毕业设计课题(28)基于JAVA毕业设计JAVA教室实验室预约系统毕设作品项目
消息对话框
【MCS-51】中断系统原理及应用
3dmax如何在渲染完之后加载VFB的参数和LUT文件?