-
Hexagon_V65_Programmers_Reference_Manual(5)
4.3 XTYPE 操作
XTYPE指令类包括执行的大多数数据处理操作,通过Hexagon处理器,这些操作按其操作类型分类:
- 算术逻辑单元
- 位操作
- 复数
- 浮点数
- 乘法
- 置换
- 断言
- 转换
4.3.1 算术逻辑单元
ALU操作修改8位、16位、32位和64位数据。这些操作包括:
- 有饱和和无饱和的加法和减法
- 用累加进行加减
- 绝对值
- 逻辑运算
- 最小、最大、否定指令
- 64位数据的寄存器传输
- 字到双字符号扩展
- 比较
有关更多信息,请参阅第11.1.1节和第11.10.1节。- 1
4.3.2 位操作
位操作操作修改寄存器或寄存器对中的位字段。这些操作包括:
- 位字段插入
- 位字段有符号和无符号提取
- 计数前导位和尾随位
- 比较位掩码
- 设置/清除/切换位
- 测试位操作
- 交织/解交织位
- 位反转
- 拆分位字段
- 掩蔽奇偶校验和线性反馈移位
- 表索引形成
有关更多信息,请参阅第11.10.2节- 1
4.3.3 复数
复数运算处理复数。这些操作包括:
- 复数加减
- 复数乘法,可选圆形和压缩
- 向量复数乘法
- 向量复共轭
- 向量复数旋转
- 向量约化复数乘实或虚
有关更多信息,请参阅第11.10.3节- 1
4.3.4 浮点数
浮点运算处理单精度浮点数。这些操作包括:
- 加减法
- 乘法(可选缩放)
- 最小/最大/比较
- 格式转换
Hexagon处理器的浮点运算符合IEEE标准。但是例如IEEE的某些要求不被直接支持,例如除法和平凡根。取而代之的是我们定义了特殊的指令来支持实现这些操作所需要的库,例如:
- 融合乘法加法指令的特殊版本(专门为在库例程中使用)
- 倒数/平方根近似(计算近似初始值倒数和倒数平方根例程中使用的值)
- 极值辅助(如果输入值不能产生,则调整输入值使用收敛算法更正结果
有关更多信息,请参阅第11.10.4节- 1
注意:特殊浮点指令不直接用于用户代码–它们只能在浮点库中使用- 1
格式转换
浮点转换指令sfmake和dfmake转换无符号10位立即数值转换为相应的浮点值。
必须对立即值进行编码,使位[5:0]包含有效位,位[9:6]指数将指数值添加到初始指数值(偏差 - 6)。
例如,要生成单精度浮点值2.0,位[5:0]必须为设置为0,位[9:6]设置为7。对该立即值执行sfmake得到浮点值0x40000000,即2.0注意:转换指令旨在处理常见的浮点值,包括大多数整数和许多基本分数(1/2、3/4等)。- 1
四舍五入
Hexagon 用户状态寄存器(第2.2.3节)包括FPRND字段,用于指定IEEE定义的浮点舍入模式
例外情况
Hexagon用户状态寄存器(第2.2.3节)包括五个状态字段,作为IEEE定义的五种异常条件的粘性标志:不精确、溢出、下溢、除以零和无效。当相应的异常发生时,设置粘性标志,并保持设置,直到显式清除。
用户状态寄存器还包括五个模式字段,用于指定如果其中一个浮点异常,则应执行操作系统陷阱发生。对于包含浮点操作的每个指令包,如果同时设置了浮点粘性标志和相应的陷阱启用位,则为浮点陷阱生成。在数据包提交后,Hexagon处理器会自动扔给操作系统。
注意:非浮点指令从不生成浮点陷阱,不管粘性标志和陷阱启用位的状态如何- 1
4.3.5 乘法
乘法运算支持定点乘法,包括
单精度乘法和双精度乘法以及多项式乘法。单精度
在单精度算术中,一个16位值乘以另一个16位值。这些操作数可以来自任何寄存器的高位或低位。取决于指令,16的结果 16操作可以选择累加、饱和、舍入或左移0-1位。
指令集支持对 有符号 x 有符号、无符号 x 无符号,有符号 x 无符号数据。表 4-1 总结了 16 x 16 单精度乘法的可用操作。
表中使用的符号如下:- SS – 执行
有符号 x 有符号乘法 - UU – 执行
无符号 x 无符号乘法 - SU – 执行
有符号 x 无符号乘法 - A+ – 结果添加到累加器
- A- – 从累加器中减去的结果
- 0 – 结果未添加到累加器
表4-1 单精度乘法操作

双精度
双精度指令可用于
32 x 32和32 x 16乘法:- 对于32 x 32乘法结果可以是64位或32位。32位结果可以是64位乘积的高或低部分。
- 对于32 x 16乘法结果始终作为高32位。
操作数可以是有符号的,也可以是无符号的。
表4-2总结了双精度乘法中可用的选项表4-2 双精度乘法操作

多项式
多项式乘法指令可用于字和向量半字。
这些指令对许多算法都很有用,包括扰码生成,密码算法、卷积码和里德-所罗门码。有关乘法运算的更多信息,请参阅第11.10.5节4.3.6 置换
置换操作对矢量数据执行各种操作,包括算术、格式转换和矢量元素的重新排列。
多种类型的转换可支持:- 旋转字节
- 矢量洗牌
- 矢量对齐
- 矢量饱和和压缩
- 向量splat字节
- 矢量拼接
- 矢量符号扩展半字
- 矢量零扩展字节
- 向量零扩展半字
- 标量饱和到字节、半字、字
- 向量包高半字和低半字
- 矢量圆形和压缩
- 向量splat半字
有关更多信息,请参阅第11.1.2节和第11.10.6节。4.3.7 断言
断言操作修改断言源数据。可用声明的类别包括:
- 矢量掩码生成
- 断言传输
- 维特比填料
有关更多信息,请参阅第11.1.3节和第11.10.7节4.3.8 转换
标量移位操作执行各种32位和64位移位,然后执行可选的添加/订阅或逻辑操作。图4-4显示了常规操作
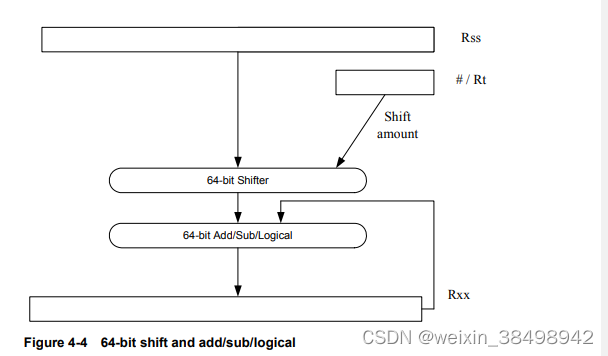
图 4-4
支持四种换档类型:- ASR–算术右移
- ASL–算术左移
- LSR–逻辑右移
- LSL–逻辑左移
在基于寄存器的移位中,Rt寄存器是一个有符号的二补数。如果此值为正,则指令操作码指示移位方向(向右或向左)。如果这个值为负,则操作码指示的移位方向反转。
当执行算术右移时,符号位移入,而逻辑右移移位以零移位。左移位总是以零移位。
有些偏移可以使用饱和度和舍入选项。
有关更多信息,请参阅第11.10.8节4.4 计算逻辑单元(ALU)32 操作
ALU32指令类包括对32位数据的一般算术/逻辑运算:
- 对32位数据进行不饱和的加、减、反运算
- 逻辑运算,如立即的AND、OR、XOR、AND 、立即的 OR
- 标量32位比较
- 组合半词,组合词,组合立即词,移位半词,和多路复用器
- 有条件的加法、组合、逻辑、减法和转移。
- NOP
- 有符号和零扩展字节和半字
- 转移即使变量和寄存器
- 向量加、减和平均半字
关更多信息,请参阅第11.1节。
注ALU32指令可以在任何插槽上执行(第3.3.3节)。第6章描述了条件执行和比较指令- 1
4.5 矢量运算
矢量运算支持对字节、半字和字的向量进行算术运算。
向量运算属于XTYPE指令类(除了向量加法,减法和平均半字,即ALU32)。向量字节运算
向量字节操作处理有符号或无符号字节的压缩向量。他们包括以下操作:
- 矢量加减有符号或无符号字节
- 向量最小和最大有符号或无符号字节
- 矢量比较有符号或无符号字节
- 矢量平均无符号字节
- 矢量减少添加无符号字节
- 无符号字节绝对差向量和
矢量半字运算
矢量半字运算处理压缩16位半字。它们包括以下操作:
- 向量加减半字
- 向量平均半字
- 向量比较半字
- 向量最小和最大半字
- 向量移位半字
- 向量对偶乘法
- 带圆形和压缩的向量对偶乘法
- 矢量乘法偶数半字,可选四舍五入和压缩
- 向量乘法半字
- 矢量减法乘法半字
例如,图4-5显示了向量算术右半字移位的操作(vasrh)说明。在该指令中,每个16位半字右移相同的长度在寄存器中指定或具有立即数的量。因为这个转变是算术中,移入的位是符号位的副本。
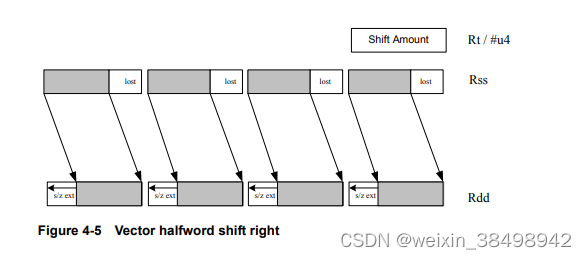
向量字运算
向量字运算处理两个字的压缩向量。它们包括以下操作:
- 向量加减词
- 向量平均字
- 向量比较词
- 向量最小和最大字
- 具有可选截断和压缩的向量移位字
有关矢量运算的更多信息,请参阅第11.1.1节和第11.10.1节4.6 CR 运算
CR指令类包括访问控制寄存器的操作(第2.2节)。
表4-3列出了访问控制寄存器的指令。

注:在寄存器对传输中,必须使用其数字别名–有关详细信息,请参阅第2.2节。 有关更多信息,请参阅第11.2节4.7 复合作业
指令集包括许多执行多个逻辑或的指令
单个指令中的算术运算。它们包括以下操作:- 和/或反向输入
- 复合逻辑寄存器
- 复合逻辑断言
- 带立即数的复合加减法
- 即时复合移位运算(算术或逻辑)
- 直接乘法加法
有关更多信息,请参阅第11.10.1节4.8 特殊运算
指令集包括许多专用指令,以支持特定的应用:
- H.264 CABAC处理
- IP internet校验和
- 基于软件的无线电
4.8.1 H.264 CABAC处理
H.264/AVC被广泛应用于各种多媒体应用中:
- 高清DVD
- HDTV广播
- 互联网视频流
上下文自适应二进制算术编码(CABAC)是两种备选方案之一H.264主配置文件中规定的熵编码方法。CABAC提供卓越的以更大的计算复杂度为代价提高编码效率。Hexagon处理器包括一个专用指令(decbin),以支持CABAC解码。
二进制算术编码基于递归区间细分原理,其状态由两个量表示:
- 当前间隔范围
- 当前代码间隔中的当前偏移量
从编码比特流读取偏移量。解码箱子时,间隔范围为根据LPS概率PLP的估计细分为两个区间:一个宽度为rLPS=范围x pLPS的间隔,以及宽度为rMPS=范围x的间隔pMPS=范围-rLPS,其中LPS表示最小可能符号,MPS表示最大可能符号
可能符号。根据偏移量属于哪个子区间,解码器决定是否使用二进制编码解码为MPS或LPS,然后迭代更新这两个量,如图4-1中所示

4.8.1.1 CABAC 实现
在H.264中,偏移量为9位,在常规模式下为9位,在旁路模式下为10位模式。rLPS的计算近似为64×4 256字节的表格,其中范围和上下文状态(为要访问的bin选择解码)用于处理查找表。保持整体精度解码过程中,必须对新的范围进行重整,以确保最显著的位始终为1,偏移量从位流同步重新填充。
为了简化重整化/重新填充过程,中所示的解码方案图4-2是为了显著降低重整化频率和从位流中重新填充位,同时也适用于DSP实现。
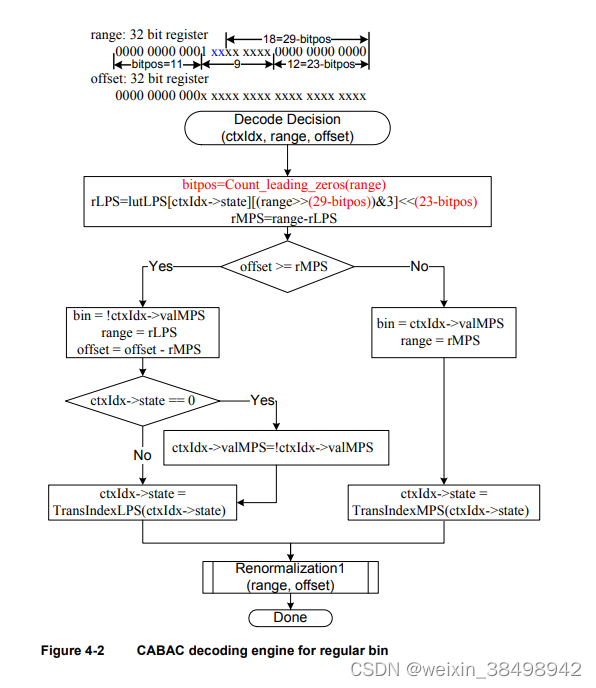
通过使用decbin指令,Hexagon处理器能够解码一个常规bin在2个循环中(不包括箱子重新填充过程)。
有关decbin指令的更多信息,请参阅第11.10.6节
例子:Rdd = decbin(Rss,Rtt) INPUT: Rss and Rtt register pairs as: Rtt.w1[5:0] = state Rtt.w1[8] = valMPS Rtt.w0[4:0] = bitpos Rss.w0 = range Rss.w1 = offset OUTPUT: Rdd register pair is packed as Rdd.w0[5:0] = state Rdd.w0[8] = valMPS Rdd.w0[31:23] = range Rdd.w0[22:16] = '0' Rdd.w1 = offset (normalized) OUTPUT: P0 P0 = (bin)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
4.8.1.2 代码示例
H264CabacGetBinNC: /**************************************************************** * Non-conventional call: * Input: R1:0 = offset : range , R2 = dep, R3 = ctxIdx, * R4 = (*ctxIdx), R5 = bitpos * * Return: * R1: 0 - offset : range * P0 - (bin) *****************************************************************/ // Cycle #1 { R1:0= decbin(R1:0,R5:4) // decoding one bin R6 = asl(R22,R5) // where R22 = 0x100 } // Cycle #2 { memb(R3) = R0 // save context to *ctxIdx R1:0 = vlsrw(R1:0,R5) // re-align range and offset P1 = cmp.gtu(R6,R1) // need refill? i.e., P1= (range<0x100) IF (!P1.new) jumpr:t LR // return } RENORM_REFILL:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4.8.2 IP 校验
internet checksum(See RFC 1071 (http://www.faqs.org/rfcs/rfc1071.html)
)的主要功能包括:- 校验和可以按任何顺序求和
- 可以使用大于所添加大小的累加器来累积进位,并且随时添加回
使用标准的数据处理指令,互联网校验和可以计算为8通过加载字并累积为双字,主循环中每个周期的字节数。在循环之后,上部单词被添加到下部单词;那么上半字是添加到下半字,所有进位都添加回。
Hexagon处理器支持专用指令(vradduh),该指令支持以每周期16字节的速率计算互联网校验和。vradduh指令接受两个输入向量的半字,将它们全部相加并将结果放入32位目标寄存器。可以使用此操作用于在保留进位的同时计算16字节输入的总和,以及计算结束时累积进位。
有关vradduh指令的更多信息,请参阅第11.10.1节。注意:此操作利用了Hexagon处理器中可用的最大负载带宽。4.8.2.1 代码示例
.text .global fast_ip_check // Assumes data is 8-byte aligned // Assumes data is padded at least 16 bytes afterwords with 0's. // input R0 points to data // input R1 is length of data // returns IP checksum in R0 fast_ip_check: { R1 = lsr(R1,#4) // 16-byte chunks, rounded down, +1 R9:8 = combine(#0,#0) R3:2 = combine(#0,#0) } { loop0(1f,R1) R7:6 = memd(R0+#8) R5:4 = memd(R0++#16) } .falign 1: { R7:6 = memd(R0+#8) R5:4 = memd(R0++#16) R2 = vradduh(R5:4,R7:6) // accumulate 8 halfwords R8 = vradduh(R3:2,R9:8) // accumulate carries }:endloop0 // drain pipeline { R2 = vradduh(R5:4,R7:6) R8 = vradduh(R3:2,R9:8) R5:4 = combine(#0,#0) } { R8 = vradduh(R3:2,R9:8) R1 = #0 } // may have some carries to add back in { R0 = vradduh(R5:4,R9:8) } // possible for one more to pop out { R0 = vradduh(R5:4,R1:0) } { R0 = not(R0) jumpr LR }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
4.8.3 软件定义的无线电
Hexagon处理器包括六条专用指令,它们支持软件无线电的实现。这些指令大大加快了以下算法:
- 耙式解扩
- 扰码生成
- 多项式场处理
4.8.3.1 耙式解扩
解扩中的一个基本操作是PN乘法操作。在此操作中将接收到的复码片与QAM的伪随机序列进行比较星座点和累积点。
图4-3显示了用于执行此操作的vrcrotate指令。这个乘积相加形成软32位复数符号。该指令具有两种功能累积和非累积版本
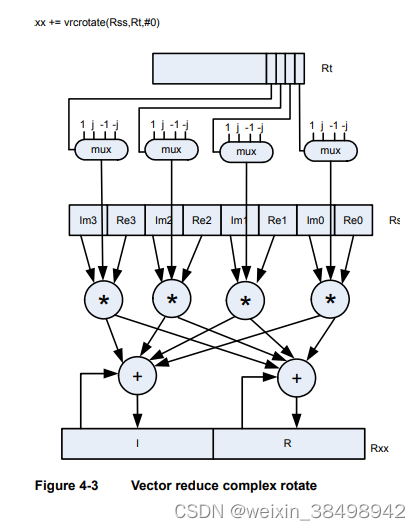
有关vrcrotate指令的更多信息,请参阅第11.10.3节。注:使用此指令,Hexagon 处理器可以每周期处理5.3个芯片,一个12指WCDMA用户只需要15兆赫。4.8.3.2 多项式运算
多项式乘法指令支持以下操作:
- 扰码生成(WCDMA的速率为每周期8个符号)
- 密码算法(如椭圆曲线)
- CRC检查(每周期21位)
- 卷积编码
- 里德-所罗门码
该指令的四个版本都支持32 x 32和向量16 x 16乘法有无堆积,如图4-4所示。
有关pmpy说明的更多信息,请参阅第11.10.5节。

-
相关阅读:
软件测试03:软件工程和软件生命周期
基于Python的视觉词袋实现数据分类
【LeetCode215】数组中的第K个最大元素
[数据库]MYSQL之授予/查验binlog权限
Langchain-Chatchat项目:4.2-P-Tuning v2使用的数据集
【Effective Objective - C】—— block 块
算法--插入排序
重装系统后如何在win10系统打开命令行窗口
MMSegmentation系列之训练与推理自己的数据集(三)
ubuntu18.04上遇到的一些bug修复
- 原文地址:https://blog.csdn.net/weixin_38498942/article/details/125905272
