-
C语言程序的编译(预处理)概述 —— 上
1. 程序的翻译环境和执行环境
在 ANSI C 的任何一种实现中,存在两个不同的环境。
- 翻译环境,在这个环境中源代码被转换成可执行的机器指令
- 执行环境,它用于实际执行代码
2. 编译 + 链接概述
在我们写好代码并且 Ctrl + F5 会弹出一个黑框框,在我们的项目目录下会生成 .exe 可执行文件,我们现在要了解的就是这个东西是怎么被“造”出来的。


2.1 翻译环境
我们大体上可以知道是,可执行文件是由编译、链接这两个部分组合产生。用文字阐述可以说:源文件(可以是多个)经过编译器编译产生目标文件,这些目标文件被送进链接库进行链接,从而产生可执行程序。


我们需要注意一个点,编译器的编译过程不止编译这一个环节。 也就是说,编译本身也可以分为几个阶段。
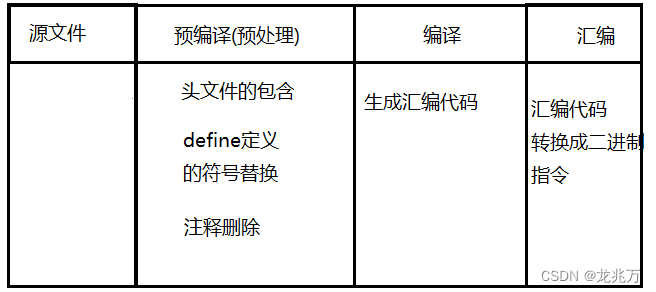
因为 Visual Studio 这些编译器是一个集成开发环境,所以不方便展示各个部分的详细内容。但是在以后学习 Linux 的过程中,我们回过头来是一定可以观察的。这里我就用文字阐述。
- 在预编译阶段,编译器会将头文件的内容、define 定义的文本替换都写入 .i 文件当中,并且删除注释。也就是说,预编译产生的 .i 文件里面写的 C 语言代码,是包括头文件的所有 C 语言代码。
- 编译阶段,从这个阶段开始,就要逐渐让计算机硬件能够识别我们的代码。所以这个阶段就会把 C 语言代码翻译成汇编语言代码。比如说我们有 int max = 10; ,那么编译阶段就会把 int 看成类型生成对应的汇编指令,max 是变量名,生成对应的汇编语句, = 是赋值符号,同样也会生成汇编语句,等等……这些汇编代码存放在 .s 文件中。
- 汇编,这里就是生成目标文件的步骤。这个阶段会对汇编代码进行更加细化的拆分,生成最原始的机器指令,即二进制指令。这些指令会被放在 .obj 文件当中(Linux 环境下为 .o 文件),在 Linux 环境下可观察这些二进制指令,但我们的大脑会认为这些是乱码。
2.2 运行环境
程序的执行过程:
- 程序必须载入内存中。在具有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排(比如单片机中的烧写代码就需要借助电脑的操作系统),也可能是通过可执行代码置入只读内存来完成。
- 程序载入内存后,执行便开始,此时需要找到 main 函数并调用它。
- 程序代码被执行后,这时程序将使用一个运行时堆栈(函数栈帧),存储函数的局部变量和返回地址。程序同时也可以使用静态存储,存储于静态内存中的变量在程序的整个执行过程一直保留(全局变量)。
- 终止程序,可能是 main 函数正常结束,也可能是意外结束。
3. 预处理概述
3.1 预定义符号
我们可以了解一些预定义符号:
- __FILE__ //进行编译的源文件
- __LINE__ //文件当前的行号
- __DATE__ //文件被编译的日期
- __TIME__ //文件被编译的时间
我们可以搭配文件操作使用他们。
- #include
- int main()
- {
- FILE* pf = fopen("test.txt", "w");
- if (pf == NULL)
- {
- perror("fopen");
- return 1;
- }
- //格式化输出
- fprintf(pf, "file:%s line:%d date:%s time:%s\n", __FILE__, __LINE__, __DATE__, __TIME__);
- fclose(pf);
- pf = NULL;
- return 0;
- }
此时在项目目录下生成的 .txt 文件记录着我们想要的东西:

3.2 #define
3.2.1 #define 定义标识符
定义标识符非常简单,也就是常说的文本替换。
- #define MAX 1000
- #define reg register //为 register这个关键字,创建一个简短的名字
- #define do_forever for(;;) //用更形象的符号来替换一种实现
- #define CASE break;case //在写case语句的时候自动把 break写上。
- // 如果定义的 stuff过长,可以分成几行写,除了最后一行外,每行的后面都加一个反斜杠(续行符)。
- #define PRINT printf("%s\n","#define 定义标识符")
- #include
- int main()
- {
- PRINT;
- return 0;
- }
需要注意的是,在我们定义标识符时,尽量不要在后面添加分号,因为在我们书写代码时会习惯自己加上分号,如果定义的标识符后有分号,可能会产生不易察觉的错误。
- #define WHILE while(1);//这里添加了分号
- #include
- #include
- int main()
- {
- WHILE //这里相当于 while(1); 循环执行了空语句,与程序本意不一致
- {
- printf("hello world!\n");
- Sleep(1000);
- }
- return 0;
- }
当然我们也可以使用这个功能来实现一些令人难以捉摸的骚操作,假设有一个程序员每次使用 swich 语句内的 case ,后面都要写 break,他觉得很麻烦,那么他便写出了这么一段代码:
- #define CASE break;case
- #include
- int main()
- {
- int n = 3;
- switch (n)
- {
- case 1:
- CASE 2 :
- CASE 3 :
- printf("hello world!\n");
- CASE 4 :
- break;
- }
- return 0;
- }

-
相关阅读:
小白学爬虫:通过商品ID获取1688跨境属性数据接口|1688商品属性接口|1688一件代发数据接口|1688商品详情接口
Unity中Shader抓取屏幕并实现扭曲效果
网络协议:网络安全
Vue 组件的全局注册与组件的jsx实现方法
Linux常用指令(十一)——关机重启
linux下.bashrc文件修改和生效
JAVA【设计模式】桥接模式
【Dubbo3高级特性】「框架与服务」自定义Dubbo服务容器及扩展容器实现分析
学习编程的第二十五天
【砖墙】python刷题记录
- 原文地址:https://blog.csdn.net/weixin_59913110/article/details/125836477
