-
对自己LRU算法代码的优化
今天我翻了翻自己之前的博客,然后对想回顾一下自己LRU算法,附上链接:
https://blog.csdn.net/qq_42627977/article/details/119045646#comments_17685616
附上需要优化代码:
//获取元素 public int get(int key) { //从map中获取元素 DLinkedNode node = map.get(key); if(node == null) return -1; //获取到元素以后,该元素刚刚使用,所以将该节点移动到头部 moveToHead(node); return node.value; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我之前是用HashMap保存了key为查找元素,vlaue为链表的node节点,当链表节点被删除时,我们应该将HashMap中的元素删除,附上代码:
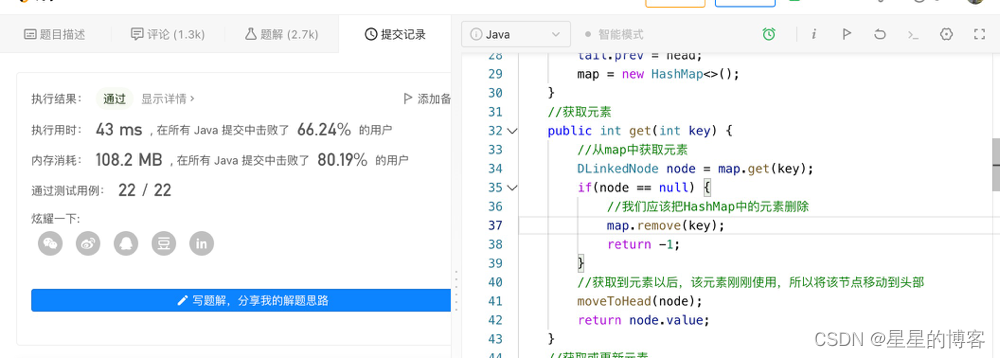
//获取元素 public int get(int key) { //从map中获取元素 DLinkedNode node = map.get(key); if(node == null) { //我们应该把HashMap中的元素删除 map.remove(key); return -1; } //获取到元素以后,该元素刚刚使用,所以将该节点移动到头部 moveToHead(node); return node.value; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
为了验证是否正确,我重新在leetcode上做了测试,结果成功。
附上图:
-
相关阅读:
CV学习——day32 读论文:顶会ICCV · 会议CV——2021 Swin Transformer
【问题记录】一次由filter引发的血案,如何定位上游链路的问题,问题排查与定位思路分享
基于Python的发票OCR-数字识别的简单实现
java基础(面向对象,异常,类,抽象类,继承类,构造方法,接口,string类,==和equals,修饰符final,static,重写和重载)
C语言解决逻辑分析题(猜凶手)(猜名次)
【算法|前缀和系列No.3】leetcode LCR 012. 寻找数组的中心下标
简单有效的记录日常收支
go语言tcp协议实现文件上传
设计模式介绍
Flutter 教程之如何从头开始设置 Flutter(2022 mac 版)
- 原文地址:https://blog.csdn.net/qq_42627977/article/details/125909007