-
【数据聚类】第六章第二节:层次聚类算法之BIRCH算法
- 注意:文章中部分内容来自刘建平博客,多谢多谢:刘建平:BIRCH聚类算法原理
一:BIRCH算法概述
BIRCH算法:该算法于1996年提出,尤其适用于大型数据库。它会增量地对输入数据进行聚类,有时甚至只需对所有数据扫描一遍就可以产生结果,当然额外的扫描肯定可以提升聚类效果,而且还可以有效处理噪声。BIRCH算法需要引入以下两个概念
- 聚类特征(CF)
- 聚类特征数(CF树)
聚类特征数类似于平衡B+树,CF树的每个结点是由若干聚类特征CF组成的
(1)聚类特征CF
聚类特征CF:一个聚类特征由一个三元组表示,它给出了一个簇的汇总描述。在大小为 N N N的 d d d维数据集 { x 1 , x 2 , . . . , x N } \{x_{1},x_{2},...,x_{N}\} {x1,x2,...,xN}上,定义聚类特征如下
C F = ( N , L S ⃗ , S S ) CF=(N,\vec{LS},SS) CF=(N,LS,SS)
- N N N:数据数量
- L S ⃗ \vec{LS} LS: N N N个数据点的线性和,也即 ∑ i = 1 N x i ⃗ \sum\limits_{i=1}^{N} \vec{x_{i}} i=1∑Nxi
- S S SS SS: N N N个数据点的平方和,也即 ∑ i = 1 N x i 2 ⃗ \sum\limits_{i=1}^{N} \vec{x_{i}^{2}} i=1∑Nxi2
聚类特征是可以求和的
- C F 1 = ( N 1 , L S 1 ⃗ , S S 1 ) CF_{1}=(N_{1},\vec{LS_{1}},SS_{1}) CF1=(N1,LS1,SS1)
- C F 2 = ( N 2 , L S 2 ⃗ , S S 2 ) CF_{2}=(N_{2},\vec{LS_{2}},SS_{2}) CF2=(N2,LS2,SS2)
- C F 1 + C F 2 = ( N 1 + N 2 , L S 1 ⃗ + L S 2 ⃗ , S S 1 + S S 2 ) CF_{1}+CF_{2}=(N_{1}+N_{2},\vec{LS_{1}}+\vec{LS_{2}},SS_{1}+SS_{2}) CF1+CF2=(N1+N2,LS1+LS2,SS1+SS2)
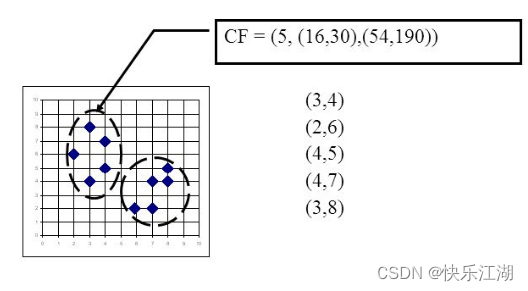
如下图,有5个样本形成的一个簇,分别是 ( 3 , 4 ) , ( 2 , 6 ) , ( 4 , 5 ) , ( 4 , 7 ) , ( 3 , 8 ) (3, 4),(2,6),(4,5),(4,7),(3,8) (3,4),(2,6),(4,5),(4,7),(3,8),则有
- N N N:5
- L S ⃗ \vec{LS} LS: ( 3 + 2 + 4 + 4 + 3 , 4 + 6 + 5 + 7 + 8 ) = ( 16 , 30 ) (3+2+4+4+3, 4+6+5+7+8)=(16, 30) (3+2+4+4+3,4+6+5+7+8)=(16,30)
- S S SS SS: ( 3 2 + 2 2 + 4 2 + 4 2 + 3 2 + 4 2 + 6 2 + 5 2 + 7 2 + 8 2 ) = 244 (3^{2}+2^{2}+4^{2}+4^{2}+3^{2} +4^{2}+6^{2}+5^{2}+7^{2}+8^{2})=244 (32+22+42+42+32+42+62+52+72+82)=244
(2)聚类特征树
聚类特征树:一个CF树存储了层次聚类的聚类特征。它存储了层次聚类的聚类特征。下图是一个典型的CF树。CF树中每个非叶结点存储的CF是其孩子结点的CF总和,也即父结点存储的信息是其子结点存储信息的汇总。一个叶子结点至多包含 L L L个条目,每个条目是一个聚类特征三元组,每个叶子结点有两个指针,即
prev和next,用来把所有的叶子结点连接起来一个CF树有如下两个参数,当阈值 T T T越大时树就会越小,它们决定了树的大小
- 分支因子 B B B:表示每个非叶结点最大的孩子数目
- 阈值 T T T::表示存储在树的叶子结点中的子聚类的最大半径

如下图,在CF树中,对于父结点的每个CF结点,它的 ( N , L S ⃗ , S S ) (N,\vec{LS},SS) (N,LS,SS)三元组的值等于这个CF结点所指向的所有子结点的三元组之和

(3)聚类特征树的生成
A:生成规则
聚类特征树的生成规则:CF树是随数据的输入动态增长的,生成CF树的步骤如下
- 找到要插入的叶子结点:从CF树根结点开始,通过比较结点的CF值找到距离最近的簇,然后从该簇的孩子结点中继续找到距离最近的簇,直到最后找到叶子结点
- 修改叶子结点: 找到叶子结点中距离最近的条目,检查该叶子结点能够再加入新条目,可以的话直接加入,不可以的话分裂叶子结点并加入条目
- 更新路径的CF信息:从插入的叶子结点自下而上更新CF树上的CF值信息
B:例子
这里再次重申三个参数
- B B B:非叶结点的最大CF数
- L L L:叶子结点的最大CF数
- T T T:叶子结点每个CF的最大样本半径阈值
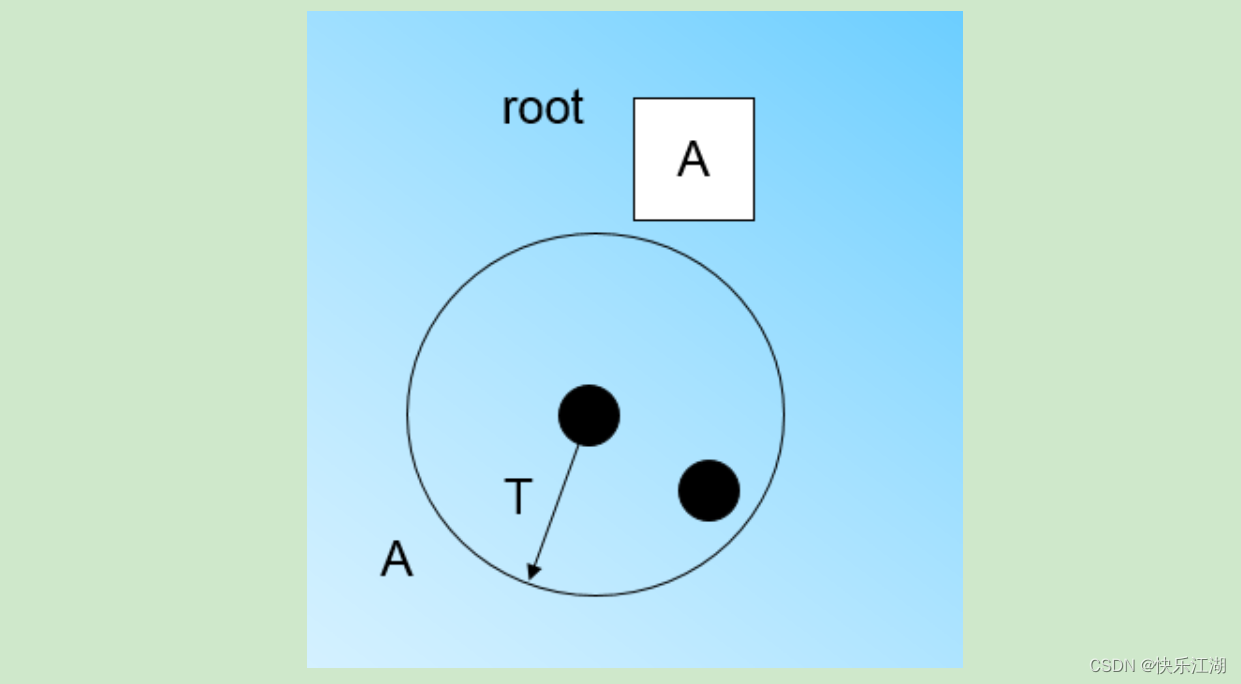
开始是,CF树为空,无任何样本,从数据集读入第一个样本点,将其放入一个新的CF三元组 A A A(此时此三元组的 N N N=1),将这个新的CF放入根结点

继续读入第二个样本点,发现此样本点在 A A A的半径 T T T范围内,所以同属于一个CF,因此将此样本点加入 A A A,并更新 A A A的三元组(此时A的三元组中的 N N N=2)
来了第三个样本点,发现此结点未在 A A A的半径 T T T范围内,所以需要一个新的CF三元组 B B B来容纳这个新的值
对于第四个样本点,发现它在 B B B的半径 T T T范围内

在构建CF tree的过程中,除了空间距离,还需要考虑平衡因子B和L。比如对于以下LN1节点而言,如果叶平衡因子L的值大于3,则sc8这个CF就可以作为LN1的一个叶子节点

如果小于3,就需要分裂出一个新的分支,分裂时,从LN1下所有的CF中挑选出距离最小和最大的两个CF,作为的内部节点,图示如下
枝平衡因子B影响内部节点的结构,如果B的值小于3,则要对内部节点进行拆分,分裂的方法是相同的,就是挑选距离最近和最远的两个CF作为新的分支,分裂后的结果如下

二:BIRCH算法流程

-
相关阅读:
微信小程序云开发-云函数发起https请求简易封装函数
442. 数组中重复的数据
【电机控制】FOC电机控制
LeetCode每日一题(1770. Maximum Score from Performing Multiplication Operations)
人机环境系统智能有利于防止人工智能失控
企业电子招标采购系统源码Spring Boot + Mybatis + Redis + Layui + 前后端分离 构建企业电子招采平台之立项流程图
对Spring AOP的进一步深入理解
第6讲:v-for使用
springboot+vue+elementUI基于SpringBoot的冬奥会科普平台#毕业设计
1005. K 次取反后最大化的数组和-快速排序
- 原文地址:https://blog.csdn.net/qq_39183034/article/details/125885921