-
YOLOPose实战:手把手实现单阶段的人体姿态估计+代码解读

开源地址: https://github.com/TexasInstruments/edgeai-yolov5/tree/yolo-pose
导读:
前不久看到一则新闻,YOLO之父Joseph Redmon离开CV界,原因是受不了道德的谴责,该技术已被用在军事和隐私问题上。最近,YOLO又火了,YOLOv7在速度和精度的平衡上达到了最佳水平。而基于YOLOv5的YOLOPose也在人体姿态估计领域取得了端到端领先的性能。本篇记录复现YOLOPose的过程,与代码解读。
一、设置
1.1 克隆仓库,安装依赖库,检查Pytorch和GPU
!git clone https://github.com/ultralytics/yolov5 # clone repo #YOLO-Pose分支无法克隆,直接下载zip包即可; %cd edge-yolov5-yolo-pose/ %pip install -r requirements.txt # install dependencies import torch from IPython.display import Image, clear_output # to display images clear_output() print(f"Setup complete. Using torch {torch.__version__} ({torch.cuda.get_device_properties(0).name if torch.cuda.is_available() else 'CPU'})")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Setup complete. Using torch 1.9.1+cu101 (Tesla V100-SXM2-16GB)如果pytorch版本不对,会出现下列问题:
AttributeError: ‘Upsample‘ object has no attribute ‘recompute_scale_factor‘ #https://blog.csdn.net/qq_40280673/article/details/125095353 #正确的版本 pip install torch==1.9.1 pip install torchvision==0.10.1- 1
- 2
- 3
- 4
- 5
- 6
本地conda环境下运行,(pytorch-cifar) wqt@ser2024:edgeai-yolov5-yolo-pose$ pip install torch==1.9.1
二、推理
2. 1 下载训练好的YOLO和YOLOPose模型
(pytorch-cifar) wqt@ser2024:edgeai-yolov5-yolo-pose$ ./weights/download_weights.sh
由于直接打开链接下载,会出现格式错误,这里推荐命令行下载:wget http://software-dl.ti.com/jacinto7/esd/modelzoo/gplv3/08_02_00_11/edgeai-yolov5/pretrained_models/checkpoints/keypoint/coco/edgeai-yolov5/other/best_models/yolov5s6_640_57p5_84p3_kpts_head_6x_dwconv_3x3_lr_0p01/weights/last.pt #此处下载Yolov5s6_pose_960- 1
- 2
- 3
2.2 准备数据
数据集需要准备成YOLO格式,因为数据加载需要同时读取关键点和位置框的信息。有专门的代码库可以产生所需要的格式,见https://github.com/ultralytics/JSON2YOLO 。由于作者已经把coco keypoints转换成所需的格式,直接去下载附件包即可。并且将数据集软连接到所需要文件夹中,文件夹目录如下所示:
edgeai-yolov5 │ README.md │ ... │ coco_kpts │ images │ annotations | labels │ └─────train2017 │ │ └─── | | └─── | | ' | | . │ └─val2017 | └─── | └─── | . | . | train2017.txt | val2017.txt- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
软连接可参考如下:
(base) wqt@ser2024:NewProjects$ ln -s ~/Datasets/coco/* coco_kpts (base) wqt@ser2024:coco_kpts$ rm coco #即可删除软连接- 1
- 2
- 3
2.3 运行
真实标注如下所示:

YOLOPose实测效果,如下图所示:

放大的细节对比:


不难发现,YOLOPose在小尺度的人体检测上有亮点(如左图最右边,右图最左边)!
三、代码解读
3.1 检测器的一般框架
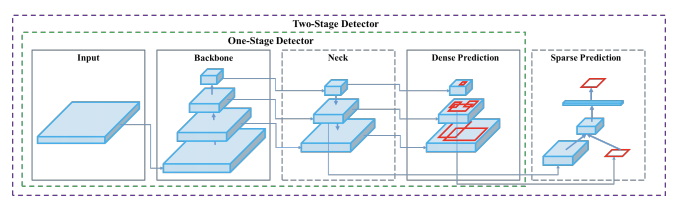
这里描述了目标检测的一般流程图(来自YOLOv4),可以看到一个类人的结构:- 骨架:通常由CNN网络产生不同颗粒度的特征图;
- Neck:一系列网络层融合特征图;
- Head:消化来自Neck的网络特征,并预测位置框与分类。
3.2 YOLOv5架构

YOLOv5主要有4个版本:s,m,l,x。模型不断增大,精度不断提升,但推理速度下降。3.2.1 EfficientDet架构
这里作者与EfficientDet方法进行了对比,我们也可以了解下EfficientDet架构的一些特点:

EfficientDet架构三层特点如下:
- Backbone:采用EfficientNet作为基础骨架;
- Neck:采用Bi-direction金字塔特征进行交互融合;
- Head:预测分类头+预测位置框头;
当然,很有其他处理方法在每个部件可以选择不同架构的组合。YOLOv5最大的贡献就是组合CV其他领域的突破,并证明作为一个融合体能够提升检测性能。
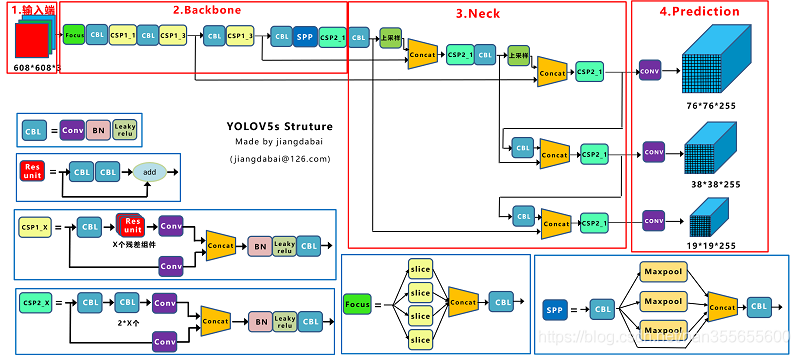
感谢博主提供的YOLOv5架构图!3.3 YOLOv5的新特性
相比v4之前的版本,v5的提升有几个方面:
- 输入端:Mosaic数据增强,自适应锚框,自适应图片缩放;
- Backbone:Focus结构,CSP结构
- Neck:PANet,减少了参数量,更快的推理速度和更好的精度。
- Head:采用GIOU_Loss
3.3.1 数据增强
其实,数据增强也是YOLOv4的秘密武器,与其说新架构,不如说是数据增强。数据增强的方式太多了,有机会专门写一篇有关数据增强的方法介绍,可参考roboflow,很好的外文网站,介绍最新的AI技术。


YOLOv5会将数据集传送给一个数据加载器dataloader,它将会在线增强数据,主要方式有:缩放,颜色空间调整和mosaic增强。其中,马赛克增强是将四张照片以随机比例结合成一张。它对于COCO数据集上的小目标检测效果非常好,见上述实测例子。3.3.2自适应锚框
怎么从图片中找到感兴趣区域?传统的方式是采用滑动窗口去遍历,这将产生大量的冗余候选集,还会增加大量运算量。
在YOLOv3以后,为了检测候选框,网络从一个anchor box列表中计算偏移量来预测候选框位置。

在YOLOv3论文中,作者采用K-means和遗传算法去学习anchor boxes,基于定制数据集的候选框的分布。这对于自定义数据集非常重要,因为候选框的尺度和位置与当前COCO数据集存在很大差异。比较极端的情况就是,长颈鹿的检测框将会很窄很长,而带鱼的检测框很宽很扁。# parameters nc: 80 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple # anchors anchors: - [116,90, 156,198, 373,326] # P5/32 - [30,61, 62,45, 59,119] # P4/16 - [10,13, 16,30, 33,23] # P3/8- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3.3 模型配置文件
YOLOv5统一模型配置文件在 . y a m l .yaml .yaml中,这与DarkNet中的 . c f g .cfg .cfg不一样。主要差别是在 . y a m l .yaml .yaml文件中只需要指定不同层,然后将他们乘以块中的层数即可。其配置如下:
# YOLOv5 backbone backbone: # [from, number, module, args] [[-1, 1, Focus, [64, 3]], # 0-P1/2 [-1, 1, Conv, [128, 3, 2]], # 1-P2/4 [-1, 3, C3, [128]], [-1, 1, Conv, [256, 3, 2]], # 3-P3/8 [-1, 9, C3, [256]], [-1, 1, Conv, [512, 3, 2]], # 5-P4/16 [-1, 9, C3, [512]], [-1, 1, Conv, [1024, 3, 2]], # 7-P5/32 [-1, 1, SPP, [1024, [5, 9, 13]]], [-1, 3, C3, [1024, False]], # 9 ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
# YOLOv5 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3.3.3 CSP骨架
YOLOv4和v5都采用了CSP bottleneck来制定特征, Cross Stage Partial Networks, CSPNet借鉴了DenseNet的思想,为了缓解梯度消失问题,促进特征传播,鼓励重复使用特征,并减少网络参数量。



class BottleneckCSP(nn.Module): # CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() c_ = int(c2 * e) # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False) self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False) self.cv4 = Conv(2 * c_, c2, 1, 1) self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3) self.act = nn.ReLU(inplace=True) self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)]) def forward(self, x): y1 = self.cv3(self.m(self.cv1(x))) y2 = self.cv2(x) return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3.3.4 PANet Neck
YOLOv4和v5都采用了PANet(下图b)方式来聚合特征。

此图来EfficientDet论文,它采用BiFPN方式来融合特征,证明了此结构对于目标检测任务是最好的选择。或者这对于Yolo而言是需要进一步探索的。
3.4 Bounding box损失函数
有关检测框的损失函数,专门有在系列文章中介绍。这里,Yolov5中采用其中的CIOU_Loss做Bounding box的损失函数。

在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中仍然采用加权nms的方式。可以看出,采用DIOU_nms,下方中间箭头的黄色部分,原本被遮挡的摩托车也可以检出。

后续不妨考虑修改损失函数!参考
- https://blog.csdn.net/nan355655600/article/details/107852353
- https://blog.roboflow.com/yolov5-improvements-and-evaluation/
bug调试
ImportError: cannot import name 'amp' from 'torch.cuda' (/home/wqt/anaconda3/envs/pytorch-cifar/lib/python3.7/site-packages/torch/cuda/__init__.py)- 1
原始conda环境下torch版本比较低,按照install requirement.txt中安装又容易出现最高版本,最好的选择是看作者推荐的版本,或者从issue中找答案。
AttributeError: Cant get attribute SPPF on module models.common- 1
这是由于下载的yolov5分支是比较早期的,要么下载最新git,要么直接把这个类贴进去。可参考https://blog.csdn.net/Steven_Cary/article/details/120886696
总结:
想改进YOLO去提升性能,可能面临的主要麻烦有:首先,涉及的改动联动太多;其次,数据格式也需要改成YOLO格式,如果想在其他数据库上运行,先要过数据这一关,一股蛋蛋的忧桑涌上心头
-
相关阅读:
CSS padding(填充)
树莓派Pico入手
Python和PyTorch深入实现线性回归模型:一篇文章全面掌握基础机器学习技术
通过坐标平移实现非完整约束系统的反馈线性化
win10换ubuntu
学习C++第二十五课--using定义模板别名与显式指定模板参数笔记
使用 AWS S3 SDK 访问 COS-腾讯云国际站代充
【信号和槽】
Redis常用数据类型--Set
量化交易全流程(一)
- 原文地址:https://blog.csdn.net/wqthaha/article/details/125893789
