-
【transformer】ViT
概述
ViT直接将transformer用于分类任务,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率,说明了transformer同样适用于计算机视觉相关的任务。
但是要是想复现的话,难度是很大的,因为ViT的最佳模型是在google自己的JFT-18K(303million)上预训练的,而这个数据集是不公开的,开源的最大的数据集貌似是ImageNet-21K(14million),另一方面,transformer庞大的参数量也不是一般显卡吃得消的。细节
结构
主要分为以下的几个部分,首先是patch embedding、添加class-token、positional encoding,中间的transformer encoder部分以及最后的MLP head。
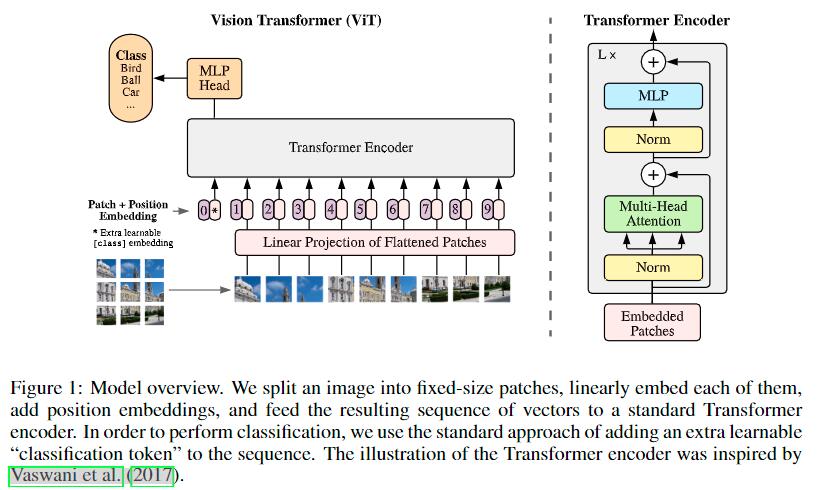
patch embedding
序列化操作:
这个操作是为了将图片转换成sequence。一个直观的思路就是,对于一个HxWxC的图片,将每个像素作为一个vector,那么就会得到长度为一个HxW的sequence,但是这样的话,长度就有点大了。因此,一个新的做法就是,对于一个HxWxC的图片,选取N个patch或者说是N个小图,得到长度为N的sequence。假设patch的长度是p,那么 N = H ∗ W p ∗ p N=\frac{H*W}{p*p} N=p∗pH∗W,每个vector中元素的个数就是 p ∗ p ∗ C p*p*C p∗p∗C,整个sequence就是 N ∗ ( p ∗ p ∗ C ) N * (p*p*C) N∗(p∗p∗C),然后还要做一个映射操作,将维度映射到我们想要的数值,也就是 N ∗ e m b e d d i m N * embed_dim N∗embeddim。
以上是思路,但是在实际实现中,这个操作其实是通过卷积操作实现的,我们设置kernel_size和stride就是我们的patch_size,out_channels就是embed_dim。class-token:
class-token就是encoder最左边的那个输入,他是我们额外附加的一个token。再说这个之前,以往我们做分类的话,一般是最后接一个全局平均池化操作,将尺寸降到1x1,然后再接一个Linear层做分类。这个做法是蛮cv的,而class-token就是nlp的做法了。class-token对应的输出是经过transformer的,对于整个sequence有一个很好把控的一个输出,我们对他进行监督,达到分类的效果。
positional encoding:
这个点使用NLP的思路比较好理解。如果没有字符的位置的话,对于self-attention操作而言,"我爱你"和"你爱我"这两个句子对应的输出是相同的,因此我们需要添加了位置信息,而添加的方式就是add。毕竟这个信息也是token的,同时也不需要,所以不需要concat。至于位置信息从哪来?可以手工指定,也可以让网络自己学习,一般倾向于后者。encoder
每个encoder块主要包含四个部分,MSA(多头注意力)、LN(层归一化)、MLP(多层感知机或者说是transformer中写的前馈神经网络),另外还有一个贯穿始终的残差连接。
MSA:链接,链接中self-attention这节中有讲到的,其实就是中间的qkv多几份,最后对应的输出取个平均作为真正的输出。
LN:BN是针对所有的样本,对某一个特征图计算均值和方差,然后然后对这个特征图神经元做归一化。LN是对某一个样本,计算该样本所有特征图的均值和方差,然后对这个样本做归一化。在cv中常用BN,但是NLP中常用LN,当然也能用BN代替,虽然细细说来能说出很多不同,但是其实差不多。
MLP:一个简单的前馈神经网络,核心就是两个全连接层,一个全连接层将将维度扩张若干倍数,另一个线性层将维度变回来,把它当做黑箱的话,其实输入输出shape是一样的。值得注意的话,激活函数用的是GELU,而不是RELU,还是那句话,细细说来能说出很多不同,但是其实差不多。
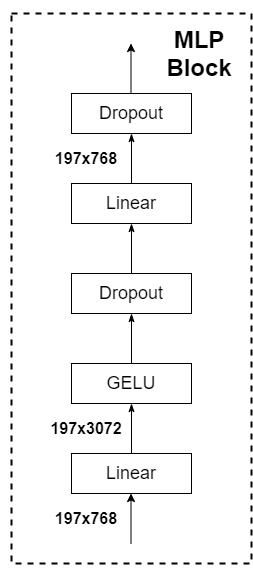
MLP head
ViT中说MLP是由一个全连层 + Tanh激活 + 全连接层组成。但实际使用起来一层全连接层直接做分类即可。
实验
ViT更需要预训练:
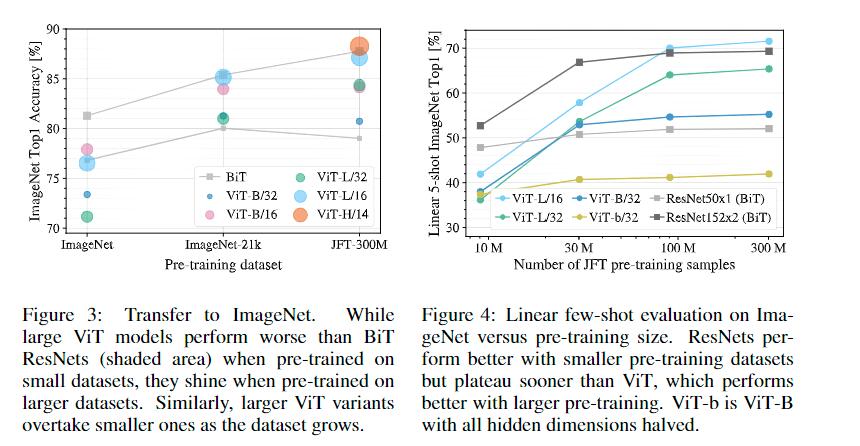
ViT的参数量比较大,所以,ViT模型相较于CNN网络更加需要大数据集的预训练。作者在多个数据集上进行预训练,比较其与CNN模型的性能。在数据量较小时,无论是在ImageNet还是JFT数据集,BiT(以ResNet为骨干的CNN模型)准确率相对更高,但是当数据集量增大到一定程度时,ViT模型略优于CNN模型。所以,ViT模型更需要大数据集进行预训练,以提高模型的表征。
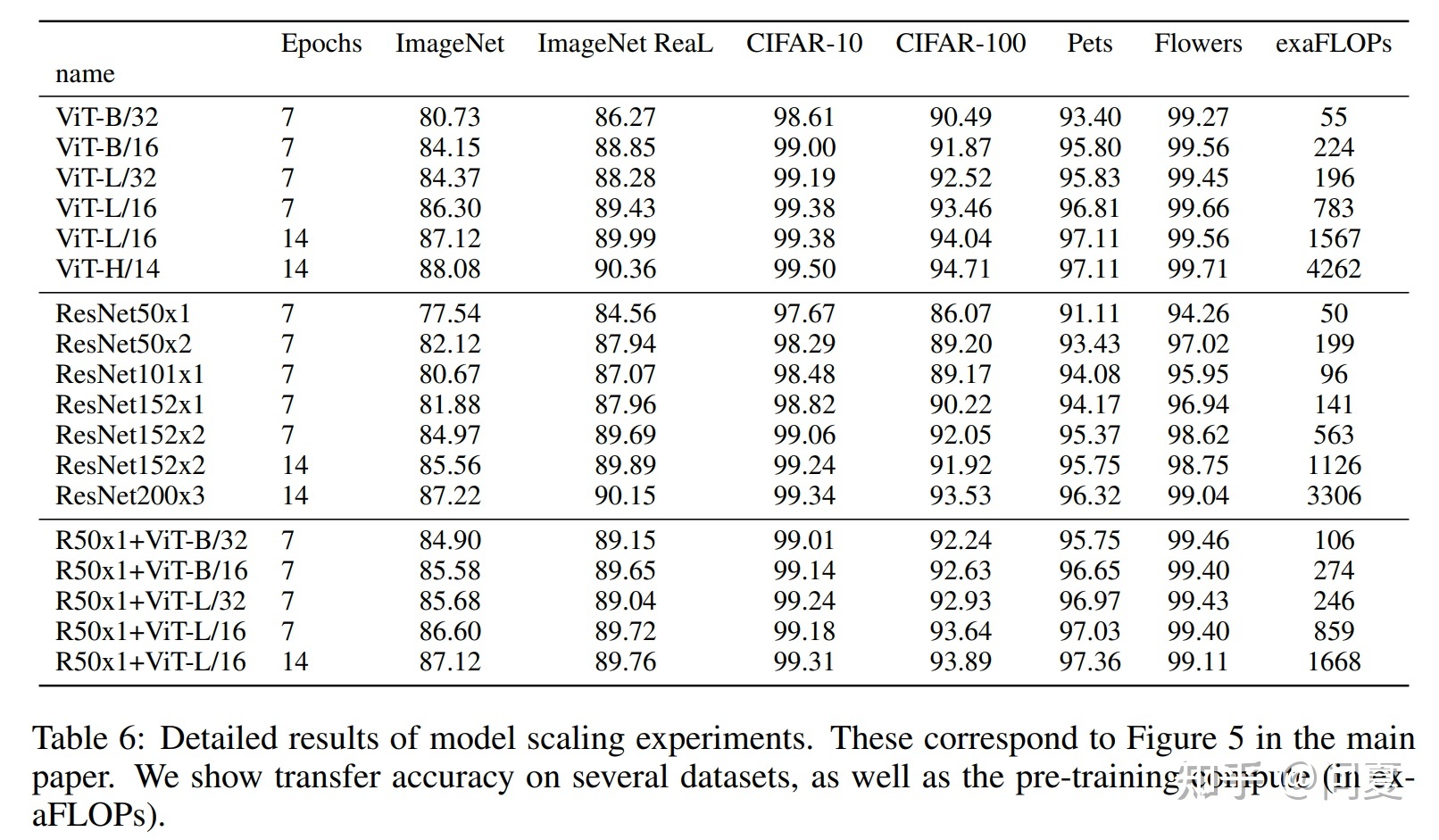
ViT模型更容易泛化到下游任务
对于CNN网络,即使有预训练权重,当使用这个网络泛化到其他下游任务时,也需要训练较长时间才能达到较好的结果。但是,对于ViT模型来说,当拥有ViT的预训练权重时,只需要训练几个epoch既可以拥有很好的性能。如下图所示,训练7个epoch时,ViT类的模型就有一个比较好的效果了。
-
相关阅读:
用Windows Installer CleanUp Utility 在windows server上面将软件卸载干净,比如SQLSERVER
MS2400隔离式调制器可pin对pin兼容AD7400
BitBake使用攻略--BitBake的语法知识二
hadoop 3.x大数据集群搭建系列4-安装Spark
2023-11-17 服务器开发-性能分析-intel-vtune-安装
【Java第24期】:IO、存储、硬盘和文件系统的相关知识
录屏怎么录,这2个方法不容错过!
Java后端开发(十)-- idea(2022版)将 已push 的 远程仓库 的 多条commit记录 进行撤销
Vue2 —— vue面试题分享
mybatis <if>标签判断“0“不生效
- 原文地址:https://blog.csdn.net/qq_44173974/article/details/125901599