-
序列模型(一)- 循环序列模型
本次学习笔记主要记录学习深度学习时的各种记录,包括吴恩达老师视频学习、花书。作者能力有限,如有错误等,望联系修改,非常感谢!
序列模型(一)- 循环序列模型
- 一、为什么选择序列模型(Why Sequence Models)
- 二、数学符号(Notation)
- 三、循环神经网络模型(Recurrent Neural Network Model)
- 四、通过时间的反向传播(Backpropagation through time)
- 五、不同类型的循环神经网络(Different types of RNNs)
- 六、语言模型和序列生成(Language model and sequence generation)
- 七、对新序列采样(Sampling novel sequences)
- 八、循环神经网络的梯度消失(Vanishing gradients with RNNs)
- 九、GRU单元(Gated Recurrent Unit)
- 十、长短期记忆(LSTM)
- 十一、双向循环神经网络(Bidirectional RNN)
- 十二、深层循环神经网络(Deep RNNs)
第一版 2022-07-18 初稿
一、为什么选择序列模型(Why Sequence Models)

1.语音识别之前,给定一个输入音频片段x,并要求输出对应的文字记录y。输入输出都是序列模型。
2.音乐生成,输入数据可以是空集。
3.情感分类。
4.DNA序列分析。
5.机器翻译。
6.视频行为识别,需 一系列视频帧。
7.命名实体识别。二、数学符号(Notation)
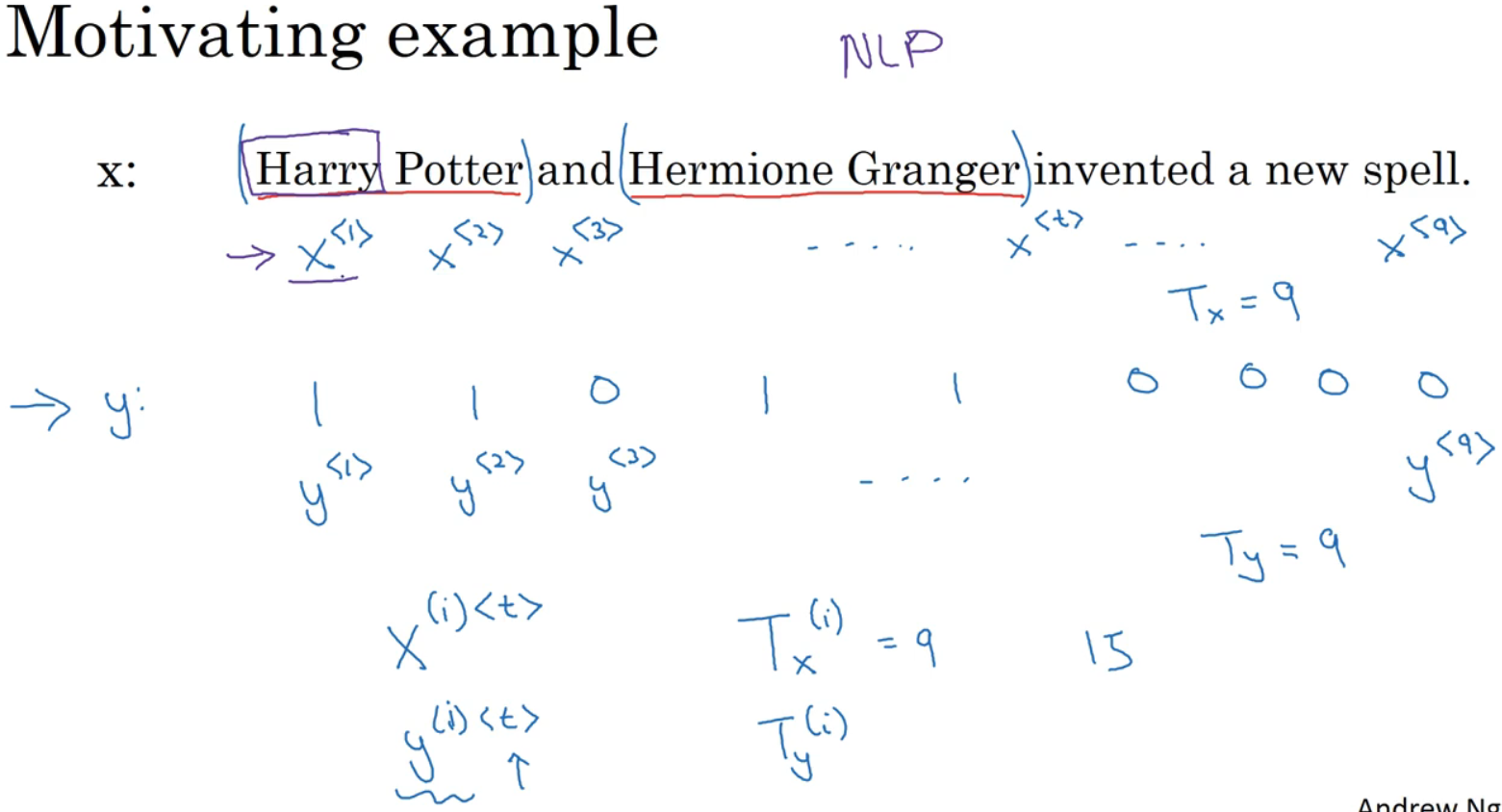
若想建立一个序列模型,输入一句话。若想建立一个能够自动识别句中人名的位置的序列模型,那么这就是一个命名实体识别问题,常用于搜索引擎。
用x来索引序列中间的位置。输出用y表示。Tx和Ty分别表示输入和输出序列的长度。x(i) 表示训练样本i中的序列中第t个元素。

首先做一张词典,列出表示方法中用到的单词,本次使用10000的词典,商业应用会更大。构建词典的一个方法是 遍历训练集,找到前10000个常用词,也可浏览网络词典,找到常用词,接下来可用one-shot表示法来表示词典中的每个单词。x
指代句子里的任意词,它就是个one-shot向量,因为只有一个值是1,其余全是0,因此会有9个one-shot向量表示句中9个单词,用这样表示方式表示X,用序列模型在X和目标输出Y之间学习建立一个映射。
若有不在词典中的单词,答案是创建一个新的标记,叫Unknow Word的伪单词,用作为标记,表示不在词表中的单词。三、循环神经网络模型(Recurrent Neural Network Model)
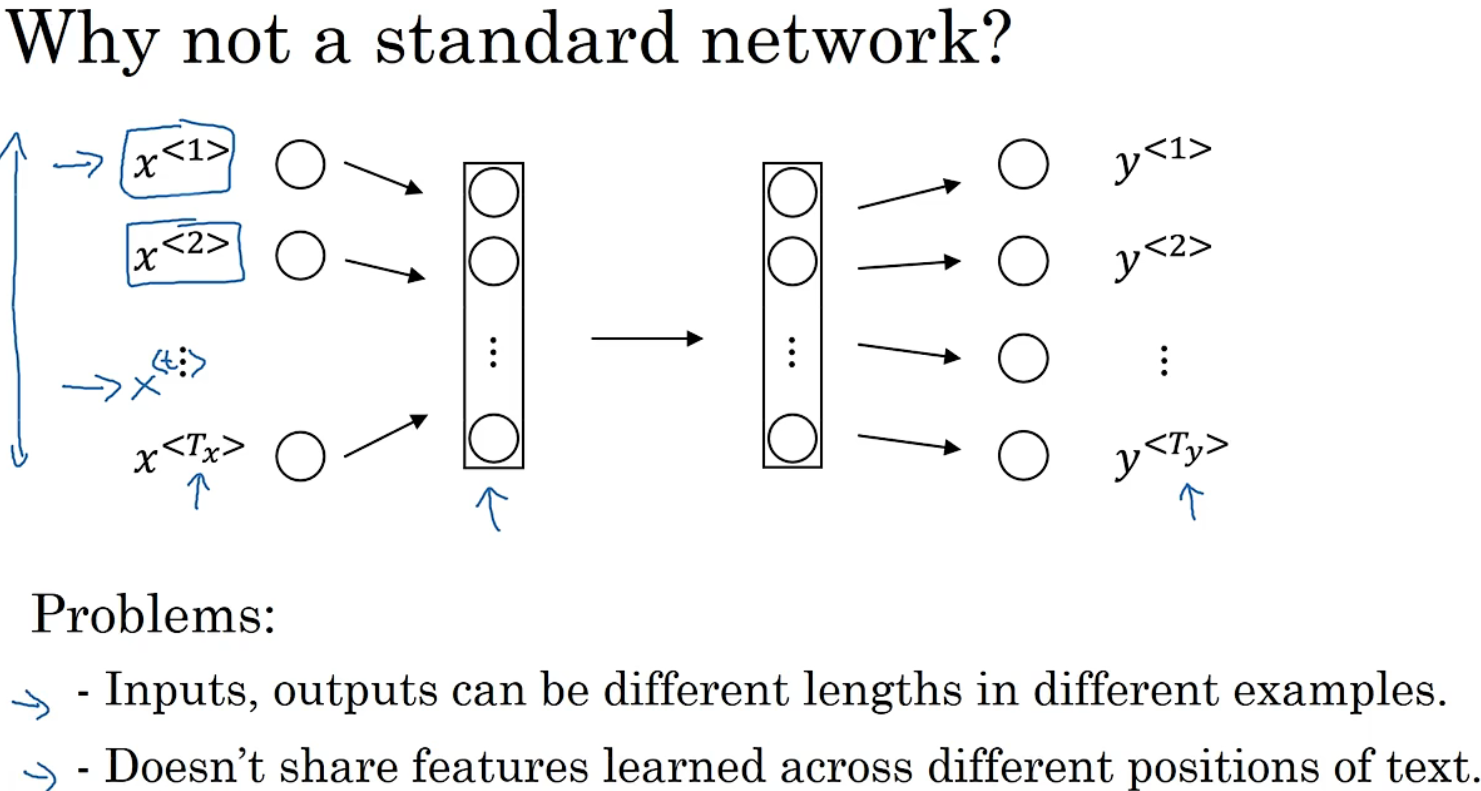
上节的例子中有9个输入单词,可能有9个one-shot向量,然后将它们输入到一个标准神经网络中,经过隐藏层,最终会输出9个值为0或1的项,表明每个输入单词是否是人名的一部分。
上述方法并不好,问题如下:
1.输入和输出数据在不同例子中可以有不同的长度。也许能填充或零填充使每个输入语句都达到最大长度,但仍看起来不是一个好的表达方式。
2.像神经网络结构,并不共享从文本的不同位置上学到的特征。权重参数会巨量,但RNN无此问题。
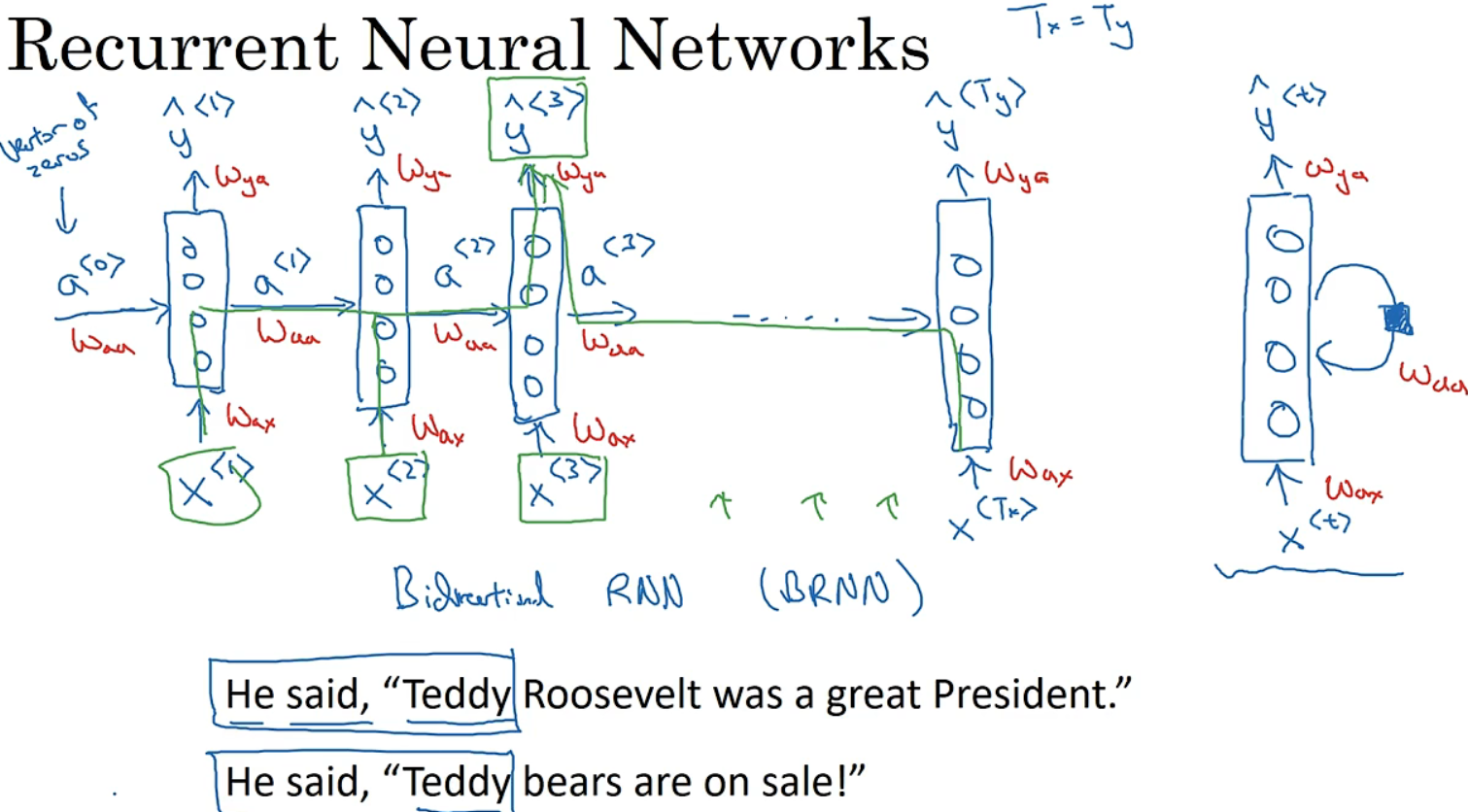
循环神经网络做的是,当读到句中的第二个单词时,不是仅用x<2>就预测出yhat<3>,也会输入一些来自时间步1的信息。若Tx和Ty不等,此操作需要一些改变。
如图右,会有个循环连接,同时画个黑色方块表示此次会延迟一个时间步。W_ax表示管理者从x<1>到隐藏层的连接的一系列参数,激活值也就是水平联系由参数W_aa决定,输出结果由W_ya决定,每个时间步使用的都是相同的参数W_ax、W_aa。
循环神经网络一个缺点是,只使用了之前的信息预测,像x<4>等信息没被使用。如第一句,判断Teddy是否是人名,只靠前方单词是不够的,会在双向循环神经网络处理此问题。
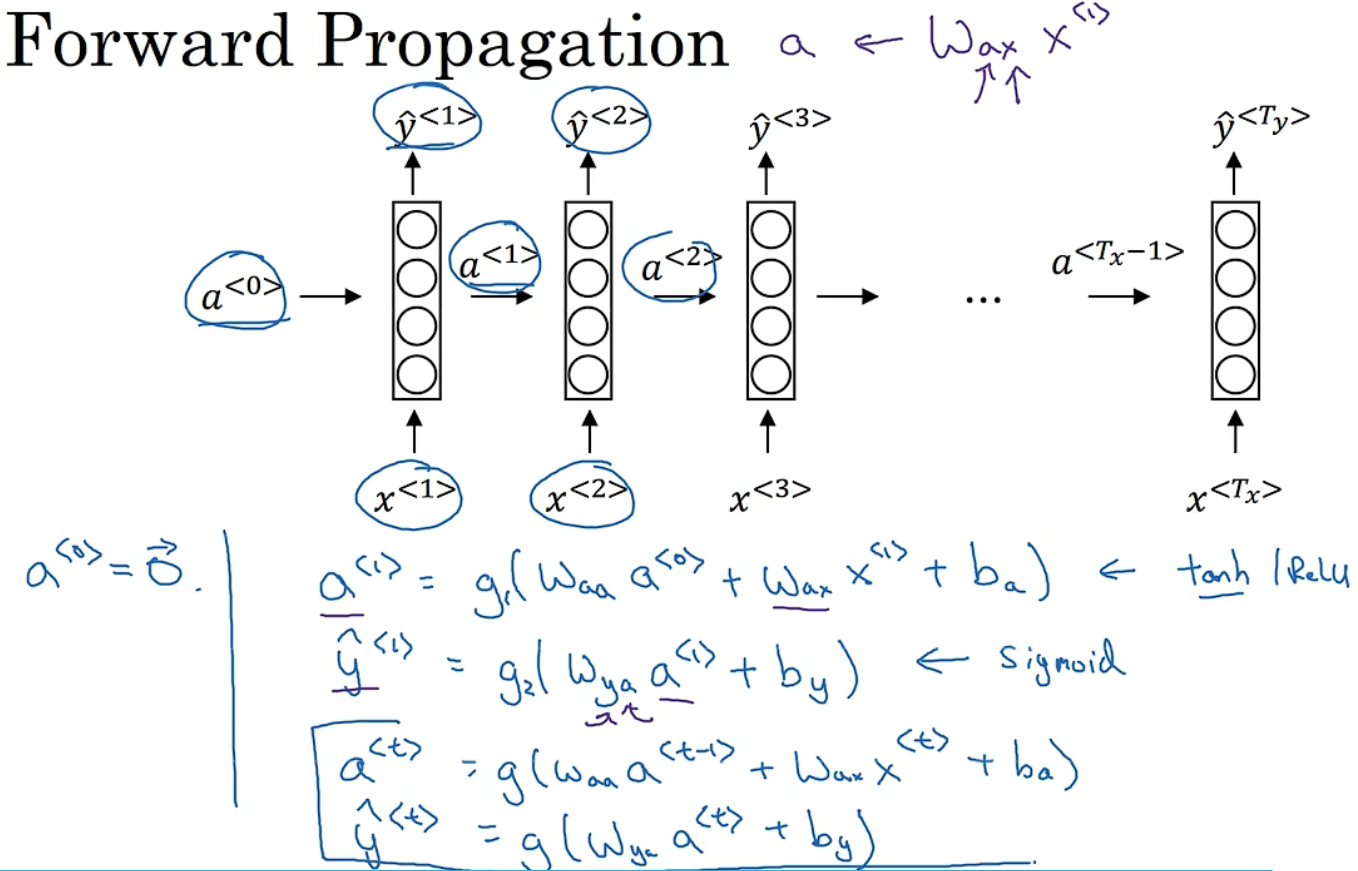
先激活a再激活y。二分类问题常用sigmoid函数,k分类用softmax函数。
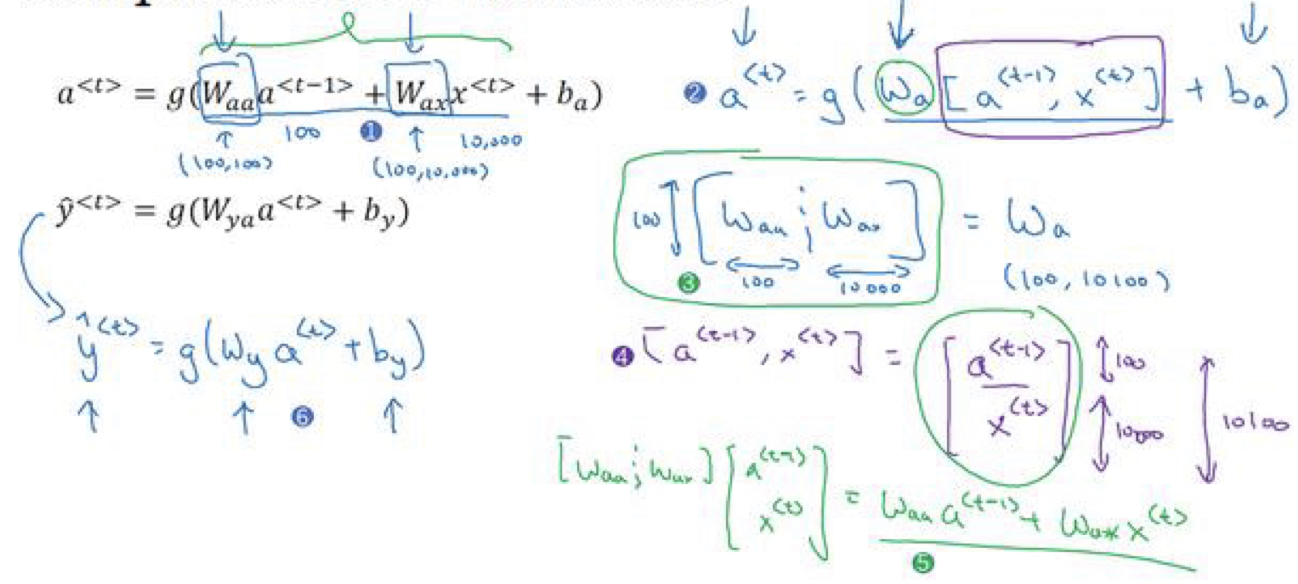
简化:
编号1为最初公式,接着写成2的形式,如3将w表示为w_aa和w_ax水平并列放置(若a是100维,延续之前x为10000维,那么W_aa就是(100,100)维的矩阵),W_ax是(100,10000)维的矩阵。堆叠后W_a为(100,10100)维。
如4,a和x堆在一起为10100维的向量。如5公式刚好对应最初公式。6是对输出的简化。
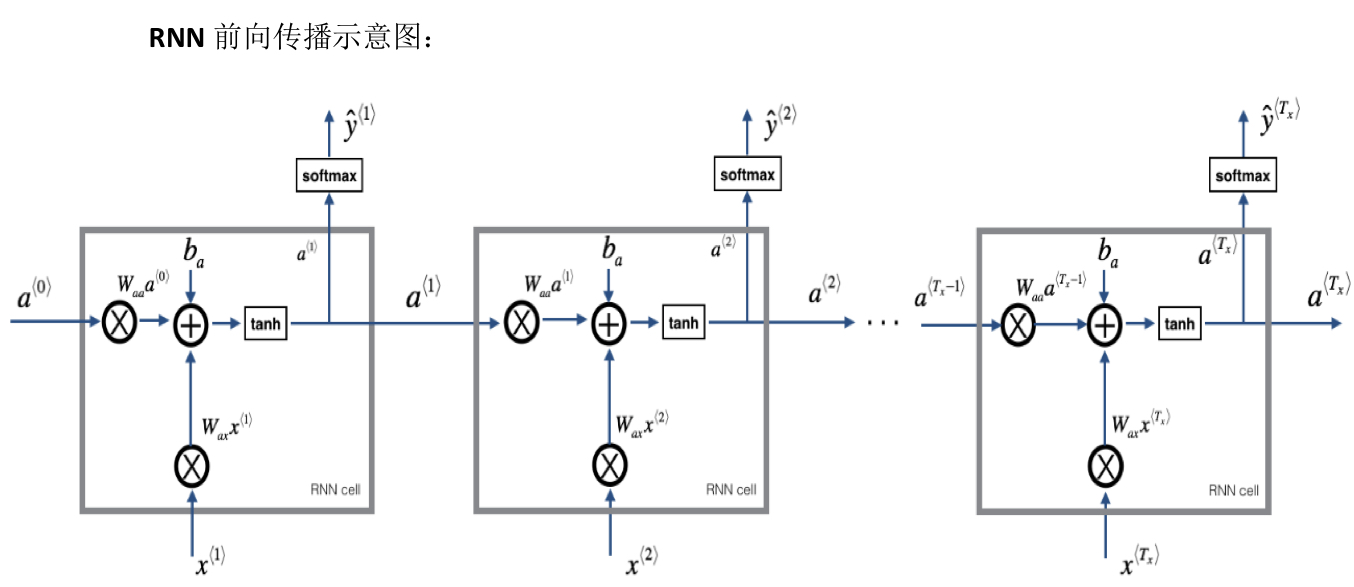
四、通过时间的反向传播(Backpropagation through time)
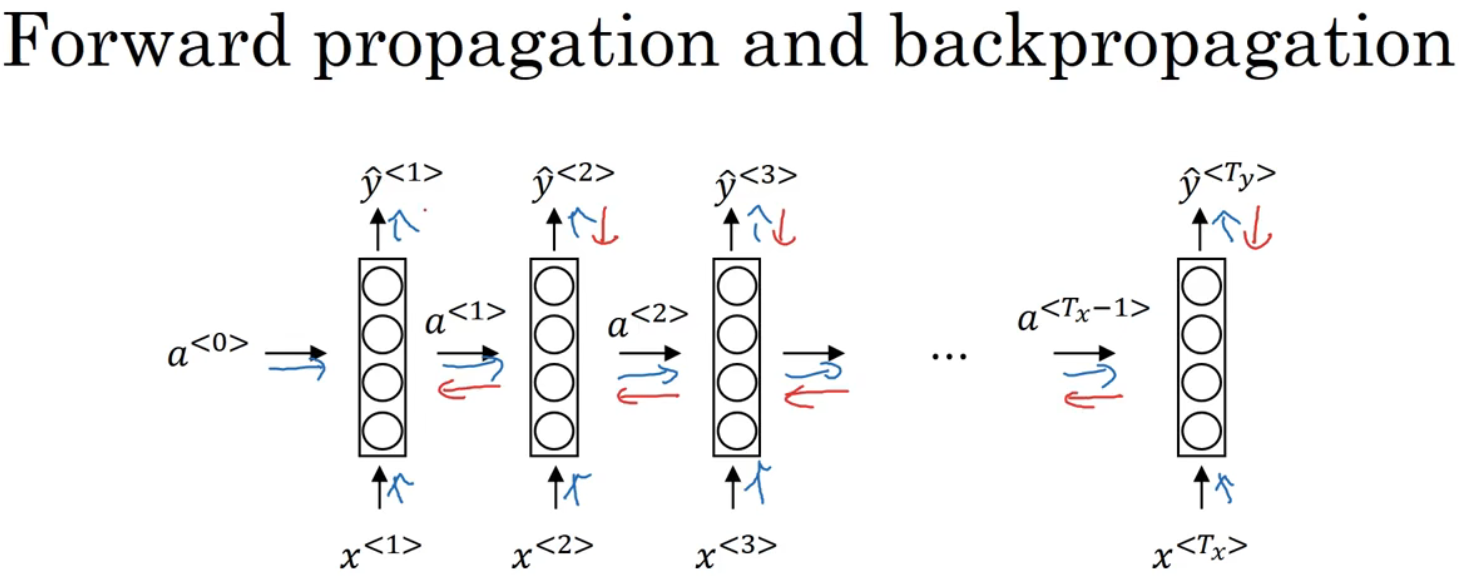
蓝前向传播,红反向传播。
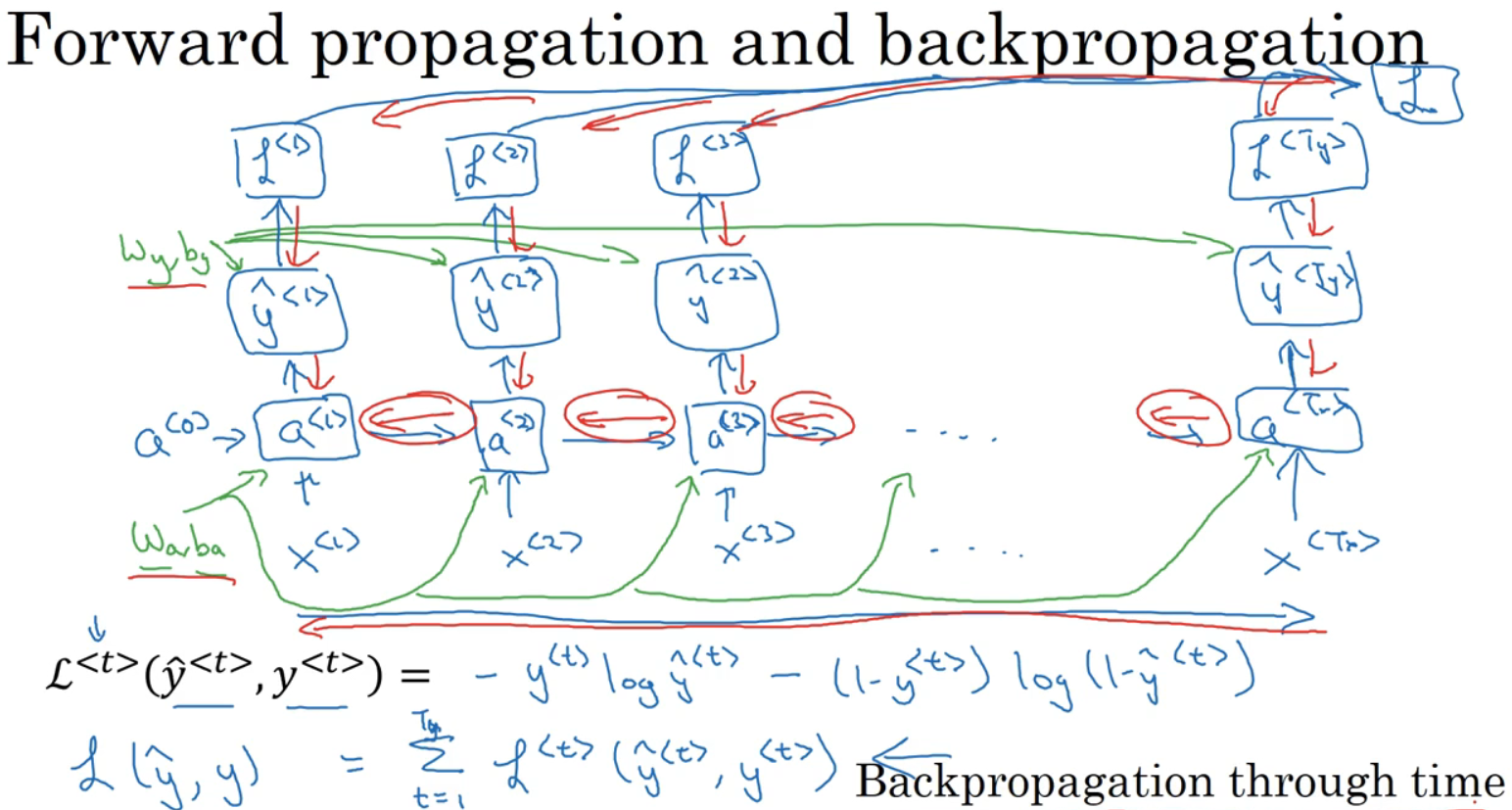
为了计算反向传播,需要一个损失函数L(yhat ,y ),其对应序列中一个具体的词,神金网络输出此词是名字的概率,将它定义为标准逻辑回归损失函数,也叫交叉熵损失函数。
下方为整个序列的损失函数。对于前向传播,从左到右计算,随时间增加;反向传播就像时间倒流,从右到左计算,因此命名为“通过时间反向传播”。
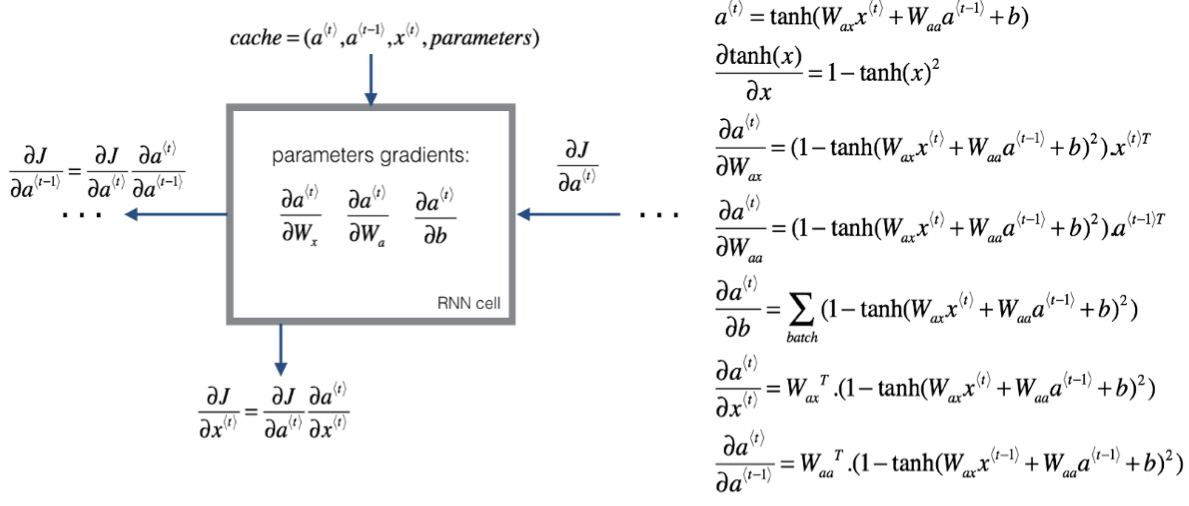
RNN反向传播示意图五、不同类型的循环神经网络(Different types of RNNs)

许多例子中有,输入可能为空集,输入输出长度不等的问题。
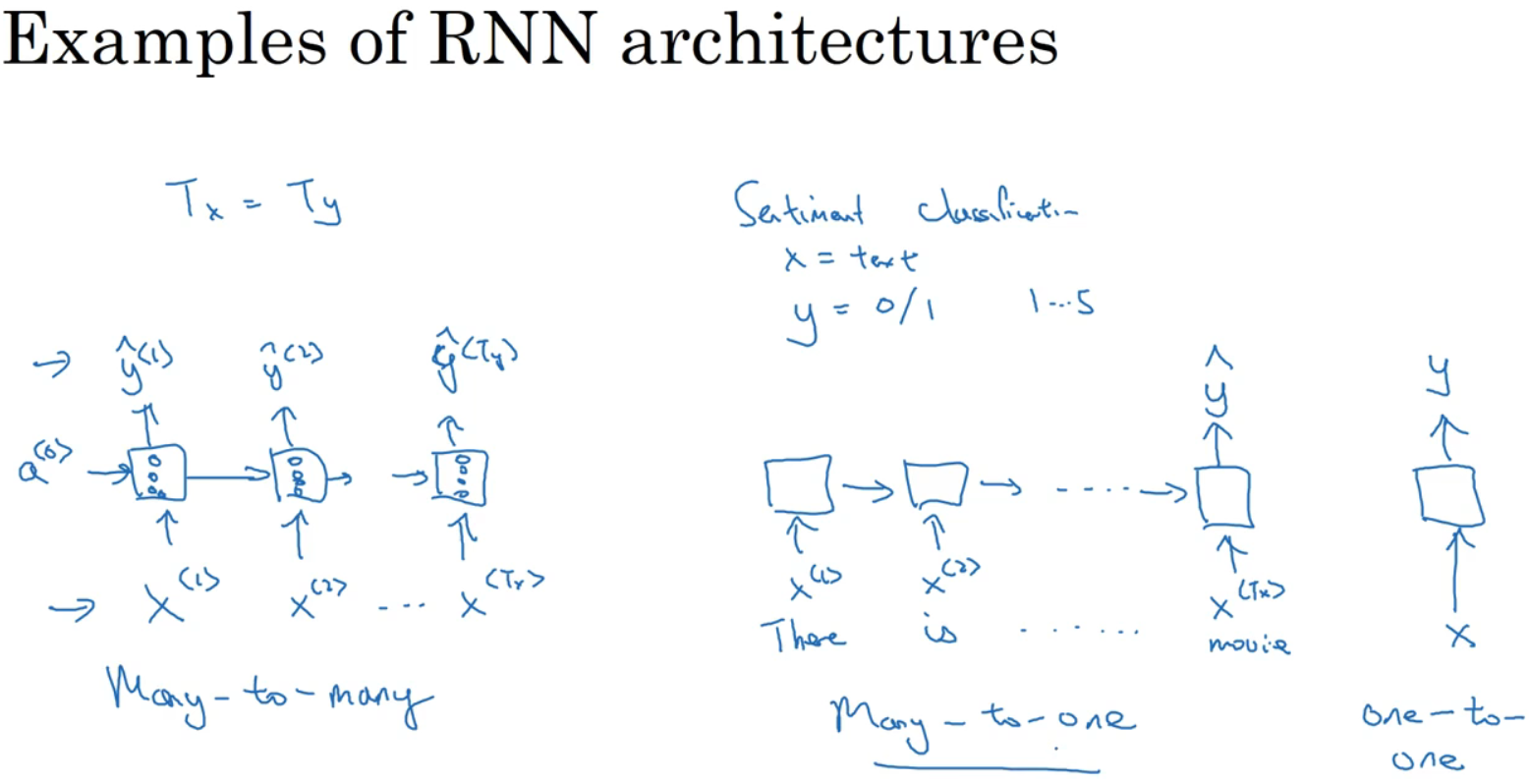
如上图左,“多对多”的结构。看右方另一个例子:
假设处理情感分类问题,x可能是一段电影的评论,y是0或1表示好评或差评,也可以是1到5表示打星。
不再在时间上都有输出,而是让RNN网络读入整个句子,然后在最后一个时间上得到输出,即“多对一”的结构。还有最右方为“一对一”的结构。
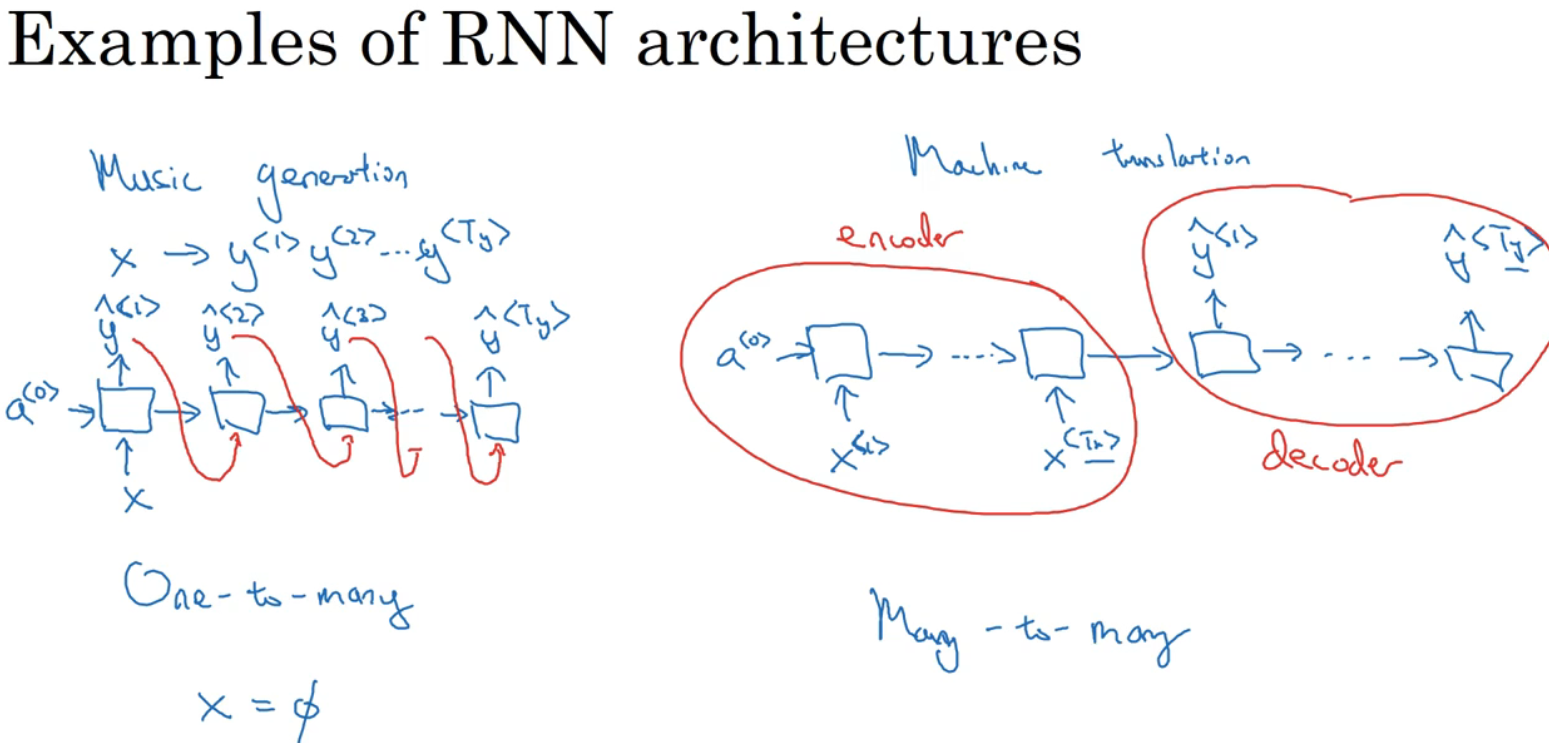
除了多对一,也可能是一对多,一对多如音乐生成。通常会把第一个合成的输出喂给下一层,如图红线所连。对于多对多,如图右,对于机器翻译,可能输入和输出单词数量不一致,可构造如图结构,一个编码器一个解码器。
注意力结构会在后边讲到。
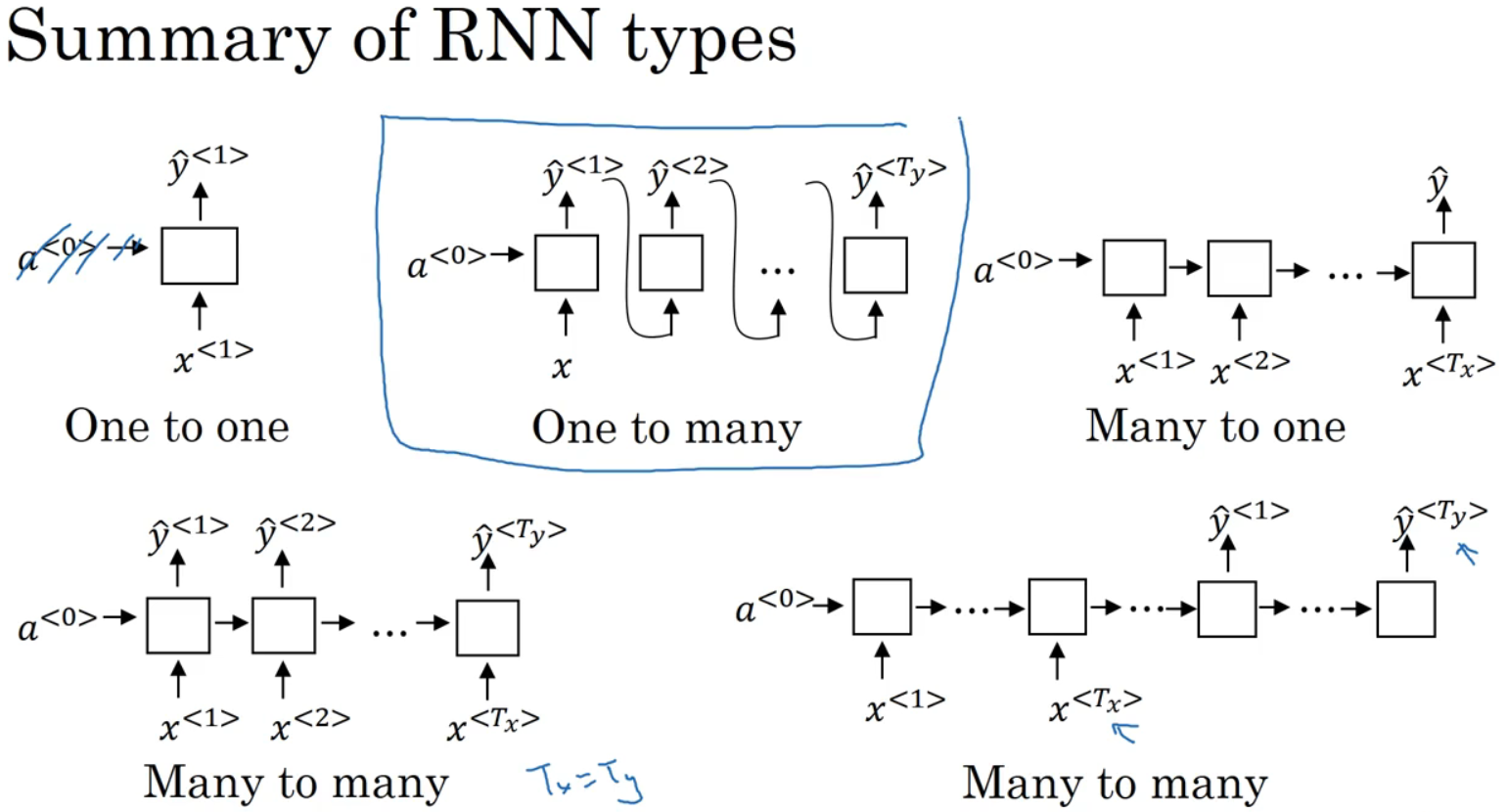
1.一对一,去掉a0就是标准的神经网络;
2.一对多,如音乐生成或序列生成;
3.多对一,情感分类;
4.多对多(Tx=Ty);
5.多对多(Tx≠Ty)。六、语言模型和序列生成(Language model and sequence generation)

如语音识别,生成两个相似句子,让语音识别系统选择第二个句子的方法就是使用第一个语言模型,能计算出两句话各自的可能性。

需要训练集,包含一个很大的英文文本语料库。如图一句话“Cats average 15 hours of sleep a day.”,要做的是将这个句子标记化,多出来的是定义句子的结尾,一般做法是增加一个额外的标记,记为EOS,帮助搞清楚句子何时结束。可自行决定标点符号是否看成标记。另一种情况,训练集有些词不在字典中,如“The Egyptian Mau is a bread of cat.”,其中一词Mau,可把它替换为“UNK”的代表未知词的标志,只针对UNK建立概率模型,而不是针对这个具体的词Mau。

按惯例a0设为0向量,a<1>做的是通过softmax进行预测,其实就是第一个词是a的概率多少,是Aaron的概率是多少,是结尾标志的概率等,最终得单词Cats。
下一个时间步,使用a<1>,并让x<2>=y<1>,接着同样的操作。
直到最后,在第9个时间步,得到结果为EOS,即结尾标记。定义损失函数L,和总体损失函数L。若用很大训练集训练RNN时,可通过开头一系列单词预测之后单词的概率。
1.告知y<1>的概率;
2.告知y<1>的情况下y<2>的概率。
3.告知y<1>和y<2>的情况下y<3>的概率。
三个概率相乘,最后得到这个包含3个词的整个句子的概率。七、对新序列采样(Sampling novel sequences)
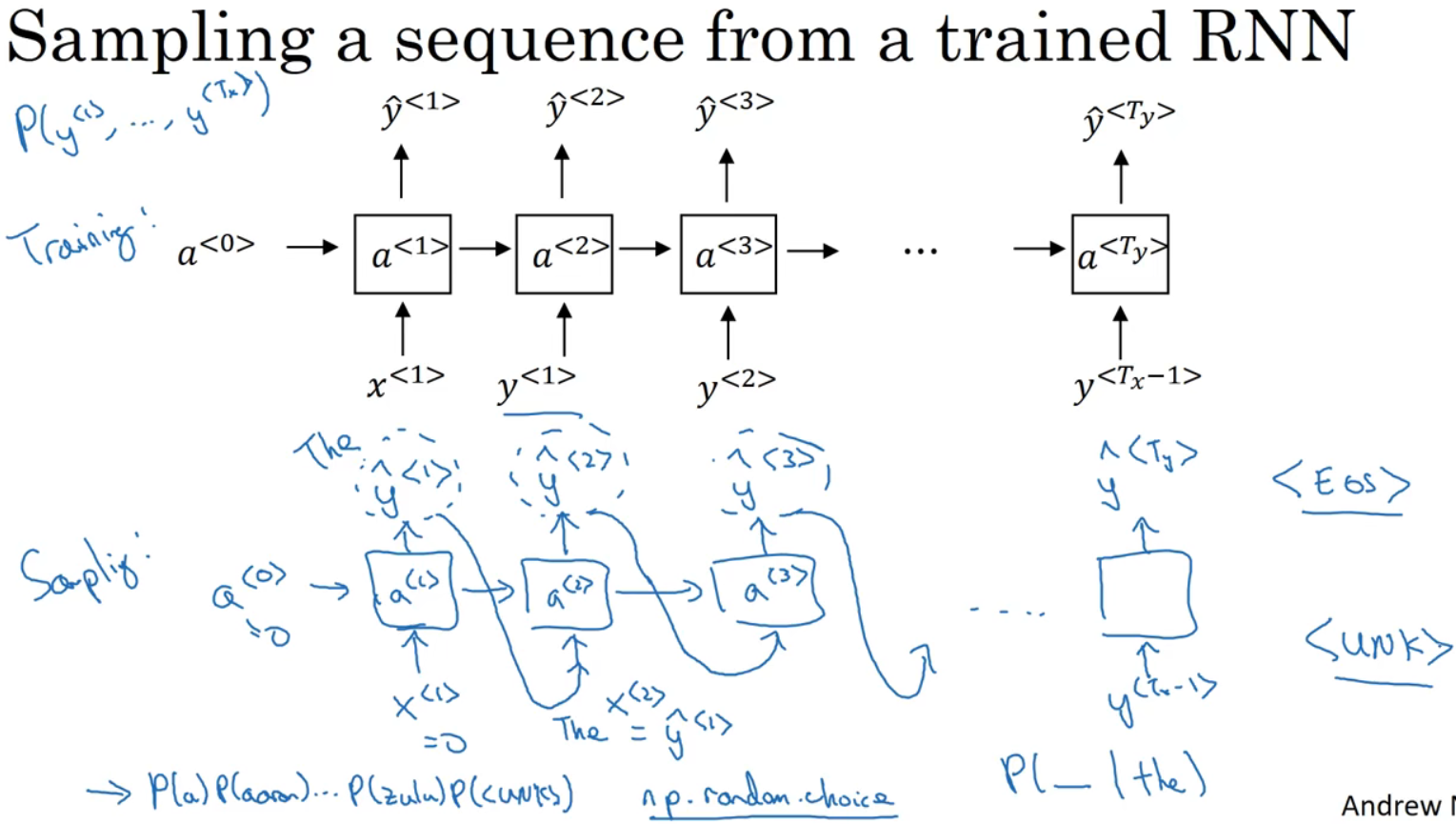
可用numpy.random.choice(),来根据向量中这些概率的分布进行采样。
结尾可用EOS标识;另一种情况,没这个词,可以决定从20个或100个或其他单词进行采样,直到所设定的时间步,此过程会产生UNK标识。
若确保不会输出UNK,就是拒绝采样过程中产生任何未知的标识,一旦出现就继续在剩下的词中进行重采样,直到得到一个不是UNK标识。不介意则不用管。
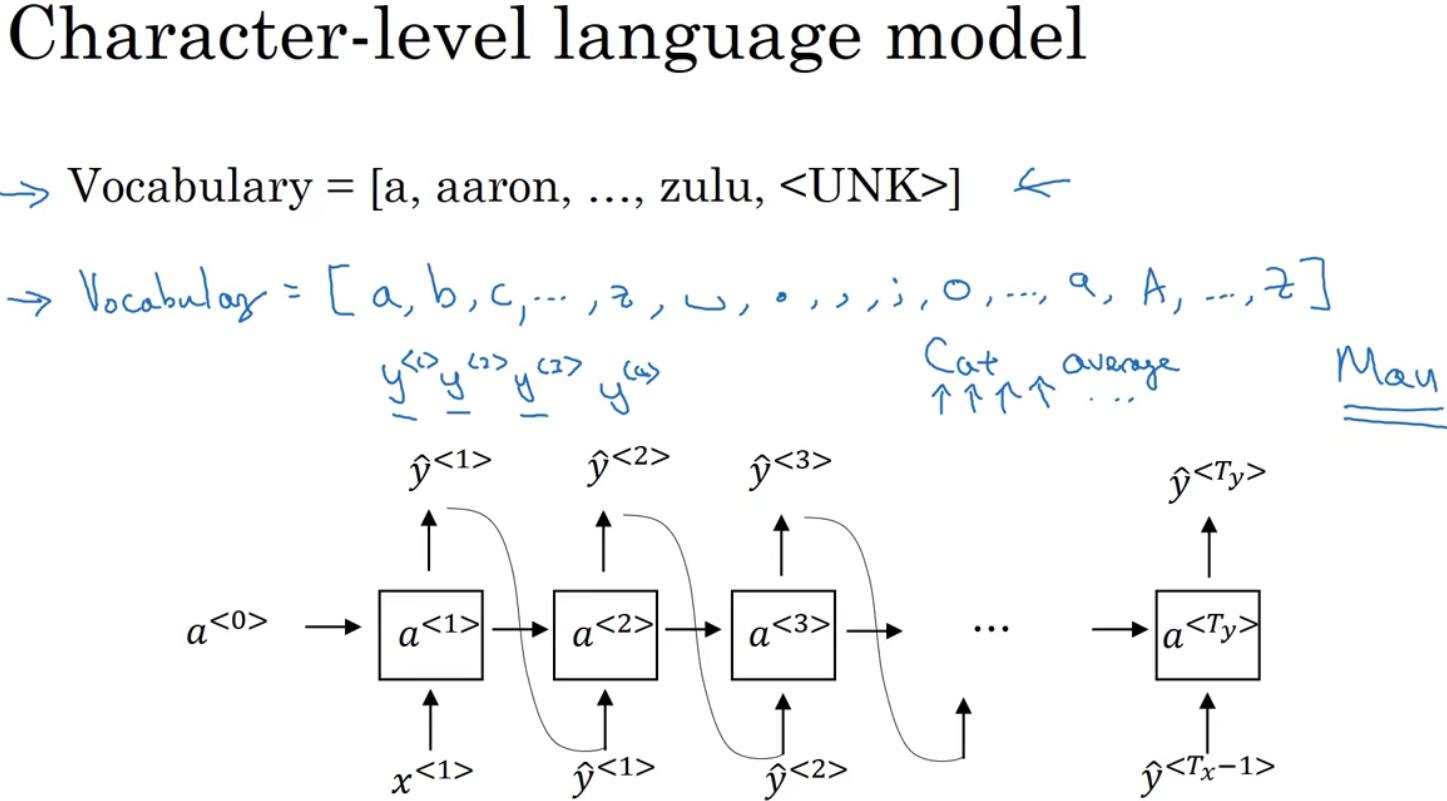
可构建英语单词的字典,或只包含字符的字典。
基于字符的字典优点是不必担心出现未知的标识,缺点是会得到太多太长的序列,成本昂贵,前后依赖关系不如基于词汇的。

左边基于新闻生成
右边基于莎士比亚语录生成八、循环神经网络的梯度消失(Vanishing gradients with RNNs)
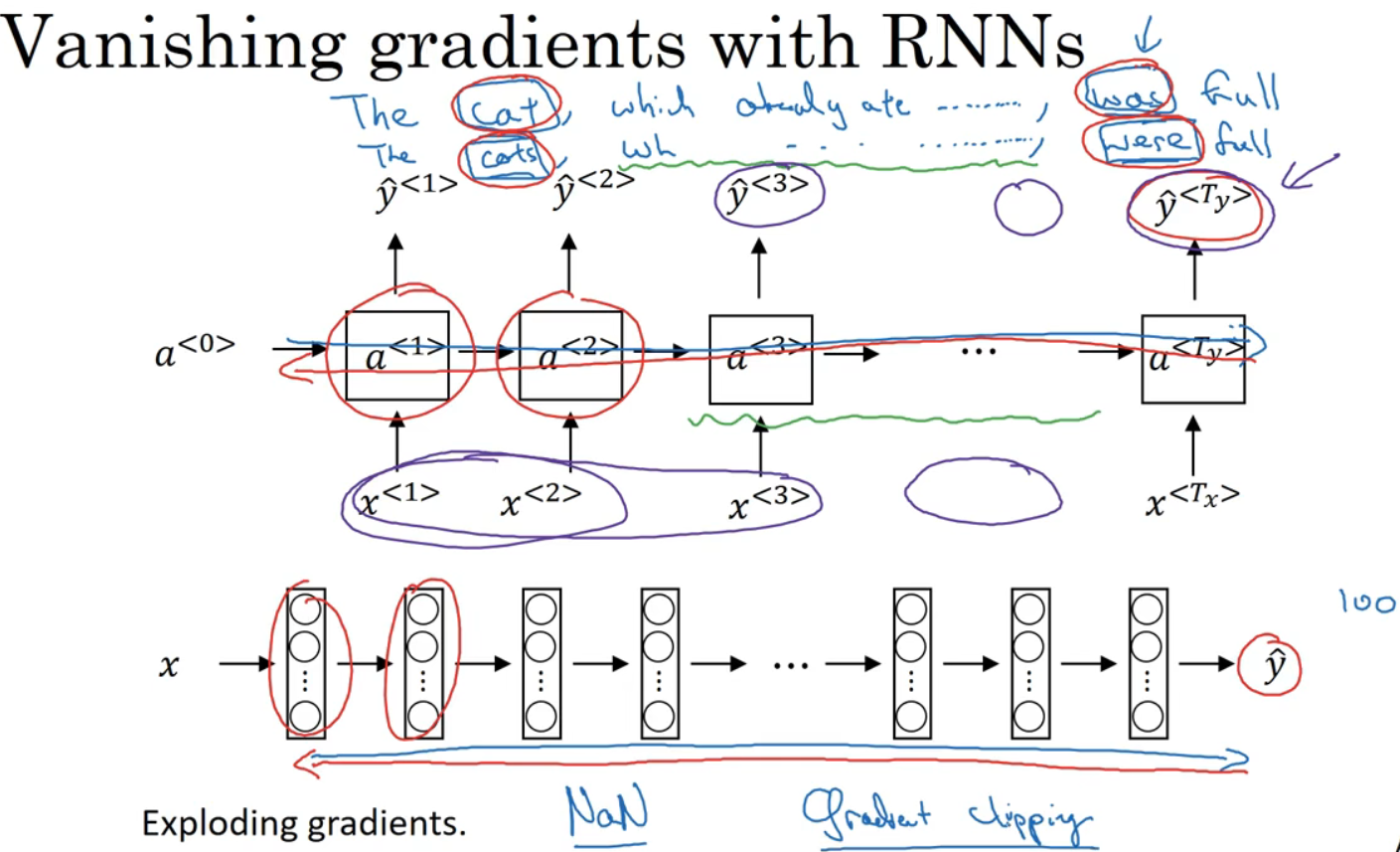
如图两个句子的例子,存在长期依赖,但目前RNN不擅长捕获这种长期依赖效应。
图中下方很深很深的神经网络,前向传播再反向传播,从yhat返回很艰难,很难影响靠前的权重。对于上述同样的问题,RNN也存在,中间的单词可以任意长,因此需要长时间记住单词的单数和复数,后边句子才能用到这些信息。
在神经网络时,还有梯度爆炸一说,在反向传播时,随着层数的增多,梯度不尽可能指数型下降,还可能指数型上升。
事实上,梯度消失在RNN是首要问题,尽管梯度爆炸(导数值很大或Nan)会出现,梯度爆炸很容易发现,梯度爆炸可以用梯度修剪,就是观察梯度向量,若它大于某个阈值,缩放梯度向量,保证它不会太大。九、GRU单元(Gated Recurrent Unit)
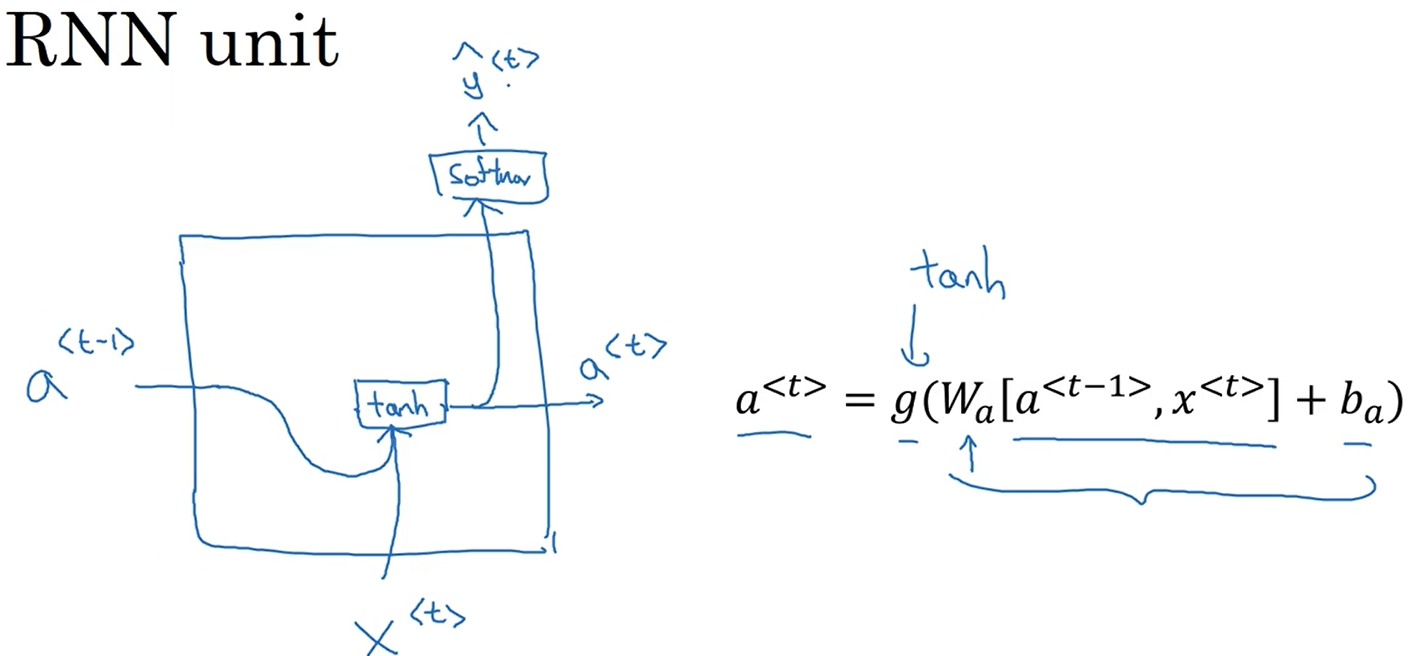
在RNN的时间t处计算激活值。得a传给softmax函数,输出y 。

图右部分:
当我们从左到右读句子时,GRU会有个新的变量称为c,代表cell(细胞),即记忆细胞,于是在时间t处有记忆细胞c,对于GRU,c =a 。
在每个时间步,将用一个候选值重写记忆细胞,即chat,其是个替代值,代替表示c 的值。
重点来了,GRU真正的思想是,我们有一个门,先把们叫做Γ_u,u代表更新门,Γ_u是一个从0到1的值,实际上其是把值带入sigmoid函数得到。sigmoid如图右上角。Γ或G(门的首字母)。其实重要的是更新c,然后门决定是否更新。cat为单数,将c
设为1,GRU将会一直记住c 的值,直到was处。门就是决定什么时候更新c 。所以有了c 的新公式。
若有100维隐藏的激活值,那么c、chat 、Γ_u都是相同的维度。实际上Γ_u不会真的0和1,可能是0到1之间的中间值,

完整的GRU:
在计算的第一个式子中,给记忆细胞的新候选值加上一个新的项,添加一个门Γ,其告知下一个c的后选值chat 跟c 有多大的相关性。 十、长短期记忆(LSTM)
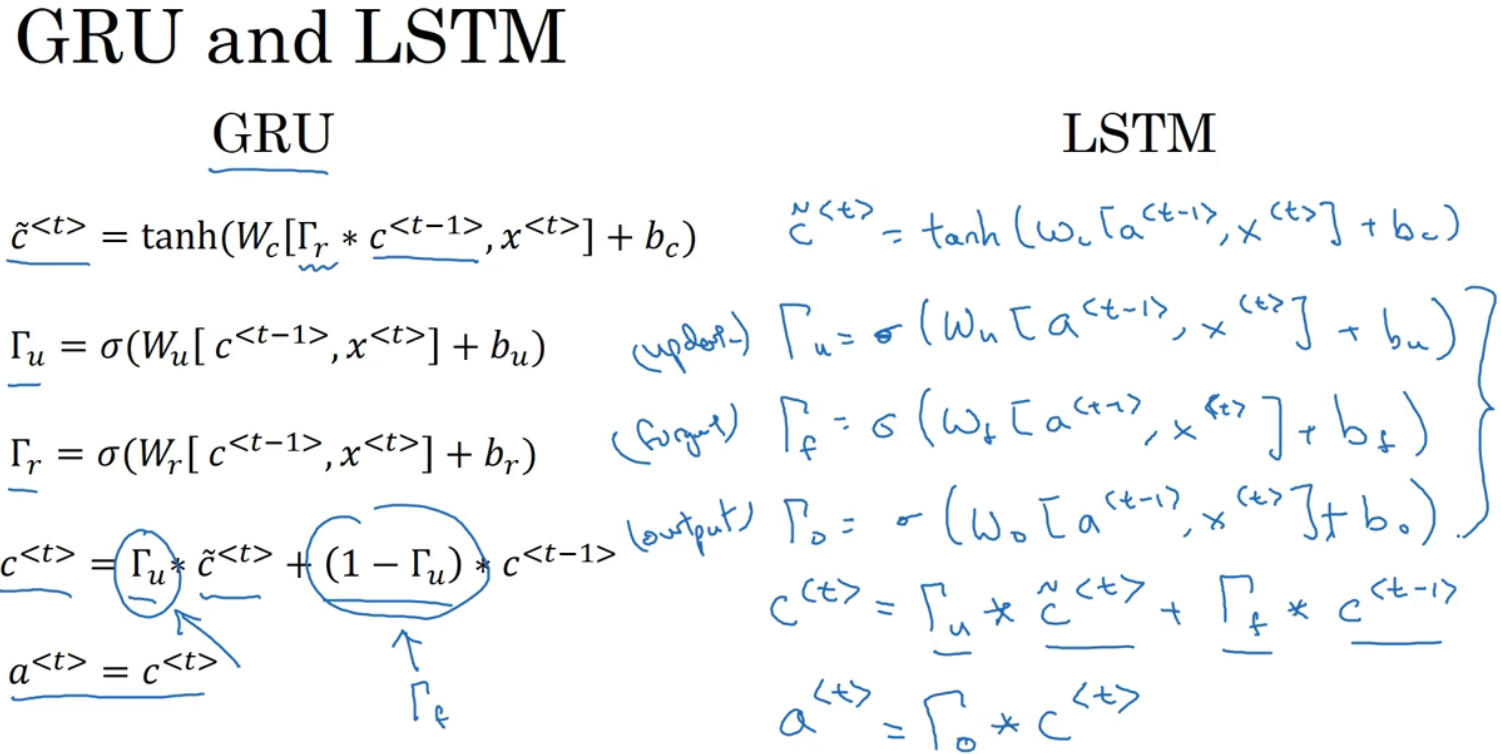
GRU:
两个门:更新门和相关门LSTM:
LSTM中不再有a=c ,也不用相关门了。
LSTM新特性是不只有一个更新门控制。Γ_u更新门、Γ_f遗忘门、Γ_o输出门。
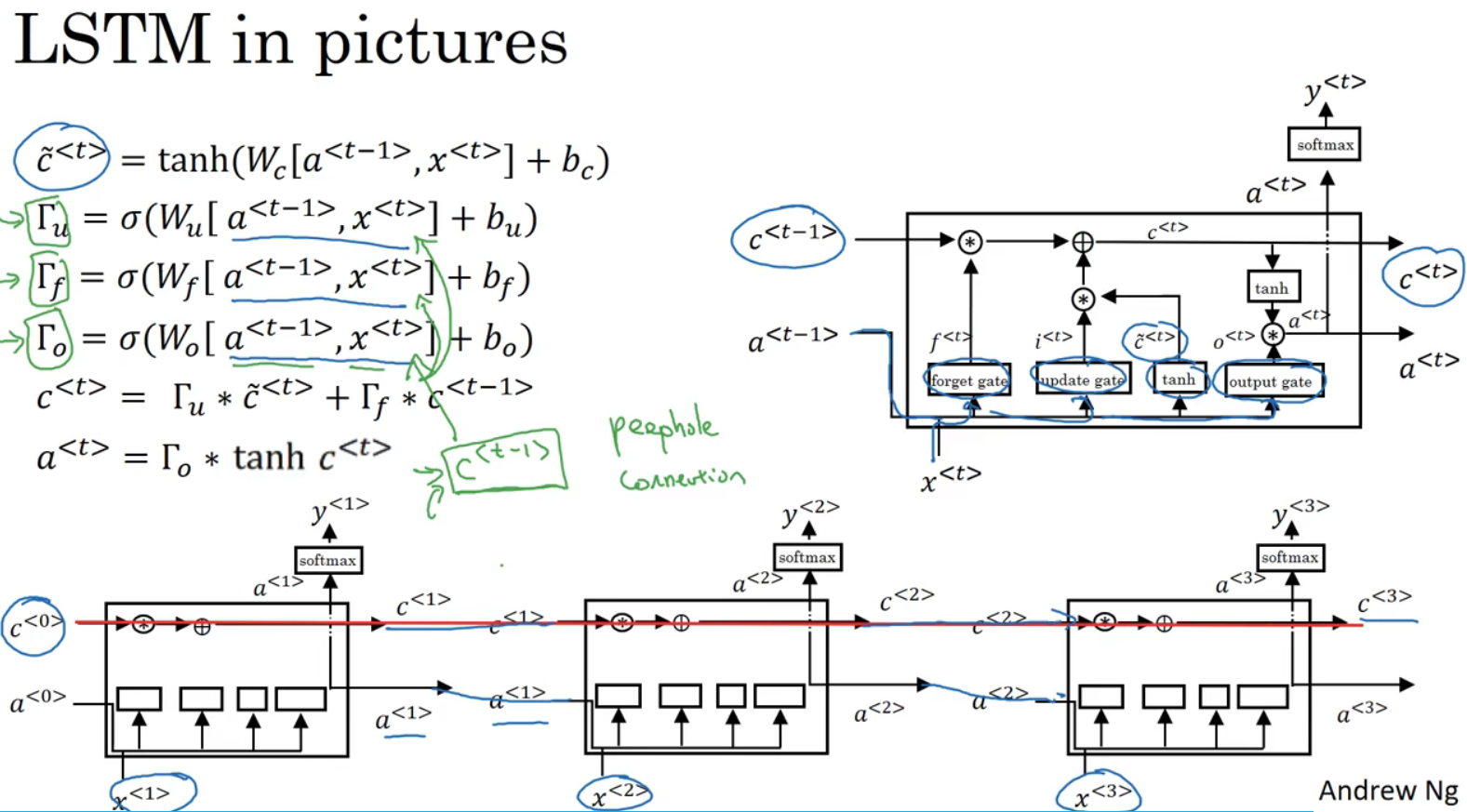
LSTM流程图中,左到右:遗忘门、更新门和输出门。门值不仅取决于a和x,有时候偷窥下c
的值,叫做“窥视孔连接”。
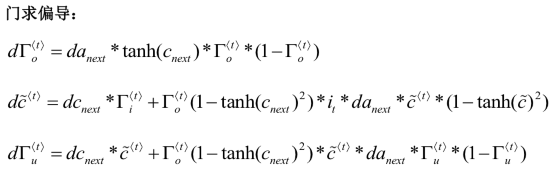
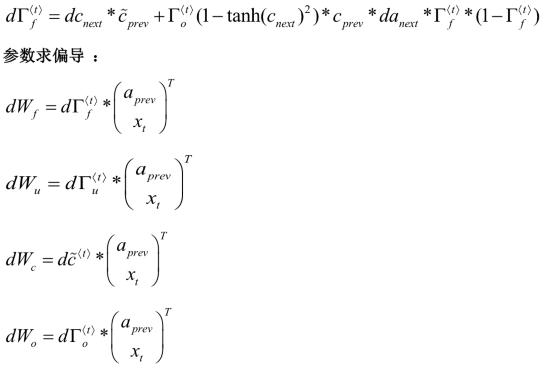

GRU优点更简单,易创建更大的网络,而且只有两个门,运行快。
LSTM更强大和灵活。大部分人今天仍 选择LSTM。十一、双向循环神经网络(Bidirectional RNN)
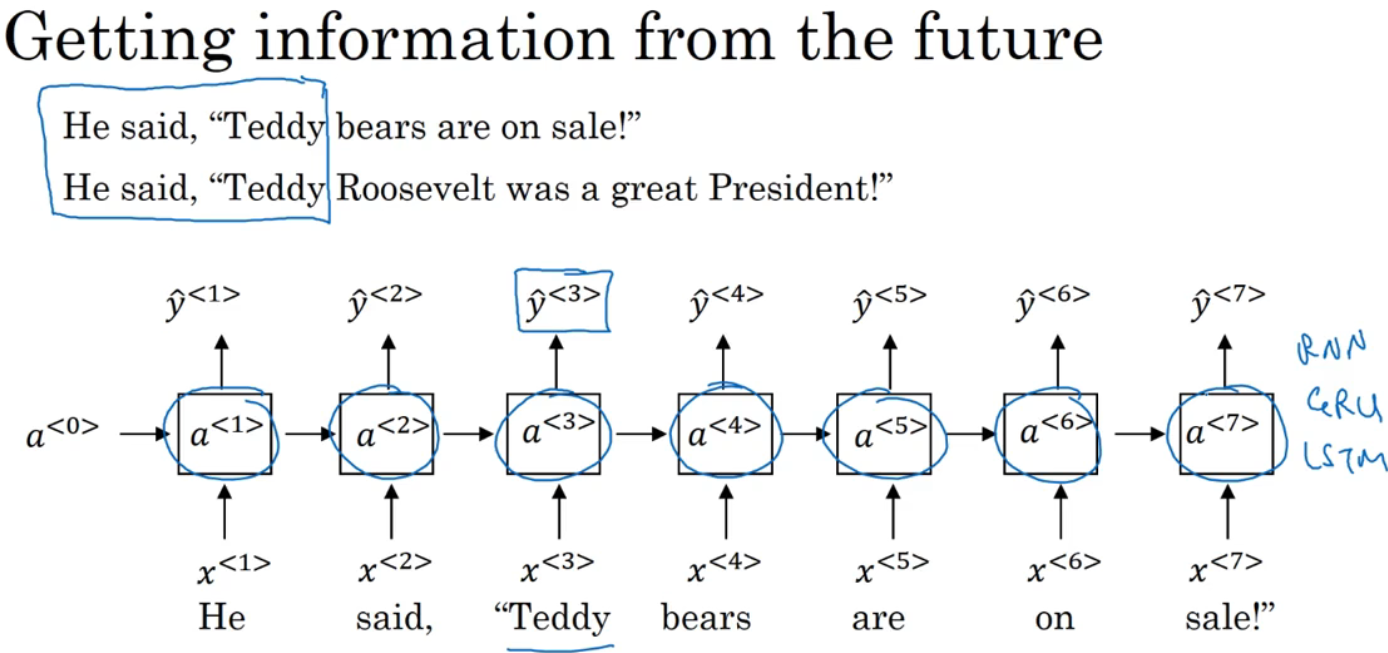
B-RNN不仅可在某点获取之前的信息,还可获取未来的信息。如图,在判断Teddy是否为人名,只看句子前方是不够的,还需后方信息。
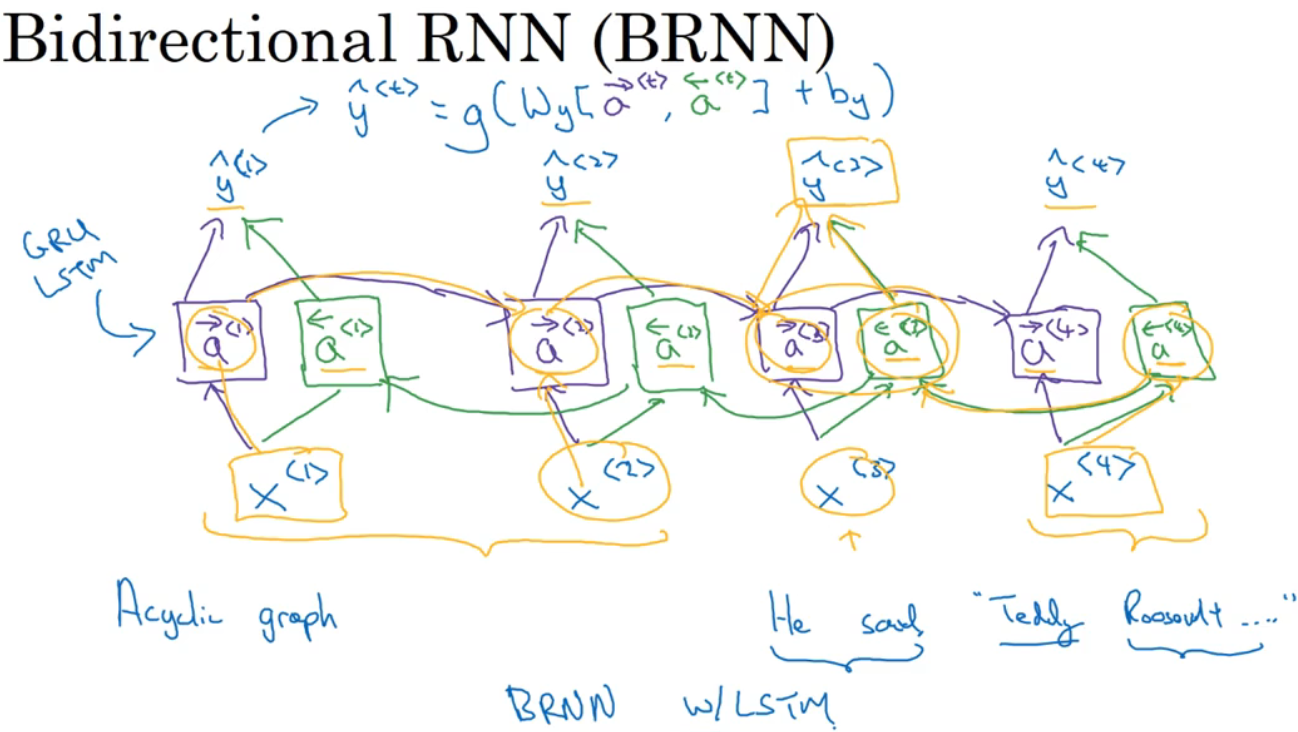
4个输入,会有一个前向的循环单元,并如紫线相连,都得到相应输出yhat。再来个反向循环链,从后往前,相当于前向的传播。然后预测结果。双向RNN缺点是需要完整的数据序列,才能预测任意位置。因此,有时需要等人全部说完才能识别。
十二、深层循环神经网络(Deep RNNs)
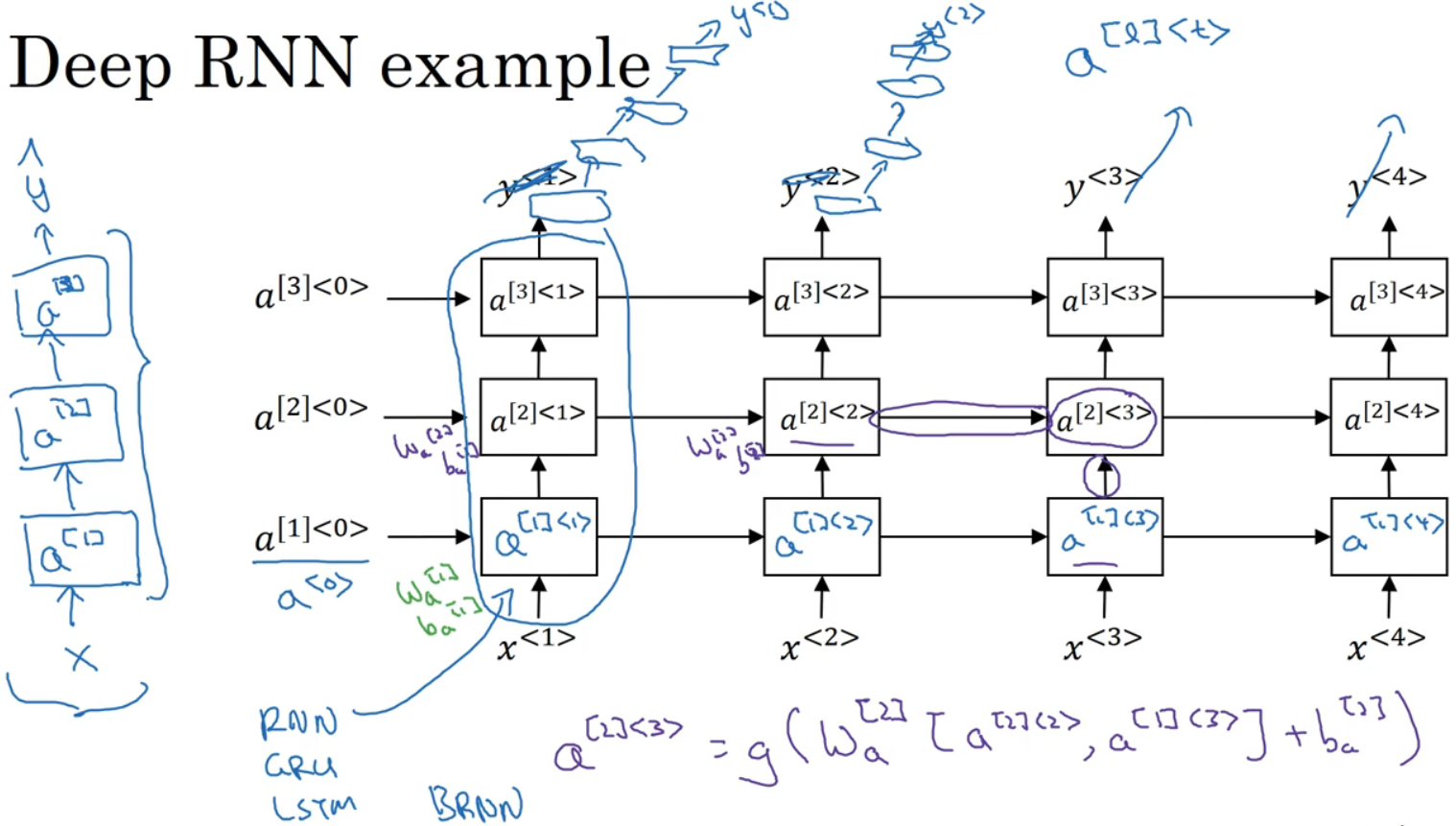
现在选用a[1]<0>来表示第一层,即使用a[l]表示第l层的第t个时间点的激活值。
对于RNN有三层就已经不少了。同时可以在第三层后,去掉y,用更多层做输出。
-
相关阅读:
搭建MyBatis以及Mybaits的相关配置与功能
C# BackgroundWorker用法详解(源码可直接使用)
Python做一个中秋节嫦娥投食小游戏
C++hello world出门遇到坑
C# 实体类转换的两种方式
day09-计算机网络参考模型
如何诊断公司项目流程发现问题提出方案?【项目管理面试秘籍3】
Python 无废话-基础知识元组Tuple详讲
企业微信+SCRM的整体营销工作要如何形成合力?
xgplayer西瓜视频插件引用后因视频格式引起问题?
- 原文地址:https://blog.csdn.net/zxq997997/article/details/125837761