-
机器学习强基计划0-2:什么是机器学习?和AI有什么关系?
0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。
🚀详情:机器学习强基计划
1 什么是机器学习?
摆在最前面的问题是:机器学习这么一个高大上的概念到底是什么?和传统编程逻辑有什么区别?
1.1 定义
用一句话概括:机器学习是致力于研究如何通过计算的手段,利用经验产生模型以改善系统自身性能的学科
这里面有几个抽象的概念,什么是经验?什么是模型?怎么才算改善系统自身性能?接下来通过一个例子来具象化地说明一下。
在经济学中,个人的收入与消费之间存在着密切的关系。收入越多,消费水平也越高;收入较少,消费水平也较低。从一个社会整体来看,个人的平均收入x与平均消费y之间大致呈线性关系。现在我们看看路人甲的收入和消费水平的关系
收入x 消费水平y 1.0 0.5 1.2 0.8 1.5 1.3 现在的问题是:请问在一个社会中,收入水平为1.5的人群,消费水平如何?
首先,把路人甲的数据放在坐标系里可视化一下
在中学阶段,我们学过一个概念,叫线性最小二乘法,它的实现思路是:首先给出一个点集,然后用一条直线去拟合这个点集,使所有点到这条直线的距离最小——误差最小。现在让我们做出这样一条直线。

得出的这条直线能干嘛呢?能用来预测!我们现在可以根据这条直线来判断任意收入水平下,你的消费水平如何。
在这个例子中,这三个点就是经验,我们是根据路人甲已有的经验来预测的,在机器学习中,经验表现为数据;而这条直线就叫模型,模型体现的是数据内部蕴含的潜在模式和规律。
有人会说,你这也太扯淡了,就用一个人的三个数据就能做收入水平预测这么大的课题?
确实是这样,所以机器学习需要的数据量是非常大的,只有在大数据的支持下,得到的模型才有实际意义。比如说,我们又采样了一部分人群的数据,得到的结果如下
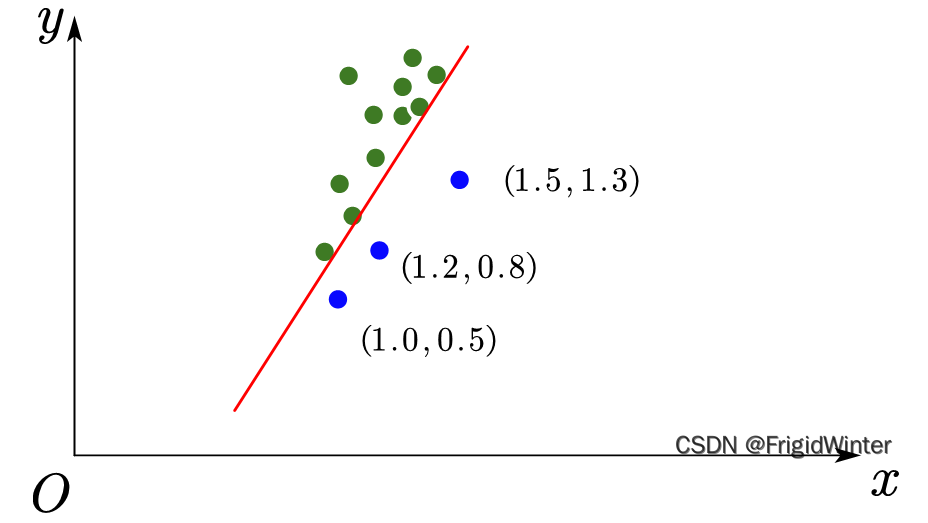
再次应用最小二乘法,我们发现直线变了。数据量越大、质量越高,其现实意义越强、偶然性越小。所以机器学习模型就会随之变得有效(称为泛化性,但这个概念后面再说),我们可以认为系统性能得到了改善。这是符合我们人类认知规律的!随着我们经历的事情越来越多,阅历也就是经验越来越丰富,对事物的认识也越来越深刻。可能过去我们对某个事物的错误认识,会在接下来的人生阶段得到纠正,这就是机器学习的道理。
事实上,我们在高中就接触机器学习了,上面说的最小二乘法就是后面介绍线性回归等模型的理论基础!
所以机器学习的概念实质上并没有想象得那么高大上,就是机器模仿人的学习,从数据内部获得潜在客观规律的过程。
1.2 编程逻辑
前面说到数据和经验的概念,这实际上属于统计意义。
什么意思呢?就是世间的数据是不能穷尽的,总有可能出现一两个个例,但我们只要在统计意义上,有足够概率的把握说明模型符合认知就足够了。
所以概率统计的思想会贯穿机器学习始终。传统上如果我们通过输入确定性的指令让计算机工作,这是因果确定的,但在机器学习中,我们输入的是测试数据,得出的是最大概率的预测,比如上面那个收入消费的例子,假设收入1.5,模型告诉我消费1.2,那难道所有人就都是1.2的消费水平吗?并不是,只是大概率在1.2的水平附近。
另外,机器学习内部的运算过程也充满了随机性,特别是以概率图模型为基础的各大算法,本节作为开篇,暂时避免引入晦涩的概念。
所以机器学习在编程上的随机性有别于传统编程的确定性。
2 机器学习与AI的关系
2.1 人工智能三大学派
纵观人工智能发展历史,有三个主流的学术研究流派。
- 符号主义学派
符号主义学派认为:任何能够将某些模式或符号进行操作并转化成另外一些模式或符号的系统就可能产生智能行为。符号主义的核心是数理逻辑,关注的是人类智能的高级行为,比如推理、规划、知识表示等,致力于用计算机的符号操作来模拟人的认知过程和抽象逻辑思维。 - 连接主义学派
连接主义学派认为:人脑中万亿个神经元细胞间错综复杂的互相连接,是智能产生的来源。连接主义的核心是仿生学和神经科学,关注的是神经网络间的连接机制和学习算法,致力于通过计算机表示大量神经元,以模拟大脑的智力。 - 行为主义学派
行为主义学派认为:智能行为是个体用于适应环境变化的、各种身体反应的组合。行为主义的核心是控制理论,关注的是一种基于“感知-行动”的行为智能模拟方法,致力于预见和控制行为。
2.2 机器学习在AI中
人工智能是个非常庞大的概念,涉及到非常多的内容:计算机视觉、自然语言处理、机器学习、深度学习、机器人控制等等,这些内容彼此也会交叉,互相涉及,总的来说,机器学习是人工智能的一个分支学科
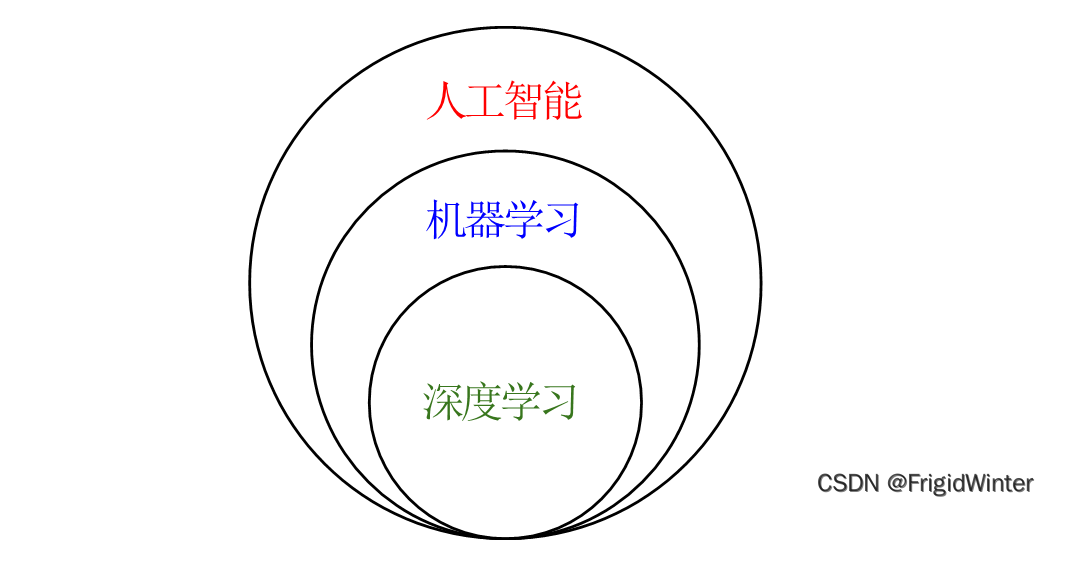
深度学习以神经网络为核心,而神经网络是机器学习的基本模型之一,简单理解,深度学习是堆叠了很多层网络的机器学习。
3 机器学习能干什么?
机器学习可以应用领域十分广阔,比如医疗健康、商业服务、消费零售、金融、机器人、农业、教育、律师法务、媒体社交、汽车交通、智能家居、通讯服务、城市公共、旅游等各个领域。
- 搜索引擎
- 推荐系统(抖音给你推什么内容,你写的文章为什么能上热榜)
- 辅助决策
- 医疗机器人
- 智能穿戴
- …

4 学习路线
花了这么长的篇幅介绍机器学习的概念和用途,接下来是最重要的,机器学习该怎么学?
我们定位在从事创新性工作,而非重复采用前人已有的模型。要做到这一点,必须对模型的原理理解透彻,这样才能知道模型有什么缺陷,要如何改进,如何创造自己的模型。
这也是机器学习强基计划的初衷,我们通过探索模型背后的数学原理,来从本质上看出模型的优劣,有哪些限制条件,模型改进的思路是什么,争取不停留在表面。
-
第一阶段:基本工具
掌握一门编程语言,推荐以python入门。机器学习作为应用型学科,最终必定要落实到编程。机器学习算法推导需要一定数学基础,大概有三个方向的内容:- 概率论
- 线性代数
- 最优化
部分模型还会涉及到图论、泛函分析等学科的一些理论。不了解的可以先稍微了解下这三门数学的基础概念,或者跟着本专栏用到什么学什么。对数学学习程度要求不高,只需要用数学定理证明机器学习理论即可,不需要深究这些数学定理是怎么来的。
-
第二阶段:机器学习基本模型
在理论层面上学习机器学习模型,站在巨人的肩膀上,了解前人的思想和机器学习面对的基本问题- 数据集如何划分
- 模型之间的关联和区别是什么?
- 如何提高模型泛化能力?
- 如何根据场景选择模型
- …
在机器学习理论方面推荐三本教材:《Deep Learning》、《统计机器学习 李航》、《机器学习 周志华》
-
第三阶段:结合具体应用方向
本专栏以第一阶段为基础,定位在第二阶段,争取讲清楚教材中一笔带过却又令人匪夷所思的细节。
本期图书推荐
《神经网络与深度学习:案例与实践》

【书籍简介】
- 本书主要介绍神经网络与深度学习中的基础知识、主要模型(卷积神经网络、递归神经网络等)以及在计算机视觉、自然语言处理等领域的应用。
- 学完本书,读者将掌握与深度学习相关的网络结构、处理方法等关键概念。
【抽奖方式】
- 关注博主,点赞收藏文章,并做出有效评论
- 根据评论记录随机抽取2位用户赠送实体图书
- 截止日期:7.24日晚8点,届时通过blink公布获奖信息,请中奖用户及时私信
🔥 更多精彩专栏:
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇 - 符号主义学派
-
相关阅读:
【数据挖掘工程师-笔试】2022年大华股份
python爬虫入门教程(非常详细):如何快速入门Python爬虫?
树和二叉树
Ardupilot — EKF3使用光流室内定位代码梳理
Leetcode 349.两个数组的交集
C# dll代码混淆加密
如何化解35岁危机?华为云数据库首席架构师20年技术经验分享
链表(三)——链表中的经典算法
力扣第347题 堆(优先队列) 经典题 c++ 简易注释版 附(相关知识点解答)
26 docker前后端部署
- 原文地址:https://blog.csdn.net/FRIGIDWINTER/article/details/125802637